POLARIS · 引擎分析 · 基于单机数据库扩展的分布式查询处理引擎
Author: kunyu
引言
POLARIS是微软Azure Synapse的分布式查询引擎,由于近来数据的数量与多样性都在极快的增长,相较于传统数仓的ETL再进行分析的步骤,直接面向DataLake的数据分析服务在使用体验上较前者会更好,因此微软开发了POLARIS用于取代Azure的SQL DW,该系统主要一个比较有趣的点是系统的设计大量复用了已有的组件,整个引擎几乎到处都可以看到SQL Server的影子。
POLARIS的架构
POLARIS 的架构和snowflake 的架构似乎相似,都是为了彻底分离存储层与计算层,如图所示:
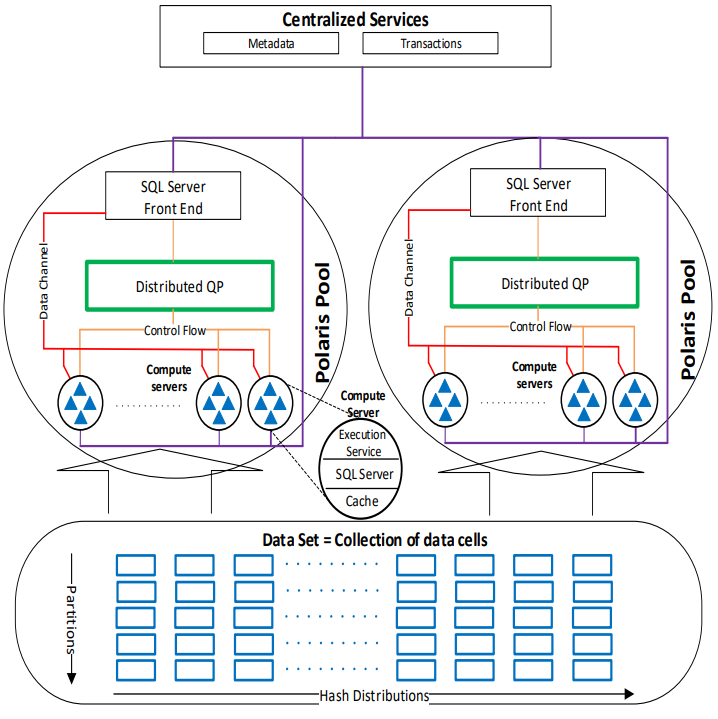
总体分三部分组成:
- 整个POLARIS的中心化组件,主要负责维护整个POLARIS集群的meta data与transaction信息
- Polaris Pool:这里是整个系统负责执行query的部分,每个Polaris Pool接受一条query之后先由分布式优化器进行优化,随后由分布式执行器负责将(图中的Distributed QP,文中也称做DQP)分发到执行节点去执行,图中的Control Flow负责推进query执行流程,Data Channel负责节点间的数据交互(query的中间结果)与返回最终结果。
- Data Set:是分布在存储上的大量的”data cell”,这里对数据同时做了哈希分区与partition,主要是为了加速查询,这点之后会提到。
Data cell与基于HASH和Partition的数据分片
data cell是一块数据的抽象,对cell的抽象细节在论文中并没有多讲,但是我猜测可能是一个类似与ToSQLServerTable()这样的接口,将若干data cell转换为SQL Server中的表放入compute server的local disk中,这样的好处是对上层的执行节点(SQL Server)改动比较小,比较符合整个系统的设计考量。
POLARIS对输入的数据做了双重分区,第一重是哈希分区,哈希分区的主要是用于拆分query到不同的分区执行;另一重则是通过用户自定义的partition进行分区(如果用户提供了partition算法),partition算法主要用于做pruning,减少不必要的数据访问,为每个compute server上的执行加速。
POLARIS的分布式查询
分布式优化器(DQO)
分布式查询与单机查询的一个区别是分布式查询需要将query分发到多个机器上执行(实际上单机上的并行查询也有类似的性质),这要求输入的数据必须按照某种方式切分,为此POLARIS引入了distribution properties,用来描述数据集的分区状况:
- $P^{[c]}$: 数据集P按照c列上的哈希映射到多个data cell。
- $P^1$: 数据集P的c列上所有值的哈希值相同,因此所有值都在一个data cell中。
- $P^{\emptyset}$: 数据没有做hash分区,多见于query的中间结果。
在这之后POLARIS引入了required distribution properties的概念,因为部分算子为了并行的执行,会对输入的数据分布有一定要求(比如hash join要求数据按key分区),这个词就是用来形容这些要求的,比如hash join的要求,用论文中这一套形容一下就是 \(P{\bowtie}^{a=b}Q: \{\{P^{[a]}\and Q^{[b]}\}\or P^{1}\or Q^{1}\}\) 这个性质要求join的两个表必须按照join key做分区,或其中一张表小到可以被广播到各个计算节点上,POLARIS中的很多算子都有对应的required distribution properties,为了使数据重新分布以满足这些要求,我们需要算子来对数据做re-partition,POLARIS为执行计划中添加了两个算子:
- HashOp: 记作$H_{d}$,意为对所有数据按d列的哈希值做重分区,结合前面的distribution properties不难得到$H_d(P^{*}) = p^{[d]}$
- BroadcastOp: 记作$B$,意为将多个cell的数据放进同一个data cell,并复制到多个data cell中,同时有$B(P^{*}) = p^{1}$
上面的Op是用来改变数据分布以符合算子的equired distribution properties的,现在我们通过在cascade optimizer通过为每个算子添加enforcer(即算子的required distribution properties),再给予HashOp与BroadcastOp合适的cost,单机数据库系统的优化器就可以用于处理分布式查询了,以下是优化器处理Join的一个例子,在枚举过程中,不满足required distribution properties的计划将会被丢弃,之后从可用的plan中按照cost择优选择即可:
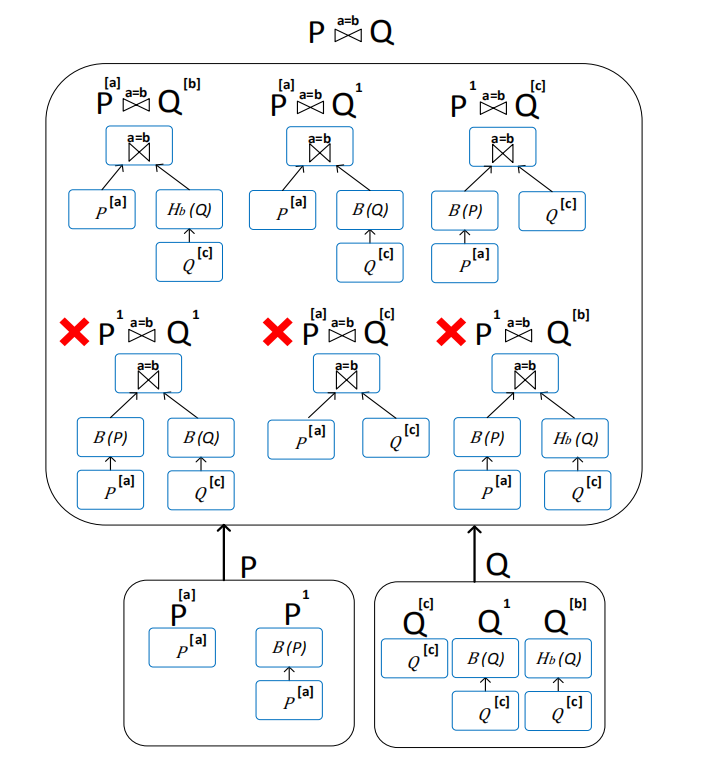
关于各个算子的required distribution properties文中附录都列举了出来,如果想要了解可以直接查看原论文的附录。cascade optimizer相关的概念可以参看Greenplum的优化器Orca,比较细致的讲解了优化器相关的概念
POLARIS的分布式执行引擎(DQP)
通过上文的分布式优化器,我们可以得到一个合适的物理计划,实际上,SQL中的查询计划可以视作一个有向无环图(DAG),无论是单机执行器还是分布式执行器,本质上都是自底向上执行查询计划中对应节点,POLARIS的执行流程很简单:自底向上执行每个节点,每个节点的执行会被拆分为多个task进行分布式执行,直到整个计划执行完毕,如图所示:
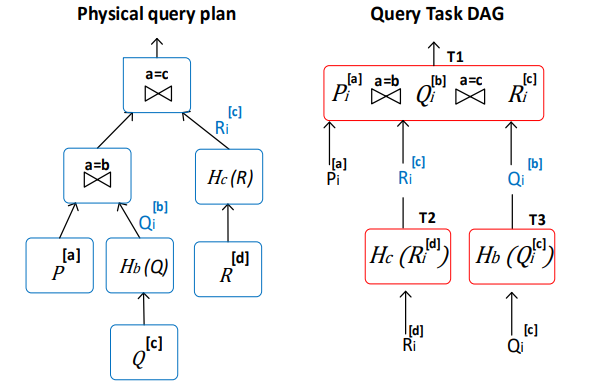
图中的红框部分是要执行的节点,每个节点会被拆分为若干task,每个task由3部分组成:
- Input: 一组输入的data cell,这些data cell可以存在远端的高可用存储中(比如S3),或者本地磁盘(远端存储的cache)中。
- Task template: 一段用于描述计算节点的任务的代码,结合之前的架构看,task template可能是是一段SQL,用于在计算节点的SQL Server上执行。
- Output: 与input一样,一组输出的data cell,可以是中间结果,也可以是返回给用户的最终结果。
我们现在可以基于task实现对query的分发,以下是一个Hash Join的例子:
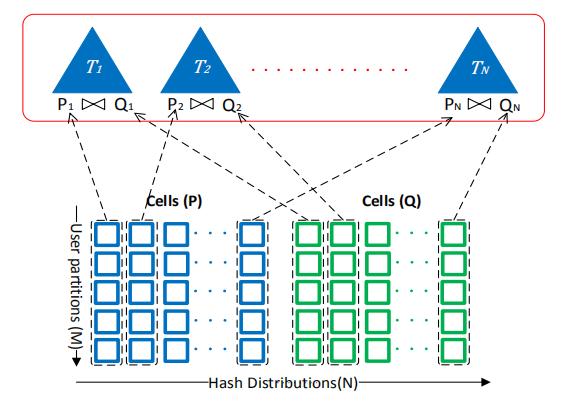
文中还提到了可以根据计算节点的缓存状况以及节点的负载来选择适合的计算节点执行查询,在POLARIS中,计算节点的execution service会提供提供相关信息给DQP,DQP将结合这些信息决定task分发到哪些计算节点执行
POLARIS的容错机制
上面两节已经描述了一个POLARIS集群在理想状况(没有节点故障,资源足够)下如何处理用户的查询,因此我们还需要处理一些现实世界中的分布式系统的常见问题:
- 确保集群能够容忍部分worker故障,因为分布式服务中单点发生故障的概率会随着集群规模增长而增加。
- 集群能够随时按需扩容缩容以弹性的提供服务。
- 有效的调度资源,保证及时处理并发请求。
这一节主要讲讲POLARIS如何解决这两个问题
容错与扩缩容
POLARIS的容错机制实现基于其计算存储分离的特性,其计算节点只负责两件事:
- 完成DQP分发的任务。
- 缓存部分数据到本次磁盘。
因此一旦某个任务超时或失败,我们可以在任意一个正常的节点重试部分任务,为了实现这一点,POLARIS将任务分为5种状态:
- run:任务正在运行
- blocked:目前当前任务不能执行,因为该任务的依赖任务还没有成功
- ready:任务的所有依赖任务都成功,等待被调度到run状态
- failed&success:任务完成与失败
查询的处理过程现在实际上已经变成了各个节点的状态转移过程,在这个过程种query DAG中各个节点的状态不断转移,直到根节点的状态变为success意味着query执行完成。通过在DQP层添加一个状态机,我们就可以优雅的实现任务的重试,从而实现我们的容错机制。从另一个角度看,状态机结合状态转移时的日志能够很容易复现调度与执行时的BUG,即使query很复杂也可以通过调度日志很好的发现问题。
下图左半部分是DQP节query task DAG对应的状态机:如果叶子节点的任务失败,就直接重试(failed$\rightarrow$run),如果是非叶子节点的任务失败,则分为两种情况:
- 如果仅自己的任务失败了,直接重试自己,和叶子节点相同。
- 如果是下面的依赖任务出了问题,比如机器故障导致取不到输入,那么block自身并重试子任务(图中的T1的虚线)。
下图右半部分则是一个执行query的例子,展示了POLARIS如何重试task以从失败中恢复
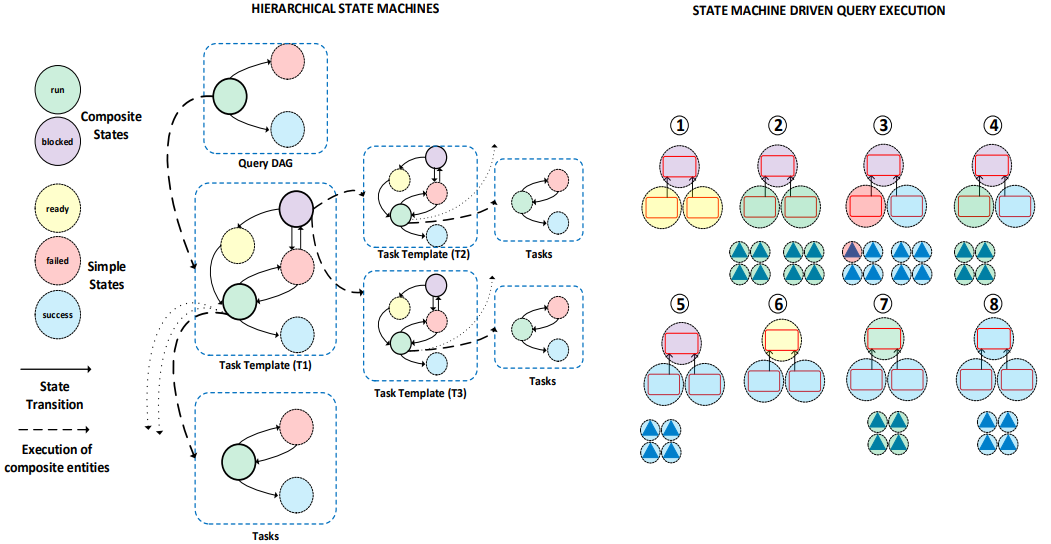
至于扩缩容,由于POLARIS的计算节点是无状态的,我们可以随时为集群增加计算节点,增加的节点不会影响增加时集群中正在运行的任务,新的查询将会基于扩容后的集群进行调度执行,缩容也类似。
POLARIS的资源调度
这一章讲讲POLARIS是如何实现基于资源的任务调度的,回想单个任务的调度情况:所有ready状态的任务以一定顺序执行完毕,随后他们的父任务状态将会改为ready并参与调度,现在由于资源有限,在调度执行之前需要检查一下任务需要的资源情况,POLARIS利用WorkLoad Graph来处理这个问题:
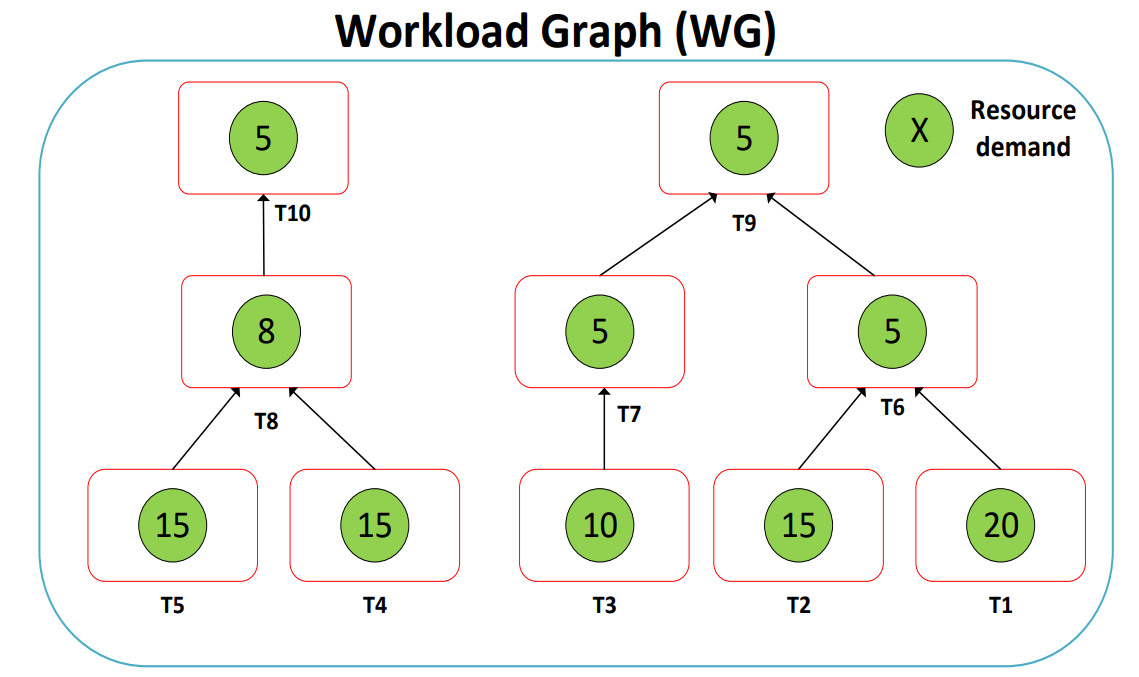
其实没有什么特别的地方,只是给每个查询计划对应的节点添加了一个所需资源数目的属性而已。在这里我们调度的实际上不是这两个查询,而是图中的10个task,我们需要决定哪些task允许被执行(ready$\rightarrow$run),因此我们的调度对象是所有状态为ready的task,考虑到这些,POLARIS给出了一个短小的调度算法:
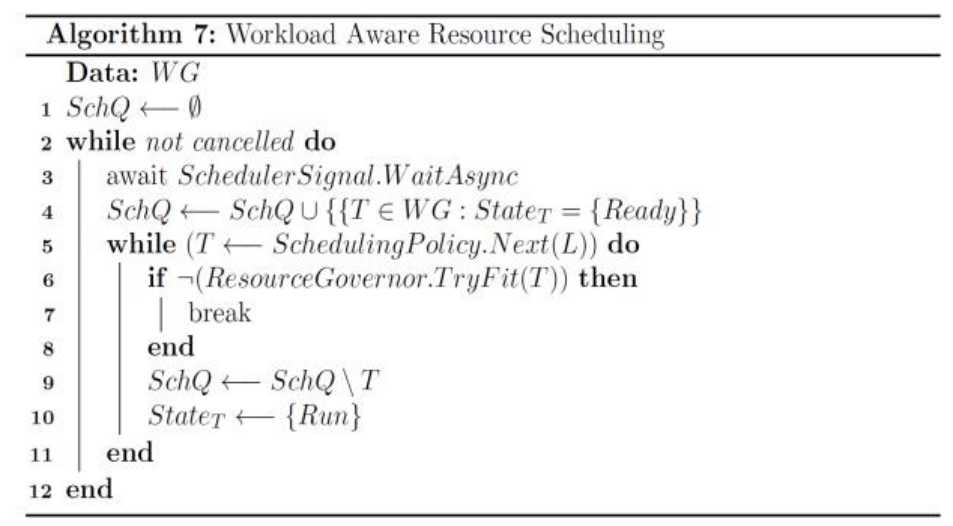
这个调度算法做的事情非常简单:每次被唤醒就将所有当前ready状态的task加入队列,然后依照调度策略取出下一个应该被执行的任务,如果我们能够满足资源要求,就执行该任务。
这个算法提供了一个调度策略的配置(图中的SchedulingPolicy),文中提到了三种调度策略:
- FIFO:很经典的策略,好处就是公平,能够保证一个相对还行的响应时间
- sorted by resource demand:按照task所需资源多少排序,比较类似于worst Fit算法,目的在于减少资源碎片,坏处则是可能会产生饥饿。
- sorted by proximity to the root:按照任务在task DAG中的位置排序,最靠近根节点的任务最先执行,这个策略的目的在于尽快完成简单的query,这样可以释放掉query level的资源,坏处和楼上一样,复杂的query可能很长时间不能完成。
这个问题实际上和内存分配的策略是相似的,所以不同的策略实质上是资源利用率/响应时间的取舍
总结
POLARIS和snowflake同为云原生数仓,整体的架构实际具有相似性,但是除此之外,论文清晰的向我们阐述了如何从单机数据库(SQL Server)演进到云原生数仓,对于从单机分析型数据库出发转向分布式数据库的产品有一定参考意义
参考文献与相关资料
- POLARIS: the distributed SQL engine in azure synapse. Proc. VLDB Endow. 13, 12 (August 2020), 3204–3216.
- The Snowflake Elastic Data Warehouse. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD ‘16).
- Orca: a modular query optimizer architecture for big data. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD ‘14).