PgSQL · 特性分析· JIT 在数据仓库中的应用价值
Author: 曾文旌(义从)
背景
近几年,分析型数据库中有项技术得到了广泛的应用。它就是 JIT(Just-in-time compilation)动态编译。还有一些相关名词 LLVM codegen 和这项技术相关。本文把这项技术做一个简单的分析,和大家分享。
一、JIT 是什么
长久以来数据仓库都是以高效的处理量数据的能力著称。随着硬件的发展,他们使用大量相关技术充分挖掘硬件的能力提高数据的吞吐量和处理效率。例如 SMP MPP mapreduce 列存储 压缩 等等。这么多年开源生态的活跃,使得我们对这类技术的实现细节也越来越了解。嗯,现在轮到 JIT 普及了。
简单的说 JIT 是一种提高程序运行效率的方法。通常,程序有两种运行方式:静态编译与动态直译。静态编译的程序在执行前全部被翻译为机器码,而直译执行的则是一句一句边运行边翻译。 JIT 则混合了这二者,一句一句编译源代码,但是会将翻译过的代码缓存起来以降低性能损耗。相对于静态编译代码,即时编译的代码可以处理延迟绑定并增强安全性。
二、数据仓库中的 JIT 应用
数据仓库领域,单个的任务为了追求高性能,需要尽可能的利用整个仓库的硬件资源进行计算。当前的硬件条件下,分析业务无疑是 CPU 密集型的任务。我们经常能看到跑一个任务,调度整个集群的 CPU 满负荷运转几分钟,甚至几小时的情况。另外,随着我们的数据的爆发式增长,数据压缩存放已经成为缺省选项。读取的读写都要相当量的 CPU 计算。如何提高 CPU 的计算效率成为一个通用的性能优化任务。
了解数据库内核实现的同学都知道,传统数据库后端编码是一套通用的代码,实现通用的数据处理。例如
- 一套代码实现不同数据类型(定长,变长)组合的表结构的读和写,而一个 SQL 往往只涉及几个有限的表。比如 select * from t 这个 SQL 只涉及一个表,这表的数据类型列的个数是固定的。
- 通用的 DB 执行器,可以兼容不同执行节点随意组合的执行方式,而一个SQL 往往是固定的几个执行节点的组合,比如 select count(*) from t 这个 SQL 就是一个全表扫描节点 Seqscan 和聚集节点 Group 的简单组合。
- 实现一个通用的 SQL 表达式计算框架,兼容所有表达式计算(各种数据类型 + - 计算 不同参数的函数调用)。而单个 SQL 中表达式是固定的。比如 select fun(t.a,t.b) + t.c from t 这个 SQL 即是把表 t 中的3个列做简单的函数加合计算。
各位已经看出,单个 SQL 中,很多之前的“变量”,已经成为“常量”,如果我们在知道用户的 SQL 的之后再 “coding”,会少很多条件判断,少很多无关代码,效率自然会高很多。 更加变本加厉的是,数据分型业务,往往处理的数据相当庞大。单个任务(SQL)往往使用相同的模式处理少则几十 GB,多则上 TB 的数据。如果我们拿到用户的 SQL 后使用 JIT 技术生成一段“精简”的代码再执行,效率会大大提高。
其实,这样的思路早在一些高端大气的商业产品中得到了使用,例如 IBM DB2 中就产品化了类似的特性。称作 threaded code generation 技术,动态生成效率较高的 section 来优化 CPU 执行效率。感觉很高级啊。的确,该技术之前不普及的原因是实践起来有一定难度,难点在于在执行阶段生成代码缺少难度较低的实现方式,直到 LLVM 的出现。
三、LLVM 是个什么鬼
LLVM,一个自由软件项目,是一种编译器的基础建设,以 C++ 写成。它是为了任意一种编程语言写成的程序,利用虚拟技术,创造出编译时期,链接时期,运行时期以及“闲置时期”的最优化。它最早是以C/C++为实现对象,目前它支持了很多编程语言。 LLVM 项目起源于 2000 年伊利诺伊大学厄巴纳-香槟分校维克拉姆·艾夫(Vikram Adve)与克里斯·拉特纳(Chris Lattner)的研究发展而成,他们想要为所有静态及动态语言创造出动态的编译技术。LLVM 是以 BSD 授权来发展的开源码软件。在2005年,苹果电脑雇用了克里斯·拉特纳及他的团队,为了苹果电脑开发应用程序系统,LLVM 为现今 Mac OS X 及iOS开发工具的一部分。
嗯,乔大爷看上的技术都差不了。LLVM 的命名最早源自于底层虚拟机(Low Level Virtual Machine)的首字字母缩写。它提供了一种在程序运行时编译执行代码的可行的程序框架。不仅仅如此 LLVM 这几年快速普及,还有很多靓丽的特性
- LLVM 也可以在编译时期、链接时期,甚至是运行时期产生可重新定位的代码(Relocatable Code)上面已经提到;
- LLVM 支持与语言无关的指令集架构及类型系统。LLVM 可以提供完整编译器系统的中间层,从编译器获取中间表示(IR)代码并发出优化的 IR。然后可以将这个新的 IR 转换并链接到目标平台的依赖于机器的汇编语言代码。在我们的应用场景中,使用 LLVM API 会生成中间代码 IR。存放在内存或外部文件中。在目标平台执行时,针对对应的平台再生成对应的机器码再执行。这意味着我们在 IR 层编程,在不同的 CPU 上执行,会生当前硬件平台生成最优的机器码。即使是 intel 的 x86 平台,不同代的 CPU 优化程度也不同。例如 LLVM 会充分利用新 CPU 上的指令集,例如 SIMD。这一点在数据仓库做浮点数计算时会用到。
- LLVM 有一套完整的 API 可以用于编码,并生成 LLVM IR 中间代码。支持很多种编码语言,C/C++ 都覆盖到了。我们主要的工作都在这了。
- LLVM 的前端编译器 clang 兼容 gcc, 且性能相当。相关代码使用编译器 clang 编译,能和 gcc 编译的二进制相互链接。
四、谁在用 LLVM
目前比较流行的数据分析数据库中使用 JIT 技术的有
| 产品 | 简介 | 状态 |
|---|---|---|
| HyPer | 高性能内存数据库 | 闭源,使用 LLVM code generation 技术 |
| Impala | Cloudera公司主导开发的新型查询系统 | 开源,使用LLVM动态生成部分执行器 |
| Postgres Professional | PostgreSQL 的一个发行版 | 开源,JIT-compilation of queries 的计划 |
| gpdb | 基于 PostgreSQL 的 MPP 产品 | 开源,已经开始开发 JIT ,目前刚起步 |
另外,国内几家互联网公司也都有使用 LLVM 优化自己数据分析业务的案例
五、LLVM 可优化的点
一. 优化频繁调用的存取层
数据库执行器通过存取层装在数据,针对特定的表结构,可以定制读取和解析 tuple 的代码,其中有很多优化点。
举例: 通常,情况下通用的解析 tuple 的流程如下,每一列的数据类型不同,是定长数据类型还是变长也不确定。
void MaterializeTuple(char* tuple)
{
for (int i = 0; i < num_slots_; ++i)
{
char* slot = tuple + offsets_[i];
switch(types_[i])
{
case BOOLEAN:
*slot = ParseBoolean();
break;
case INT:
*slot = ParseInt();
break;
case FLOAT: …
case STRING: …
// etc.
}
}
}
当知道表结构后, 动态生成的代码就简单了。
void MaterializeTuple(char* tuple)
{
*(tuple + 0) = ParseInt(); // i = 0
*(tuple + 4) = ParseBoolean(); // i = 1
*(tuple + 5) = ParseInt(); // i = 2
}
按照顺序解析数据,不需要做数据类型的判断,直接在获取对应偏移的数据,跳过不需要获得的列。都是能够优化 CPU 的点。随着处理的行数增加,节省的计算量是惊人的。这才只是刚刚开始。
二. 表达式计算
以 PostgreSQL 为例,它的表达式计算基于一套通用的框架,表达式求值计算像一颗二叉树一样,求值过程就是从叶子节点算到根节点。整个步骤是递归方式执行。
例如
select funx(((1 + a.b) + a.a )) /2 from a
他的执行过程是
expr(root) // funroot
funx(data) // funx
data (/) 2 // fundivision
data (+) a.a // funadd
1 (+) a.b // funadd
可以看到,表达式越复杂,递归调用越深。执行的函数个数越多。
然而,在获取到查询计划之后再“写”代码,就简单了,只需要这样
llvm_expr_fun1
{
tmp = 1 (+) a.b;
tmp1 = tmp + a.a;
tmp3 = tmp1 / 2;
tmp4 = funx(tmp3);
}
这么做的好处是:
- 递归改顺序执行
- 整个过程一个函数调用完成,性能提高明显。 整个优化方式适合 OLTP 和 OLAP 场景,我们可以像保存查询计划那样保存 LLVM 生成的表达式函数
三:优化执行器流程
这部分是表达式计算的高级版本,改进的单位从每一行数据的处理提高到整个 SQL 的处理流程。 传统的流水线执行方式效率不高,如果调整成循环批量处理方式,能充分利用 CPU cache,大幅提高效率。
举例
select *
from R1,R3,
( select R2.z,
count(*)
from R2
where R2.y=3
group by R2.z
) R2
where R1.x=7
and R1.a=R3.b
and R2.z=R3.c
上面的 SQL 采用传统的方式是 pipeline 方式,如下图
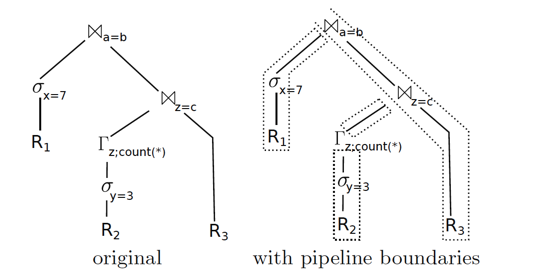
如果采用如下“批量”处理的方式
initialize memory of ona=b, onc=z, and Gz
for each tuple t in R1
if t:x = 7
materialize t in hash table of ona=b
for each tuple t in R2
if t:y = 3
aggregate t in hash table of Gz
for each tuple t in Gz
materialize t in hash table of onz=c
for each tuple t3 in R3
for each match t2 in onz=c [t3:c]
for each match t1 in ona=b [t3:b]
output t1 ◦t2 ◦t3
他的核心思想是批量处理,单独处理每个表,把处理结果固化下来 这么做的优势是充分利用现代 CPU 的大缓存,让尽可能多的数据的计算能够在 CPU cache 中完成,避免去相对慢得多的内存中存取数据。 再结合 CPU 向量计算相关指令集,性能会进一步提高。LLVM 会帮我们做到这一点。
性能
- 我们在场景 1 和 2 上完成了优化的 demo,在比较复杂的 SQL 表达式计算场景(读取单表中 10 个数值的简单数学计算,1000W 行数据),性能有 3 倍的提高(执行时间从25秒降到7秒)。
- 相关论文表明,以为典型的分析型业务场景模型 TPCH 为测试模型,采用上述优化的方法,TPCH 中所有 SQL 都能获得少则几倍,多则几十倍的性能提升。
总结
LLVM 降低了 JIT 的工程化难度,使得它最近几年在数据仓库领域得到了广泛的普及。它能通过提高 CPU 效率的方法提高任务的性能,显著降低硬件成本。 最后,你期待阿里云数据分析产品采用该技术么?期待和大家一同研究这方面的问题,邮箱 wenjing.zwj@alibaba-inc.com