MongoDB · 引擎特性 · 复制集原理
Author: linqing
复制集简介
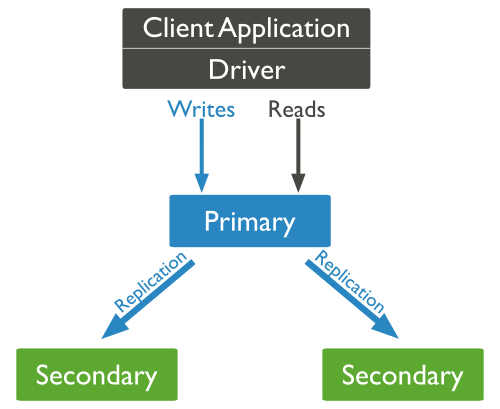
Mongodb复制集由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
下图(图片源于Mongodb官方文档)是一个典型的Mongdb复制集,包含一个Primary节点和2个Secondary节点。
Primary选举
复制集通过replSetInitiate命令(或mongo shell的rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起Priamry选举操作,获得『大多数』成员投票支持的节点,会成为Primary,其余节点成为Secondary。
初始化复制集
config = {
_id : "my_replica_set",
members : [
{_id : 0, host : "rs1.example.net:27017"},
{_id : 1, host : "rs2.example.net:27017"},
{_id : 2, host : "rs3.example.net:27017"},
]
}
rs.initiate(config)
『大多数』的定义
假设复制集内投票成员(后续介绍)数量为N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出Primary,复制集将无法提供写服务,处于只读状态。
| 投票成员数 | 大多数 | 容忍失效数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 4 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
通常建议将复制集成员数量设置为奇数,从上表可以看出3个节点和4个节点的复制集都只能容忍1个节点失效,从『服务可用性』的角度看,其效果是一样的。(但无疑4个节点能提供更可靠的数据存储)
特殊的Secondary
正常情况下,复制集的Seconary会参与Primary选举(自身也可能会被选为Primary),并从Primary同步最新写入的数据,以保证与Primary存储相同的数据。
Secondary可以提供读服务,增加Secondary节点可以提供复制集的读服务能力,同时提升复制集的可用性。另外,Mongodb支持对复制集的Secondary节点进行灵活的配置,以适应多种场景的需求。
Arbiter
Arbiter节点只参与投票,不能被选为Primary,并且不从Primary同步数据。 比如你部署了一个2个节点的复制集,1个Primary,1个Secondary,任意节点宕机,复制集将不能提供服务了(无法选出Primary),这时可以给复制集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
Arbiter本身不存储数据,是非常轻量级的服务,当复制集成员为偶数时,最好加入一个Arbiter节点,以提升复制集可用性。
Priority0
Priority0节点的选举优先级为0,不会被选举为Primary。
比如你跨机房A、B部署了一个复制集,并且想指定Primary必须在A机房,这时可以将B机房的复制集成员Priority设置为0,这样Primary就一定会是A机房的成员。(注意:如果这样部署,最好将『大多数』节点部署在A机房,否则网络分区时可能无法选出Primary)
Vote0
Mongodb 3.0里,复制集成员最多50个,参与Primary选举投票的成员最多7个,其他成员(Vote0)的vote属性必须设置为0,即不参与投票。
Hidden
Hidden节点不能被选为主(Priority为0),并且对Driver不可见。 因Hidden节点不会接受Driver的请求,可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务。
Delayed
Delayed节点必须是Hidden节点,并且其数据落后与Primary一段时间(可配置,比如1个小时)。 因Delayed节点的数据比Primary落后一段时间,当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
数据同步
Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的local.oplog.rs特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用。
因oplog的数据会不断增加,local.oplog.rs被设置成为一个capped集合,当容量达到配置上限时,会将最旧的数据删除掉。另外考虑到oplog在Secondary上可能重复应用,oplog必须具有幂等性,即重复应用也会得到相同的结果。
如下oplog的格式,包含ts、h、op、ns、o等字段
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "100" }
}
上述oplog里各个字段的含义如下
- ts: 操作时间,当前timestamp + 计数器,计数器每秒都被重置
- h:操作的全局唯一标识
- v:oplog版本信息
- op:操作类型
- i:插入操作
- u:更新操作
- d:删除操作
- c:执行命令(如createDatabase,dropDatabase)
- n:空操作,特殊用途
- ns:操作针对的集合
- o:操作内容,如果是更新操作
- o2:操作查询条件,仅update操作包含该字段
Secondary初次同步数据时,会先进行init sync,从Primary(或其他数据更新的Secondary)同步全量数据,然后不断通过tailable cursor从Primary的local.oplog.rs集合里查询最新的oplog并应用到自身。
init sync过程包含如下步骤
- T1时间,从Primary同步所有数据库的数据(local除外),通过listDatabases + listCollections + cloneCollection敏命令组合完成,假设T2时间完成所有操作。
- 从Primary应用[T1-T2]时间段内的所有oplog,可能部分操作已经包含在步骤1,但由于oplog的幂等性,可重复应用。
- 根据Primary各集合的index设置,在Secondary上为相应集合创建index。(每个集合_id的index已在步骤1中完成)。
oplog集合的大小应根据DB规模及应用写入需求合理配置,配置得太大,会造成存储空间的浪费;配置得太小,可能造成Secondary的init sync一直无法成功。比如在步骤1里由于DB数据太多、并且oplog配置太小,导致oplog不足以存储[T1, T2]时间内的所有oplog,这就Secondary无法从Primary上同步完整的数据集。
修改复制集配置
当需要修改复制集时,比如增加成员、删除成员、或者修改成员配置(如priorty、vote、hidden、delayed等属性),可通过replSetReconfig命令(rs.reconfig())对复制集进行重新配置。 比如将复制集的第2个成员Priority设置为2,可执行如下命令
cfg = rs.conf();
cfg.members[1].priority = 2;
rs.reconfig(cfg);
细说Primary选举
Primary选举除了在复制集初始化时发生,还有如下场景
- 复制集被reconfig
- Secondary节点检测到Primary宕机时,会触发新Primary的选举
- 当有Primary节点主动stepDown(主动降级为Secondary)时,也会触发新的Primary选举
Primary的选举受节点间心跳、优先级、最新的oplog时间等多种因素影响。
节点间心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
节点优先级
- 每个节点都倾向于投票给优先级最高的节点
- 优先级为0的节点不会主动发起Primary选举
- 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
Optime
拥有最新optime(最近一条oplog的时间戳)的节点才能被选为主。
网络分区
只有更大多数投票节点间保持网络连通,才有机会被选Primary;如果Primary与大多数的节点断开连接,Primary会主动降级为Secondary。当发生网络分区时,可能在短时间内出现多个Primary,故Driver在写入时,最好设置『大多数成功』的策略,这样即使出现多个Primary,也只有一个Primary能成功写入大多数。
复制集的读写设置
Read Preference
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
- primary: 默认规则,所有读请求发到Primary
- primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
- secondary: 所有的读请求都发到secondary
- secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
- nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
Write Concern
默认情况下,Primary完成写操作即返回,Driver可通过设置[Write Concern(https://docs.mongodb.org/manual/core/write-concern/)来设置写成功的规则。
如下的write concern规则设置写必须在大多数节点上成功,超时时间为5s。
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: majority, wtimeout: 5000 } }
)
上面的设置方式是针对单个请求的,也可以修改副本集默认的write concern,这样就不用每个请求单独设置。
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
异常处理(rollback)
当Primary宕机时,如果有数据未同步到Secondary,当Primary重新加入时,如果新的Primary上已经发生了写操作,则旧Primary需要回滚部分操作,以保证数据集与新的Primary一致。 旧Primary将回滚的数据写到单独的rollback目录下,数据库管理员可根据需要使用mongorestore进行恢复。