PgSQL · 特性分析 · 数据库崩溃恢复(上)
Author: 卓刀
背景
为了合并I/O提高性能,PostgreSQL数据库引入了共享缓冲区,当数据库非正常关闭,比如服务器断电时,共享缓冲区即内存中的数据就会丢失,这个时候数据库操作系统重启时就需要从非正常状态中恢复过来,继续提供服务。本文将具体分析在这种情况下,PostgreSQL数据库如何从崩溃状态中恢复。
上期月报PgSQL · 特性分析 · checkpoint机制浅析中介绍了PostgreSQL中的checkpoint机制。其中提到,当PostgreSQL数据库崩溃恢复时,会以最近的checkpoint为基础,不断应用这之后的XLOG日志。为了更好地理解PostgreSQL数据库从崩溃中恢复的过程,我们需要弄清楚以下几个问题:
- 数据库操作系统如何识别到自己是非正常状态(崩溃状态)
- 数据库如何找到合适的checkpoint作为基础
- 为什么应用XLOG日志可以恢复数据库数据
- 数据库如何应用XLOG日志
数据库状态
在PostgreSQL中,把数据库分为以下几种状态:
typedef enum DBState
{
DB_STARTUP = 0,/*数据库启动*/
DB_SHUTDOWNED,/*数据库正常关闭*/
DB_SHUTDOWNED_IN_RECOVERY,/*数据库在恢复时关闭*/
DB_SHUTDOWNING,/*数据库启动到正常关闭过程中崩溃*/
DB_IN_CRASH_RECOVERY,/*数据库在恢复过程中崩溃*/
DB_IN_ARCHIVE_RECOVERY,/*数据库处于归档恢复*/
DB_IN_PRODUCTION/*数据库处于正常工作状态,等待接受事务处理*/
} DBState;
PostgreSQL的数据库状态被存储在pg_control文件中,可以执行pg_controldata命令,查看当前的数据库状态,返回结果如下:
pg_control version number: 942
Catalog version number: 201409291
Database system identifier: 6403125794625722170
Database cluster state: shut down
...
其中 Database cluster state: shut down指明当前数据库的状态为DB_SHUTDOWNED,即正常关闭状态。
pg_control文件由对应的结构体ControlFileData存储,ControlFileData数据结构如下:
typedef struct ControlFileData
{
uint64 system_identifier; /*唯一系统标识符——保证控制文件和产生XLOG文件的数据库一致*/
uint32 pg_control_version; /* 标识pg_control的版本*/
uint32 catalog_version_no; /*标识catalog的版本 */
DBState state; /*最后一次操作后的数据库状态 */
pg_time_t time; /*pg_control最近一次更新的时间时*/
...
pg_crc32 crc;
} ControlFileData;
每次PostgreSQL数据库启动时,会读取pg_control文件获取最后一次操作后的数据库状态,如果为非正常关闭状态(DB_SHUTDOWNED),则会执行崩溃恢复逻辑。
checkpoint相关结构
ControlFileData结构
当数据库意识到自己处于崩溃状态后,会去选择一个合适的checkpoint作为基础,不断应用在这之后的XLOG日志。在PostgreSQL中,最近一次检查点的信息会被存储在pg_control文件中,pg_control由对应的结构体ControlFileData存储,ControlFileData数据结构如下:
typedef struct ControlFileData
{
...
XLogRecPtr checkPoint; /*指向最近一次的检查点位置*/
XLogRecPtr prevCheckPoint; /*指向最近一次检查点的前一次检查点的位置*/
CheckPoint checkPointCopy; /*最近一次检查点控制信息的副本*/
XLogRecPtr minRecoveryPoint; /*归档恢复时必须恢复到的最小LSN*/
XLogRecPtr backupStartPoint; /*在线备份时进行的检查点开始LSN*/
XLogRecPtr backupEndPoint; /*在线备份时进行的检查点结束LSN*/
bool backupEndRequired; /* 用于判断是否基于正确的在线备份集恢复*/
TimeLineID minRecoveryPointTLI; /* 必须恢复到的最小时间线 */
...
pg_crc32 crc;
} ControlFileData;
在数据库崩溃恢复过程中,一般会选取最近一次的检查点作为恢复的基础,但是因为一个检查点的时间比较长,所以有可能数据库系统在检查点做完之前崩溃,这样磁盘上的检查点可能是不完全的,所以PostgreSQL数据库会多存储一个检查点的位置,即prevCheckPoint。
在数据库崩溃恢复过程中,PostgreSQL规定了三个在启动之前必须恢复到的最小位点:
- minRecoveryPoint
- 数据库在归档恢复过程中,minRecoveryPoint被更新为最新被刷新到磁盘的LSN。每次数据库启动时必须已经replay该位置的XLOG日志记录。
- backupStartPoint
-
数据库在线备份开始时,会调用pg_start_backup函数执行一次checkpoint,并生成backup_label文件。当使用在线备份集进行恢复时,backupStartPoint就是上述checkpoint记录对应的LSN,当达到了该LSN,该值置为0,在置为0之前,数据库不能启动。该值被记录在backup_label文件中如下,直到在线备份结束,pg_stop_backup将该文件删除。这样就保证了在备份过程中,数据库崩溃了,可以默认从备份开始时的日志检查点开始恢复。
``` START WAL LOCATION: 0/6000020 (file 000000040000000000000006) CHECKPOINT LOCATION: 0/6000020 BACKUP METHOD: pg_start_backup BACKUP FROM: master START TIME: 2017-05-15 10:18:55 HKT LABEL: zhuodao ```
-
- backupEndPoint
- 当数据库从一个备库做的在线备份集进行恢复时,backupEndPoint表示备份结束的LSN,当达到该LSN,该值置为0,在置为0之前,数据库不能启动。
recovery.conf文件
在恢复过程中,用户可以通过使用recovery.conf文件来指定恢复的各个参数,如下:
- 归档恢复设置
- restore_command:用于获取一个已归档段的XLOG日志文件的命令
- archive_cleanup_command:清除不在需要的XLOG日志文件的命令
- recovery_end_command:归档恢复结束后执行的命令
- 恢复目标设置(默认情况下,数据库将会一直恢复到 WAL 日志的末尾)
- recovery_target = ’immediate’:在从一个在线备 份中恢复时,这意味着备份结束的那个点
- recovery_target_name (string):这个参数指定(pg_create_restore_point()所创建)的已命名的恢复点,将恢复到该恢复点
- recovery_target_time (timestamp):这个参数指定恢复到的时间戳
- recovery_target_xid (string):这个参数指定恢复到的事务 ID
- recovery_target_inclusive (boolean):指定是否在指定的恢复目标之后停止(true),或者在恢复目标之前停止 (false);适用于recovery_target_time或者recovery_target_xid被指定的情况;这个设置分别控制事务是否有准确的目标提交时间或 ID 是否将被包括在该恢复中;默认值为 true
- recovery_target_timeline (string):指定恢复到一个特定的时间线
- recovery_target_action (enum):指定在达到恢复目标时服务器应该立刻采取的动作,包括pause(暂停)、promote(接受连接)、shutdown(停止服务器),其中pause为默认动作
- 备库参数设置
- standby_mode(boolean):为on表示作为一个备库,否则不为备库
- primary_conninfo (string):指定备库连接主库的连接字符串
- primary_slot_name (string):通过流复制指定主库的一个复制槽来复制主库数据,如果没有设置primary_conninfo,则此参数无效
- trigger_file (string):指定一个触发器文件,该文件存在可以结束备库的恢复,即升级备库为一个独立的主库
- recovery_min_apply_delay (integer):这个参数允许将恢复延迟一段固定的时间,如果没有指定单位则以毫秒为单位。
如果recovery.conf中同时指定了recoveryTargetXid、recoveryTargetName、recoveryTargetTime时,PostgreSQL会按照RECOVERY_TARGET_XID> RECOVERY_TARGET_NAME > RECOVERY_TARGET_TIME的优先级来获取最终的目标恢复位点。
如果在recovery.conf指定recovery_targetTimeLine为latest,则可以基于当前TimeLineID为起点寻找最新时间线:
- 寻找当前TimeLineID的时间线历史文件“XXX.history”,如果存在则继续寻找,否则错误退出
- TimeLineID是线性增长的,将当前TimeLineID自增1寻找是否存在时间线历史文件,直到不存在对应的时间线历史文件为止,即可找到最新的时间线。
XLOG日志结构
XLOG日志中详细地记录了服务进程对数据库的操作过程。之前的月报PgSQL · 特性分析 · Write-Ahead Logging机制浅析介绍过PostgreSQL WAL机制的实现,下面将具体介绍XLOG日志的组织结构。
概括起来,XLOG日志分为多个XLOG逻辑日志文件,每个逻辑日志文件包含多个XLOG段文件,每个XLOG段文件包含多个XLOG日志页:
- 每个XLOG逻辑日志文件都有一个ID
- 实际XLOG被分为pg_xlog目录下多个大小为16MB的段文件
- 文件名由时间线TimeLineID(8位16进制)、逻辑日志文件号(8位16进制)和段文件ID(8位16进制)组成
- 每个段文件分为多个8KB的页(块)
- 每个页包含一个头部,头部信息之后才是真正的XLOG日志记录
其中,值得注意的是,每个XLOG段文件大小可以在编译时使用–with-wal-segsize参数来指定,每页的大小可以在编译的时使用–with-wal-blocksize参数来指定,接下来主要介绍XLOG日志每页的组织形式。
XLOG日志页的组织形式
在PostgreSQL中,XLOG日志页可以分为以下几部分:
| 组成部分 | 具体含义 |
|---|---|
| PageHeaderData | XLOG日志页面头部信息 |
| XLogRecord | XLog日志记录的头部信息 |
| Data of RMGR | 资源管理器的数据,长度xl_len |
| Backup Block 0 | 备份数据块头部BkpBlock + 块大小的备份数据 |
| Backup Block 1 | 备份数据块头部BkpBlock + 块大小的备份数据 |
| Backup Block 2 | 备份数据块头部BkpBlock + 块大小的备份数据 |
| Backup Block 3 | 备份数据块头部BkpBlock + 块大小的备份数据 |
XLOG日志页头部信息
每个XLOG日志页分为页面头部信息和日志记录,其头部信息XLogPageHeaderData结构如下:
typedef struct XLogPageHeaderData
{
uint16 xlp_magic; /* 校验位,用于识别不同的XLOG版本 */
uint16 xlp_info; /* flag bits, see below */
TimeLineID xlp_tli; /* 页面第一条记录的时间线 */
XLogRecPtr xlp_pageaddr; /* XLOG页面的首地址 */
uint32 xlp_rem_len; /* 前XLOG页面最后一条记录剩余的长度 */
} XLogPageHeaderData;
其中,xlp_info是标志位:
- 0x0001表示该页面包含一个跨页面的记录(上个页面的最后一条记录)
- 0x0002表示该页面为段文件的首个页面,头部是一个长头部
- 0x0004表示该页面备份数据块是可选的
如果当前的页面没有足够的空间来存储一个XLOG日志记录,系统允许将剩余的数据存储到下一个页面,但是XLog日志记录的头部信息,即后文中的XLogRecord是不允许分开存储到两个不同的页面的。
如果该页面为段文件的首个页面,除了上面的标准页面头部信息外,还增加一个长头部用来更精确地定位文件,即XLogLongPageHeaderData:
typedef struct XLogLongPageHeaderData
{
XLogPageHeaderData std; /* 标准页面头部信息 */
uint64 xlp_sysid; /* pg_control 中的系统标识符*/
uint32 xlp_seg_size; /* 段的尺寸 */
uint32 xlp_xlog_blcksz; /* 页(块)的尺寸*/
} XLogLongPageHeaderData;
XLOG日志记录的头部信息
每个XLOG日志页面头部之后才是真正的XLOG日志记录,XLogRecord记录了XLOG的相关数据信息,具体结构如下:
typedef struct XLogRecord
{
uint32 xl_tot_len; /* 整条记录的总长度*/
TransactionId xl_xid; /* 事务ID */
XLogRecPtr xl_prev; /* 上条XLOG日志记录的位置(LSN) */
uint8 xl_info; /* flag bits, see below */
RmgrId xl_rmid; /* 资源管理器ID */
/* 2 bytes of padding here, initialize to zero */
pg_crc32c xl_crc; /* 本记录的CRC校验码 */
/* XLogRecordBlockHeaders and XLogRecordDataHeader follow, no padding */
} XLogRecord;
其中,xl_rmid表示资源管理器ID,在PostgreSQL中,资源管理器根据资源种类,可以分为17类,其分别的ID按照以下顺序分别为0-16:
PG_RMGR(RM_XLOG_ID, "XLOG", xlog_redo, xlog_desc, NULL, NULL)
PG_RMGR(RM_XACT_ID, "Transaction", xact_redo, xact_desc, NULL, NULL)
PG_RMGR(RM_SMGR_ID, "Storage", smgr_redo, smgr_desc, NULL, NULL)
PG_RMGR(RM_CLOG_ID, "CLOG", clog_redo, clog_desc, NULL, NULL)
PG_RMGR(RM_DBASE_ID, "Database", dbase_redo, dbase_desc, NULL, NULL)
PG_RMGR(RM_TBLSPC_ID, "Tablespace", tblspc_redo, tblspc_desc, NULL, NULL)
PG_RMGR(RM_MULTIXACT_ID, "MultiXact", multixact_redo, multixact_desc, NULL, NULL)
PG_RMGR(RM_RELMAP_ID, "RelMap", relmap_redo, relmap_desc, NULL, NULL)
PG_RMGR(RM_STANDBY_ID, "Standby", standby_redo, standby_desc, NULL, NULL)
PG_RMGR(RM_HEAP2_ID, "Heap2", heap2_redo, heap2_desc, NULL, NULL)
PG_RMGR(RM_HEAP_ID, "Heap", heap_redo, heap_desc, NULL, NULL)
PG_RMGR(RM_BTREE_ID, "Btree", btree_redo, btree_desc, NULL, NULL)
PG_RMGR(RM_HASH_ID, "Hash", hash_redo, hash_desc, NULL, NULL)
PG_RMGR(RM_GIN_ID, "Gin", gin_redo, gin_desc, gin_xlog_startup, gin_xlog_cleanup)
PG_RMGR(RM_GIST_ID, "Gist", gist_redo, gist_desc, gist_xlog_startup, gist_xlog_cleanup)
PG_RMGR(RM_SEQ_ID, "Sequence", seq_redo, seq_desc, NULL, NULL)
PG_RMGR(RM_SPGIST_ID, "SPGist", spg_redo, spg_desc, spg_xlog_startup, spg_xlog_cleanup)
其中,上述引用代码中PG_RMGR函数的参数依次为:
| 参数名称 | 具体含义 |
|---|---|
| symname | 资源管理器ID |
| name | 资源名称 |
| redo | redo恢复函数 |
| desc | 描述函数 |
| startup | 启动函数 |
| cleanup | 清理函数 |
在PostgreSQL中,用xl_rmid和xl_info高4位来唯一地标示该XLOG日志记录对应的数据库操作,例如事务资源管理器(RM_XACT_ID),对应XLogRecord中xl_info字段高4位:
#define XLOG_XACT_COMMIT 0x00
#define XLOG_XACT_PREPARE 0x10
#define XLOG_XACT_ABORT 0x20
#define XLOG_XACT_COMMIT_PREPARED 0x30
#define XLOG_XACT_ABORT_PREPARED 0x40
#define XLOG_XACT_ASSIGNMENT 0x50
#define XLOG_XACT_COMMIT_COMPACT 0x60
例如元组管理器(RM_HEAP_ID),对应xl_info的高4位:
#define XLOG_HEAP_INSERT 0x00
#define XLOG_HEAP_DELETE 0x10
#define XLOG_HEAP_UPDATE 0x20
/* 0x030 is free, was XLOG_HEAP_MOVE */
#define XLOG_HEAP_HOT_UPDATE 0x40
#define XLOG_HEAP_NEWPAGE 0x50
#define XLOG_HEAP_LOCK 0x60
#define XLOG_HEAP_INPLACE 0x70
xl_info字段是个xl_info低4位表示当前XLOG记录数据块备份的情况:
#define XLR_BKP_BLOCK_MASK 0x0F /* all info bits used for bkp blocks */
#define XLR_MAX_BKP_BLOCKS 4
#define XLR_BKP_BLOCK(iblk) (0x08 >> (iblk)) /* iblk in 0..3 */
当日志记录涉及到的缓冲区Buffer从上个checkpoint后第一次被修改,则将该Buffer备份附加到XLOG日志的备份块iblk中,对应修改xl_info的XLR_BKP_BLOCK(iblk)位。这是为了保证每个写入到磁盘的数据都是完整的页,当写入某个整页的过程中出现崩溃,即写入的页面不是完整的,则可以从XLOG日志中知直接将备份块恢复过来。
除此之外,XLogRecord的xl_crc记录XLOG日志记录的CRC校验,保证写入到磁盘的XLOG记录都是完整的,如果应用不完整的日志记录,PostgreSQL会报错。
XLOG日志记录的资源管理器数据
XLOG日志记录的资源管理器数据由一系列XLogRecData结构体链表组成,之所以要用XLogRecData链,是因为在所要处理的日志记录实体数据在内存空间可能不是连续存储的,而且数据可能分布在多个缓冲区内,需要用XlogRecData链表将它们组织起来。XlogRecData数据结构如下:
typedef struct XLogRecData
{
char *data; /*资源管理器包含数据的开始*/
uint32 len; /*资源管理器包含的数据大小*/
Buffer buffer; /*如果有buffer指明第几个缓冲区*/
bool buffer_std; /*是否含有标准的pd_lower/pd_upper结构*/
struct XLogRecData *next; /*指向下一个结构体*/
} XLogRecData;
其中,buffer_std该值为true,则容许XLOG释放备份页的空闲空间,空闲空间由pd_lower和pd_upper限定:
- pd_lower表示页面起始位置与未分配空间开头的字节偏移
- pd_upper表示页面末尾位置与未分配空间末尾的字节偏移
XLogRecData中data保存每条XLOG日志记录中的数据信息,以INSERT、UPDATE、DELETE为例,XLogRecData中data的大体内容如下(该图引自《Internals Of PostgreSQL Wal》):
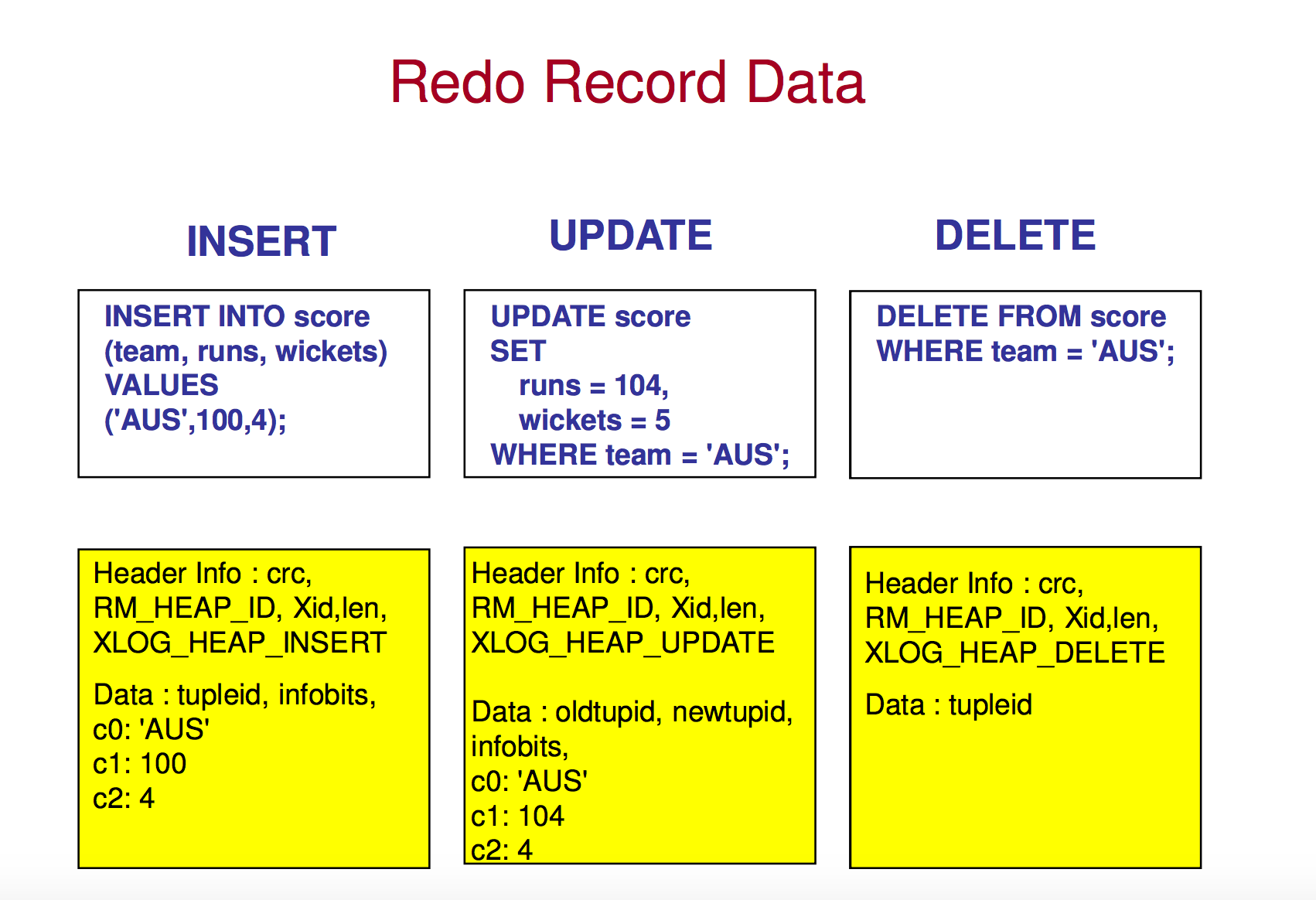
可以看出,根据XLogRecData的信息,我们很容易恢复出对应的数据。
备份数据块
备份数据块包含一个头部信息BkpBlock和一块大小的备份数据,其中BkpBlock结构如下:
typedef struct BkpBlock
{
RelFileNode node; /* 用于唯一标示该块所属的关系表,包括表空间OID,数据库OID,关系表OID等*/
ForkNumber fork; /*一个关系表在存储上可能由多个分支组成,每个分支以文件单独存储,RelFileNode对应关系表的分支号*/
BlockNumber block; /*对应块的块号*/
uint16 hole_offset; /*空洞偏移量*/
uint16 hole_length; /* 空洞长度*/
} BkpBlock;
如果需要备份的块存在空洞,则备份的时候只记录这个空洞的偏移量和长度,但没有实际备份它,从而提高备份效率。
备份数据块头部后紧跟一个块大小的备份数据,该块可以在数据库崩溃恢复时直接恢复。
Redo恢复的具体步骤
每次postmaster进程启动时,都会调用StartupXLOG函数对数据库崩溃进行恢复,由于该过程非常繁琐,为了更好的理解,本文把Redo恢复分为三个阶段:
- Redo恢复前
- Redo恢复中
- Redo恢复后
Redo恢复前
该阶段主要是根据数据库当前状态判断是否需要恢复,如果需要则获取恢复的起始位点以及目标恢复时间线(recoveryTargetTLI);如不需要则正常启动系统。该阶段具体操作如下:
- 读取控制文件pg_control,根据文件中的信息设置恢复参数
- 检查pg_xlog和pg_xlog/archive_status文件夹是否存在
- 读取配置文件recovery.conf,根据文件中的信息设置恢复参数
- 读出时间线历史记录中的时间线列表expectedTLIs,如果recoveryTargetTLI不在时间线列表expectedTLIs中,则系统报错
- 检测是否存在backup_label文件,如果存在,则从备份标记定义的检查点(CHECKPOINT LOCATION)读取检查点的记录到record中 a. 若record不空,则从record中的检查点记录为恢复起始位置,参数InRecovery参数设置为true b. 若record为空,则系统报错
- 如果不存在backup_label文件,读取pg_control文件中的最近一次检查点,并把它的记录读到record中。 a. 若record不空,则从record中的检查点记录为恢复起始位置 b. 若record为空,则读取最近一次检查点的前面一次检查点(prevCheckPoint),并把它的记录读到record中 c. 如果新record不为空,把参数InRecovery参数设置为true,否则系统报错
- 把record记录中的值赋给一个检查点结构体变量checkPoint,checkPoint的nextXid和nextOid赋给共享缓冲区中的变量缓冲区ShmemVariableCache的nextXid和nextOid。把checkPoint的时间线ID赋给ThisTimeLineID
- 在checkPoint的redo指针和undo指针有效的情况下,把参数InRecovery参数设置为true。
- pg_control中数据库状态不是DB_SHUTDOWNED(系统正常关闭)时,把参数InRecovery参数设置为true
- pg_control中参数InArchiveRecovery为真,把参数InRecovery设置为true
- 当参数InRecovery的值为true时,执行恢复
总结起来,在PostgreSQL中,如果启动时遇到以下情况,需要进行恢复操作:
- pg_control中的数据库状态不正常(非DB_SHUTDOWNED)
- pg_control中记录的最新检查点读取不到XLOG日志文件
- 通过指定recovery.conf文件,指定归档恢复
其中第三种情况是用户通过配置文件recovery.conf手动控制恢复过程。
Redo恢复中
上个阶段主要是做Redo恢复之前的准备工作,确定恢复起始的位置,而本阶段主要是基于上个阶段,进行真正的恢复操作:
-
初始化恢复环境,启动各种需要恢复的资源,即调用对应资源管理器的启动函数:
RmgrTable[rmid].rm_startup(); -
设置需要Redo的日志记录的起始位置(离上个阶段checkPoint最近的一条日志记录),把起始位置处的日志记录读入record,进入循环,不断地进行redo操作
a. 如果record不空,从record开始循环执行redo操作,处理完一条需要redo的记录,即调用对应资源管理器的redo操作:
RmgrTable[record->xl_rmid].rm_redo(EndRecPtr, record);b. 如果record为空,不需要进行redo操作
-
读取下一条记录到record中,不断进行redo操作,直到执行到了我们所要求的时间线的位置,或者已经把所有的日志记录中需要redo的record执行完毕
Redo恢复后
这个阶段主要是对Redo恢复的环境进行清理,并启动需要的辅助进程。
- 本次恢复结束之际,确定是否需要再设置一个新的时间线。如果是恢复到某个指定的时间点上而不是全部恢复,则生成一个新的时间线
- 更新XlogCtl控制结构体中的recoveryLastRecPtr
-
当参数InRecovery的值为true时,执行初始环境的清理工作,调用:
RmgrTable[rmid].rm_cleanup(); - 执行CreateCheckPoint,强迫恢复的内容刷到磁盘
- 调用PreaaalocXlogFiles为新日志记录重新分配日志段文件,同时释放日志恢复时申请的内存。调用ShutdownRecoveryTransactionEnvironment关闭恢复环境。再次更新控制结构体ControlFile、Xlogctl等。
- 开始启动clog、prepared transactions需要的资源或环境等内容,为恢复结束后、系统正常运行做准备工作
- startupXlOG结束,系统正常启动
总结
至此,我们分析了PostgreSQL数据库在崩溃时恢复的具体过程,其中具体的Redo恢复过程,实际上是通过资源管理器获取对应的redo函数接口来执行恢复操作,每种资源管理器其处理过程不尽相同,这里我们不再一一介绍,后面的月报我们会去分析各种资源的redo函数具体操作。