POLARDB · 理论基础 · 敢问路在何方 — 论B+树索引的演进方向(上)
Author: zhiyi
前言
B+树是上世纪70年代针对硬盘和单核处理器设计的。为了减少机械硬盘的寻道次数,它采用多叉树结构,降低了索引结构的深度,减少了外存访问延迟对性能的影响。因为B+树在单键值和范围查找操作等方面具有良好的性能,所以它作为索引结构的构建模块,在长达四十多年的各类大型系统发展历程中发挥了极其重要的作用。此外,为了提高B+树在多核处理器场景下的并发性能,学术界/工业界进行了长达数十年的研究。在前文《B+树并发控制机制的前世今生》中,笔者详细分析了latch-based B+树自上世纪70年以来的发展历程。业界在多个角度优化了B+树的并发机制:1. 减小加锁粒度,从索引粒度的S/X锁到树节点粒度的S/X/SX锁;2. 降低加锁频率,利用基于版本号的乐观读机制 + 自底向上的细粒度写锁。因此,B+树的多线程扩展性得到了极大提升。然而,在四十多年的硬件发展历程中,不管是片上处理器的架构设计,还是存储器件的访问特性,都发生了颠覆性的变化。在面对新的硬件特性时,B+树原有的结构设计很大程度上导致它无法发挥出最优的硬件性能,无法榨干所有的硬件红利,这主要表现在两个方面:
多核处理器的迅速发展。随着摩尔定律的逐渐失效,单核处理器的性能无法持续地线性增长,CPU制造商们向多核处理器方向转变。为了发挥出多核处理器的性能优势,索引结构需要设计更加优秀的并发控制机制。然而,现有的latch-based B+树存在两个难以解决的问题:1. 修改树节点的线程需要先持有树节点的锁,锁机制会带来一定程度的堵塞,并且可能导致死锁/活锁等问题;2. 传统B+树的修改操作是本地更新的(In-place),这会导致其它处理器上包含该行数据的缓存行失效,这类开销称之为cache coherence cost。尤其在以NUMA架构为基础的多核处理器平台上,传统in-place更新机制容易引入昂贵的cache coherence cost(具体看前文《B+树并发控制机制的前世今生》)。上述两个问题会随着线程数量的增加变得更加严重,所以传统latch-based B+树依然容易引入性能瓶颈,限制了它的多线程扩展性。存储器件的颠覆性变革。传统磁盘的I/O寻道延迟很高,这导致它的访问延迟(~10ms)远高于内存(~100ns),并且它的随机访问性能远低于顺序访问性能,这对上层软件系统的设计产生了极大的影响。为了解决这一问题,存储器件的演进方向主要包含两类:(1)闪存(Solid State Disk,SSD)将I/O访问延迟降低了三个数量级(~10us),并且它的随机读取性能与顺序读取性能相似;(2)非易失内存(Non-Volatile Main Memory,NVMM)具备传统内存的性能和字节寻址的特性,并且具备磁盘的数据持久性。它将传统的快速易失性内存+慢速持久性外存两层存储架构合并成字节寻址的单层持久性内存架构,这将对上层软件系统的设计产生颠覆性的变化。然而,B+树是针对磁盘设计的,无法完全发挥出新型存储器件的性能优势。
正因此,笔者不禁发问:在处理器和存储器技术迅速发展的今天,B+树的演进方向又在何方?为了解答这个问题,笔者阅读了几十年来数十篇B+树的代表性论文,尝试分析出B+树的未来优化方向,故有此文。本文将从两个方向讨论B+树的发展方向:
多核处理器+闪存场景下B+树的演进方向。Bw树[3]作为范围索引的构建模块,被使用在SQL Server的Hekaton内存OLTP引擎[1,2]。笔者以Bw树为例,详细分析Bw树的索引设计[3]、存储层设计[4]和Bw树在数据库中的实际应用[1,2],并分析它的优势劣势[5]。多核处理器+非易失内存场景下B+树的演进方向。首先,由于非易失内存的特性极大影响了B+树的设计,这会导致B+树结构发生较大的变化,因此笔者先分析单线程场景下B+树的设计与优化[8-12]。其次,笔者将分析多线程场景下B+树的设计。与latch-based B+树不同,笔者将分析一些新的并发控制机制,包括利用硬件事务内存(Hardware Transaction Memory,HTM)的FPTree[11]和Bw树在SCM上的变体latch-free BzTree[13]。
由于篇幅和时间限制,本文着力于讨论多核处理器+闪存场景下B+树的演进方向,而将多核处理器+非易失内存场景下B+树的演进方向放在下一篇文章中分析。本文的部分观点可能尚不完善,读者可根据文章末尾的引用论文,深入阅读相关工作。
多核处理器 + 闪存场景下的B+树
如上文所述,多核处理器+闪存场景下的B+树需要克服多核处理器和闪存特性带来的问题。
- 针对多核处理器的两个瓶颈问题,Bw树提出了相应的解决方案:1. 对于锁带来的扩展性问题,Bw树采用
latch-free的并发控制机制,即通过CAS操作避免锁操作带来的堵塞问题,有效提高了CPU的利用率;2. 针对本地更新带来的cache coherence问题,Bw树通过增量更新操作,避免对数据的本地更新,避免了原数据在其它处理器缓存中的实效问题; - 针对闪存,虽然它将I/O访问性能提升了3个数量级,并且具有性能相似的顺序读写操作/随机读操作,但是它存在一个必须解决的问题:在每次执行更新操作前,它需要执行一个昂贵的块粒度的擦除操作(这里的块粒度远大于文件系统中的页粒度,一个块往往包含64个以上的数据页,因此涉及合法数据页的数据迁移等开销),这导致随机写操作的性能远低于顺序写操作,尤其是小粒度的随机写操作会导致闪存性能/寿命下降十分严重。实验表明,高端FusionIO设备的顺序写操作的性能要比随机写操作快三倍[2]。为了解决这个问题,Bw树采用了
基于日志结构(Log-structured)的存储层,通过append+batch write机制减少随机写操作。
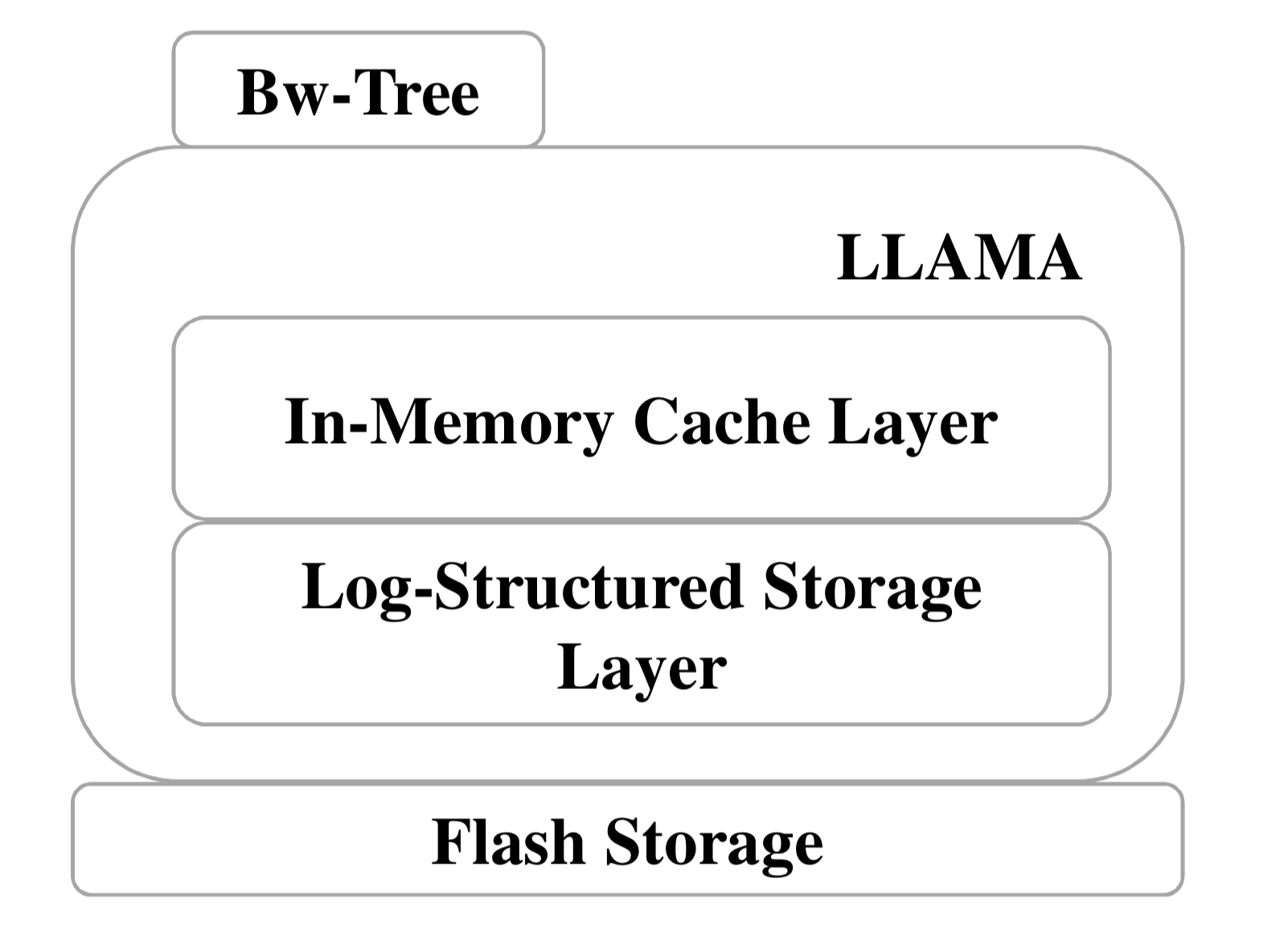
如下图所示,Bw树主要包含以下3个层次:
索引结构层(Bw-Tree),提供供上层应用访问数据的相关接口(CRUDS API,Create/Read/Update/Delete/Range Search),针对内存中的数据页提供latch-free的更新访问机制;缓存层(In-Memory Cache,IMC),提供索引结构层访问的逻辑页抽象,维护内存中逻辑页到闪存中物理页的映射表信息,并且当发生页缺失操作时将数据页从闪存读取到内存中;基于日志结构的存储层(Log-Structured Store,LSS),支持对闪存的顺序写入操作和垃圾回收机制。
IMC和LSS两层构成了LLAMA层,基于LLAMA层构建了Bw树索引结构。值得注意的是,LLAMA层与传统数据库系统的存储层相似(例如MySQL),提供了page粒度的抽象访问接口和内存/外存的交互机制。由于LLAMA层提供的是通用页粒度的接口,在LLAMA层上也可以构建其它索引结构,例如哈希表。在Bw树系列的论文中,分别通过两篇论文描述了Bw树索引结构[3]和LLAMA层[4],本文也会详细分析这两个部分。
Bw树索引结构
Bw树的树节点结构与传统B+树相似,内部索引节点包含有序键值对(键值和指针)指向下一层的树节点,叶节点包含键值对(键值和记录)。此外,每个页还包含:1. low-key,表示能存在这个页上的最小键值信息;2. high-key,表示能存在这个页上的最大键值信息;3. side-link,指向同一层次右边的兄弟节点,与B-link树相似。然而,两种不同的特征使得Bw树区别于传统B+树。
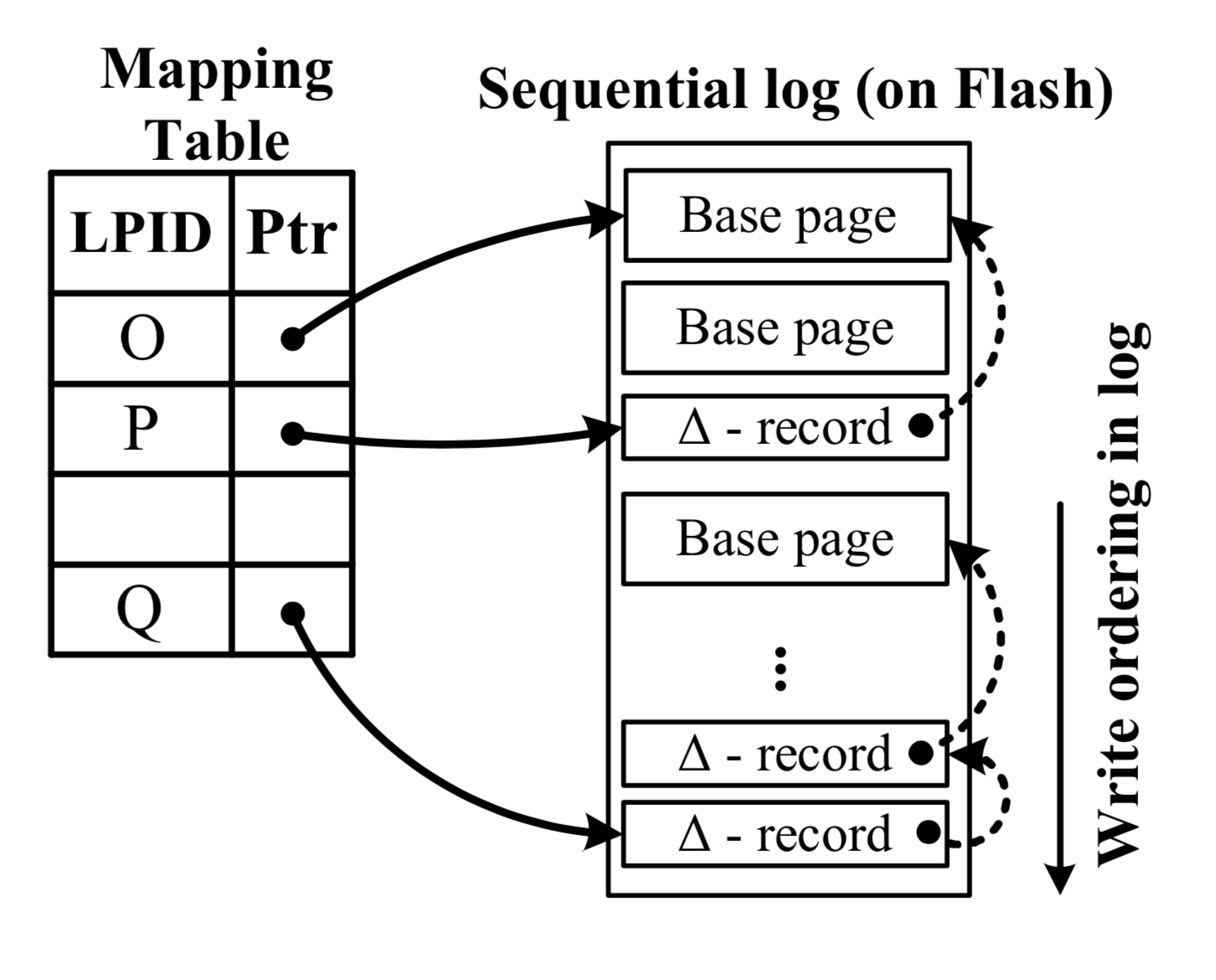
首先,Bw树的树节点是逻辑性的,并不占用固定的物理位置。逻辑地址到物理地址的映射关系,通过键值对的方式存储在Bw的核心模块 - 地址映射表(mapping table)中。如下图所示,地址映射表将数据页的逻辑地址映射到真实的物理地址。逻辑地址通过页描述符PID(page identifier)来表示,而物理地址分为两类数据:1. 闪存地址,表示这个页在闪存中的起始地址;2.内存指针,表示这个页在内存中的起始地址。在Bw树中,树节点与树节点之间的链接关系用PID来表示,而不是物理指针。任何一个访问树节点的操作首先需要访问地址映射表,将PID信息转化成树节点的真实物理地址。因此,在每次更新数据页到闪存的过程中,因为树节点间相连接的PID信息并没有发生变化,所以Bw树不需要更新到树的根节点,它只需要将新的树节点的地址信息更新到地址映射表中。
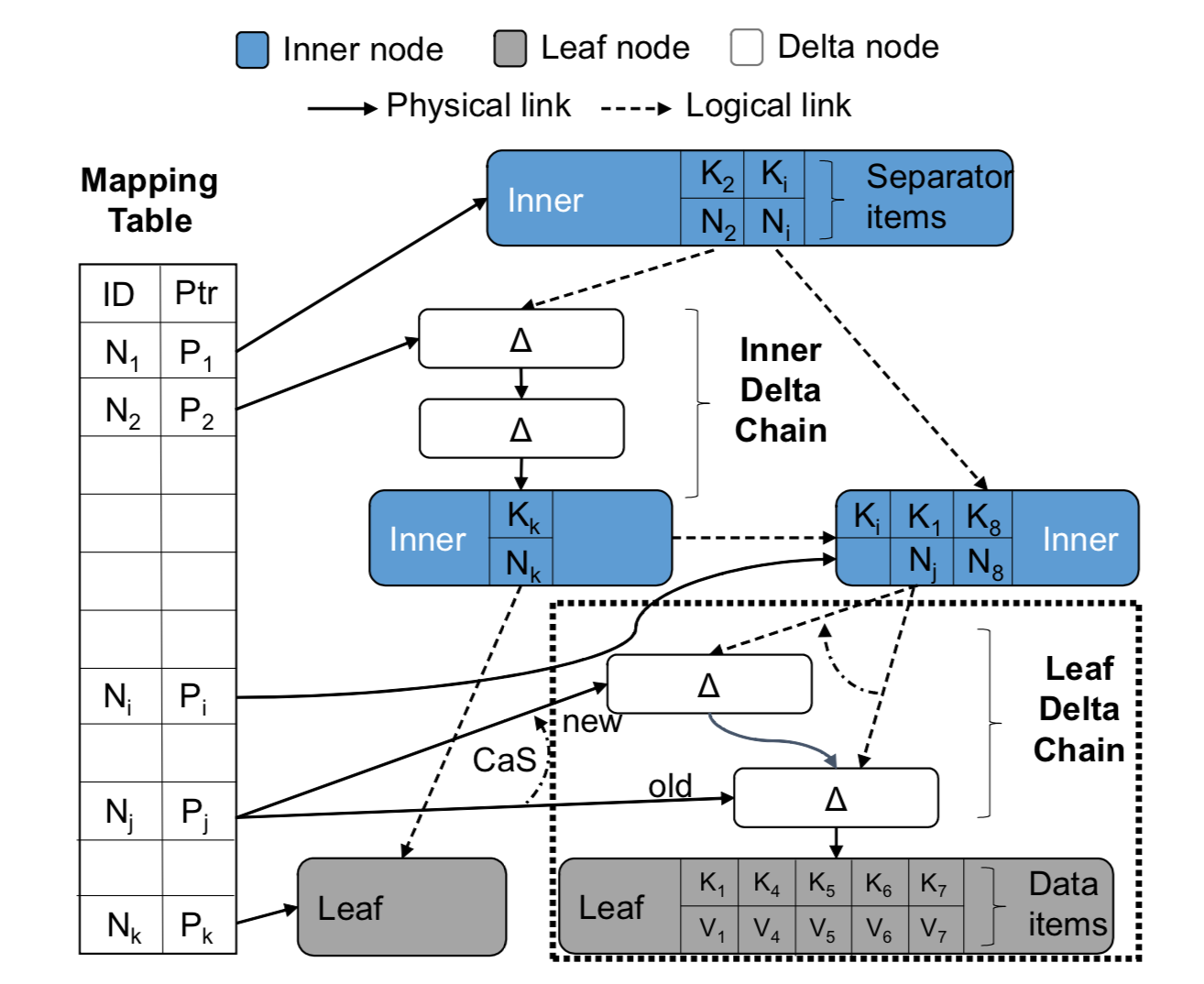
其次,Bw树节点的大小是可伸缩的,这种设计方式使得Bw树在存储真实树节点时具有更高的灵活性。如上图所示,所有的更新操作都不是本地更新的(不会直接修改原数据),而是会创建一个增量记录(delta record,描述修改信息)。每个增量记录包含一个物理指针,指向现存的页数据。然后,Bw树将将增量记录记录到映射表中,增量记录就成为了该数据页的新地址。所以,一个逻辑树节点包含原数据和一系列的增量记录,形成一个单链表结构(delta chain)。这种异地更新机制避免了对处理器缓存中源数据的修改,提高了处理器缓存的效率。此外,这也意味着它没有严格的树节点大小限制,可以在合适的时候再执行分裂操作。下图描述了异地更新所需的关键元信息。


显然,在将增量记录的地址更新到地址映射表前,其它线程不会看到更新操作的中间状态。这一特性使得Bw树可以利用原子操作(Compare-And-Swap,CAS),实现latch-free的树操作。
Bw树的latch-free操作 - 单个树节点的操作
本文首先从最简单的树操作入手,这指的是记录的插入/删除/更新/查询操作,它们只会针对单个数据页产生修改。如下图(a)所示,虚线表示页P的旧地址,实线表示表示更新操作产生的指向原数据的增量记录D。在叶节点层,增量记录包含插入/更新/删除操作三种类型。插入/更新操作的增量记录包含完整的插入信息,而删除操作的增量记录只包含删除的键值信息。此外,每个增量记录包含一个LSN号,这个LSN号将被用于事务恢复机制中,这将在后文中详细叙述。
Bw树利用CAS操作将增量记录的新内存地址记录到映射表中。如果CAS操作成功,这个增量记录就变成了这个数据页的新物理“根”地址,因此就更新了这个页。如果CAS操作失败,这说明有其它线程正在修改这个数据页,所以它会重做该操作。CAS操作保证同时修改该数据页的多个线程中只有一个胜利者,因此保证了操作的正确性。
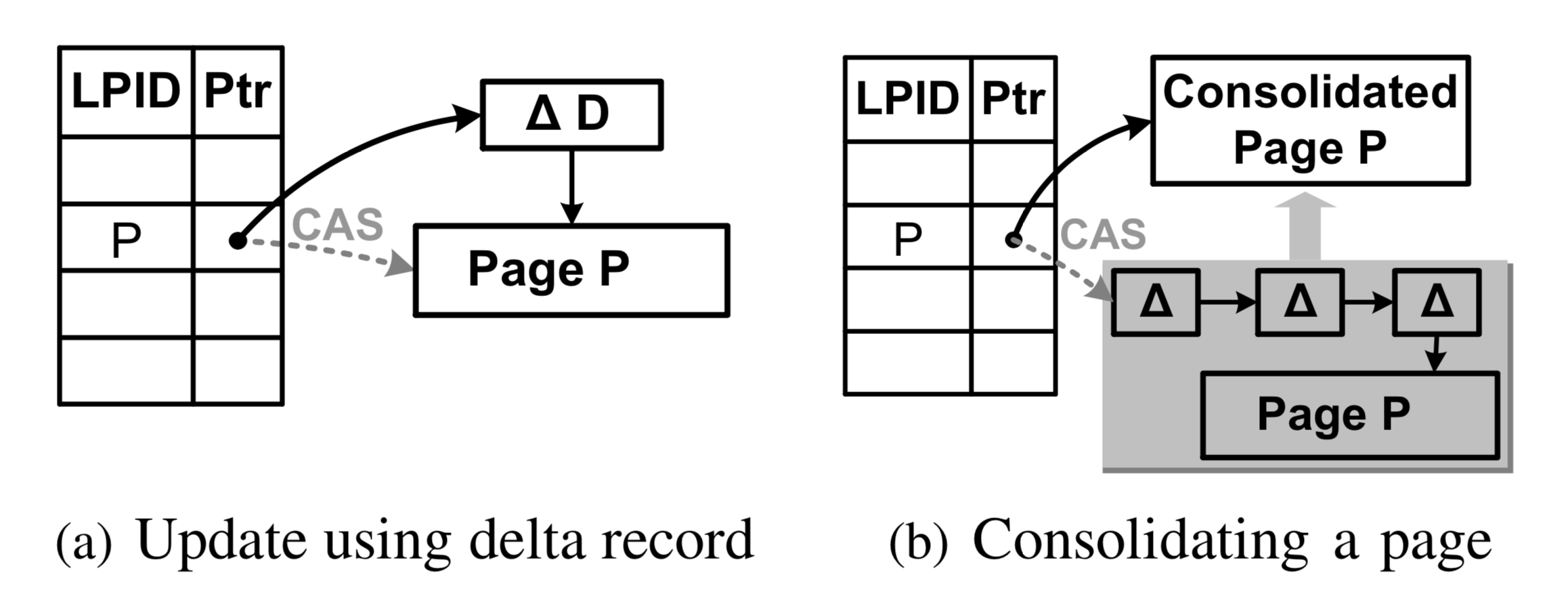
对于页的搜索操作,它需要遍历增量记录链,直到找到第一个目标键值对。如果在增量记录链中没有找到目标键值对,它会在原来的数据页中执行二分查找操作。显然,过长的增量记录链会影响Bw树读操作的性能和存储空间的利用率。所以,当访问增量记录链的操作发现链长超过某个阈值时,它会在执行完操作后执行增量记录链和原数据页的合并操作(consolidate)。
一个页的合并操作同样是通过CAS操作实现的。如上图(b)所示,Bw树执行一个合并操作,虚线表示页P的原地址,而实线表示页P合并后的新地址。Bw树首先创建一个新页,将页P的原数据和所有增量记录合并到这个新页,然后通过CAS操作记录到地址映射表中。如果成功了,它通过垃圾回收,处理原来的页信息和增量记录。如果失败了,说明有其它操作在更新或者合并数据页P,所以该线程会释放新页并放弃这个操作,后续访问该增量记录链的操作会视情况再次执行合并操作。
对于范围查找操作,它往往会指定一个键值范围:(low key,high key)。在Bw树中,范围查找操作会维护一个游标,记录目前搜索的状态信息。当第一次访问包含目标信息的数据页时,Bw树会构建一个记录向量,包含这个页上范围操作所需的所有记录。当该数据页没有被修改时,这可以加速获取下一个键值对信息。当然,在从向量数组中获取记录之前,Bw树会检查是否有其它更新操作影响了这个子查询结果。如果是,Bw树会重建向量数组。
因为Bw树没有用锁保护正在访问的数据对象,所以它也采用epoch-based reclamation机制[7]避免回收正在被访问的数据对象。原理简单来说就是将删除操作分为逻辑删除和物理删除两个步骤,只有在确保一个对象没有被任何操作访问时才可以回收这个对象的物理空间。由于篇幅和时间所限,本文在后续的文章中会单独分析这类垃圾处理机制的原理和实现过程,在此不做赘述,感兴趣的读者可以参考引用[7]这篇文章。
Bw树的latch-free操作 - 多个树节点的操作
Latch-free的并发控制机制不仅使用在单数据页的操作中,而且也用在涉及多个数据页的树节点分裂/合并操作中。当Bw树的逻辑节点大小超出或者低于某个阈值时,这个逻辑节点需要分裂成两个逻辑节点或者与其它兄弟节点合并成一个逻辑节点。这类复杂操作称之为SMO(Index structure modification operation)操作。然而,一个CAS操作无法保证多个数据页的原子性修改。
为了解决这个问题,Bw树借鉴了B-link树的设计,简化了SMO操作(前文《B+树并发控制机制的前世今生》中已经详细分析过B-link树)。以页分裂操作为例,Bw树可以将一个树节点分裂操作分解成两个原子性的“half-split”操作。首先它在子节点层次(叶节点)执行原子性的分裂操作,其次它对父节点执行原子性的插入操作(指向新分裂节点的键值对信息)。如果父节点依然需要分裂,这个过程会可以递归执行。在完成第一次原子性操作后,得益于B-link树结构,即使新分裂的节点还没有插入到父节点中,每个数据页的右指针提供了一种合法的方式去访问新分裂的树节点。具体过程如下:
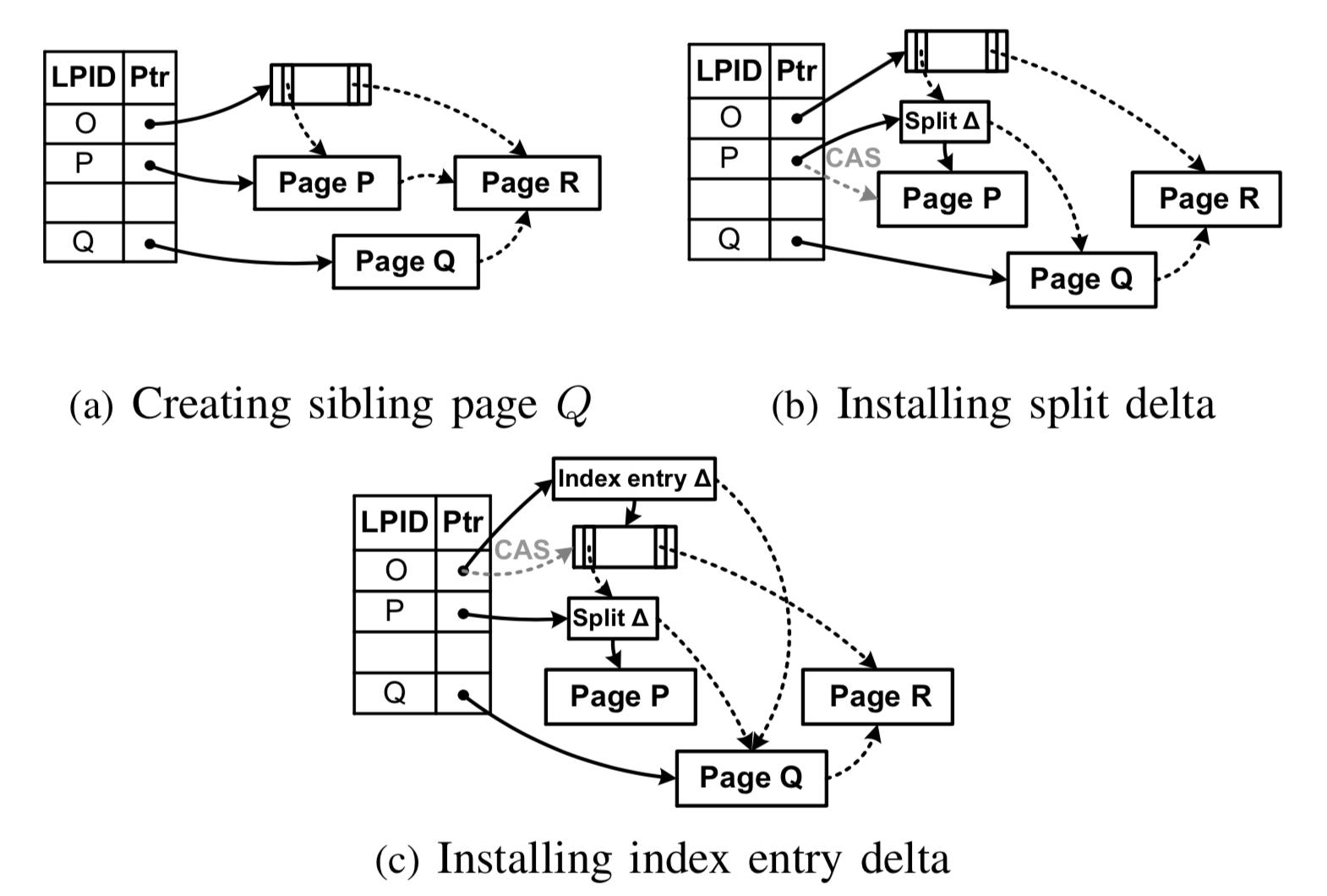
- 子节点的分裂。分为两个步骤:(1) 为了分裂节点P,Bw树会申请一个新节点Q。Q作为P的右兄弟节点, 包含节点P一半的键值对信息,并指向P的原右兄弟节点R。然后,Q的地址信息被记录到地址映射表中。值得注意的是,这个操作不需要使用原子操作(CAS),因为Q目前只会被当前的分裂线程看到。上图(a)中描述了这个场景;(2)修改节点P,删除已经移动到Q的键值对。Bw树会生成一个
分裂增量(split delta),并使用CAS操作加入到节点P的映射表项中。分裂增量包含两部分信息:1. 分裂键值KP,用于表示大于KP的所有键值对已经被移动到其它节点;2. 逻辑指针指向新节点Q。Bw树通过这次CAS操作,判断在split过程中节点P是否被其它线程所修改,如果是则需要重做。自此,Bw树完成了第一个原子操作,上图(b)中描述了这个场景。当上述步骤完成后,即使没有将新的节点Q更新到父节点O中,索引依然是合法的。原因在于所有访问节点Q的数据(键值信息大于KP)的线程首先会访问P,然后根据分裂增量,通过右兄弟指针访问节点Q。 - 父节点的更新。为了让树操作可以直接访问节点Q,Bw树将指向Q的键值对信息插入到P和Q的父亲节点O中,这就是
第二个原子操作。该操作会生成一个索引增量(index delta),它包括:1. 分裂键值KP,用以区分节点P和Q的键值;2. 指向Q的逻辑指针;3.KQ,用以区分节点P和R的键值。Bw树采用和B-link树相似的方式找到父节点(具体看上一篇文章)。即使在父节点被删除的情况,它也能通过epoch-based reclamation判断出父节点的状态,递归到更上层的祖先节点找到合适的父节点。自此,Bw树完成了两个原子操作,上图(c)中描述了这个场景。 因为SMO操作需要2个以上的原子操作,在原子操作之间可能会发生修改相同数据页的更新操作或者其它SMO操作,而SMO操作没有通过锁来避免其它操作看到一个未完成的SMO操作,所以Bw树需要处理SMO操作与有影响的其它SMO/普通更新操作之间的顺序关系,从而使SMO操作整体上像是原子性的。Bw树给出的处理机制是:当某一线程看到未完成的SMO操作时,它会先完成SMO操作,再去执行自己的操作。例如,当其它线程尝试通过兄弟指针访问正确的数据页Q时,它会先完成整个split SMO操作,更新Q的父节点,然后再去执行自己的操作。Bw树通过这种方式,将相互影响的SMO操作与其它操作串行化,避免了很多复杂问题。举两个简单例子:1. 由于Bw树并没有使用锁保护节点P/Q,因此在插入到父节点的过程中,节点P/Q可能被删除,从而导致父节点O指向一个被删除的树节点。通过上述这种方式,这种问题就可以被有效避免。2. 当执行节点P分裂的线程被挂起时,其他线程也可以持续执行,不会因为未完成的P分裂操作而持续等待。这种机制在latch-free的数据结构设计中被广泛使用,称之为the help-along protocol。
此外,当树节点的合法键值对总量少于某个阈值时,它会触发多页之间的合并操作。该操作与分裂操作类似,在此不作赘述,感兴趣的读者可以阅读原文。
LLAMA:缓存/外存子系统
LLAMA层包含IMC和LSS两层,提供了通用的访问接口,可以与Bw树索引结构独立开。LLAMA主要包含以下三类接口:
页粒度的更新访问接口:1. Update-D,将增量更新记录添加到原数据页;2. Update-R,将原数据页替换成一个全新的数据页;3. Read,读取一个数据页,如果数据页不在内存中就会从闪存中读取数据页到内存。区别于Bw树提供的CRUD接口,LLAMA的接口都是为通用性考虑的,所以是页粒度的。页缓存管理接口:1. Flush,将页数据拷贝到I/O缓存中,添加flush增量记录,但不保证数据的持久性;2. Mk-Stable//Hi-Stable,确保数据持久化/获取持久化信息;3. Allocate/Free,分配释放一个新页。用于SMO操作的内部事务接口,这类接口保证涉及多个数据页修改的SMO操作的原子性和持久性。 上层Bw树索引结构通过上述接口完成和LLAMA层的交互。本文并不拘束于讨论如何调用这些接口,下文重点说明LLAMA的原理,系统设计者们也可以根据自己的需求独立使用LLAMA层。
缓存层(In-Memory Cache,IMC)
缓存层负责在内存和闪存之间读取、刷新和交换数据页。它维护了映射表,提供了Bw树中逻辑页的抽象,并将脏页不定期地写回到闪存中。当Bw树通过PID访问某个树节点时,地址映射表记录着树节点的内存地址或闪存地址。后者表示该树节点不在内存中,它需要从闪存中读取数据页到内存中,并通过CAS操作将内存地址记录到地址映射表,并返回内存地址指针。
内存中的树节点在某些场景下需要flush回到闪存中。例如,当Bw树作为事务系统的一部分时,缓存层需要更新数据刷回到闪存中,保证更新数据的持久性。例如,当内存空间不足时,Bw树需要刷出一部分数据,将内存空间留给新数据。flush操作涉及数据页的换出,它会在地址映射表中记录闪存的地址信息,并回收之前占用的内存空间。为了追踪闪存上数据的版本和位置,Bw树为flush操作引入了flush增量记录(flush delta record),它同样通过CAS操作记录到地址映射表中。当页刷新成功时,flush增量记录包含该数据页的新闪存地址。此外,它也标示了该树节点的哪些修改操作被持久化到闪存中,从而后续相同节点的flush操作只需要将后续的增量更新操作持久化到闪存中。此外,LLAMA中维护了flush缓存,只有在缓存中的数据到达一定容量时(论文中默认为1MB)才执行flush操作,减少I/O开销。并且,LLAMA采用了ping-pong双缓存,支持缓存在flush的同时可以准备下一批flush的数据页。
基于日志结构的存储层(Log-Structured Store,LSS)
如下图所示,在闪存上,Bw树采用基于日志结构的方式存储数据,这种方式最早出现在文件系统[6]中。LSS的好处在于,它将分散在内存中同一个树节点的增量记录信息合并成一个顺序写操作,显著减少随机写数量。然而,日志结构也有明显的挑战:系统需要定期回收垃圾数据,回收操作需要将存活数据迁移到日志末尾,这会产生额外的写操作。幸运的是,当每一次执行flush操作时,LSS只将那些变化的增量信息(与上一次页刷新操作的内容相比)写入到闪存中,有效减少了刷新操作带来的写总量。
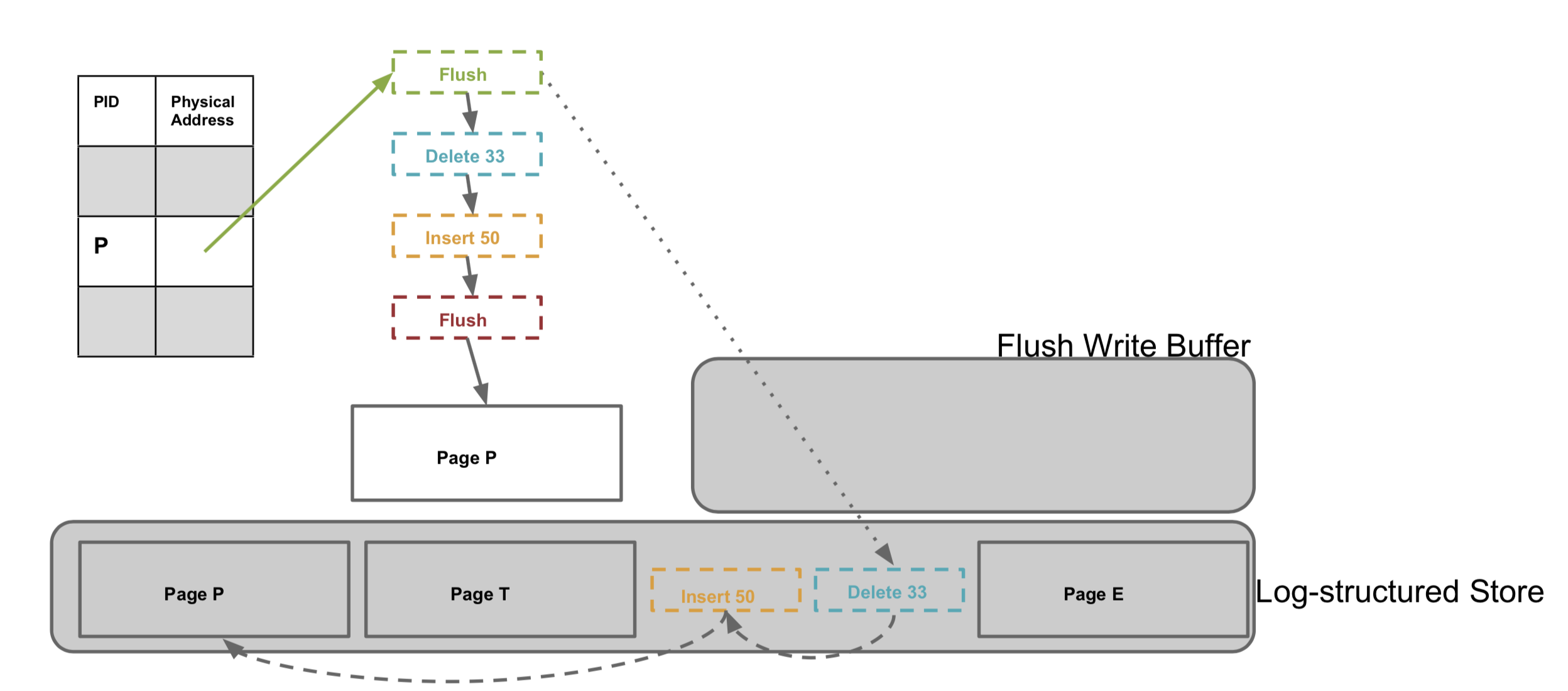
下图显示了基于日志结构的一个例子。一个逻辑页包含了一个基础页和多个增量记录,这与内存中的组织方式类似。因此,闪存上的逻辑页可能在多个不同的物理块设备上,它们相互之间通过文件偏移信息进行连接,就像内存指针一样。因此,一个物理块可能包含来自多个页的record记录信息。这也是LSS与传统Log-structured文件系统最大的不同,只flush增量记录的方式可以提高存储空间利用率,减少写放大。显然,这会增加读操作的成本。然而,由于闪存的随机读操作性能远优于磁盘,这在很大程度上降低了对读操作性能的影响。此外,LSS需要定期清理闪存中旧数据(已被更新或者删除)。为了回收这部分旧空间,LLSS需要将那些存储的数据页移动到日志末尾。LSS也做了一些优化,它在清理旧数据过程中将数据页和它的增量更新操作放在一起,从而提升访问操作的性能。
Bw树与事务语义的结合(含恢复机制)
Bw树可以作为一部分,嵌入到传统事务系统的,所以本章简单介绍一下Bw树如何处理上层的事务语义。原文将事务系统可以分为事务部分(transactional component, TC)和数据部分(data component, DC),相似概念可以套用到其它事务系统中。
上层事务为每个更新操作配置了一个独特的LSN(Log Sequence Number)号。每一次flush操作中最高的LSN号会被记录到flush增量中。LSN号通过TC产生,并被事务日志所使用。当TC将更新数据顺序持久化到日志时,它会更新ESL(End of Stable Log)值。ESL值表示已经持久化到日志中的LSN号,即小于ESL的所有LSN记录都已被持久化到日志中。与传统数据库系统相似,Bw树的页刷新操作遵循日志先行协议(write-ahead log protocol ,WAL),即DC不会将大于ESL的LSN号对应的更新数据持久化。这就确保了DC持久化数据的速度慢于TC。TC会周期性向DC发送ESL,DC在flush某个页面过程中,缓存管理器只会将那些位于上一次flush的最大LSN和ESL之间的LSN记录顺序写入flush buffer中,而上一次flush的最大LSN号存储在每个数据页最新的flush增量记录中。
此外,TC还维护了一个RSSP(Redo-Scan-Start-Point)点。所有小于RSSP的LSN记录都可以被回收。TC会发送RSSP给DC,当DC将所有小于RSSP的LSN记录持久化后,它会反馈给TC这个信息。RSSP允许事务系统可以回收那些早于RSSP的事务日志,这与MySQL中已经完成了checkpoint的旧日志类似。
对于基于Bw树的事务机制,原文没有过多叙述,笔者只做一个简单分析:在某个事务提交前,事务涉及的更新数据通过append的方式添加到日志末尾,即保证了事务的持久性;Bw树的更新操作并没有破坏原数据,日志结构的存储方式天然存在多版本的数据控制,这也可以优化undo日志等机制的实现,保证事务的原子性;在上层封装了lock子系统和MVCC多版本控制,保证了事务的隔离性;当系统崩溃时,事务可以从RSSP开始扫描,将整个系统恢复到崩溃前的一致性状态;LLAMA还有一个比较独特的问题,即需要考虑到系统崩溃时地址映射表的恢复。方法是将地址映射表也看成一个数据库,所有映射表的操作都等于对某个数据页的更新。当系统崩溃时,通过重放LSS的“Log”恢复地址映射表,并通过周期性对映射表的checkpoint和日志清理来加速地址映射表的恢复速度。
当然,落实到具体的数据库系统(例如后文所述的Hekaton),事务机制需要根据业务场景做很多细节的设计,这已经超出了本文的范畴。
Bw树的应用情况及优缺点分析
真实数据库中的应用
Bw树被作为一个内存无锁索引结构,被应用在Hekaton[1],由微软开发的SQL Server的内存OLTP引擎中。Hekaton引擎被集成到SQL Server中,它不是一个分离的数据库系统。用户可以将一个表声明为memory-optimized ,这表示这个表会被存储在内存中,并通过Hekaton进行管理。每个Hekaton表有多个索引,每个索引有两种类型可选:分别是哈希索引和范围索引(Bw树)。当用户不需要范围操作时,哈希表提供更好的索引性能,反之Bw树提供了更优的范围操作性能。Hekaton中所有数据结构都是无锁的,从而避免线程之间的物理冲突,获取到更高的多线程扩展性。
下面讨论Hekaton的事务机制。在Hekaton中,每条记录的更新都是异地的,每条记录包含合法的时间戳范围<Beg, End>。Hekaton采用了乐观(无锁)的多版本并发控制机制(Optimistic MVCC),在事务执行过程中不持有锁:
- 对于更新操作,它会将之前的数据记录的End打上事务ID,然后创建一个新的数据记录,并为新数据记录的Beg打上事务ID,这些信息告知其它事务该数据记录正在被该事务更新中。在事务提交时,旧数据记录的End和新纪录的Beg会被打上当时的事务时间戳;
- 对于读取操作,通过快照隔离技术(snapshot isolation)读取事务可见时间戳范围内的数据记录。在事务提交时,根据事务所需的隔离级别,判断事务读集合的合法性;
如果事务之间的冲突概率相对较低,Optimistic MVCC能取得更优的事务性能。Hekaton同样优化了事务的持久性,提高checkpoint和recovery的性能,但因为这部分技术与本文主题联系并不紧密,本文不作赘述。笔者针对软件事务内存/内存数据库的并发控制机制有过较为深入的研究,在后面的文章中笔者会单独写一篇文章分析MVCC的演进历史,感兴趣的读者可以阅读引用[14]这篇文章。最后,引用[1,2]中描述了Bw树在Hekaton中的应用,实验表明,相比于运行在内存中的传统数据库,Bw-tree+Hekaton的搭配获得了较大的性能提升。
优缺点分析
Bw树针对多核处理器和闪存场景分别提出了latch-free和log-structured的优化机制。然而,Bw树并非没有缺点。首先,Bw树论文中的性能测试部分过于简单,原文仅与BerkeleyDB/Skip list进行对比。此外,Bw树原论文中缺乏很多关键步骤的细节分析,且没有开源实现版本,这导致实现起来难度较大,导致了实际应用的匮乏。针对这些问题,CMU的研究者在SIGMOD'18上发表了《Building a Bw-Tree Takes More Than Just Buzz Words 》一文[5],主要针对in-memory Bw树进行研究,主要内容包括:
- 加入了部分实现细节:1. 加入了Non-unique Key的支持;2. 加入了范围查找操作Iteration的遍历过程分析;3. 针对地址映射表的动态扩展的分析;
- 加入了部分优化技术:1. 为每个树节点预先分配增量记录空间,提高处理器缓存的命中率;2. 去中心化的垃圾回收器设计,避免garbage collection对多线程扩展性的影响;3. 提高页数据和增量记录合并操作的性能。
- 完善了部分性能测试,将in-memory Bw树与另外四种in-memory数据结构Skip list/Masstree/B+Tree/ART对比。实验得出的结论也在意料之中,抛开Log-structured机制对闪存的性能提升,in-memory Bw树的性能要低于现有的Masstree和经过优化的B+Tree等。原因也十分简单,对于in-memory data structures,处理器缓存的命中率对性能影响十分显著,而Bw树需要遍历增量链表,这个过程可能会导致多次处理器缓存缺失,产生多次内存访问,对性能有显著的影响。笔者认同对于纯内存的场景,Bw树并不是最优的索引结构,但是该论文的结果无法抹杀Bw树的优异之处:Bw树是针对多处理器和闪存设计的,Log-structured的设计避免了对原数据的修改,避免了原来事务系统中checkpoint的昂贵开销,榨干闪存的性能红利,并且天然支持多版本数据控制;Latch-free的并发控制解决了锁带来的性能瓶颈问题。
多核处理器 + 非易失内存场景下的B+树
相比于多核处理器+闪存场景,多核处理器+非易失内存场景下B+树的演进方向会更加复杂。对于基于非易失内存的索引,它需要保证索引结构在系统崩溃后可以恢复到一致性的状态。并且,非易失内存往往存在读写不对称的特性,写操作的延迟显著高于读延迟,并且具有有限的写寿命问题。因此在单线程场景下,B+树的优化方向主要分为两类:1. 优化B+树的持久化开销,例如采用多版本机制的CDDS-Tree[8],采用无序树节点的NVTree[9]/wB+Tree[10];2. 优化B+树的一致性开销,例如采用混合内存架构的NVTree/FPTree[11],控制缓存行刷出顺序的FAST+FAIR[12]。
此外,对于基于内存的索引结构,它需要更高的多线程扩展性。因此在多线程场景下,B+树的优化方向主要分为两类:1. 采用硬件事务内存等新的硬件红利,优化B+树的多线程扩展性,例如FPTree;2. 利用内存字节寻址的特性,设计latch-free的B+树,例如BzTree[13]。由于时间所限,这一部分的内容将在下一篇文章中详细说明。
总结
随着硬件技术的快速发展,软件系统的设计往往也需要作出相应的改变,才能充分榨干硬件红利。本文以多核处理器+闪存为背景,分析了代表性数据结构Bw树的原理/应用/优势劣势,希望大家看完以后有一定的收获。目前在业界,还有针对闪存设计的其它数据结构,笔者在后续的文章中也会进行分析。索引结构作为影响数据库系统性能的关键模块,对数据库系统在高并发场景下的性能表现具有重大影响。如何充分发挥出新型硬件的性能,提供用户爆炸性的性能提升,POLARDB作为新一代云原生数据库,一直在努力!请持续关注POLARDB!
引用
- [1] Cristian Diaconu, Craig Freedman, Erik Ismert. Hekaton:SQL server’s memory-optimized OLTP engine[C]// ACM SIGMOD International Conference on Management of Data. ACM, 2013:1243-1254.
- [2] Levandoski J, Lomet D, Sengupta S, et al. Indexing on modern hardware: hekaton and beyond[C]// ACM SIGMOD International Conference on Management of Data. ACM, 2014:717-720.
- [3] Levandoski J J, Lomet D B, Sengupta S. The Bw-Tree: A B-tree for new hardware platforms[C]// IEEE International Conference on Data Engineering. IEEE Computer Society, 2013:302-313.
- [4] Levandoski J , Lomet D , Sengupta S . LLAMA: A Cache/Storage Subsystem for Modern Hardware[C]// Proc Vldb Endow. 2013.
- [5] Wang Z, Pavlo A, Lim H, et al. Building a Bw-tree takes more than just buzz words[C]//Proceedings of the 2018 International Conference on Management of Data. ACM, 2018: 473-488
- [6] Rosenblum, Mendel, Ousterhout, John K. The design and implementation of a log-structured file system[J]. ACM Transactions on Computer Systems (TOCS), 1992, 10(1):26-52.
- [7] K. Fraser. Practical lock-freedom. Technical Report UCAM- CL-TR-579, University of Cambridge Computer Laboratory, 2004.
- [8] Venkataraman S , Tolia N , Ranganathan P , et al. Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory[C]// Usenix Conference on File & Stroage Technologies. USENIX Association, 2010.
- [9] Yang J , Wei Q , Chen C , et al. NV-Tree: reducing consistency cost for NVM-based single level systems[C]// Usenix Conference on File & Storage Technologies. 2015.
- [10] Chen S , Jin Q . Persistent B + -trees in non-volatile main memory[M]. VLDB Endowment, 2015.
- [11] Oukid I , Lasperas J , Nica A , et al. FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory[C]// the 2016 International Conference. ACM, 2016.
- [12] Hwang D, Kim W H, Won Y, et al. Endurable transient inconsistency in byte-addressable persistent B+-tree[C]//16th USENIX Conference on File and Storage Technologies. 2018: 187.
- [13] Arulraj J, Levandoski J, Minhas U F, et al. Bztree: A high-performance latch-free range index for non-volatile memory[J]. Proceedings of the VLDB Endowment, 2018, 11(5): 553-565.
- [14] PerÅke Larson, Blanas S , Diaconu C , et al. High-Performance Concurrency Control Mechanisms for Main-Memory Databases[J]. Proceedings of the Vldb Endowment, 2011, 5(4):298-309.