MySQL · 代码阅读 · MYSQL开源软件源码阅读小技巧
Author: 韩逸
开源软件已经广泛的被互联网公司所应用,不仅仅是因为其能给企业节省一大笔成本,而且最重要的是拥有更多的自主可控性,能从源头上对软件质量进行把控。另一方面,由于开源软件背后往往没有大型的商业公司,所以文档相对来说不是非常完善(或者说文档和代码不一定相互对应),因此,作为一名合格程序员,尤其是基础软件开发的程序员,阅读开源软件源码的能力是必备的素质。
MySQL作为world most popular的开源数据库,被广大程序员所使用,其简单、高效、易用等优点被大家赞不绝口,作为一款已经有20多年的开源数据库,不少开源狂热分子对其源码进行了详细的剖析,然后面对MySQL上百万行的代码,初学者往往无从下手。古语说的好,工欲善其事必先利其器,本文分享分享一些Linux下阅读修改源码常用工具的小技巧,笔者认为这些小技巧对MySQL源码(其实对其他开源项目也一样)分析以及后续的修改有莫大的帮助。
另外说明一下,这篇文章需要你对这些常见的工具有所了解,如果之前对vim/git/gdb/Ctags/Cscope/Taglist/gcc等没有什么了解,建议先上网找找基础教程。
Tip 1: 不同文件自动加载不同格式
众所周知,MySQL数据库采用插件式存储引擎模式,即MySQL分Server层和plugin层,Server层主要做SQL语法的解析、优化、缓存,连接创建、认证以及Binlog复制等通用的功能,而plugin层才是真正负责数据的存储,读取,奔溃恢复等操作。Server层定义一些接口,plugin层只要实现这些接口,那么这个引擎就能在MySQL中使用,因此才有了这么多的引擎,例如InnoDB,TokuDB,MyRock等,但这个同时也代表着,引擎层的代码和Server层的代码风格会完全不一样,例如在Server层中,代码缩进是2个空格而在InnoDB层中,代码缩进是8个空格,当需要经常同时修改不同层的代码时,容易造成格式混乱,从而影响阅读。
Vim作为一款Linux下常用的文本查看编辑工具,在源码的阅读中必属主力。针对这个问题,常用的解决办法是,在家目录下,写两个不同的vimrc文件,一个对应Server层的风格,一个对应InnoDB层的风格,还需要编写一个简单的切换脚本,当需要修改Server层的代码时,切换到Server层的风格,反之亦然。但是当需要同时修改Server和InnoDB多处代码时候,会比较繁琐,同时,在文件中切换,往往使用的是Ctags和Cscope,直接从Server层切换到InnoDB层的代码了,根本没有给你切换的机会(可以直接在Vim中执行source命令,但是依然麻烦),如果Vim能根据不同的文件加载不同的格式那就方便多了。
在Vim的配置文件中有个内置的命令autocmd,后面可以跟一些事件E,再后面可以跟一些文件名F,最后放一些命令C,表示,当这些文件F触发这些事件E后,执行这些命令C。在另外一方面,MySQL的Server层代码和InnoDB层代码放在不同的目录下,虽然有很多,但是可以用通配符匹配。结合autocmd这个命令以及MySQL源码分布的规律,可以写出下面的vimrc配置文件:
" mysql server type
au BufRead,BufNewFile /home/yuhui.wyh/polardb/sql/* source ~/.vimrc_server
au BufRead,BufNewFile /home/yuhui.wyh/polardb/include/* source ~/.vimrc_server
au BufRead,BufNewFile /home/yuhui.wyh/polardb/mysql-test/* source ~/.vimrc_server
au BufRead,BufNewFile /home/yuhui.wyh/polardb/client/* source ~/.vimrc_server
" mysql innodb type
au BufRead,BufNewFile /home/yuhui.wyh/polardb/storage/innobase/* source ~/.vimrc_innodb
第一部分,这里重点介绍一下BufRead和BufNewfile这两个事件,前者表示当开始编辑新缓存区,读入文件后。说的通俗易懂点就是,当你打开一个已经存在的文件后且这个文件内容都已经被加载完毕后,这个事件被触发。后者,表示开始编辑不存在的文件,简单的说,就是打开一个新的文件。
第二部分,其中,au是autocmd的缩写,/home/yuhui.wyh/polardb是笔者MySQL的根目录,sql、include目录下面放了大部分Server层的代码,client目录下是客户端的代码(比如mysqlbinlog, mysql等)也沿用了Server层的风格,同时团队在testcase中也规定用Server层的代码风格,因此也把它放在一块。另外一方面,InnoDB层的代码就相对比较统一,都在storage/innobase下面。
第三部分,就是source命令,这个命令表示加载并执行后面这个文件里面的配置。vimrc_server和vimrc_innodb分别表示Server层和InnoDB层的不同格式,需要自己编写。
综上所述,我们可以分析出这个vimrc配置文件所表达出的意思,这里以最后一行为例,其他几行类似。最后一行的意思就是,当打开/home/yuhui.wyh/polardb/storage/innodb/这个目录下的所有文件或者在此目录下创建一个新文件的时候,执行~/.vimrc_innodb这个配置文件。
至此,完美解决上述问题。
同时由于这个方式是以缓存区为粒度的,所以下述几种使用方式都有效:
- 当前文件A属于Server层,使用Ctags跳转到InnoDB层文件B,则文件B使用InnoDB风格,编辑或者阅读后,如果使用Ctrl+T返回(或者其他方式)A,则A依然使用Server层风格,不会被影响。
- 多窗口支持,由于缓存区独立加载,即使同时打开多个终端中的多个vim,也不会相互影响。
- 如果先打开Server层的文件A,然后使用:e命令打开另外一个InnoDB层的文件B,然后使用:bn相互切换,格式依然不会乱掉,A永远使用Server层风格,B永远使用InnoDB风格。
- 如果使用vim -O方式同时打开多个InnoDB和Server层文件,然后使用Ctrl+w在其之间切换,依然没有什么问题。
BufRead事件的威力就是如此牛X。
BTW,上面这图只是我的配置文件的一部分,完整的文件如下:
" normal type au BufRead,BufNewFile * source ~/.vimrc_normal " mysql server type au BufRead,BufNewFile /home/yuhui.wyh/polardb/sql/* source ~/.vimrc_server au BufRead,BufNewFile /home/yuhui.wyh/polardb/include/* source ~/.vimrc_server au BufRead,BufNewFile /home/yuhui.wyh/polardb/mysql-test/* source ~/.vimrc_server au BufRead,BufNewFile /home/yuhui.wyh/polardb/client/* source ~/.vimrc_server " mysql innodb type au BufRead,BufNewFile /home/yuhui.wyh/polardb/storage/innobase/* source ~/.vimrc_innodb
倒数第二行的意思是,当遇到.ic结尾的文件时,把这个文件当作是C语言的文件来解析,这样语法就会高亮啦~
这里还有一点要说明的是,如果同时多个事件被触发,则按照配置文件中出现的顺序依次执行,所以如上图所示,vimrc_normal放的是我自己常用的风格,毕竟不能被MySQL完全同化么~。而最后vimrc_base里面放的是三种模式(normal,server,innodb)共有的配置,代码复用么,嘿嘿
Tip 2: 使用Ctags/Cscope/Taglist提高源码阅读效率
Ctags和Cscope是很有名的Linux命令行下阅读代码的神器,有Linux下的sourceinsight的美称,网上已经有很多介绍,不熟悉的可以先去网上找找。这里分享一下笔者常用的配置,不同的配置可能导致搜索结果的不同。
[Sun Dec 11 17:45:10 ~]
$ alias csfile
alias csfile='find . -name "*.c" -o -name "*.cc" -o -name "*.cp" -o -name "*.cpp" -o -name "*.cxx" -o -name "*.h" -o -name "*.hh" -o -name "*.hp" -o -name "*.hpp" -o -name "*.hxx" -o -name "*.C" -o -name "*.H" -o -name "*.cs" -o -name "*.ic" -o -name "*.yy" -o -name "*.i" -o -name "errmsg-utf8.txt" > cscope.files'
[Sun Dec 11 17:46:09 ~]
$ alias cs
alias cs='cscope -bqR -i cscope.files && ctags --extra=+q --fields=+aimSn --c-kinds=+l --c++-kinds=+l --totals --sort=foldcase -L cscope.files'
由于源码经常变动,因此我写了一个alias方便重建tag数据库。csfile其实就是生成源码文件列表(并不是MySQL源码目录下的所有文件都是源码文件),这里要注意把.ic和.i为后缀名的文件也加进去,这种文件也是MySQL源码文件,其他的后缀名基本都是比较常规的。生成了源码文件列表后就可以用从scope和ctags生成对应的标签了。这里介绍一下我使用的参数:
cscope: -b 建立tag数据库文件,默认文件名为cscope.out
-q 建立倒排索引加速检索,会产生cscope.in.out和cscope.po.out两个文件
-R 在目录下递归搜索
-i 从指定文件中获取源码文件路径,有了这个参数,不用上面这个参数也可以
ctags: –extra=+q 在tag中增加类的信息,这样当一个tag有多处定义的时候,搜索时可以帮助辨认
–field=+aimSn 主要也是在tag中增加一些信息(类的访问权限,继承关系,函数原型等),搜索时可以根据这些额外信息把最有可能的定义排在前面
–c-kinds=+l 增加局部变量定义的索引,MySQL有一些函数很大,不方便查找,把这个开起来就方便多了–total 产生tag文件后,输出一些统计信息,例如,扫描了多少个源文件,多少行源代码以及产生了多少个tags
–sort=foldcase 对产生tags数据库使用大小写不敏感的排序,便于后续检索
-L cscope.files 从文件中获取源代码文件的路径
这里只是简单的提一下,详细可以看帮助文档。
接下来分享一下笔者常用的使用方法:
为了方便跳转,笔者在vimrc文件中加入了如下定义:
set cscopetagorder=1
这样,当我搜索一个标签(Ctrl+])的时候,先从ctags产生的标签库中搜索,然后再从cscope中搜索。
nmap <C-\>s :csfind s <C-R>=expand("<cword>")<CR><CR>
nmap <C-\>g :csfind g <C-R>=expand("<cword>")<CR><CR>
nmap <C-\>c :csfind c <C-R>=expand("<cword>")<CR><CR>
nmap <C-\>t :csfind t <C-R>=expand("<cword>")<CR><CR>
nmap <C-\>e :csfind e <C-R>=expand("<cword>")<CR><CR>
nmap <C-\>f :csfind f <C-R>=expand("<cfile>")<CR><CR>
nmap <C-\>i :csfind i ^<C-R>=expand("<cfile>")<CR>$<CR>
nmap <C-\>d :csfind d <C-R>=expand("<cword>")<CR><CR>
同时在vimrc中加入上图的定义,方便使用cscope的功能:
Ctrl+\+g:寻找定义处,笔者一般很少用了,一般用Ctrl+]代替。
Ctrl+\+s: 当你想查看一下这个标签以C语言标准Symbol在哪些地方出现过时,可以用这个,也就是说,搜索出的结果都是标准C语言Symbol的。
**Ctrl+\+t: ** 这个是搜索出所有出现这个tag的位置,不管是不是C语言Symbol。 这里介绍一个上面两个命令的区别,一般来说,Ctrl+\+s这个命令搜索出的一般都在源代码中且是全词匹配的,而Ctrl+\+t这个命令可能搜索出注释中的tag,也有可能是半个词匹配,但是Ctrl+\+t这个命令有实时性,即当你修改过文件后,如果不重建整个tags数据库,用Ctrl+\+s搜索不到最新的标签,而用Ctrl+\+t就可以,当然Ctrl+\+t这个速度也会慢一点。换句话说,Ctrl+\+t是Ctrl+\+s的超集,如果你用Ctrl+\+s搜索不到,然后用Ctrl+\+t可能就能找到了,这种情况在MySQL源码中还比较常见,因为其用了很多宏定义来简化代码,这些宏定义有些不能被ctags正确的解析成C语言Symbol,所以只能用Ctrl+\+t才能搜索到,一个常见的例子就是InnoDB层线程函数基本都用类似DECLARE_THREAD()的形式来定义,只能用Ctrl+\+t来找,才能找到这个函数正确的定义处。
Ctrl+\+c: 查找当前的标签在哪些地方被引用过。笔者经常用这个功能,因为常常需要看当前这个函数在哪些地方被调用过。如下图,可以一眼看出recv_parse_log_recs这个函数被三个函数调用过(分别用《《和》》包括起来)。
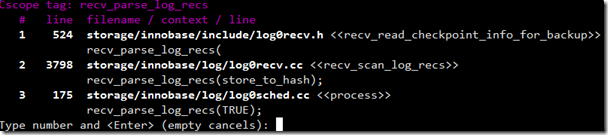
在这例子中,如果你查看了编号为1调用的地方,不用返回,可以直接按下:tn(:tN代表反向)这个命令,然后会自动跳到编号为2调用的地方,这样可以快速的在调用处查看。这个小技巧在cscope其他命令中也支持。
Ctrl+\+d: 查找这个函数中引用了哪些函数,用的相对较少一点。
Ctrl+\+f: 打开指定文件名的文件,需要在索引中。这个命令也还是经常用的,例如,你当前在sql_parse.cc的Server层代码中,需要查看一下ha_innodb.cc这个InnoDB层的文件,你可以直接输入:cs f f ha_innodb.cc,这样文件可以直接打开,而不需要你用:e或者其他命令输入完整的文件路径,提高了不少效率。当然,你把光标停在一个include语句的头文件上,也是可以直接打开的。
Ctrl+\+e: 使用了这个,你可以在tag中指定通配符,这样就支持模糊查询了。
此外,当你没打开任何一个文件的时候,突然想查看一个tag(例如rds_update_malloc_size)的定义,你可以直接在命令行输入vim -t rds_update_malloc_size,注意要在tags数据库所在的目录,然后就会直接打开rds_update_malloc_size定义的文件并跳转到定义处。这里要求tag不能拼错一点,也就是不支持模糊查询,如果你想要模糊查询的话,直接打开一个空的vim,然后输入:tag rds_update,然后按Tab键,就可以自动补全,如果补全的不是你想要的,接着按Tab直到找到你想要的。
最后,介绍一下TagList的小工具。这个工具就是把一个文件中的所有定义给抽取出来,显示在一个分屏中,方便你查看。类似下图:
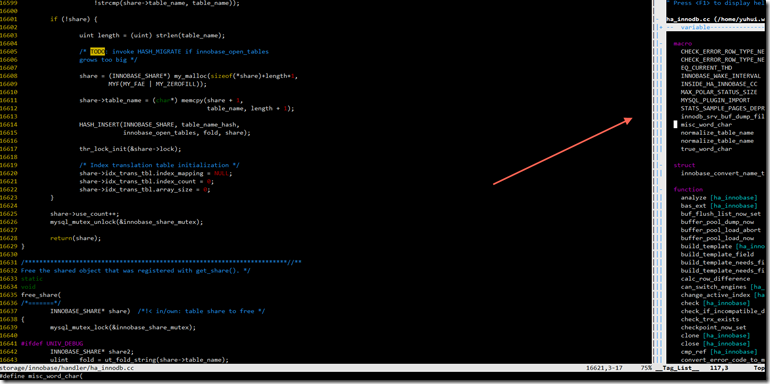
它统计了变量,结构体,宏定义以及函数,打开后你可以得到这个文件的概览,有些时候,你想查看一个函数,但是这个函数的名字又想不起来,你可以打开这个,然后在函数列表里面找,比你在文件中用]]命令一个个找快的多。常用命令:
回车:当你停留在某个标签上,直接回车,即可跳转到这个标签的定义上,同时光标也会停留在定义所在的窗口上,如果你想接着查看TagList窗口,需要重新切换。
p: 同回车作用差不多,不同的就是,跳转后光标依然停留在TagList窗口,你可以接着查看其他标签,这个比较实用,一般现在TagList窗口中查找,找到后在敲回车,切换过去,同时可以把TagList窗口关掉。
x: 如果你嫌TagList窗口太小,就可以用这放大窗口
+,-,*,=:这些都是折叠或者展开某一类或者全部的标签
s:排序有两种,一种是按照出现顺序,一种是按照首字母排序,可以用这个命令切换
此外,你可以在vimrc中配置TagList相关配置,例如:
let Tlist_Exit_OnlyWindow = 1
let Tlist_Show_One_File = 1
let Tlist_Sort_Type = "name"
let Tlist_Auto_Open = 1
let Tlist_Use_Right_Window = 1
其中,Tlist_Exit_OnlyWindow表示当只剩下TagList这个窗口时,退出vim。Tlist_Use_Right_Window表示TagList窗口显示在vim右边。当你打开多个文件的时候,如果不设置Tlist_Show_One_File为1,就会把所有文件里面的定义都输出在TagList窗口中。Tlist_Auto_Open则表示TagList窗口是否默认打开。Tlist_Sort_Type表示默认按照首字符出现顺序排序。
总之,在阅读源码的过程中,要善于使用各种工具便于我们快速找到我们想要的东西,如果还有什么使用技巧值得分享,可以留言告诉笔者哈
Tip 3: 定制vimrc函数简化常用复杂的操作
有时候,当你在源码中游走的时候,会被搞的晕头转向,不知道自己在哪里了,这个时候你可以使用Ctrl+G来查看自己在哪个文件中,但是你还想知道自己在哪个函数中呢?这个vim貌似没有提供默认的快捷键,那么我们就自己造个轮子吧:
fun! ShowFuncName()
let lnum = line(".")
let col = col(".")
echohl ModeMsg
echo getline(search("^[^ \t#/]\\{2}.*[^:]\s*$", 'bW'))
echohl None
call search("\\%" . lnum . "l" . "\\%" . col . "c")
endfun
map f :call ShowFuncName() <CR>
这个showFuncName的函数跟快捷键f绑定起来了,你只需把这个函数放在vimrc中,然后在源码中按下f,就可以查看当前在哪个函数中,但是有些时候会有问题,可能没有找到正确的函数头,这个时候,就只能用最原始的[[和]]命令来找函数头了,然后使用Ctrl+O的方式返回之前停留的地方。
MySQL Server层的代码对单行的注释有点小要求:如果这行有代码也有注释,必须从第48列开始写注释。这个时候如果你用手调整到48列,会很麻烦,依然可以写一个函数,然后绑定一个快捷键(Shift+Tab):
function InsertShiftTabWrapper()
let num_spaces = 48 - virtcol('.')
let line = ' '
while (num_spaces > 0)
let line = line . ' '
let num_spaces = num_spaces - 1
endwhile
return line
endfunction
" jump to 48th column by Shift-Tab - to place a comment there
inoremap <S-tab> <c-r>=InsertShiftTabWrapper()<cr>
介于MySQL Server层和InnoDB层的格式很容易搞错,你需要经常查看格式是否正确,这个时候你可能需要把所有隐藏的不可见的字符给显示出来,命令你给是set list,同样,如果你频繁使用,还不如加个快捷键绑定:
map l :set list! <CR>**
这样你只要按下l就可以在是否显示不可见字符中切换。
我们在写代码中,一般不希望有多余的空格,尤其在一行代码的结束后,后面不应该有多余的空格,但是空格又是不可见的字符,很难察觉到,除了用上述set list查看外,可以用一下的命令,这个命令会查找多余的空格,然后用红色高亮出来,时刻提醒你。
highlight WhitespaceEOL ctermbg=red guibg=red
match WhitespaceEOL /\s\+$/
此外,这边总结了一些常用好用的vim命令,在阅读源码中很有用。
set number: 显示代码行数
set ignorecase: 忽略大小写,这个在使用/搜索中很有用
set hlsearch: 搜索结果高亮
set incsearch: 当你在搜索时,每输入一个字母就开始搜索一次,这样当你要搜索一个很复杂的东西时候,只需要输入部分,就可以找到了。例如,你要搜InsertShiftTabWrapper这个函数,如果这个参数不打开,需要等你输入完所有,然后按回车才开始搜索,而打开这个参数,则每输入一个字母,就搜索一次,你可能只需要输入Insert这个单词,vim可能就已经跳转到InsertShiftTabWrapper这个函数了。
set showmatch: 当你输入后半个括号时候,打开这个开关,前半个括号会闪一下,提示你当前输入的括号是跟他匹配的。
set paste: 可以进入复制模式,复制入的东西不会被重排。
批量注释连续多行: 光标移到第一列,切换到列选择模式Ctrl+v,然后选择中所有需要注释的行,然后按一下Shift+i,接着输入//,最后按两下Esc键即可。
*: 光标停留在一个tag上,然后按下这个,就可以在文件中找到所有这个tag,并且高亮出来,可以用n查看下一个,用N查看上一个。
%:停留在括号上,可以用来查看另外半个括号,一般用来查看括号匹配。
Ctrl+F,Ctrl+B:整页滚动
gd:查看局部变量定义
gD:查看全局变量定义,只能查看这个文件中的
[[: 跳转到上面一个定义
]]: 跳转到下面一个定义
Tip 4: GDB高效化调试
用gdb记得加上-g以及关掉-O的优化,不然单步调试中,无法跟源代码对应,看不清楚。
gdb启动参数中加上-q可以把烦人的版本信息给去除掉。
gdb可以使用—args启动,然后程序的参数就可以直接写在后面,不需要进入gdb后再指定。
可以在家目录下建立.gdbinit文件,把常用配置写进去,如下图:
setprint elements 0
setprint array-indexes onsetprint pretty onsetprint object onset history filename ~/.gdb_history
set history save on
set print elements 0: 如果你要打印一个数组,set print elements 5,表示最多只打印5个元素,set print elements 0表示打印所有元素
set print array-indexes on: 打印数组的时候,同时把索引也打印出来
set print pretty on: 打开的时候,显示结构体会比较漂亮,按照多行缩进的格式显示,关闭的时候,只是在一行中打印整个结构
set print object on: 打开的时候,如果使用type命令查看变量类型,会考虑虚函数的影响,即打印真正的类型,否则只打印编译时候确定的父类型
set history save on: 打开历史命令记录功能,这样当你再次进入gdb的时候,你可以使用方向键查看之前使用过的命令了
使用-tui参数启动gdb,或者启动gdb后按Ctrl+x+a,可以进入gdb的图形化调试界面,上半部分为源代码窗口,下半部分为命令行界面,再按一下这个组合键就能返回传统的字符界面:

源码界面,执行到的代码行会高亮出来,断点行前面会有个B+>标识。默认的焦点在代码窗口,即方向键控制的是代码的移动,可以使用focus cmd将焦点切换到命令行窗口,方向键即可控制查看之前执行过的命令,否则需要使用Ctrl+p或者Ctrl+n。其他命令跟命令行gdb类似。
另外,我们常常会碰到MySQL hang住的情况,虽然这个时候你用kill命令杀掉,然后重启,能解决燃眉之急,不过为了找到hang的原因,最好的办法是保留住内存现场,方便后面排查。一种方法是使用kill -11的方法,让内核产生一个coredump,但是如果当时MySQL内存使用的比较多,需要产生一个很大的文件,这对磁盘写入造成很大的冲击。另外一种方式是使用pstack产生一个所有线程的函数调用堆栈关系,类似gdb中的bt命令,如下图:
Thread 4 (Thread 0x7ff8f05fa700 (LWP 15335)):
#00x0000003330ce0263inselect () from /lib64/libc.so.6
#10x000000000116e8cain os_thread_sleep(unsigned long) ()
#20x00000000010ef1ddin log_wait_for_more(unsigned long, bool, log_reader_t*) ()
#30x000000000113eff3in log_reader_t::read_log_state(unsigned char*, unsigned int*) ()
#40x000000000113e920in log_reader_t::acquire_data(unsigned char*, unsigned int*, unsigned int*) ()
#50x0000000001013532in innobase_read_redo_log(void*&, unsigned long, unsigned char*, unsigned int*, unsigned int*) ()
#60x0000000000a2a0a3in com_polar_dump(THD*, char*, unsigned int) ()
#70x00000000009df128in dispatch_command(enum_server_command, THD*, char*, unsigned int) ()
#80x00000000009dab90in do_command(THD*) ()
#90x000000000096ea42in do_handle_one_connection(THD*) ()
#100x000000000096e117in handle_one_connection ()
#110x00000000016c1a11in pfs_spawn_thread ()
#120x00007ff8f56e8851in start_thread () from /lib64/libpthread.so.0
#130x0000003330ce767din clone () from /lib64/libc.so.6
Thread 3 (Thread 0x7ff8f0578700 (LWP 15400)):
#00x0000003330cda37din read () from /lib64/libc.so.6
#10x0000003330c711e8in _IO_new_file_underflow () from /lib64/libc.so.6
#20x0000003330c72ceein _IO_default_uflow_internal () from /lib64/libc.so.6
#30x0000003330c674dain _IO_getline_info_internal () from /lib64/libc.so.6
#40x0000003330c66339in fgets () from /lib64/libc.so.6
#50x0000000000fbc817in rds_pstack ()
#60x0000000000875085in handle_fatal_signal ()
#7 <signal handler called>
#80x000000000107bae9in i_s_innodb_log_reader_fill_table(THD*, TABLE_LIST*, Item*) ()
#90x0000000000aae83din do_fill_table(THD*, TABLE_LIST*, st_join_table*) ()
#100x0000000000aaf023in get_schema_tables_result(JOIN*, enum_schema_table_state) ()
#110x0000000000a56065in JOIN::prepare_result(List<Item>**) ()
#120x00000000009834d3in JOIN::exec() ()
#130x0000000000a578f0in mysql_execute_select(THD*, st_select_lex*, bool) ()
#140x0000000000a57f95in mysql_select(THD*, TABLE_LIST*, unsigned int, List<Item>&, Item*, SQL_I_List<st_order>*, SQL_I_List<st_order>*, Item*, unsigned longlong, select_result*, st_select_lex_unit*, st_select_lex*) ()
#150x0000000000a53ffein handle_select(THD*, select_result*, unsigned long) ()
#160x00000000009f67c9in execute_sqlcom_select(THD*, TABLE_LIST*) ()
#170x00000000009e5366in mysql_execute_command(THD*) ()
#180x00000000009fc078in mysql_parse(THD*, char*, unsigned int, Parser_state*) ()
#190x00000000009dd917in dispatch_command(enum_server_command, THD*, char*, unsigned int) ()
#200x00000000009dab90in do_command(THD*) ()
#210x000000000096ea42in do_handle_one_connection(THD*) ()
#220x000000000096e117in handle_one_connection ()
#230x00000000016c1a11in pfs_spawn_thread ()
#240x00007ff8f56e8851in start_thread () from /lib64/libpthread.so.0
#250x0000003330ce767din clone () from /lib64/libc.so.6
这里仅仅截取了两个线程的函数堆栈信息。通过这个可以看出,程序在i_s_innodb_log_reader_fill_table这个函数处奔溃了,然后你需要去那个函数里面看到底发生了什么。后面这种方法由于只需要产生一个很小的文本文件,线上出问题了经常使用这种方式。但是这里还是有点小不爽,奔溃的位置既然能定位到函数级别,那么能不能直接定位到源码中的行级别,这样即使这个函数很大,后期诊断起来也方便多了。解决方法很简单,只需要改一下pstack的源码:
$GDB --quiet $readnever -nx /proc/$1/exe $1 <<EOF 2>&1 |
把这行中的$readnever去掉就行了。readnever这个参数的作用如下:
`--readnever'
Do not read each symbol file's symbolic debug information. This makes startup faster but at the expense of not being able to
perform symbolic debugging.
说白了就是启动效率,但是个人感觉得不偿失,既然程序已经发生问题了,提供更加详细的诊断信息才是王道。去掉这个参数后,以后看到的pstack结果就是类似下图了:
Thread 2 (Thread 0x7ffa4c106700 (LWP 44741)):
#00x0000003330cda37din read () from /lib64/libc.so.6
#10x0000003330c711e8in _IO_new_file_underflow () from /lib64/libc.so.6
#20x0000003330c72ceein _IO_default_uflow_internal () from /lib64/libc.so.6
#30x0000003330c674dain _IO_getline_info_internal () from /lib64/libc.so.6
#40x0000003330c66339in fgets () from /lib64/libc.so.6
#50x0000000000fbfe7fin rds_pstack () at /home/yuhui.wyh/polardb/mysys/stacktrace.c:758
#60x0000000000878605in handle_fatal_signal (sig=11) at /home/yuhui.wyh/polardb/sql/signal_handler.cc:269
#7 <signal handler called>
#80x00000000010134b2in innobase_get_read_lsn (uuid=0x7ffa4c105d40, start_lsn=0x7ffa4c105d50, orig_start_lsn=0x7ffa4c105d38) at /home/yuhui.wyh/polardb/storage/innobase/handler/ha_innodb.cc:11035
#90x0000000000a2a43cin polar_io_thread (arg=0x0) at /home/yuhui.wyh/polardb/sql/sql_polar.cc:1827
#100x00000000016dd785in pfs_spawn_thread (arg=0x4872800) at /home/yuhui.wyh/polardb/storage/perfschema/pfs.cc:1858
#110x00007ffa78d7c851in start_thread () from /lib64/libpthread.so.0
#120x0000003330ce767din clone () from /lib64/libc.so.6
Thread 1 (Thread 0x7ffa7979e720 (LWP 44707)):
#00x00007ffa78d807bbin pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0
#10x0000000000fc7afdin safe_cond_timedwait (cond=0x2bfd900, mp=0x2bfd780, abstime=0x7ffff07562e0, file=0x19a97b0"/home/yuhui.wyh/polardb/include/mysql/psi/mysql_thread.h", line=1199) at /home/yuhui.wyh/polardb/mysys/thr_mutex.c:278
#20x0000000000fbad17in inline_mysql_cond_timedwait (that=0x2bfd900, mutex=0x2bfd780, abstime=0x7ffff07562e0, src_file=0x19a97f0"/home/yuhui.wyh/polardb/mysys/my_thr_init.c", src_line=240) at /home/yuhui.wyh/polardb/include/mysql/psi/mysql_thread.h:1199
#30x0000000000fbb994in my_thread_global_end () at /home/yuhui.wyh/polardb/mysys/my_thr_init.c:239
#40x0000000000faf4c6in my_end (infoflag=0) at /home/yuhui.wyh/polardb/mysys/my_init.c:205
#50x000000000067c836in mysqld_exit (exit_code=1) at /home/yuhui.wyh/polardb/sql/mysqld.cc:1913
#60x000000000067c72ein unireg_abort (exit_code=1) at /home/yuhui.wyh/polardb/sql/mysqld.cc:1894
#70x0000000000689655in init_server_components () at /home/yuhui.wyh/polardb/sql/mysqld.cc:5185
#80x000000000068bee1in mysqld_main (argc=26, argv=0x410e6d8) at /home/yuhui.wyh/polardb/sql/mysqld.cc:5850
#90x00000000006741d2in main (argc=9, argv=0x7ffff0756ba8) at /home/yuhui.wyh/polardb/sql/main.cc:25
可以看到函数在哪个文件中的哪一行了。在MySQL发生死锁时,用这招进行诊断很有效。当然,记住,在编译MySQL的时候一定要带上-g,不然还是没有这些调试信息的。
Tip 5: git reset/git rebase简化提交的代码
在平时的代码开发中,需要加新的feature,或者fix bug以及optimize等操作时,一般都会从master上拉一个分支出来,然后自己在上面随便折腾,这也就导致在同一分支上,会有多次commit,最后在把这些commit都提交到主干,会导致主干上比较乱,这时候git reset命令就有用了:
git reset –soft HEAD^^: 把最近的两次提交的变动合并,结果以提交到暂存区的形式存在,即git add之后的文件状态,这个时候,你只需要再git commit一下,就能把多次提交合并。
git reset –mixed HEAD^^: 跟上面的类似,只不过文件回退到未加入暂存区之前的状态,也就是说,你还需要执行一把git add,然后才能执行git commit。
git reset –hard HEAD^^: O这个操作直接把最近两次的提交都给删除掉,代码没有了,慎用。
合并自己的commit后,也不能直接就提交,最好把master上的变更给同步过来,因为在你开发分支的时候master上可能有新的提交。这个时候git rebase命令就上场了。笔者常用的方法是,首先checkout出master,然后git pull一把,然后切换回之前的分支并执行git rebase master,这样就会把master上的变动给同步过来,master上的变动在前,你自己的变动在后,如果两者有冲突,git rebase会停下来,你自己把冲突的文件给处理好后,然后git add,再执行git rebase –continue。最后再把分支提交,发起code review过程,如果通过的话,就可以直接merge到master,不会有冲突。使用git rebase还有一个好处是,能保证master上的提交是一条线,不像使用git merge提交的,会导致master上有很多分支,当然也有一个不好的地方,那就是会导致提交的时间发生变动,提交的时间不会保证是递增的顺序。
此外,还有一些命令也挺好用的:
git blame: 当你发现源码中的Bug的时候,想找出这是谁的锅,然后这条命令就排上用场了。当然其实更有用的一种用法是通过它来找到这个新的feature的issue:比如说,代码中多了一个变量var_path,你想知道这个变量是干啥的,除了看注释和源码,你可以通过git blame找到提交的commit id,然后在git log的commit message中找到Issue id信息以及简介,找到Issue id后就可以在gitlab等代码仓库中,找到Issue的详细信息,比如为何创建,什么时候创建以及解决的办法等。
Tip 6: GCC使用技巧
开源软件为了兼容各个操作系统不同平台,需要维护不同的代码,在C语言中,常用#ifdef等宏定义来区分不同平台的代码,另外一方面,很多时候当代码逻辑很复杂的时候,为了不牺牲效率同时保持高可阅读性,部分代码需要使用宏定义来简化。上面提到的两点,做的的确合理,但是大大增大了阅读代码的成本,这个时候我们可以直接在gcc编译选项中加入save-temps这个参数,这个参数可以把编译时的临时文件保存下来,包括预编译后的文件,生成汇编的文件以及最后的二进制文件。这里我们只需要查看预编译后的文件(后缀名为.i)即可,里面的信息往往很清晰,举个栗子。下图是InnoDB handler层的一段代码:
mysql_declare_plugin(innobase)
{
MYSQL_STORAGE_ENGINE_PLUGIN,
&innobase_storage_engine,
innobase_hton_name,
plugin_author,
"Supports transactions, row-level locking, and foreign keys",
PLUGIN_LICENSE_GPL,
innobase_init, /* Plugin Init */
NULL, /* Plugin Deinit */
INNODB_VERSION_SHORT,
innodb_status_variables_export,/* status variables */
innobase_system_variables, /* system variables */
NULL, /* reserved */0, /* flags */
},
i_s_innodb_trx,
i_s_innodb_locks,
i_s_innodb_lock_waits,
i_s_innodb_cmp,
i_s_innodb_cmp_reset,
i_s_innodb_cmpmem,
i_s_innodb_cmpmem_reset,
i_s_innodb_cmp_per_index,
i_s_innodb_cmp_per_index_reset,
i_s_innodb_buffer_page,
i_s_innodb_buffer_page_lru,
i_s_innodb_buffer_stats,
i_s_innodb_metrics,
i_s_innodb_ft_default_stopword,
i_s_innodb_ft_deleted,
i_s_innodb_ft_being_deleted,
i_s_innodb_ft_config,
i_s_innodb_ft_index_cache,
i_s_innodb_ft_index_table,
i_s_innodb_sys_tables,
i_s_innodb_sys_tablestats,
i_s_innodb_sys_indexes,
i_s_innodb_sys_columns,
i_s_innodb_sys_fields,
i_s_innodb_sys_foreign,
i_s_innodb_sys_foreign_cols,
i_s_innodb_sys_tablespaces,
i_s_innodb_sys_datafiles
mysql_declare_plugin_end;
这段代码是用来定义InnoDB这个引擎的接口信息的,方便Server层的代码调用。第一次看,你可能根本不知道这是个啥玩意,即使你用Ctags等工具跳转,也不一定看的清楚,尤其针对源码的初学者,这个时候你可以打开预编译文件看一下:
int builtin_innobase_plugin_interface_version= 0x0104;
int builtin_innobase_sizeof_struct_st_plugin= sizeof(struct st_mysql_plugin);
struct st_mysql_plugin builtin_innobase_plugin[]= {
{
1,
&innobase_storage_engine,
innobase_hton_name,
plugin_author,
"Supports transactions, row-level locking, and foreign keys",
1,
innobase_init,
__null,
(5 << 8 | 6),
innodb_status_variables_export,
innobase_system_variables,
__null,
0,
},
i_s_innodb_trx,
i_s_innodb_locks,
i_s_innodb_lock_waits,
i_s_innodb_cmp,
i_s_innodb_cmp_reset,
i_s_innodb_cmpmem,
i_s_innodb_cmpmem_reset,
i_s_innodb_cmp_per_index,
i_s_innodb_cmp_per_index_reset,
i_s_innodb_buffer_page,
i_s_innodb_buffer_page_lru,
i_s_innodb_buffer_stats,
i_s_innodb_metrics,
i_s_innodb_ft_default_stopword,
i_s_innodb_ft_deleted,
i_s_innodb_ft_being_deleted,
i_s_innodb_ft_config,
i_s_innodb_ft_index_cache,
i_s_innodb_ft_index_table,
i_s_innodb_sys_tables,
i_s_innodb_sys_tablestats,
i_s_innodb_sys_indexes,
i_s_innodb_sys_columns,
i_s_innodb_sys_fields,
i_s_innodb_sys_foreign,
i_s_innodb_sys_foreign_cols,
i_s_innodb_sys_tablespaces,
i_s_innodb_sys_datafiles
,{0,0,0,0,0,0,0,0,0,0,0,0,0}};
这下就很清楚了,这段代码干了两件事:定义两个int变量和定义一个结构体。同时还把结构体里面两个常量给打印了出来,看过去清晰多了。同样道理,你还可以在#ifdef分不清走哪条路径的时候用这招,很好用的。