SQL Server · 特性介绍 · 聚集列存储索引
Author: 风移
摘要
微软在SQL Server 2012引入了列存储技术,使得OLAP和Data warehouse场景性能提升10X,并且数据压缩能力超过传统表7X。这项技术包含三个方面的创新:列存储索引、Batch Mode Processing和基于Column Segment的压缩。但是,SQL Server 2012列存储索引的一个致命缺点是列存储索引表会进入只读状态,用户无法更新操作。SQL Server 2014引入了可更新聚集列存储索引技术来解决列存储索引表只读的问题,使得列存储索引表使用的范围和场景大大增加。
名词解释
SQL Server 2014使用聚集列存储索引来解决列存储索引表只读问题的同时,引入了几个全新的名称。
Clustered Column Store Index
聚集列存储索引是一个可更新的整张表数据物理存储结构,并且每张表只允许创建一个聚集列存储索引,不能与其他的索引并存。我们可以对聚集列存储索引进行Insert、Delete、Update、Merge和Bulk Load操作。这也是SQL Server 2014 Clustered Columnstore Index正真强大的地方。下面这张来自微软官方的图描述了聚集列存储索引的物理存储结构:
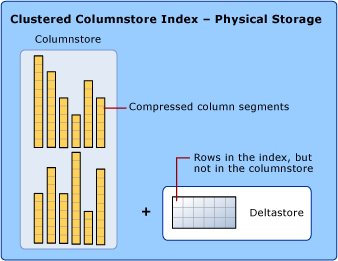
Delta Store
由于column store是基于column segment压缩而存放的结构,为了减少DML操作导致的列存储索引碎片和提高更新性能,系统在做数据更新操作(Insert和Update)的时候,不会直接去操作已经压缩存储的column store(这样系统开销成本太高),而是引入一个临时存储的中间结构Delta Store。Delta Store结构和传统的基于B-Tree结构的row store没有任何差异,它存在的意义在于提高系统的DML操作效率、提升Bulk Loading的性能和减少Clustered Column Store Index碎片。
Delete Bitmap
对于更新操作中的删除动作,会比较特殊,聚集列存储索引采用的是标记删除的方式,而没有立即物理删除column store中的数据。为了达到标记删除的目的,SQL Server 2014引入了另一个B-Tree结构,它叫着Delete Bitmap,Delete Bitmap中记录了被标记删除的Row Group对应的RowId,在后续查询过程中,系统会过滤掉已经被标记删除的Row Group。
Tuple Mover
当不断有数据插入Clustered Column Store Index表的时候,Delta Store中存储的数据会越来越多,当大量数据存储在Delta Store中以后,势必会导致用户的查询语句性能降低(因为Delta Store是B-Tree结构,相对列存储结构性能降低)。为了解决这个问题,SQL Server 2014引入了一个全新的后台进程,叫着Tuple Mover。Tuple Mover后台进程会周期性的检查Closed Delta Store并且将其压缩转化为相应的Column Store Segment。Tuple Mover进程每次读取一个Closed Delta Store,在此过程中,并不会阻塞其他进程对Delta Store的读取操作(但会阻塞并发删除和更新操作)。当Tuple Mover完成压缩处理和转化以后,会创建一个用户可见的新的Column Store Segment,并使Delta Store结构中相应的数据不可见(正真的删除操作会等待所有读取该Delta Store进程退出后),在这以后的用户读取行为会直接从压缩后的Column Store中读取。 来一张Tuple Mover的手绘图(画外音:手绘图是一种情怀,就像劳斯莱斯是纯手工打造一样):
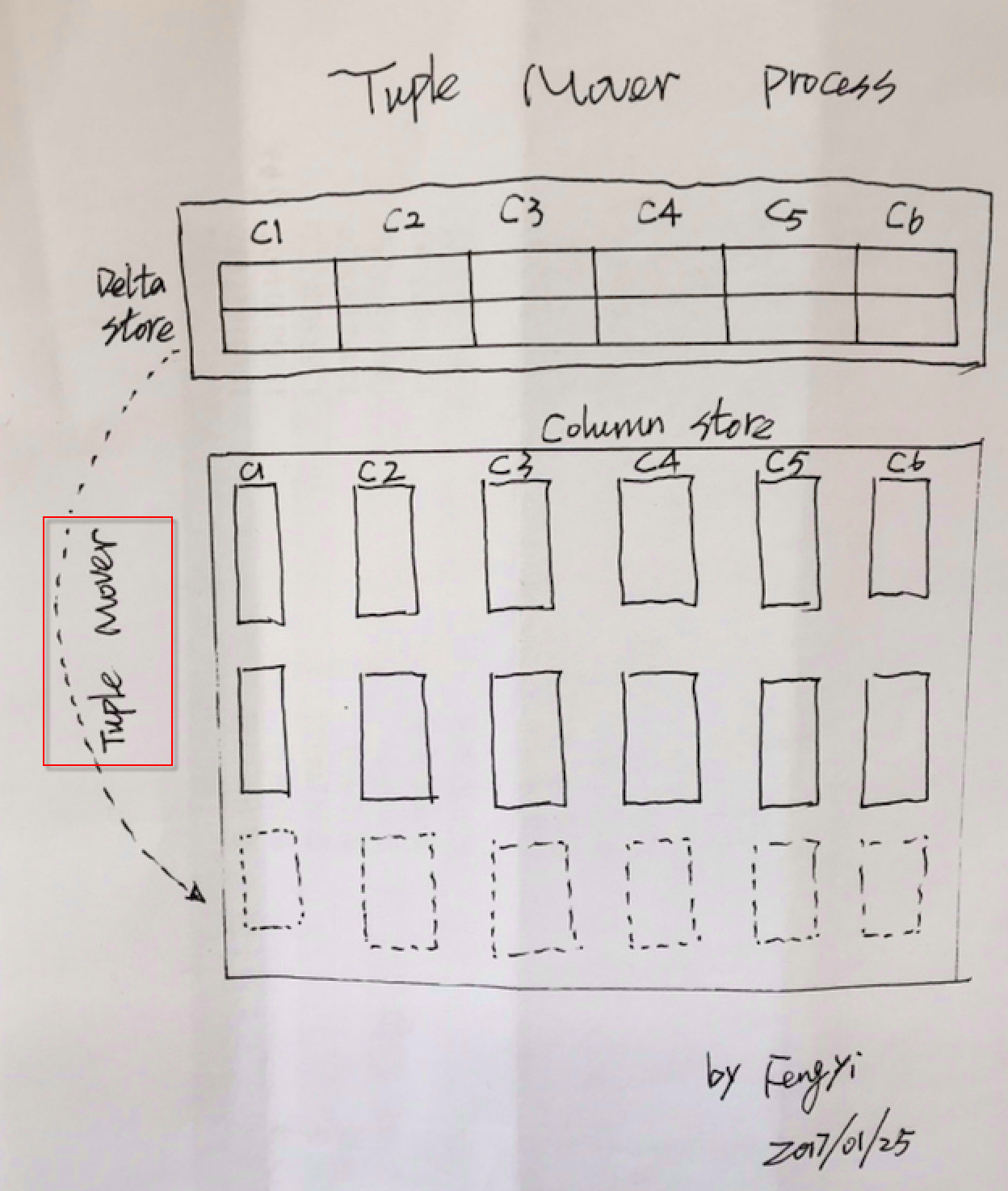
数据操作
基于Delta Store和Delete Bitmap的特殊设计,SQL Server 2014聚集列存储索引看起来是做到了可更新操作,实际上聚集列存储索引本身是不可变的。它是在借助了两个可变结构以后,达到了可更新的目的。这三部分结构示意图如下所示:
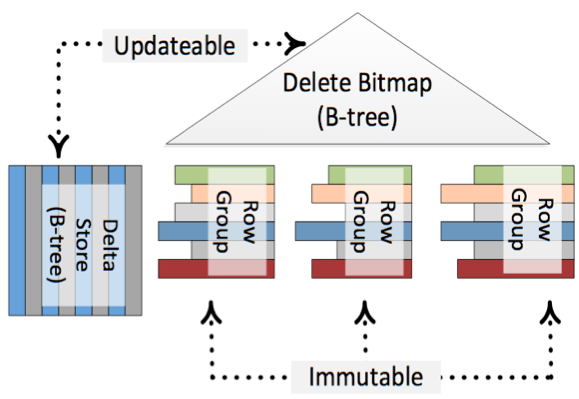
接下来,我们看看SQL Server 2014聚集列存储索引表DML操作原理。其中DML操作包括:INSERT、DELETE、UPDATE、MERGE和BULK操作,其中以BULK批量数据操作最为复杂,也是这一节需要详细讲解的地方。
INSERT
当我们执行INSERT操作的时候,INSERT的这一条新的记录不是立即进入Column Store中,而是进入Delta Store B-Tree结构中,Delta Store结构中存储的数据会在重组(Reorganize)聚集列存储索引的时候进入Column Store。INSERT完成后的数据读取操作,SQL Server会从Column Store和Delta store两个结构中读取,然后返回给用户。
DELETE
当我们执行DELETE操作的时候,数据库系统并不会直接从Clustered Store中直接删除数据,而是往Delete Bitmap结构中插入一条带有rowid的记录,系统会在聚集列存储索引重建(Rebuild)的时候最终删除Column Store中的数据。DELETE操作完成后的数据读取操作,SQL Server从Column Store中读取数据,然后通过rowid过滤掉在Delete Bitmaps中已经标记删除的数据,最后返回给用户。
UPDATE
当我们执行UPDATE操作的时候,数据库系统将这个操作分解成DELETE和INSERT操作,即先标记删除老的这条记录然后插入新的记录。SQL Server系统会在Delete Bitmaps中先插入一条带有rowid的记录,然后在Delta Store中插入一条新的记录数据。
MERGE
当我们执行MERGE操作的时候,数据库系统会将这个操作分解为相应的INSERT、DELETE或者是UPDATE操作。
BULK LOADING
在Bulk LOADING大批次数据导入介绍之前,我们必须要重点介绍几个重要的数字:
102400:数据是否直接进入Column Store的Row Group 行数的最小临界值。
1048576:一个Row Group可以容纳的最大行数。
BatchSize:Bulk Insert操作的参数,表示每批次处理的记录数。
Rows:需要批量导入聚集列存储索引表的记录总数,Rows应该总是大于等于0的整数。
在聚集列存储索引表场景中,微软SQL Server 2014推荐使用Bulk Insert进行大批次数据的更新,效率更高,维护成本也更低。聚集列存储索引针对Bulk Insert处理的逻辑是:如果Bulk Insert操作的总记录条数(Rows)小于102400条,那么所有数据会被加载到Delta Store结构中;如果Rows大于等于102400,会参照Bulk Insert的BatchSize进一步细分:BatchSize小于102400时,所有数据全部进入Delta Store;BatchSize大于等于102400时,大部分数据进入Column Store,剩下小部分数据进入Delta Store。比如:rows总共有102400 * 2 + 3 = 204803条,BatchSize为102399时,所有数据会进入Delta Store;BatchSize为102400时,会有两个Row Group的数据共204800进入Column Store,剩下3条数据进入Delta Store。 参见微软官方的流程图:
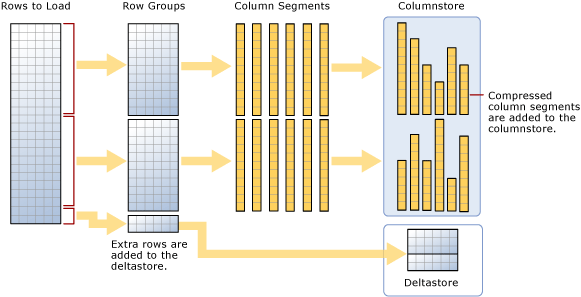
这个流程图把大致的Bulk Insert数据流向说清楚了,但是它没有把几个具体的数字和相关的逻辑表达的很清楚。现在,我们需要把详细逻辑理解清楚,以此来指导我们进行Bulk Insert来提高大批次数据导入的效率。为了表达清楚Bulk Insert的详细逻辑,参见下面的伪代码,每一个BEGIN END之间是一个语句块:
IF Rows < 102400
BEGIN
All Rows Insert into Delta Store
END
ELSE IF Rows >= 102400 & Rows < 1048576
BEGIN
IF BatchSize < 102400
BEGIN
All Rows Insert into Delta Store Batchly
END
ELSE IF BatchSize >= 102400
BEGIN
SomeData Insert into Column Store Batchly
SomeData Remaining Insert into Delete Store
END
END
ELSE IF Rows >= 1048576
BEGIN
IF BatchSize < 102400
BEGIN
All Rows Insert into Delta Store Batchly
END
ELSE IF BatchSize >= 102400 & BatchSize < 1048576
BEGIN
SomeData Insert into Column Store Batchly
SomeData Remaining Insert into Delete Store
END
ELSE IF BatchSize >= 1048576
BEGIN
SomeData Insert into Column Store Batchly
IF SomeData Remaining >= 102400
BEGIN
Some of the SomeData Remaining will be Inserted into Column Store Batchly (batchsize = 102400)
The left of the SomeData Remaining will be Inserted into Delta Store
END
ELSE IF SomeData Remaining < 102400
BEGIN
Some of the SomeData Remaining will be Inserted into Delta Store
END
END
END
伪代码写出来的逻辑还是很丑陋,也比较复杂,难于理解。再次手绘工作流程图:
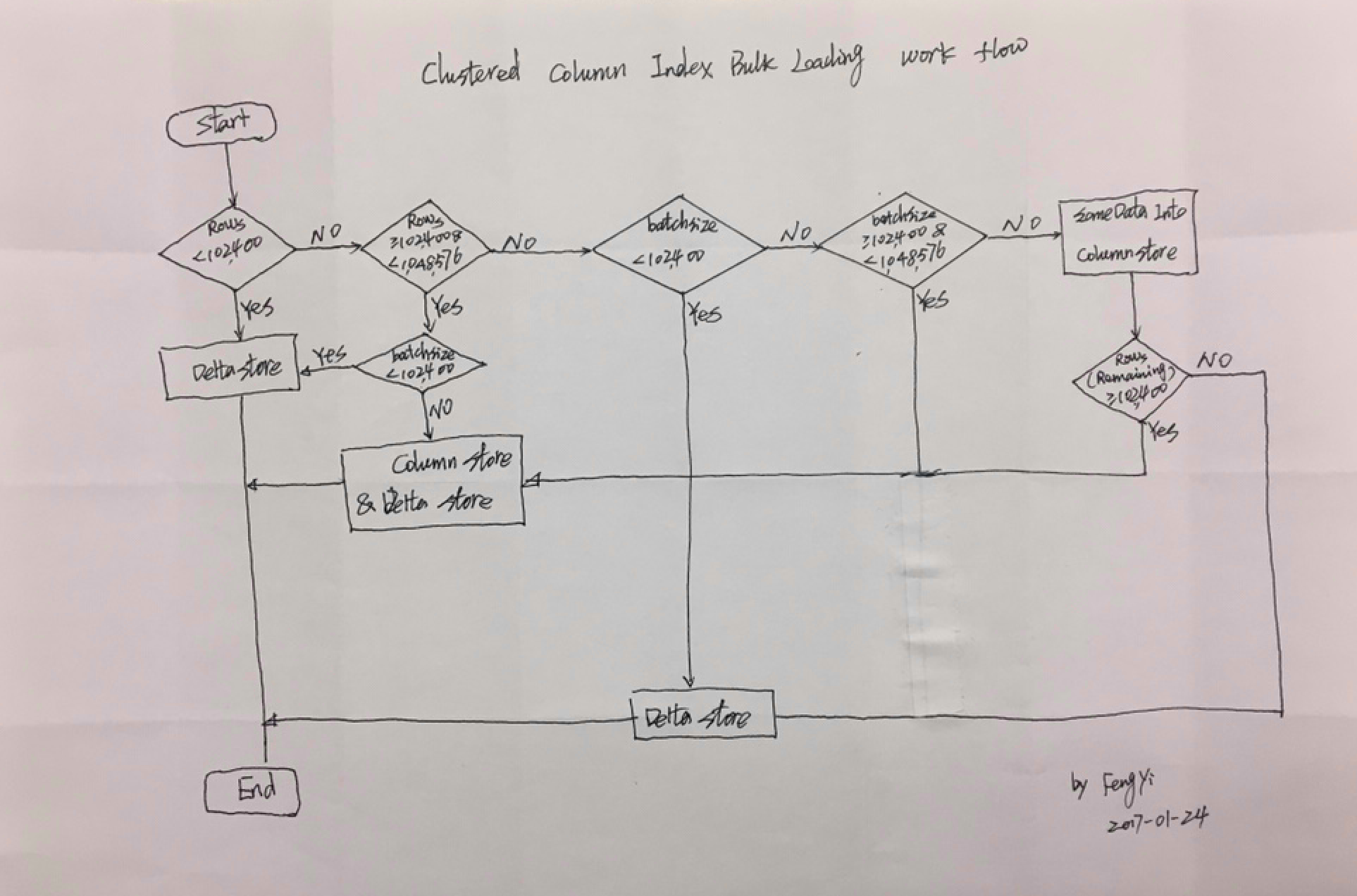
理论解释了,伪代码写好了,流程图也手绘了,接下来测试三种场景的Bulk LOADING。
创建测试环境
准备测试数据库、临时存储过程、需要用到的三个数据文件。
-- Create testing database
IF DB_ID('ColumnStoreDB') IS NULL
CREATE DATABASE ColumnStoreDB;
GO
USE ColumnStoreDB
GO
-- create temp procedure
IF OBJECT_ID('tempdb..#UP_ReCreateTestTable', 'P') IS NOT NULL
BEGIN
DROP PROC #UP_ReCreateTestTable
END
GO
CREATE PROC #UP_ReCreateTestTable
AS
BEGIN
SET NOCOUNT ON
-- create demo table SalesOrder
IF OBJECT_ID('dbo.SalesOrder', 'U') IS NOT NULL
BEGIN
EXEC('DROP TABLE dbo.SalesOrder')
END
CREATE TABLE dbo.SalesOrder
(
OrderID INT NOT NULL
,AutoID INT NOT NULL
,UserID INT NOT NULL
,OrderQty INT NOT NULL
,Price DECIMAL(8,2) NOT NULL
,UnitPrice DECIMAL(19,2) NOT NULL
,OrderDate DATETIME NOT NULL
);
CREATE CLUSTERED COLUMNSTORE INDEX CCI_SalesOrder
ON dbo.SalesOrder;
END
GO
三个数据文件,分别存在102399、204803和2199555条记录,使用BCP从上一期测试环境SQL Server 2012数据库导出,BCP导出脚本如下:
BCP "SELECT TOP 102399 * FROM ColumnStoreDB.dbo.SalesOrder" QueryOut "Scenario1.102399Rows" /c /T /S CHERISH-PC\SQL2012
BCP "SELECT TOP 204803 * FROM ColumnStoreDB.dbo.SalesOrder" QueryOut "Scenario2.204803Rows" /c /T /S CHERISH-PC\SQL2012
BCP "SELECT TOP 2199555 * FROM ColumnStoreDB.dbo.SalesOrder" QueryOut "Scenario3.2199555Rows" /c /T /S CHERISH-PC\SQL2012
测试需要的环境至此准备完毕。
Rows小于102400
这个场景需要总共需要导入的数据量为102399条,小于102400条记录数,所以数据无法直接进入Column Store结构Row Group中。
-- Scenario 1 : BULK LOADING ROWS: 102399 = 102400 - 1
EXEC #UP_ReCreateTestTable
BEGIN TRAN Scenario1
BULK INSERT dbo.SalesOrder
FROM 'C:\Temp\Scenario1.102399Rows'
WITH (
BATCHSIZE = 102400
,KEEPIDENTITY
);
SELECT *
FROM sys.column_store_row_groups
WHERE object_id = object_id('dbo.SalesOrder','U')
ORDER BY row_group_id DESC;
SELECT
database_name = DB_NAME(resource_database_id)
,resource_type
,resource_description
,request_mode
,request_type
,request_status
--,*
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
ROLLBACK TRAN Scenario1
-- END Scenario 1
执行结果如下:

从展示的结果来看,Rows为102399条数据数小于Row Group进入Column Store的最小值102400。所以数据直接进入了Delta Store结构,并且数据在Bulk Insert的时候,会对表对应的Row Group加上X锁。
Rows大于等于102400小于1048576
这个场景需要总共导入204803条记录。
-- Scenario 2 : BULK LOADING ROWS: 204803 = 102400 * 2 + 3
EXEC #UP_ReCreateTestTable
BEGIN TRAN Scenario2
BULK INSERT dbo.SalesOrder
FROM 'C:\Temp\Scenario2.204803Rows'
WITH (
BATCHSIZE = 102400 -- 102400 / 102401
,KEEPIDENTITY
);
SELECT *
FROM sys.column_store_row_groups
WHERE object_id = object_id('dbo.SalesOrder','U')
ORDER BY row_group_id DESC;
SELECT
database_name = DB_NAME(resource_database_id)
,resource_type
,resource_description
,request_mode
,request_type
,request_status
--,*
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
ROLLBACK TRAN Scenario2
-- END Scenario 2
执行结果展示如下:
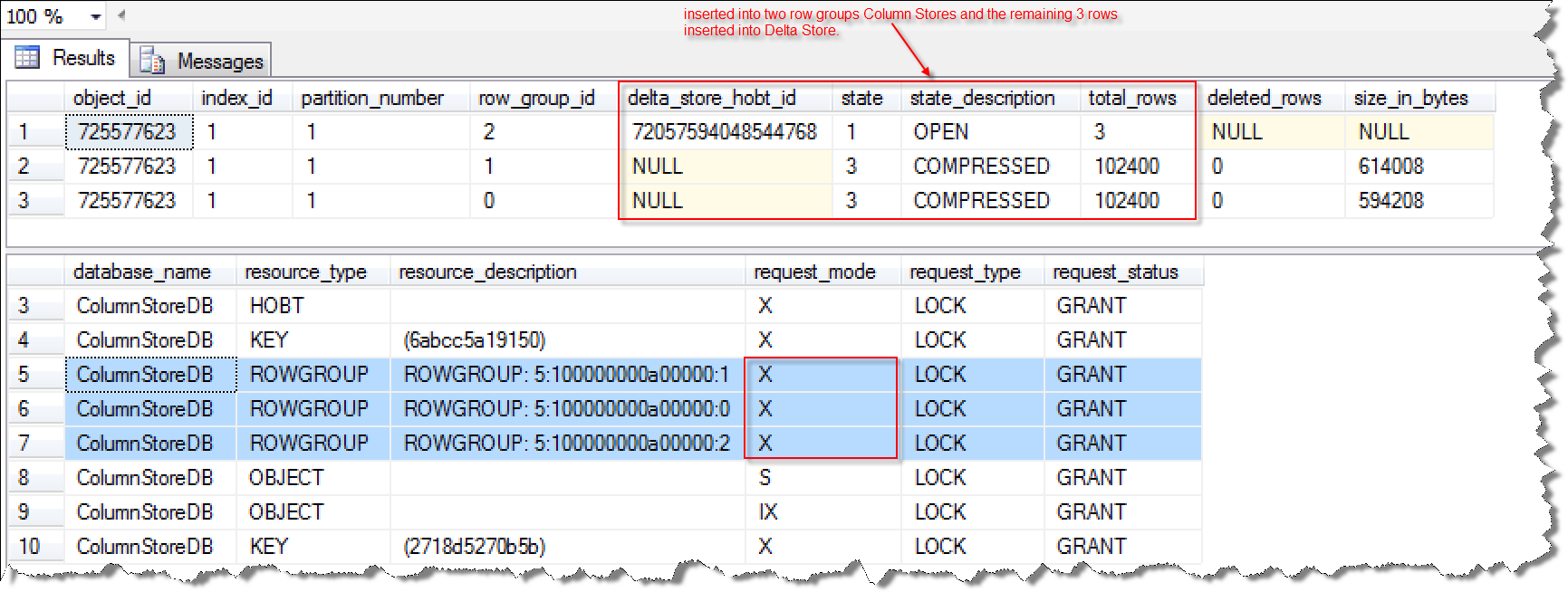
总的记录数Rows为204803 = 102400 * 2 + 3 超过102400并且Batch Size是大于等于102400的,所以,最后数据会插入到Column Store的2个Row Groups,剩下的3条数据进入Delta Store存储结构,在数据导入过程中,对三个Row Group加了X锁。
Rows大于等于1048576
这种情况相对来说是最为复杂的,我们以Bulk Insert 2199555 (等于1048576 * 2 + 102400 + 3)条记录,BatchSize分别102399和1048577为例。
-- Scenario 3 : BULK LOADING ROWS: 2199555 = 1048576 * 2 + 102400 + 3
EXEC #UP_ReCreateTestTable
BEGIN TRAN Scenario3
BULK INSERT dbo.SalesOrder
FROM 'C:\Temp\Scenario3.2199555Rows'
WITH (
BATCHSIZE = 102399 -- 102399 / 1048577
,KEEPIDENTITY
);
SELECT *
FROM sys.column_store_row_groups
WHERE object_id = object_id('dbo.SalesOrder','U')
ORDER BY row_group_id DESC;
SELECT
database_name = DB_NAME(resource_database_id)
,resource_type
,resource_description
,request_mode
,request_type
,request_status
--,*
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
ROLLBACK TRAN Scenario3
-- END Scenario 3
当BatchSize为102399时,执行结果展示如下:
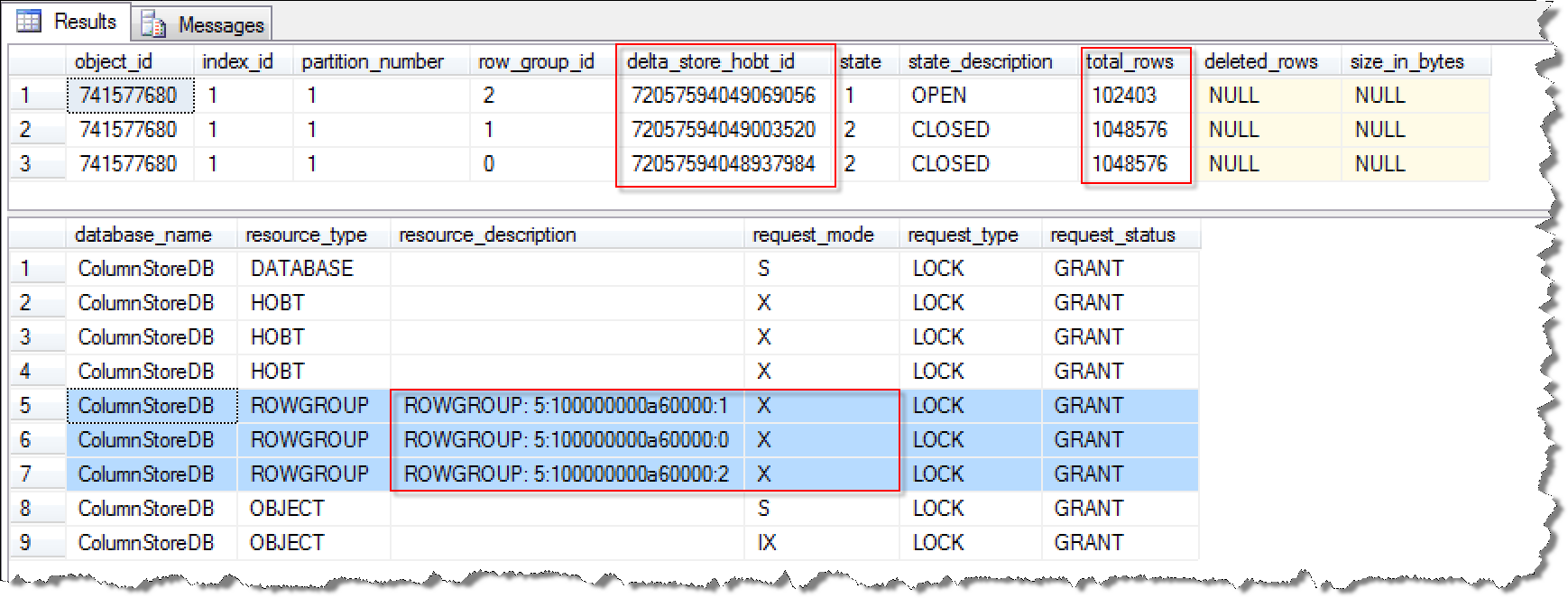
从这个结果来看,当BatchSize小于102400时,所有的数据Bulk插入操作都是进入Delta Store结构(后台进程Tuple Mover会将Delta Store结构中数据迁移到Column Store结构)。由于数据不是直接进入Column Store结构,而是全部数据聚集在Delta Store结构中(Delta Store是传统的B-Tree)。根据之前的介绍,这个时候的用户查询操作,系统会取Column Store和Delta Store两者中的数据,势必会给Delta Store带来巨大读取压力。因为,这部分新插入的200多万条数据无法使用列存储的优势,还是必须走传统的B-Tree结构查询。 如果调大BatchSize的值为比Row Group中可以存放的最大记录数还大。BatchSize为1048577的执行结果展示如下:
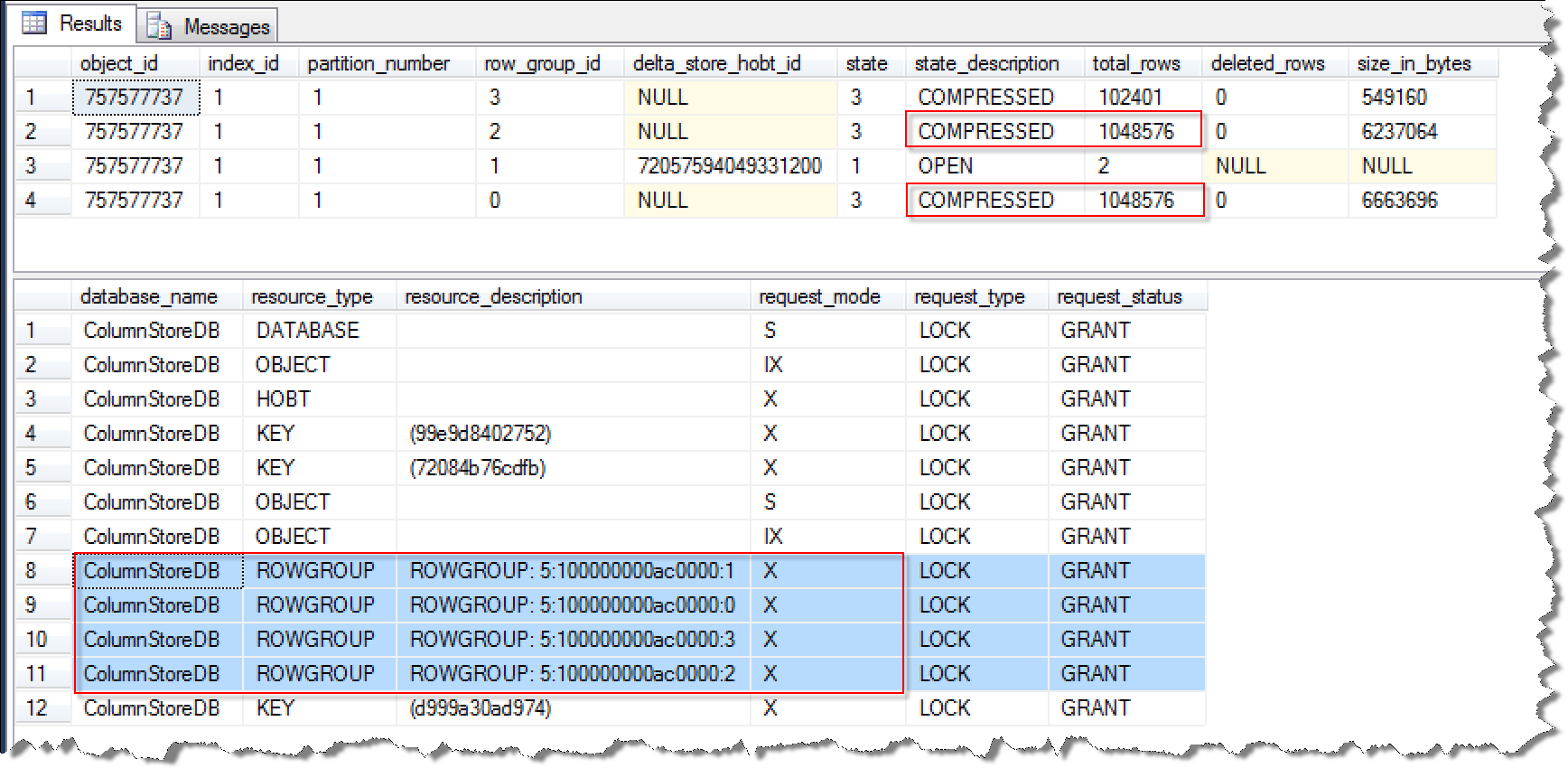
从这个结果分析可以得出结论,当BatchSize修改为1048577后,Bulk Insert操作的数据会直接进入Column Store,形成三个Row Group,而不是暂存在Delta Store结构中,仅剩下2条数据存放在Delta Store中。让我们来看看这个结果到底是怎么形成的,首先分解下总的记录数2199555,拆开来可以表示为:1048576 * 2 + 102400 + 3,换句话说,当BatchSize设置为1048577时,我们每个Row Group中可以直接存放1048576条记录,剩下的102403条记录也满足Row Group存放的最小记录数,SQL Server取了102401条放入Column Store,最后余下2条不满足Row Group存放的最小记录数,所以存放到了Delta Store结构中。这样做可以最大限度的发挥Column Store的优点,而避免Delta Store B-Tree查询的缺点,从而最大限度的提升查询性能。
Bulk Insert总结
Bulk Insert操作总结,如果总的记录数Rows小于102400,所有的数据记录直接进入Delta Store;如果总的记录数大于等于102400,但小于1048576,并且Batch Size也大于等于102400,绝大多数数据会进入Column Store,少量会进入Delta Store;如果总的记录数大于等于1048576,并且Batch Size也大于等于102400,绝大多数数据会进入Column Store,少量会进入Delta Store,最优的Batch Size值是1048576,使得压缩的Column Store中每个Row Group可以存放最多的数据记录数。
限制条件
相对于SQL Server 2012列存储索引表的限制而言,详情参见SQL Server · 特性分析 · 2012列存储索引技术,SQL Server 2014聚集列存储索引的限制有了很大改进的同时,也加入了新的限制。
限制改善
SQL Server 2014列存储索引相对于SQL Server 2012,有了不少的改善,比如:
-
SQL Server 2014既支持Nonclustered Columnstore Index也指出Clustered Columnstore Index,并且Clustered Columnstore Index表支持DML可更新操作。使得列存储索引使用的范围和场景大大增加。
-
开始支持二进制类型:binary(n)、varbinary(n),但不包varbinary(max)。
-
支持精度大于18位的decimal和numeric数据类型。
-
支持Uniqueidentifier数据类型
-
Change tracking:Clustered Columnstore Index表支持;而Nonclustered Columnstore Index表不支持,因为表之只读的。
-
Change data capture:Clustered Columnstore Index表支持;而Nonclustered Columnstore Index表不支持,因为表是只读的。
新增限制
SQL Server 2014同样也新增了不少的限制,比如:
-
整个表仅允许建立一个聚集列存储索引,不允许再有其他的索引。
-
聚集列存储索引表不支持Linked Server,链接服务器不可访问聚集列存储索引表;非聚集列存储索引表是支持链接服务器的。
-
聚集列存储索引没有对数据做任何排序。按照常理,“聚集”类型意味着数据排序,但聚集列存储索引表是没有按照任何列物理排序的,这个需要特别注意。
-
聚集列存储索引表不支持游标和触发器;非聚集列存储索引表是支持游标和触发器的。
Readable secondary:在SQL Server 2014 AlwaysOn 场景中,Clustered Columnstore Index不支持secondary只读角色;Nonclustered Columnstore Index支持secondary只读角色