PgSQL · 新特征 · PG11并行Hash Join介绍
Author: 雅悯
关键字
Parallelized, Parallel-aware hash joins
摘要
本文将介绍一下PostgreSQL 11 beta 1 新增的全并行Hash join特征。 将给读者介绍一下postgreSQL并行的设计与实现,并分析一下PostgreSQL的全并行hash join的设计与实现细节。
1.0 并行背景简介
PostgreSQL 从9.6版本开始提供并行特征,并在后续的版本中不断的迭代晚上对各种功能的并行支持。

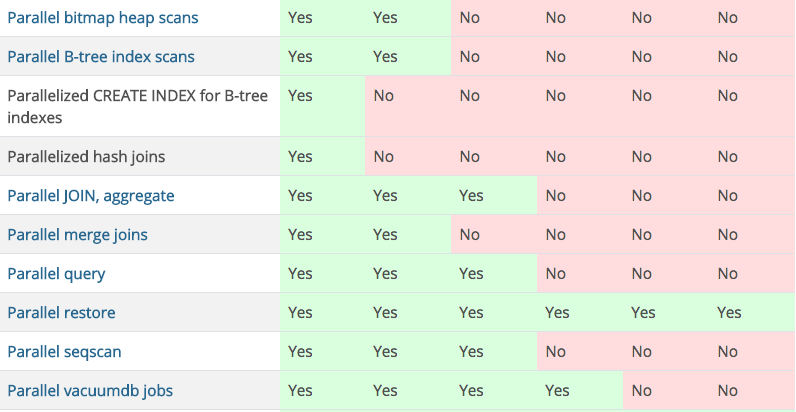
上图:描述并行各个版本中的支持 本文将给主要给大家介绍一下hash join和并行创建索引的实现。
2.0 PostgreSQL并行设计与实现
简单讲PostgreSQL通过在查询计划当中引入gather和gatherMerge算子来决定是否在查询树中开始并行执行的部分。在执行gather或ganterMerge节点的时候,这两个节点就成为起停并行执行的出入口节点。
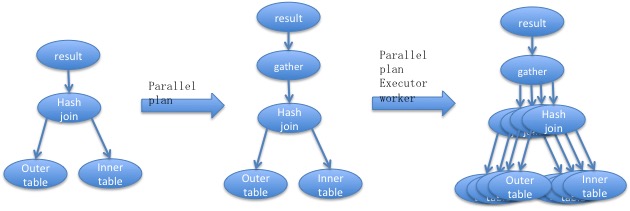
上图显示了查询怎样从原来的执行计划,通过gather节点实现并行执行的演变过程。其中gather是并行分发/汇总节点。gatherMerge是用来实现分发/按顺序汇总执行的节点。在执行的gather节点的时候,它会初始化并行执行所需要的资源,以及并行控制结构。并启动并行worker开始工作,通过共享内存来接受worker返回的数据。
3.0并行Hash Join
关于并行hash join的支持,在之前的版本已经有对hash join的并行支持,但是对于hash join并行并没有做的很彻底。之前只是在外表部分实现了并行。 内表处理是在每一个并行分支上面都做一份完整的hash表。在11版本中实现了内表部分的并行处理。
3.1并行Hash Join实现步骤
3.1.1 Hash Join状态机
并行hash join的实现与非并行的hash join大致上是一致的。可以共用一套状态机如下:
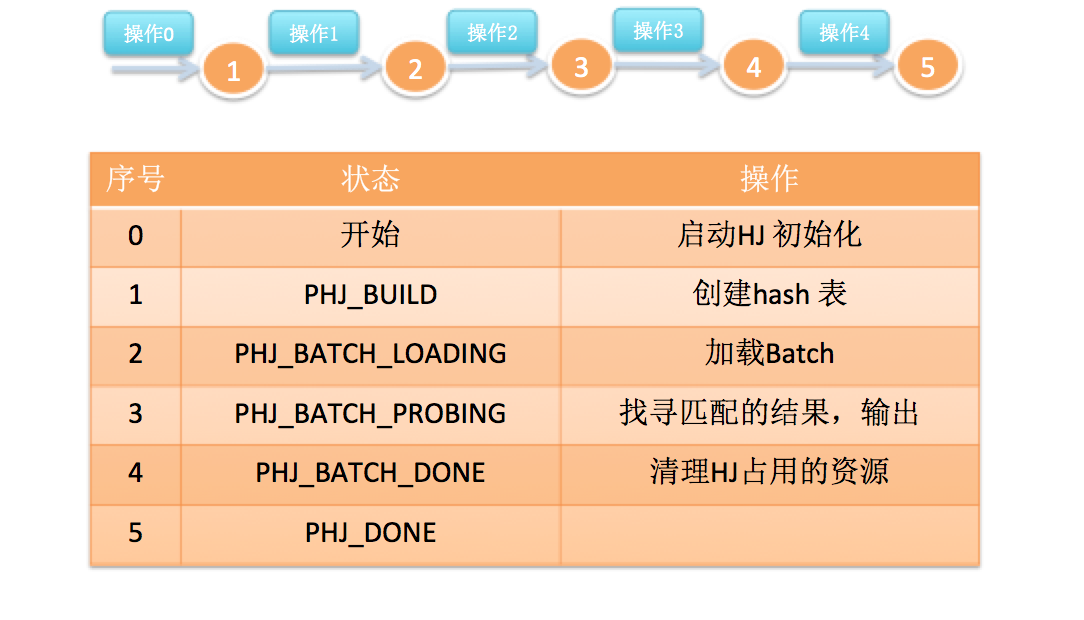
3.1.2 Hash Table状态机
在PostgreSQL 11版本中,主要增加了并行构建hash table的实现。其中关于hash table构建的状态机如下:
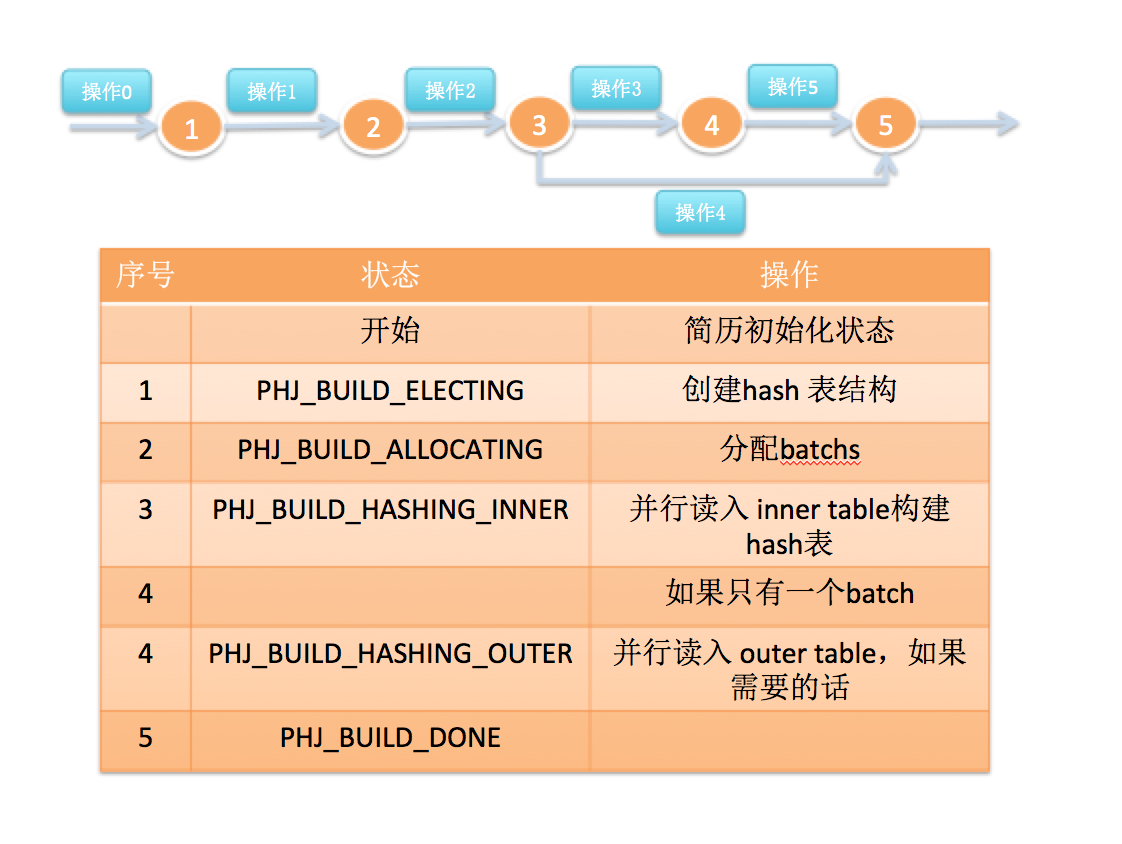
每个参与并行hash join的并行任务,它必须能够知道当前自己已经完成了多少工作,因为并行任务并不需要等待其他任务一同开始。因此在任务的一些关键节点上我们需要同步所有任务的状态,确定所有任务都到这这个点之后,然后启动下一个状态的任务。这里并行用一系列屏障机制来协调并行任务的同步进入下一状态并开始执行。
其中并行Hash INNER步骤根据需要实际数据的大小可能会调整batch和bucket中tuple的数据。状态机如下:
3.1.2.1 Batch扩展:
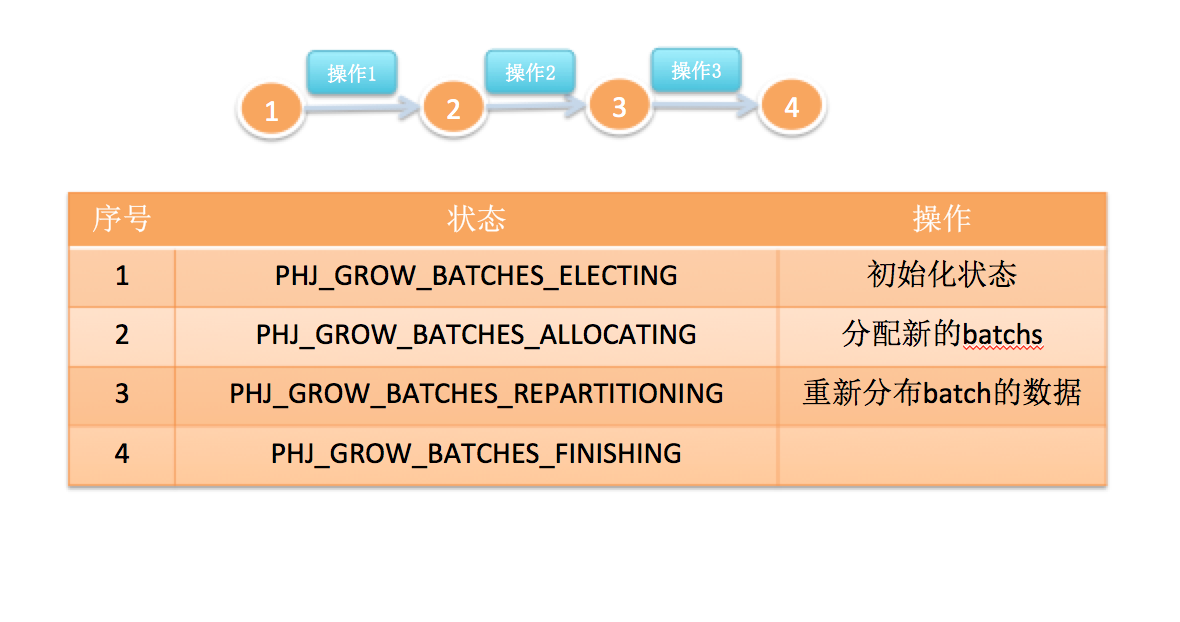
3.1.2.2 Bucket扩展:
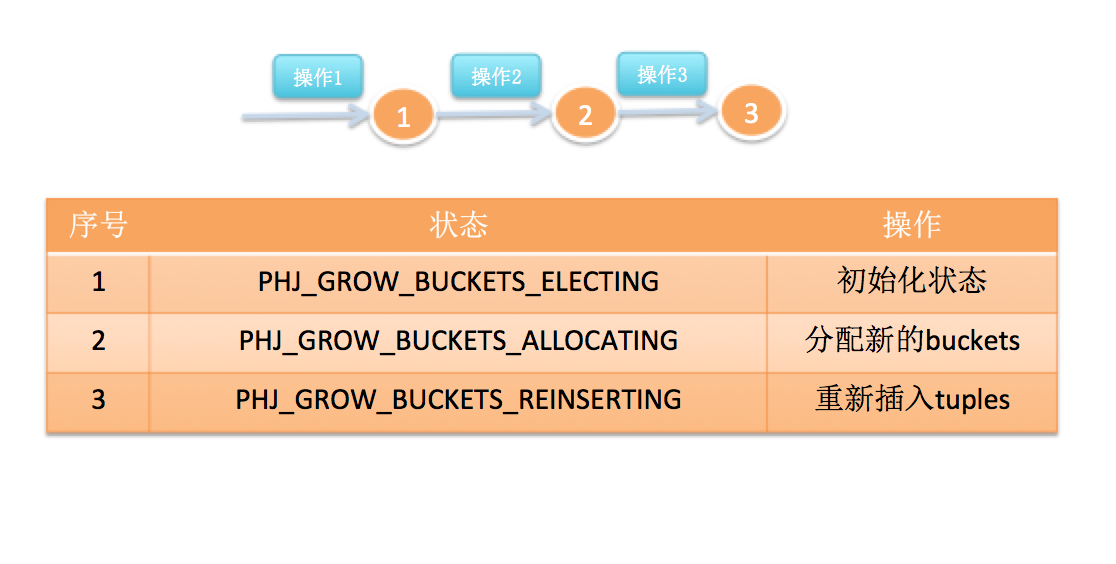 分别使用两组屏障独立处理batch和bucket的扩展;
分别使用两组屏障独立处理batch和bucket的扩展;
3.1.2.3PHJ_BUILD_HASHING_OUTER阶段
关于PHJ_BUILD_HASHING_OUTER阶段,仅仅当多个batch joins的时候会用到,因为这里我们需要讲outer表也按照同样的方式hash到相对应得batch,这样就可以独立的处理每一个batch。
4.0 总结
这篇文章主要是high level的给大家介绍了一下并行全hash join如何实现,后续如果有时间会继续分析更加详细的实现细节。