SQL Server · 引擎特性 · 从SQL Server看列式存储
Author: 柒沐
1. SQL SERVER Column Index存储进展
自2012年以来,SQL Server的Column Index在存储层设计上有了几个大方向上的进展:
- secondary/primary column index开始支持更新
- 压缩:
- 归档压缩
- 延迟压缩: 当内存的row group写满后先静置一段时间再压缩,这样压缩时就可以过滤掉那些在静置期间被删除的行,row group的有效行填充率会更高,相应的memory/IO效率就更高
- 组合索引增强
- Data warehouse场景:column index作为primary index,使用nonclustered btree index增强constraint check和seek
- HTAP场景:column index作为secondary index增强OLTP workload下的分析能力
- Snapshot Isolation
- Deframent/Compaction
| Functional | Performance | Paper | |
|---|---|---|---|
| 2012 | 只读secondary column index | 略 | 《SQL Server Column Store Indexes》 |
| 2014 | 可更新primary column index;归档压缩,压缩率好一些,但查询慢一些; | 略 | 《Enhancements to SQL Server Column Stores》 |
| 2016 | 1.可更新secondary column index;2.可以在primary column index上架secondary btree index来做unique check和seek;3.可根据filter针对部分行加secondary column index; | 1.Snapshot Isolation;2.Defragment(碎片整理);可以在Replica上访问column index; | 《Real-Time Analytical Processing with SQL Server》 |
| 2017 | 略 | 略 | 略 |
| 2019 | 可merge多个空洞的row group (Compaction & Flush) | 略 | 略 |
2. Updateable Columnstore Index设计概述
列存和行存不同的点在于数据的物理组织形式,主要体现在以下两点:
- 列存数据数据按列分割存放
- 列存数据一组连续存放的数据数据量比较大
基于这两点就可以充分发挥基于单列的压缩能力。同时执行从存储fetch数据时,可以精准fetch某一列的数据,memory和IO的利用效率更高。也更适合batch execution,batch execution一般来说有10倍以上的性能提升。
为支持更新,列存也需要索引结构辅助,列存可以用和行存一样的索引组织形式。行存的索引组织形式可以分为:
- 非聚簇索引:HeapTable,也就是非聚簇索引(一般是btree)加无序数组
- 按PK聚簇索引:
- Clustered Btree Index
- LSM
2.1 列式HeapTable
- 思路:非聚簇btree index不变,unordered array按照列纵向分割存放数据,且横向行数分割的粒度也可以比较自由地选择,比较好拓展到列存。
- 例子:
- SQL Server和in-memory table的secondary column index
- Oracle dual-format in-memory database
2.2 列式Clustered Btree Index
- 思路:理论上叶子节点中的行可以按照列分割存放,但一下几点原因导致这种方式不太可行
- 列式存储要求我们一个row group的数据量要比较大,这样才能充分发挥压缩效果,但如果叶子节点包含的数据行数扩大,相应的seek能力也就减弱很多,聚簇btree index就失去了维护的意思
- btree本身就是update-in-place,叶子节点按列划分进一步放大了btree写入的随机IO
- 聚簇btree index的叶子节点会频繁split/merge,也就是即便在写满后结构仍然会发生变化,也就意味着频繁的压缩与解压,对写入非常不友好
- 例子:目前没有这种结构的列存
2.3 列式LSM
- 思路:
- LSM是天然的Delta+Base的形式,Delta可以缓存一个row group的数据后再Flush到磁盘
- 磁盘里的sstable(Rocksdb命名方式,可以理解为是一个有序数组)的数据可以按照列分割,横向切割粒度sstable的size也是可以比较自由地选择的,比较好拓展到列式存储
- 虽然LSM的进行归并排序,但这种结构重整比Clustered Btree Index的split/merge频率会低很多,且是一种后台行为,可以动态调整。
- 例子:
- Clickhouse
- Hologres
- TiFlash
2.4 Unordered Array+Delete Map
思路:还有一种更简单粗暴的方式是简单维护按列为单位的无序数组和一个delete map,数据不会按照键值聚簇,写入时直接追加到数组末尾,现在内存中缓存到一个row group的数据后再压缩写盘。但这种方式的更新删除能力很差,需要扫描全表定位出要删除的行,因此只适合于以插入查询为主的数仓场景。
例子:SQL Server Column Index
3. 删除与更新
删除与更新是列式存储的难点。列式存储往往将一大批数据作为一个row group进行压缩再落盘,因此列式存储的删除往往是标记删除,更新是删除加插入,来避免频繁的解压压缩和写放大。
3.1 列式HeapTable
3.1.1 As Primary Index
和行式Heap Table一样我们需要一个额外的索引结构来定位要删除的行号,得到行号后可以通过delete mask或者已删除行号集合来过滤不需要的行。
3.1.2 As Secondary Index
此时列存作为行存主键索引的二级索引,我们不再需要额外的索引结构来定位要删除的行,只需要将行号维护在主索引的记录里,删除时先根据主键在主键索引中定位到行号,然后再通过delete mask或已删除行号集合来过滤被删除的行。SQL Server基于全内存行存表的列存二级索引就是这种实现方式。
3.2 列式LSM
Clickhouse无法支持实时更新,这里就介绍支持实时更新的列式LSM Hologres和TiFlash,并对两者进行一下对比。
3.2.1 Hologres
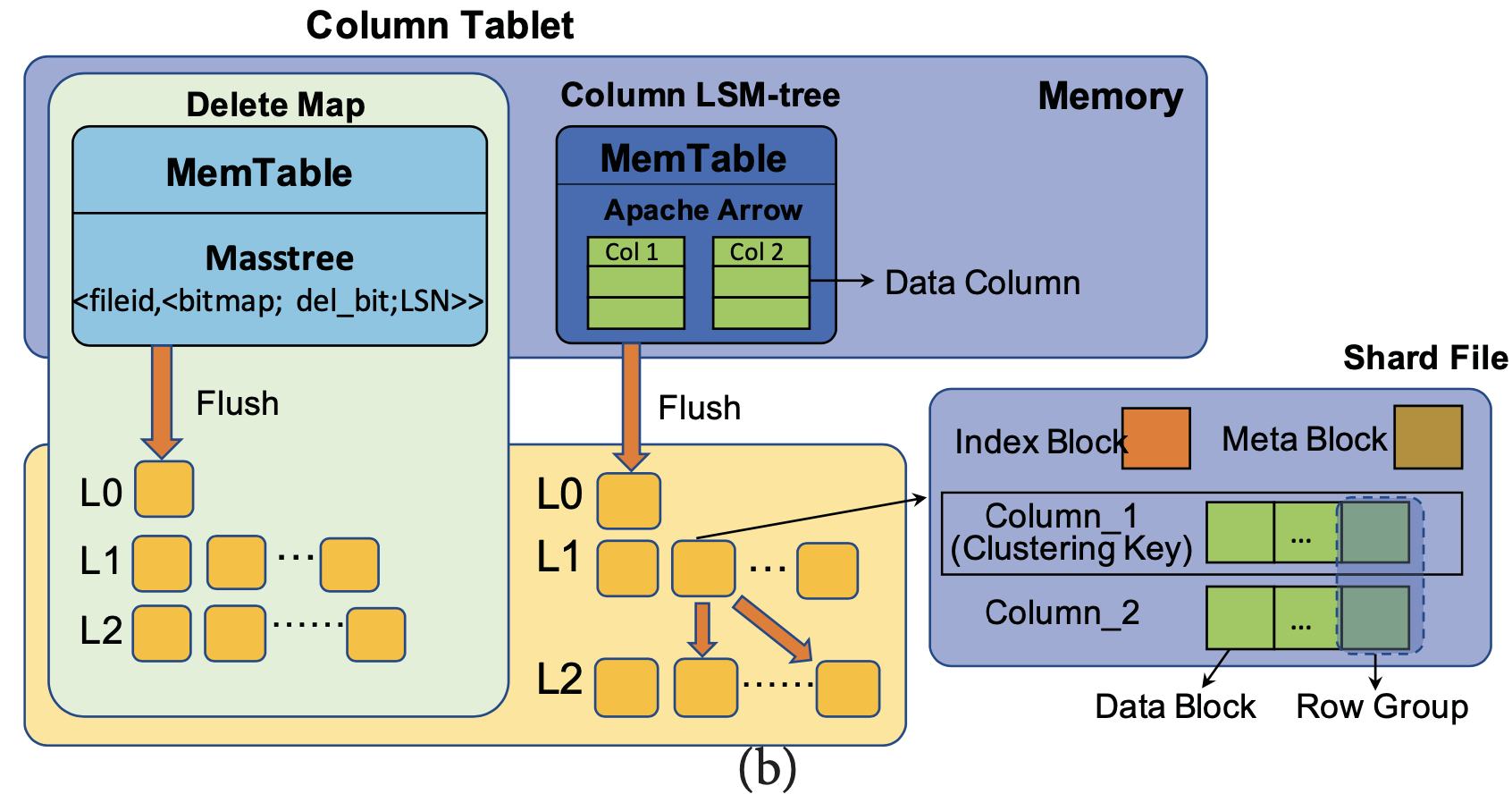
Hologres支持KV接口和AP查询,存储层类LSM,主键是主键映射记录,二级索引是二级索引列加主键列为key,value为null。和SQL Server一样,主键索引和二级索引都支持行存形式和列存形式。行存形式就是典型LSM架构,
下面主要介绍下列存形式(以主键索引为例)。Hologres的shard file可以理解为RocksDB的sstable,且只是每列的datablock是单独连续存放的。同时有个delete map的LSM组件用于维护delete操作,该LSM的key为shard file的ID,value中包括了bitmap表示该shard file中哪些记录被删除。读取shard file时会根据read sequence产生一个visible bitmap,同时merge delete map中该shard file ID的bitmap生成一个delete bitmap,merge visible bitmap和delete bitmap来过滤不可见和已删除数据。更新时先seek到旧行,然后还原出更新的新行,按照删除流程删除旧行,然后将新行从前台写入。
并且,shard file间不会有primary key的overlap,因此Hologres扫描时不需要对shard file进行归并,只需要根据bitmask过滤,也就可以并行扫描。
3.2.2 TiFlash
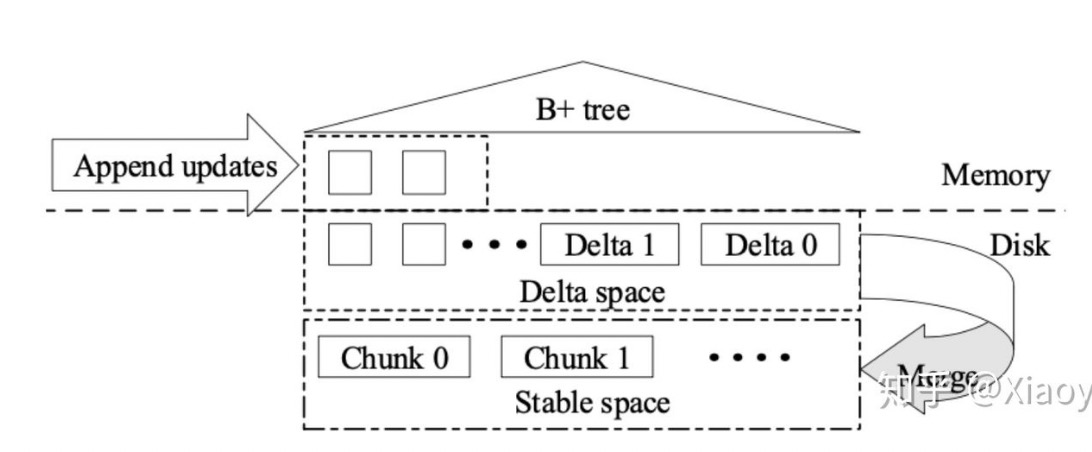
TiFlash的可更新列存引擎DeltaTree设计思路:
- 首先数据会按照主键排序来分区,每个分区如下图所示,当分区物理大小超过阈值时会分裂
- 更新append到内存的buffer后会flush到delta space中,因此delta分片里的数据是按照append顺序排布的,并非根据主键聚簇
- delta分片积累到一定量后会被排序归并到stable space中
- 因此扫描是需要归并stable space、delta space以及memory中的数据,由于delta数组组织是无序的,归并前就必须先进行排序,为避免scan前对delta的排序,在内存中维护了一个btree index来维护delta数据的逻辑顺序
3.2.3 小结
Hologres相比于TiFlash的更新开销更大,但扫描时不需要归并,且可以并行扫描。
3.3 Unordered Array+Delete Map
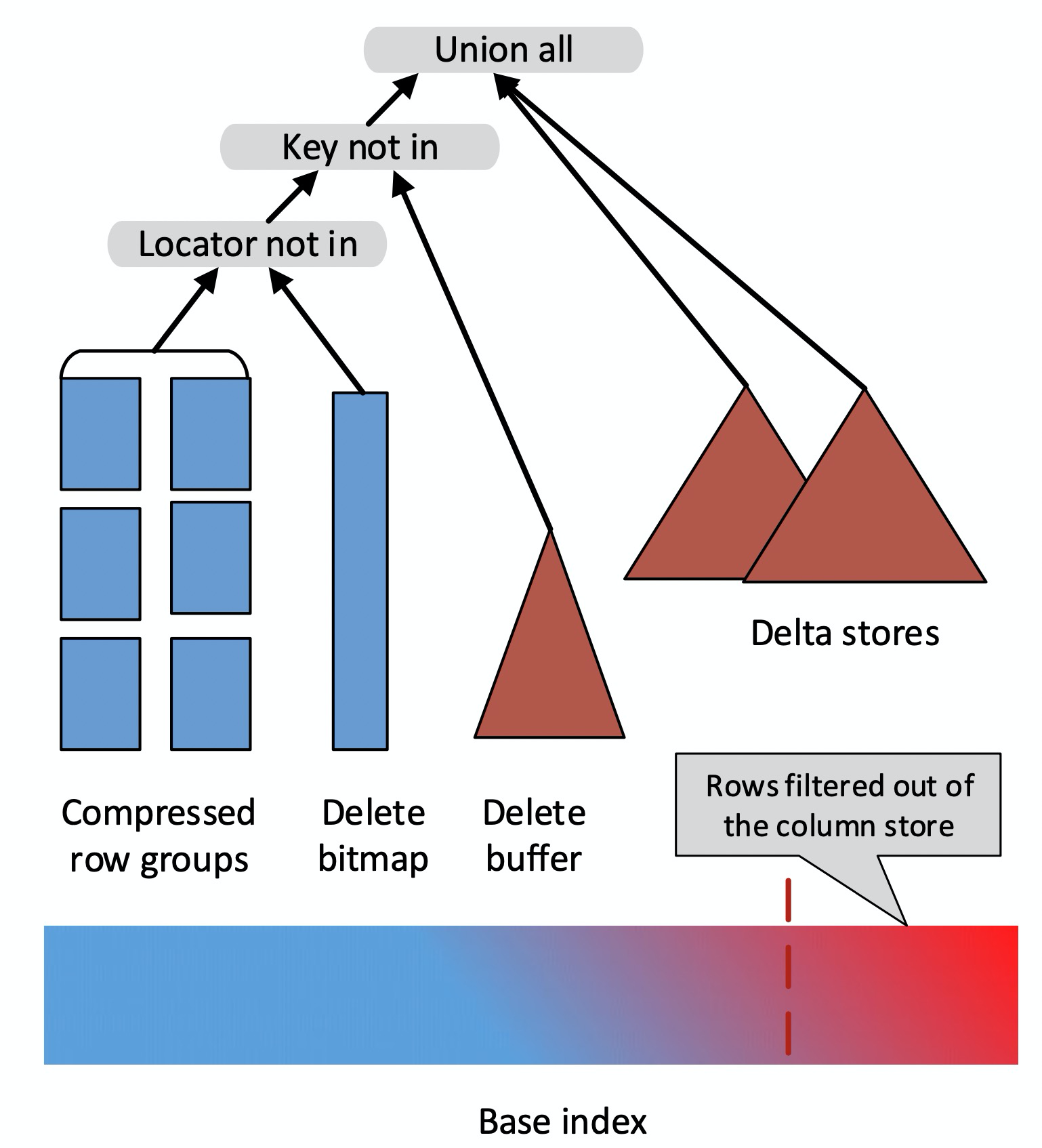
SQL Server的columnstore index作为主索引或者磁盘行存表的二级索引时就是以这种方式实现的。SQL Server做了几点优化来缓解这种设计的删除劣势:
- delta store是内存里的clustered btree index,用来缓存最热的数据,这部分数据删除是update-in-place的
- 由于column store只是简单的数组,没有索引用来定位要删除的行,每次删除必须要扫描整个column store,删除效率很低。为此,引入了delete buffer,要被删除的primary key会先缓存在delete buffer,然后批量scan更新到delete bitmap上
- scan时就merge rowgroup、delete buffer、delta store三部分的数据。
4. 列存实现选型
4.1 两大列存场景
4.1.1 HTAP
如果我们需要针对一个现有的行存表上的数据做分析,ETL到data warehouse是最常规的操作模式,但其中有几个挑战点:
- Complexity: 需要定期将增量数据从TP ETL到warehouse,这个增量判断比较麻烦
- Cost: 这个ETL有额外的通道开销,比如阿里的DTS
- Data Latency: 分析至少要delay一个ETL的时间
这时我们可以选择在现有的行存表上加一个secondary column index支持实时的AP分析。secondary column index和普通的二级索引一样,会跟着primary index保持实时更新。 这种方式的代价是多了一份列式存储数据,但由于列式存储的压缩能力强很多(压缩率基本在10倍以上),column index这份额外的空间开销不是1倍,几乎只是十分之一。带来的优势是:
- 不需要ETL,列存数据基本可以认为是实时同步的
- 甚至我们可以把行存数据和列列存数据放在不同的节点上,来进一步地隔离TP更新任务和AP分析任务的资源,比如SQL Server可以在Replica上跑AP分析,Oracle在standby上跑AP分析。
列存二级索引与普通行存二级索引的区别? 列存二级索引适合scan,不需要保序,maintain cost也更小一点,行存二级索引则更适合seek。
4.1.2 Data Warehouse
workload以insert和query为主,更新较少,此时我们可以只用一份columnstore index作为primary index,同时支持大量insert/query和少量更新。
4.2 实现选型
理论上上文介绍的几种列存实现都既可以作为primary index也可以作为secondary index,那么我们针对这两种不同的列存实现要如何进行列存实现的选型(列式HeapTable/列式LSM/无序数组+delete map)。
4.2.1 HTAP
HTAP下会有频繁的数据更新,因此我们可以首先排除无序数组加delete map这种更新能力很差的实现方式。接下来我们就需要对比列式HeapTable和列式LSM。 由于在HTAP场景,列存只是作为行存表的一个二级索引,seek/small range query可以回退到行存上,因此从查询角度上来说我们只需要关注columnstore index的scan能力。
因此,我们只需要从scan/maintain cost两个角度来衡量对比即可:
- 全量Scan:取决于列式LSM的删除实现,Hologres的扫描方式和列式堆表基本相同,TiFlash扫描需要归并效率就比列式堆表低。总的而言,列式HeapTable的扫描能力大于等于列式LSM
- 基于某个partition/order key的扫描:列式LSM可以按照order key进行聚簇,比如Clickhouse,此时列式LSM只需要扫描一段数据,但列式堆表就需要全量扫描
- maintain cost: 列式堆表和列式LSM的maintain cost类似于行式,insert比较多时列式LSM maintain cost更小,删除更新比较多时列式LSM maintain cost更小
小结:除了分区对聚簇有依赖,列式堆表比列式LSM更适合HTAP场景
4.2.2 Data Warehouse
在dataware house场景下,我们以columnstore index为主索引,在这种场景下,我们可以先忽略列存的更新能力的强弱,只要能更新即可,那么这三种实现方式都符合要求。 其次在单一存储上,seek/small range query没有行存能够回退。因此,我们衡量时也需要考虑下seek/小范围查询的能力。因此,我们从seek&small range query/scan/maintain cost三个角度来衡量对比:
- seek/小范围查询:列式堆表虽然不是物理有序的,但是是逻辑全局有序的,且由于seek/小范围查询涉及的行比较少,能力上来说列式堆表 >= 列式LSM >= 无序数组+delete map
- 全量Scan:不考虑删除更新,全量扫描这三者的能力是一样的
- 基于某个partition/order key的扫描:能力上列式LSM > 列式堆表 == 无序数组+delete map
- maintain cost:不考虑更新,cost上 无序数组+delete map < 列式LSM < 列式堆表
SQL Server在无序数组+delete map的实现上添加了nonclustered btree index来弥补seek/小范围查询能力。
小结:在data warehouse场景下,数据量比较大,因此需要对数据分区的可能性更大,也就更适合用列式LSM。此外就需要从各个角度衡量综合判断考量。
Reference
- https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-overview?view=sql-server-ver15
- Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing
- Oracle Database In-Memory on Active Data Guard: Real-time Analytics on a Standby Database
- SQL server column store indexes
- Enhancements to SQL Server Column Stores
- Real-Time Analytical Processing with SQL Server
- https://zhuanlan.zhihu.com/p/360750135
- https://zhuanlan.zhihu.com/p/170016220
- https://zhuanlan.zhihu.com/p/205663113