Database · 理论基础 · Palm Tree
Author: 唉梨
这篇文章介绍 B+ 树的无锁并发算法 Palm Tree。
论文链接:Parallel Architecture-Friendly Latch-Free Modifications to B+ Trees on Many-Core Processors。
为什么会介绍这个算法?
之前实现过一个有锁并发的 B+ 树算法,Efficient Locking for Concurrent Operations on B-Trees。
这是一个很经典的算法,它通过引入节点读写锁和层级指针来实现有锁并发,后续有不少论文都在这个基础上进行了改进。但是这个算法也有缺陷,
- 无法在多核情况下保证性能
- 对于顺序插入,性能太差
- 对删除操作不友好
前两个缺点的根本原因在于线程之间的同步开销太大。所以开始寻找新算法,然后发现了 Palm Tree。
这个算法有什么特别之处?
- 真无锁,既没有将节点的某个字段用于加锁,也不用 MVCC
- 高可扩展性,性能随着线程数增加而增加
- 顺序插入性能良好
- 满足序列化(serializability)
常规并发算法
首先我们看一下常规的并发算法,

上图代表了常规并发算法,这类算法主要特点就是每个线程把自己携带的数据处理完,同时通过加锁或者原子操作来避免并发访问的问题。缺点主要有以下几方面:
1. 加锁导致线程阻塞,CPU 利用率下降,(超)高并发情况下问题尤为严重
2. 原子操作导致的过多次重试导致 CPU 的有效利用率下降
3. 差劲的局部数据访问性能,比如顺序插入
有个值得提出的点是 LevelDB/RocksDB 中的 SkipList 使用原子操作但是插入并不需要重试,那是因为只是支持一写多读,如果是多写多读的话还是需要重试,参考 RocksDB 的 InlineSkipList。
Palm Tree 算法
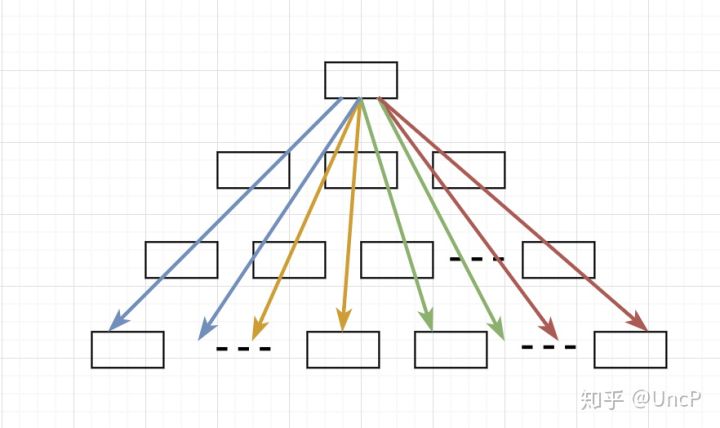
接下来我们介绍 Palm Tree。下图是论文中算法的整体流程:

对于 Palm Tree 来说,维护N个工作线程,N个线程会分工合作来处理数据。
第1行:Partition-Input,把我们要处理的 batch 内的数据平均分配给每个线程。
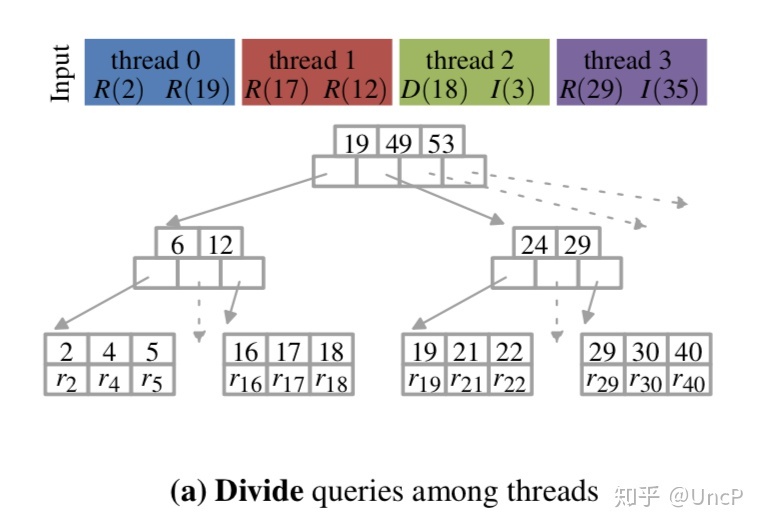
第2行:Search,每个线程对分配到的 key 下降到叶子节点,这个过程是不需要加锁与重试的,因为这个过程中所有节点都是只读的。
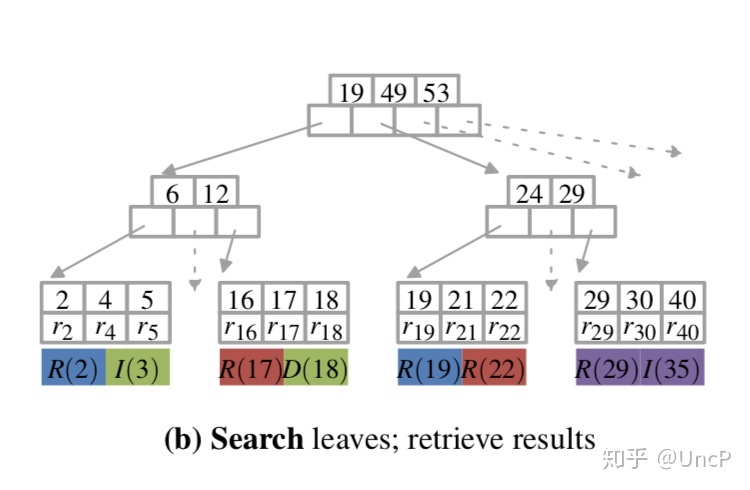
第3行:Sync,线程间进行同步,保证所有线程都下降到了叶子节点。接下来要解决并发访问的问题。在这里你可以把 sync 理解为一个全局的 barrier。
第4行:Redistribute-Work,可以看到上图中不同的线程落到了同一个叶子节点,这会带来并发访问的问题,所以我们需要进行数据的再分配,保证同一个节点只由一个线程进行读写操作。
第5行:Resolve-Hazards,要保证算法满足 serializability 这个特性,我们需要对操作进行重排,使得他们和之前在 Batch 中的顺序是一致的。
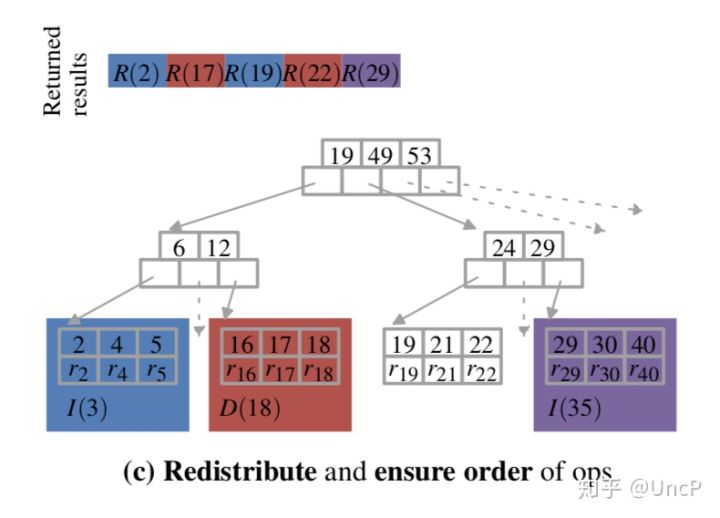
当3-4-5行执行完毕后,可以得到上面这张图。
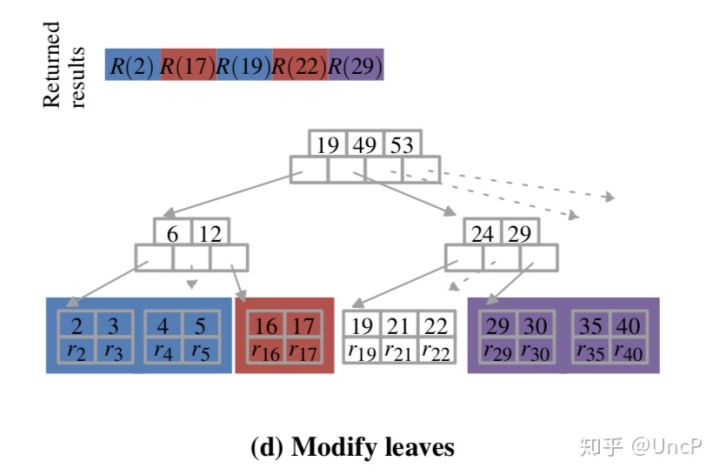
第6-7行:Modify-Node,每个线程根据自己最终分配到的数据,在相应的叶子节点进行实际的读写操作,不需要加锁,因为这时候每个叶子节点只属于一个线程。
第8行:Sync,所有线程进行完叶子节点的处理后需要进行同步。
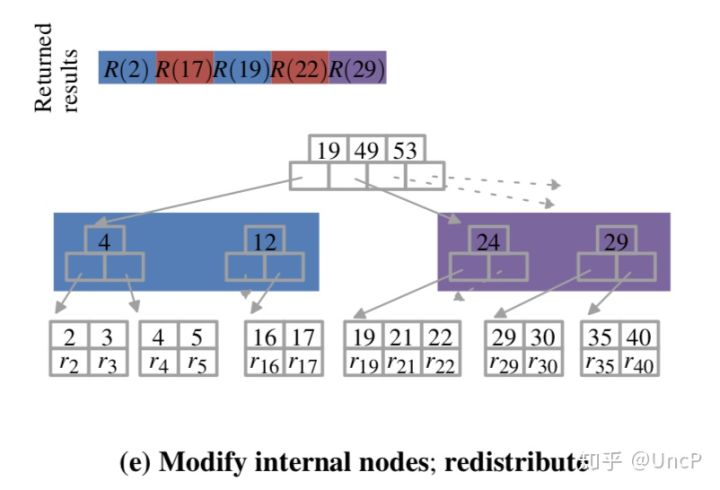
第9-13行,节点可能存在分裂或合并,这时候分裂或者合并信息相当于新的读写操作,我们要把它们反映到相应的上层节点中。这时候对于每一层需要进行(redistribute-work,分裂或合并内部结点,同步)这样的步骤,直到根节点。
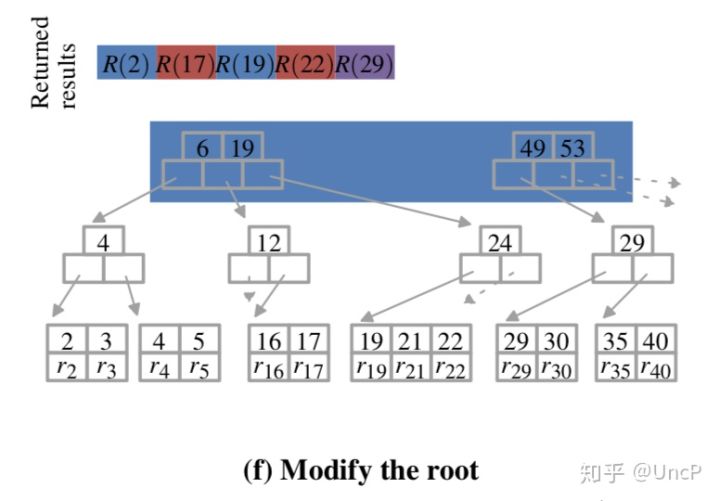
第15行:Handle-Root,根节点可能存在分裂或合并,只由编号为0的线程处理即可。
以上就是这个算法的整体流程。
Palm Tree 优化
算法自身的优化主要是两个,提前排序(pre-sort)和点对点同步(point-to-point synchronization)。
提前排序
palm tree 算法每次执行一个 batch,提前排序就是把这个 batch 里所有 key 按照顺序排好。
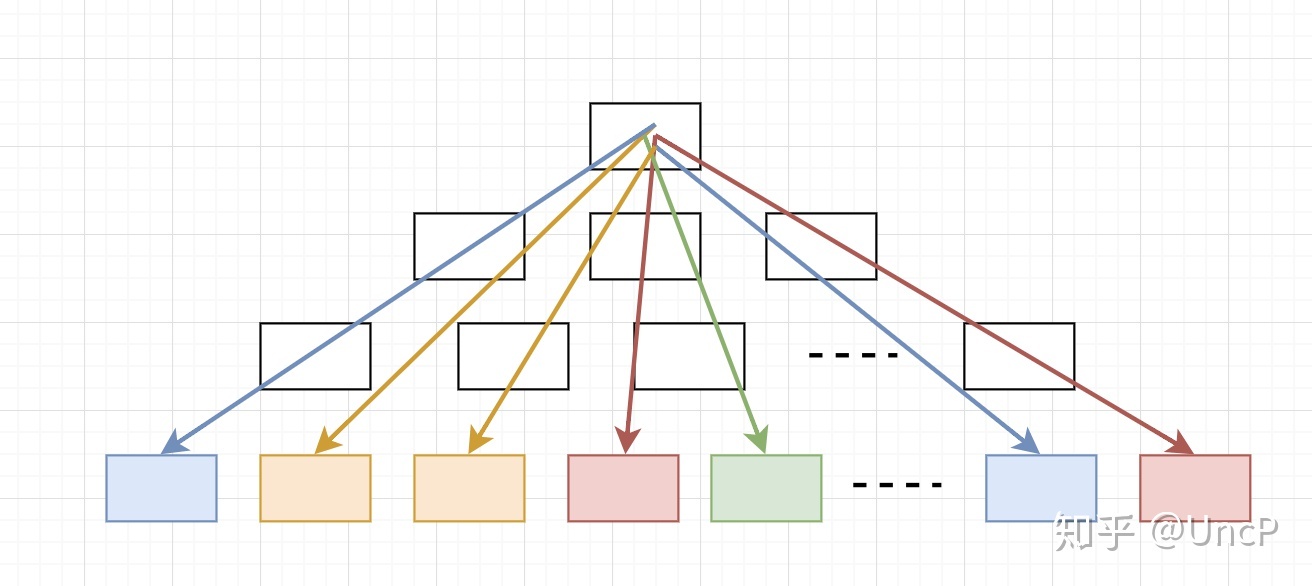
如果不排序,对于一个 batch,每个线程最后落在的叶子节点分布可能是这样的(不同颜色的线代表不同线程):
如果排序,那么每个线程落在的叶子节点的分布可能是这样的:
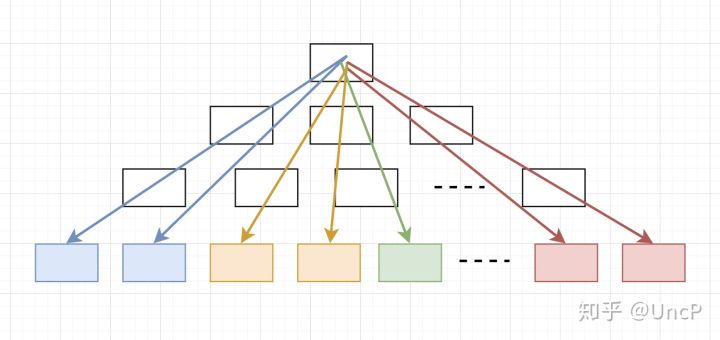
可以看到同一线程的节点分布是比较紧凑的,这样有两个好处:
- 在下降阶段,可以获得更好的缓存局部性
- 帮助获得更细粒度的线程同步
对于1,我们假设每个 batch 里有100个 key,然后一共有4个线程,那么每个线程会分配到25 个 key。对于一个线程来说,原来(排序前)key 的分布可能是 [aa, zz),排序完后,key 的分布可能是 [aa, gg),当 key 涉及的区间更紧凑时,它们在下降阶段涉及到的 B+ 树节点就少,所以可以减少 cache miss,获得更好的 cache locality。
点对点同步(point-to-point synchronization)
由上图2可以看到,当提前排序进行完后,每个线程落到的叶子节点范围是一定的。假设我们从左往右对叶子节点层进行标记,如果有100个叶子节点那就是【1,100】的区间。
对于4个线程来说,它们下降到的最终的叶子节点分布可能是这样的:
th1: [1,2,3,3,6,9],区间[1,9]
th2: [9,9,17,23,28],区间[9,28]
th3: [28,31,45,56,78],区间[28,78]
th4: [78,78,82,93,99],区间[78,99]
为了简便处理,之前我们在下降完后会进行一次全局同步(global synchronization),同步完后再进行任务分配并修改叶子节点。
但是现在不需要了,因为每个线程处理的 key 范围是不相交的,对于线程2来说,其实它只需要和线程1、线程3进行同步,此时线程4涉及到的叶子节点和线程2是不冲突的。

所以点对点同步是这样操作的,对于线程 i,通常情况下 i 只需要和线程 i-1、线程 i+1 进行同步,即相邻的线程之间进行同步即可。这样可以大大减少线程同步的开销。
具体来说,一个线程的一次同步需要确定四个值:
their_last: 前一个线程的最后一个节点
my_first: 我的第一个节点
my_last: 我的最后一个节点
their_first: 后一个线程的第一个节点
当前线程只需要等待前一个线程把它的最后一个节点发过来,同时等待后一个线程把它的第一个节点发过来就行了。
会出现线程 i 需要和 i+2 进行同步的情况吗?当然。当整个 batch 中的 key 比较紧凑时,这时 their_last 就代表前面某些或者前面所有线程的最后一个叶子节点,their_first 就代表后面某些或者后面所有线程的第一个叶子节点。举个极端的例子,顺序插入,这时候所有线程确定的四个值都是一样的,their_last == my_first == my_last == their_first,那这时候点对点同步就退化为了全局同步。
以上就是提前排序和点对点同步优化的介绍。
总结
整体上而言这个算法分为四个阶段:
1. Divide & Search
2. Redistribute-Work & Resolve-Hazards & Modify Leaf Nodes
3. Redistribute-Work & Modify Internal Nodes
4. Modify Root Node
相较于其他并发算法,Palm Tree 算法的每个线程不再孤立,而是会进行合作,然后通过线程间的同步(比如 Barrier)来保证各个线程整体上处于同一阶段以及写操作的隔离,避免节点加锁和重试,也就是之前提到的特性1。
同时,对于一次读写操作来说,耗时最多部分就是下降过程以及叶子节点的修改这两个部分。对于 Palm Tree 来说,耗时最多的操作是平均分配给各个线程独立进行的,所以理论上可以做到性能的线性扩展,也就是之前提到的这个算法的特性2。
下面这张图比较形象地描述了这个算法。
开源
这个算法的实现在这里:UncP/aili,代码在 palm/这个文件夹里。