MySQL · 引擎特性 · IO_CACHE 源码解析
Author: zhuyan
概述
在数据库中 IO 的重要性不言而喻,为了更好的管理 IO 操作,大多数数据库都自己管理页数据和刷脏机制(例如 InnoDB 中的 Buffer pool),而不是交给文件系统甚至是操作系统调度。但是对于顺序写入的日志数据,使用文件系统接口方便的多,文件系统 也是以页的形式管理,呈现给应用层的是一片连续可写的空间,管理的单位称为 Sector 大小是 4KB,所以对于 4KB 对齐的地址读写可以避免跨多个 Sector,对文件系统的性能有很大的提高。MySQL 中的 IO_CACHE 的作用就是把连续的文件读写操作,经过缓冲,转化为 4K 对齐的文件读写操作。
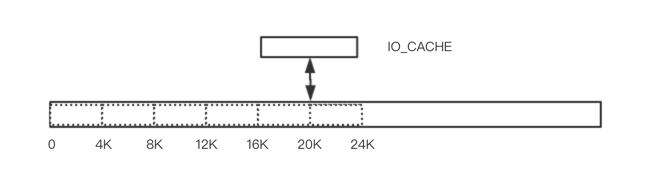
如图所示,对于文件的读写操作如果小于 IO_CACHE 大小,就放到缓冲中,当 IO_CACHE 满了就进行一次 4KB 对齐的写入,如果一次读写超过 IO_CACHE 的大小,就把 4K 对齐的数据进行一次读写,剩余部分放到 IO_CACHE 中,等待下次读写一起合并。
源码解析
IO_CACHE 有不同的类型,定义在 cache_type 中:
enum cache_type
{
TYPE_NOT_SET= 0, READ_CACHE, WRITE_CACHE,
SEQ_READ_APPEND /* sequential read or append */,
READ_FIFO, READ_NET,WRITE_NET};
常用的 general log, slow log, err log, binlog 主要使用 READ_CACHE, WRITE_CACHE, SEQ_READ_APPEND 几种类型,本文主要介绍这几种。同时 IO_CACHE 也提供支持 AIO 的接口,支持多线程同时访问 IO_CACHE 等,目前来看来应用也不多,暂不涉及。
主要代码在 mysys/mf_iocache.c 中,
READ_CACHE 是读缓冲,WRITE_CACHE 是写缓冲,SEQ_READ_APPEND 同时支持读写,写线程不断 append 数据到文件尾,读线程去 read 数据。append 使用 IO_CACHE::write_buffer, read 使用 IO_CACHE::buffer。当读到 write_buffer 中的数据时,就从 write_buffer 中拿数据。SEQ_READ_APPEND 这种类型在 MySQL 复制模块使用,IO 线程负责 append 数据到 relay log,SQL 线程负责 read 出来应用(考虑下为什么在主库上的写入线程和 Dump 线程之间不是使用这种方法,而是简单的 read-write,因为主库上 order_commit 函数很可能成为性能的瓶颈,和 Dump 线程竞争 append_buffer_lock 似乎并不好),因为 SEQ_READ_APPEND 类型更具有代表性,就以这种类型为例介绍。
基础数据结构
基本的结构是 IO_CACHE,代码中注释写的比较清楚,这里贴一下方便后面看,
typedef struct st_io_cache
{
/* Offset in file corresponding to the first byte of uchar* buffer. */
my_off_t pos_in_file;
/*
The offset of end of file for READ_CACHE and WRITE_CACHE.
For SEQ_READ_APPEND it the maximum of the actual end of file and
the position represented by read_end.
*/
my_off_t end_of_file;
/* Points to current read position in the buffer */
uchar *read_pos;
/* the non-inclusive boundary in the buffer for the currently valid read */
uchar *read_end;
uchar *buffer; /* The read buffer */
/* Used in ASYNC_IO */
uchar *request_pos;
/* Only used in WRITE caches and in SEQ_READ_APPEND to buffer writes */
uchar *write_buffer;
/*
Only used in SEQ_READ_APPEND, and points to the current read position
in the write buffer. Note that reads in SEQ_READ_APPEND caches can
happen from both read buffer (uchar* buffer) and write buffer
(uchar* write_buffer).
*/
uchar *append_read_pos;
/* Points to current write position in the write buffer */
uchar *write_pos;
/* The non-inclusive boundary of the valid write area */
uchar *write_end;
/*
Current_pos and current_end are convenience variables used by
my_b_tell() and other routines that need to know the current offset
current_pos points to &write_pos, and current_end to &write_end in a
WRITE_CACHE, and &read_pos and &read_end respectively otherwise
*/
uchar **current_pos, **current_end;
/*
The lock is for append buffer used in SEQ_READ_APPEND cache
need mutex copying from append buffer to read buffer.
*/
mysql_mutex_t append_buffer_lock;
/*
A caller will use my_b_read() macro to read from the cache
if the data is already in cache, it will be simply copied with
memcpy() and internal variables will be accordinging updated with
no functions invoked. However, if the data is not fully in the cache,
my_b_read() will call read_function to fetch the data. read_function
must never be invoked directly.
*/
int (*read_function)(struct st_io_cache *,uchar *,size_t);
/*
Same idea as in the case of read_function, except my_b_write() needs to
be replaced with my_b_append() for a SEQ_READ_APPEND cache
*/
int (*write_function)(struct st_io_cache *,const uchar *,size_t);
/*
Specifies the type of the cache.
*/
enum cache_type type;
/*
Callbacks when the actual read I/O happens. These were added and
are currently used for binary logging of LOAD DATA INFILE - when a
block is read from the file, we create a block create/append event, and
when IO_CACHE is closed, we create an end event. These functions could,
of course be used for other things
*/
IO_CACHE_CALLBACK pre_read;
IO_CACHE_CALLBACK post_read;
IO_CACHE_CALLBACK pre_close;
/*
Counts the number of times, when we were forced to use disk. We use it to
increase the binlog_cache_disk_use and binlog_stmt_cache_disk_use status
variables.
*/
ulong disk_writes;
void* arg; /* for use by pre/post_read */
char *file_name; /* if used with 'open_cached_file' */
char *dir,*prefix;
File file; /* file descriptor */
/*
seek_not_done is set by my_b_seek() to inform the upcoming read/write
operation that a seek needs to be preformed prior to the actual I/O
error is 0 if the cache operation was successful, -1 if there was a
"hard" error, and the actual number of I/O-ed bytes if the read/write was
partial.
*/
int seek_not_done,error;
/* buffer_length is memory size allocated for buffer or write_buffer */
size_t buffer_length;
/* read_length is the same as buffer_length except when we use async io */
size_t read_length;
myf myflags; /* Flags used to my_read/my_write */
/*
alloced_buffer is 1 if the buffer was allocated by init_io_cache() and
0 if it was supplied by the user.
Currently READ_NET is the only one that will use a buffer allocated
somewhere else
*/
my_bool alloced_buffer;
} IO_CACHE;
初始化
初始化函数是 init_io_cache ,主要会做以下几件事:
- 和对应的文件描述符绑定,初始化 IO_CACHE 中各种变量。
- 分配 write_buffer 和 read_buffer 的空间。
- 初始化互斥变量 append_buffer_lock. (对于 SEQ_READ_APPEND 类型而言)
- init_functions 初始化对应的文件读写函数。
其中根据传入的参数 cache_size 分配缓冲空间,一般传入的空间都不算大,例如 Binlog 的 IO_CACHE 初始化传入的大小就是 IO_SIZE(4KB),因为文件系统本身是有 page cache 的,只有调用 fsync 操作才会保证数据落盘,所以 IO_CACHE 就没必要缓冲太多的数据,只做把数据对齐写入的活。但并不是传进来多大空间就分配多大空间,看下代码:
min_cache=use_async_io ? IO_SIZE*4 : IO_SIZE*2;
cachesize= ((cachesize + min_cache-1) & ~(min_cache-1));
for (;;)
{
if (cachesize < min_cache)
cachesize = min_cache;
buffer_block= cachesize;
if (type == SEQ_READ_APPEND)
buffer_block *= 2;
if ((info->buffer= (uchar*) my_malloc(buffer_block, flags)) != 0)
{
info->write_buffer=info->buffer;
if (type == SEQ_READ_APPEND)
info->write_buffer = info->buffer + cachesize;
info->alloced_buffer=1;
break; /* Enough memory found */
}
if (cachesize == min_cache)
DBUG_RETURN(2); /* Can't alloc cache */
/* Try with less memory */
cachesize= (cachesize*3/4 & ~(min_cache-1));
}
最小的分配空间在不使用 AIO 的情况下是 8K,这个后面会用到,SEQ_READ_APPEND 类型会分配两倍空间,因为有读缓冲和写缓冲。如果申请的空间无法满足就试图申请小一点的空间。
init_functions 是根据 IO_CACHE 的类型初始化 IO_CACHE::read_function 和 IO_CACHE::write_function,当缓冲大小没法满足文件 IO 请求的时候就会调用这两个函数去文件中交换数据。
case SEQ_READ_APPEND:
info->read_function = _my_b_seq_read;
info->write_function = 0; /* Force a core if used */
break;
default:
info->read_function = info->share ? _my_b_read_r : _my_b_read;
info->write_function = _my_b_write;
}
SEQ_READ_APPEND 的写直接调用 my_b_append。
调用接口
主要的接口在 include/my_sys.h 文件中,大多是宏定义形式。简单看几个常用的:
#define my_b_read(info,Buffer,Count) \
((info)->read_pos + (Count) <= (info)->read_end ?\
(memcpy(Buffer,(info)->read_pos,(size_t) (Count)), \
((info)->read_pos+=(Count)),0) :\
(*(info)->read_function)((info),Buffer,Count))
从 IO_CACHE info 中读取 Count 个字节到 Buffer 中,read_pos 是当前读到的位置,相对于 IO_CACHE::buffer,read_end 是缓冲区的末尾,这要要注意的是 read_end 相对于 IO_CACHE::buffer 的长度,并不一定是缓冲的长度,因为在读写过程中会调整缓冲区大小做 4K 对齐。逻辑比较简单,如果缓冲区的有效数据长度不够,那么就调用 read_function 做文件 IO。
#define my_b_write(info,Buffer,Count) \
((info)->write_pos + (Count) <=(info)->write_end ?\
(memcpy((info)->write_pos, (Buffer), (size_t)(Count)),\
((info)->write_pos+=(Count)),0) : \
(*(info)->write_function)((info),(uchar *)(Buffer),(Count)))
从 Buffer 中向 IO_CACHE info 写 Count 个字节数据,逻辑类似,如果写入缓冲不够,就做一次文件 IO。
#define my_b_tell(info) ((info)->pos_in_file + \
(size_t) (*(info)->current_pos - (info)->request_pos))
这里 request_pos 是指向 IO_CACHE::buffer 的,而 current_pos 在 setup_io_cache 中初始化为 read_pos 或者 write_pos, 这种设计就可以为不同的 cache type 提供统一的接口。
还有一些非宏定义的接口比如 my_b_seek 等在文件 mysys_iocache2.c 中,不一一介绍,总之文件系统常用的操作在 IO_CACHE 中基本都可以找到。
_my_b_seq_read
以 SEQ_READ_APPEND 类型为例,文件 IO 的函数是 _my_b_seq_read, 整个流程分为三个阶段:
- read from info->buffer
- read from file description
- try append buffer
因为 SEQ_READ_APPEND 类型的读可能会读到 info->write_buffer 中还没来及写到文件系统里的数据,所以第三步就是去写缓冲中读。整个代码的精髓在于计算需要读多少数据才能保证对齐,看下代码:
// 先把 IO_CACHE 里剩下的数据读到 Buffer 里
if ((left_length=(size_t) (info->read_end-info->read_pos))
{
memcpy(Buffer, info->read_pos, left_length);
Buffer+=left_length;
Count-=left_length;
}
//更新 pos_in_file, 如果更新之后超出了 end_of_file, 就去 append_buffer 中读取。
if (pos_in_file=info->pos_in_file +
(size_t)(info->read_end - info->buffer)) > info->end_of_file)
goto read_append_buffer;
// diff_length 为了对齐读
diff_length= (size_t)(pos_in_file &(IO_SIZE-1));
// 第二阶段,从文件里读数据
// 一般 IO_CACHE 默认初始化是 2*IO_CACHE,8KB,这个意思是 Count 的大小已经不能放在一个 IO_CACHE
// 的 Buffer 里
if (Count >= (size_t)(IO_SIZE + (IO_SIZE - diff_length)
{
// 到这里面说明 Count 要读的数据超过了 IO_CACHE 中的 Buffer 大小,直接读到 Buffer
// 那么读多少比较合适呢?
// 取出高阶的 IO_CACHE,整数个。(Count & (size_t)~(IO_SIZAE-1))
// 但是因为 pos_in_file 相对于 4K 对齐地址还有一定的偏移量,再减去这个偏移,保证整个读取是对齐的
length=(Count & (size_t)~(IO_SIZE-1))-diff_Lenght;
if (read_length=mysql_file_read(info->file, Buffer, length..){}
// update after read
Count -= read_lenght;
Buffer += read_leagth;
pos_in_file += read_length;
if(read_length != length)
goto read_append_buffer; // 没有读到想要的长度
left_length += length;
diff_length=0; // no diff length now
}
// IO_CACHE buffer 中还可以读多少数据。
max_length= info->read_length-diff_length;
// 可能会超出文件结尾,需要到 append buffer 读取
if (max_length > (info->end_of_file - pos_in_file)
max_length= (size_t)(info->end_of_file - pos_in_file)
if (!max_length) // 已经到了文件尾
{
if (Count) // 如果还有东西要读
goto read_append_buffer; 去 append buffer 读
}else // 还可以读一些东西
{
// 读到 info->buffer 里,max_length 要么读到真实文件尾,要么读到 read buffer的尽头
length= mysql_file_read(info->file, info->bufffer, max_length);
if (lenth < Count) 还有东西要读
{
goto read_append_buffer;
}
}
return 0;
read_append_buffer:
{
// 先看 append buffer 剩余多少空间
size_t len_in_buffer = (size_t)(info->write_pos - info->append_read_pos);
// 取其精华
copy_len= MY_MIN(Count, len_in_buffer);
memcpy 到 BUffer
/* Fill read buffer with data from wirte buffer*/
}
my_b_flush_io_cache
介绍写之前先介绍下这个函数,它的作用就是把 write_buffer 中数据写到文件系统里,在 IO_CACHE 的操作用这个函数才会真正发生不对齐的 IO,因为要写入的数据已经都在这了,最后的长度谁也没法保证对齐,IO_CACHE 并不会填充一些无意义的数据进去。
if ((length=(size_t)(info->write_pos - info->write_buffer)))
{// length 是写缓冲区中数据的长度
pos_in_file=info->pos_in_file; // 保存一下,后面有用
...
if (!append_cache)
info->pos_in_file += length;
// 这一步是 write_cache 的精华,获得总的 buffer 大小,然后减去当前文件 pos + length
// 之和,剩余部分就是文件中还没有对齐的地方,下一个写入这么大的数据,就可以满足一次对齐写
// 所以当 buffer 比较小的时候,为了满足这种对齐的要求,可使用的 buffer 就会比较小,
// 从而触发更多的文件 IO 操作
info->write_end= (info->write_buffer + info->buffer_length -
(pos_in_file + length) & (IO_SIZE - 1)));
if (mysql_file_wirte(info->file, info->write_buffer, length, info->myflags |
MY_NABP)
info->error= -1;
set_if_bigger(info->end_of_file, (pos_in_file+length));
info->append_read_pos=info->write_pos=info->write_buffer;
....
}
my_b_append
相对于读,append 操作逻辑简单的多,和 _my_b_wirte 逻辑相似
// 和 _my_b_seq_read 互斥,保护 write buffer
lock_append_buffer(info);
rest_length= (size_t)(info->wirte_end - info->write_pos);
// 缓冲区够用
if (Count <= rest_length)
goto end;
// 缓冲区不够用,把剩下的空间写满
memcpy(info->write_pos, Buffer, reset_length);
Buffer += rest_length;
Count -= rest_length;
info->write_pos += rest_length;
// 写满了,刷到文件系统里去
if (my_b_flush_io_cache)
{
...
}
// 如果要写入的太大,缓冲区可能放不下,要直接写到文件里去了。
if (Count >= IO_SIZE)
{
// 写多少到文件里呢,IO_SIZE 以上对齐的部分。
length= Count & (size_t)~(IO_SIZE - 1);
mysql_file_write(info->file, Buffer, length, ..);
Count-=length;
Buffer+=length;
info->end_of_file+=length;
}
end:
// 到这里要么是缓冲区够用,要么是剩下的数据页足够放到缓冲区里
memcpy(info->write_pos, Buffer, (size_t)Count);
info->write_pos += Count;
unlock_append_buffer(info);
return 0;
总结
经过分析,IO_CACHE 是建立的文件系统之上的,把一系列顺序的 IO 操作经过缓冲,转化成 4K 对齐的 IO 操作落到文件系统中,因为文件系统的页缓冲,IO_CACHE 并不大,没有缓冲很多的数据。接口丰富,可以作为一个单独的组件提高文件系统的 IO 性能。