DataBase · 理论基础 · HTAP列存引擎探秘
Author: 顾绅
背景
TP查询和AP查询具有截然不同的特点,促使TP数据库和AP数据库采用不同的设计理念。然而,在一些业务中,事务处理的同时往往会伴随一些分析型的查询,传统的解决方案是由TP数据库进行事务处理,通过ETL将数据导出到AP数据库来服务分析型查询,但是这样的解决方案具有同步延时高、架构复杂、运维难度大、成本高的缺点。在这样的背景下,HTAP数据库应运而生,成为了学术界和工业界关注的热点。
本文中,我们调研了一些有代表性的HTAP数据库列存引擎实现,分析并总结了HTAP列存引擎的设计选择。
SQL Server:基于索引组织表的列存
SQL Server最初是一个OLTP的DBMS,从SQL Server 2012开始逐渐增强了OLAP和In-memory OLTP的能力,经历了从面向数仓的Read Only Column Index到支持更新的Column Index再到In-memory HTAP的发展过程。本节主要关注SQL Server的In-memory HTAP。
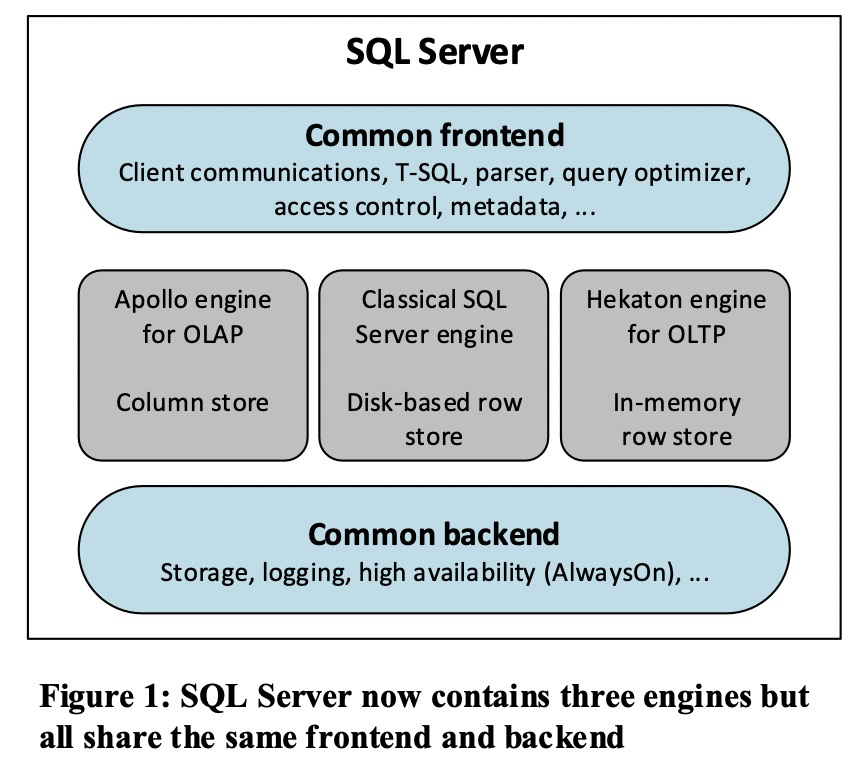
SQL Server通过引入Apollo Engine for AP和Hekaton for In-memory TP来实现In-memory HTAP,其中Hekaton的行存表是基于BwTree的索引组织表,列存和行存通过在行存表中加上一个字段存储每一行对应记录在列索引中的RowID联系在一起,即利用行存的索引来作为列索引的辅助数据结构。
在这样的存储设计下,行存中存储全量数据,列存分为Tail Index和Column Store Index(CSI),其中CSI以列的形式存储绝大部分数据,并以Row Group为单位划分,每个Row Group对应行存中一定数量的记录,Tail Index则索引行存中还没有迁移到CSI的数据(这部分数据被称为tail of the table,这也是被称为Tail Index的原因)。CSI以append-only的方式更新,借助被称为Delete Mask的bitmap标记删除,Tail Index则支持原地更新删除。事务插入数据时,会同时插入行存和Tail Index,并且记录还没有迁移到CSI时是不会分配RowID的,只有迁移到CSI时才会分配RowID。而事务删除数据时,如果记录被Tail Index索引,则直接在行存和Tail Index中删除,如果在CSI中,则需要根据行存中存储的RowID在Delete Mask中标记删除。更新则通过删除+插入实现。列存scan需要扫描CSI,并根据Delete Mask剔除已删除数据,还需要通过Tail Index从行存表中获取未迁移到CSI的数据进行扫描。
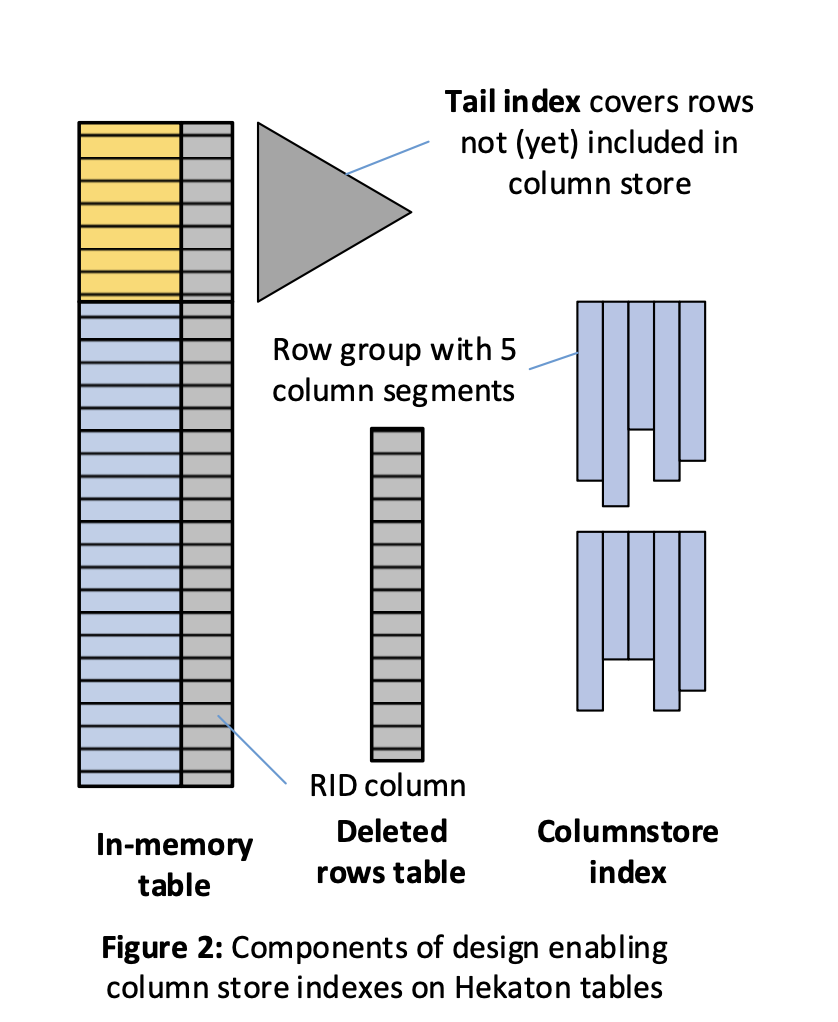
当Tail Index索引的数据达到一定阈值后会将其中较冷的数据迁移到CSI,冷热通过统计信息来判断。同步分为两个阶段:
- 第一阶段在一个事务中完成,将冷记录转为列索引,分配RowID并在Delete Mask中标记删除。事务提交后迁移的部分在CSI中不可见,但在Tail Index中依然可见,数据是一致的。
- 第二阶段在一些小事务中完成,每个事务将第一阶段迁移的一条记录从Tail Index中删除,将对应的RowID更新到行存,并删除这条记录在Delete Mask中的标记,事务提交后这条记录在CSI中可见,但在Tail Index中不可见,数据也是一致的。
SQL Server从两个方面来减少数据迁移对行存性能的影响:
- 第二阶段更新行存中RowID时不记日志,恢复时通过扫描列存重建RowID,减少日志开销。这里我觉得实际上是一个trade-off,不记日志减少运行时开销,记日志可以配合对行存和列索引做checkpoint支持fast start。
- 第二阶段每个事务只处理一条记录,减少与前台事务的写-写冲突。
CSI中标记删除的记录会影响scan的性能,也会带来额外的内存开销,因此需要进行重整。CSI上的重整由Row Group中标记删除的比例触发(90%),由后台任务将触发重整的Row Group中的有效记录重新插入Tail Index中,随后和其他前台写入的记录一起被迁移到CSI形成新的Row Group,而重整的Row Group则被回收。
这样的存储设计有两个优点:
- 借助行存实现高效删除,复用行存索引做列存的辅助数据结构,维护PK到RowID的映射,更新删除时可以借助这一层行存到列存的映射快速找到列存中的对应记录进行标记删除。借助行存实现列存上高效的标记删除也间接提升了列存scan的效率,因为append-only方式更新的列存scan后不再需要归并得到事务可见的结果。
- 复用行存的事务处理机制,保证跨行存和列索引上事务的ACID,同时很好地支持unique check。
缺点也很明显:
- 更新CSI和Row Group重整带来一定开销,更新CSI采用append-only的方式进行,产生额外的内存开销,而且两者都需要更新行存中的RowID,因此都会和行存的TP事务产生竞争,影响系统整体性能。
Oracle:基于堆表的列存
Oracle从12c版本开始就通过在堆表(Heap Table)上建立In-memory Column Index(IMCI)来支持HTAP。实际上包括堆表在内,Oracle中的表一共有三种组织形式:
- Heap Table:表和主键索引分开存储,记录在表中的存储是无序的,每个记录有一个RowID唯一标识,主键索引存储的是主键到RowID的映射。
- Index Organized Table:表存储在主键索引中,记录存储在主键索引的叶节点中,和Innodb是类似的。
- Clustered Table:多个表按连接键的顺序存储在一起,方便join。
但Oracle IMCI只能在堆表上建立,后面我们会看到,堆表会给IMCI的建立和维护带来很大的便利。
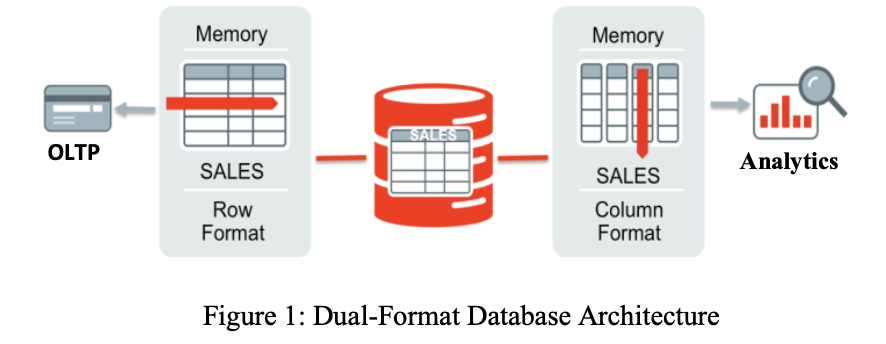
Oracle IMCI实际上是堆表在内存中的列式缓存,和原有的行式缓存一起,形成了“一份数据,两种缓存”的架构。堆表中的数据以IMCU(In-memory Compression Unit)的形式缓存在内存中,每个IMCU对应堆表中若干个DataBlock,因为堆表上Insert不会改变原有数据的组织形式,而Update和Delete又可以原地进行,所以实际上IMCU和Datablock之间的映射关系是不会改变的,也不需要额外的数据结构维护这个映射关系。构建IMCI的过程称为Populate,Populate可以在数据库初始化时进行,相当于缓存预热,也可以在运行时进行,相当于数据第一次被访问时加载进缓存。
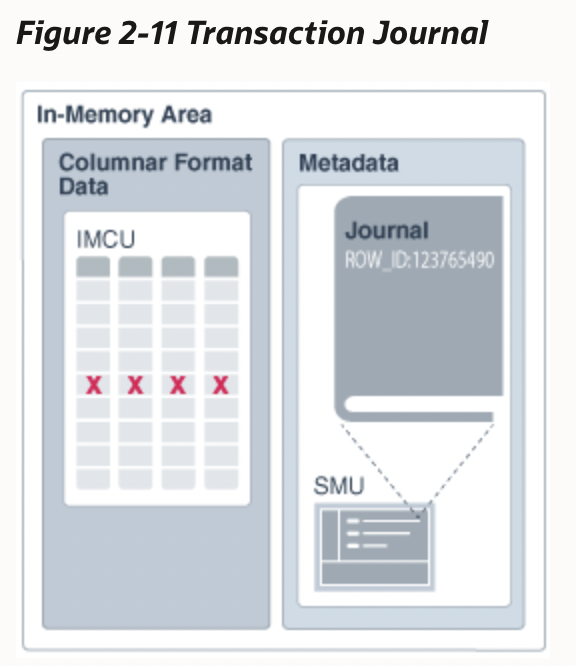
每个IMCU还有一个与之对应的SMU(Snapshot Metadata Unit),用于存储一些元信息,比如记录数量,Min/Max等,另外还会存储用于处理更新的Transaction Journal。当堆表中记录发生更新时,不会立即去更新IMCU中的对应内容,而是会在Transaction Journal中记录RowID和System Change Number(SCN,类似Snapshot)。在IMCU上scan时,如果遇到记录的RowID在Transaction Journal中存在,则需要在Transaction Journal中找到当前事务可见的RowID,根据这个RowID去堆表中获取更新后的数据,以此实现事务的一致性和隔离性。
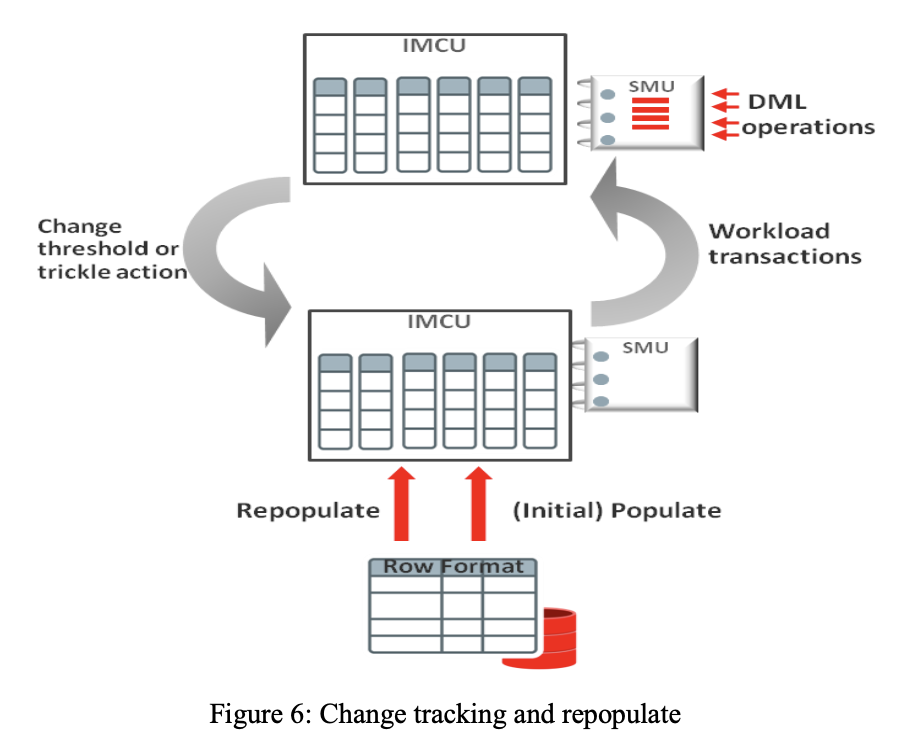
虽然堆表中的更新可以只写Transaction Journal,但是当Transaction Journal中存储的记录增加时,IMCU上的scan性能也会下降,因此还是需要将堆表中的更新实际应用到IMCU上,这一过程称为Repopulate。由于IMCU和堆表Datablock之间的映射关系是不会改变的,所以Repopulate只需要加载对应的Datablock建立新版本的IMCU来替换旧版本的IMCU。Repopulate会由两种方式触发:
- 根据IMCU的访问频率和Transaction Journal中的记录量,通过一个启发式算法触发。
- 后台线程定时扫描,触发未达到启发式算法阈值的IMCU的Repopulate。
相比SQL Server在索引表上构建类似Delta-Main架构的列索引,在堆表上构建列索引的优势就在于堆表上的Insert/Update/Delete不会影响数据组织形式,因此堆表中DataBlock和对应的列式缓存IMCU之间的映射关系不会改变,带来两个优点:
- 轻量的列索引更新:更新只要记录Transaction Journal,可以很方便地通过RowID从堆表中获得更新的记录,内存开销较小,对TP事务的影响也较小。
- 轻量的列索引重整:重整只要重新加载对应DataBlock,和行存的TP事务不会产生竞争。
SAP HANA:同时服务TP和AP的列存
SAP HANA是Delta-Main架构的HTAP数据库,以列的方式存储一份数据,并以列存同时服务TP和AP查询。其中Main Store是面向读优化的,而Delta Store是面向写优化的,Delta Store进一步分为L1-delta和L2-delta两层,L1-delta是行存,支持高效更新,而L2-delta则是append-only方式更新的列存。
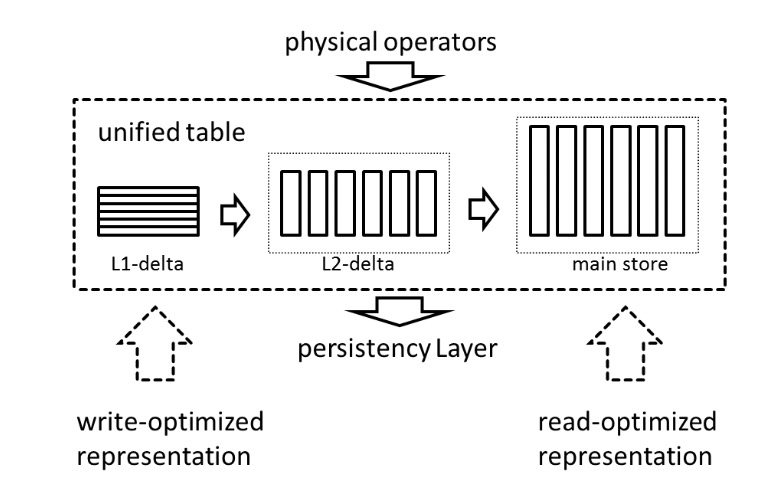
数据在L2-delta和Main Store中并不是使用朴素的列式存储,而是使用Domain Coding的方式压缩列式存储。SAP HANA会为每一层中的每一列的所有字段构建一个字典,并为每一个字段分配一个Value ID,每一列不再存储列的原始数据,而是将对应的Value ID存储在Data Vector中,并且采用Bit Packing压缩。SAP HANA还支持在Bit Packing的基础上对Data Vector应用其他压缩方式,比如RLE,Sparse Encoding,Indirect Encoding等。面向写优化的L2-delta的字典是无序的,而面向读优化的Main Store的字典是有序的,有序字典还可以进一步使用前缀编码。
更新的数据会先写入到L1-delta中,L1-delta的数据达到阈值后进行L1-to-L2-delta Merge,以append-only的方式将记录合并到L2-delta。合并记录时会首先检查L2-delta的字典中是否已经包含要迁移的字段,如果包含则直接将对应Value ID追加写入L2-delta的Data Vector,否则需要先将字段追加写入到字典并分配Value ID。L2-delta的数据达到阈值后进行L2-delta-to-main Merge,将L2-delta和Main Store的字典合并并排序,再合并两层的Data Vector,回收事务不可见的无效数据。
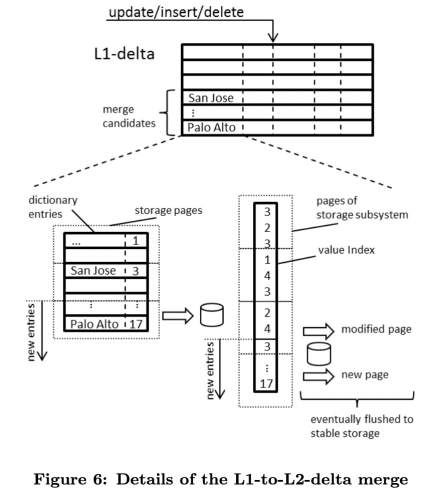
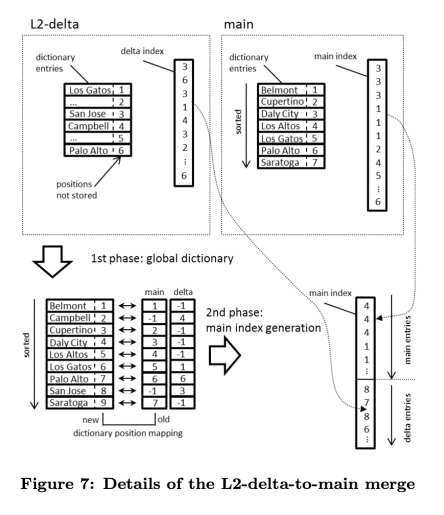
列存scan需要扫描三层,扫描L2-delta和Main Store时先扫描字典,然后根据得到的Value ID扫描Data Vector得到对应记录,最后归并得到事务可见的正确结果。SAP HANA还可以构建Inverted Index,存储Value ID到Data Vector中出现这个Value ID的位置,加速根据Value ID搜索对应记录的过程。
SAP HANA最初是一个全内存的数据库,通过redo和savepoint做持久化,随着数据量的增大,又引入了磁盘的存储形式(Piecewise columnar access),虽然各个模块可以在全内存形式和磁盘形式之间转换,但是因为存储格式的差异,转换的开销很大,难以在不同工作负载下进行动态调整。因此SAP HANA引入了统一持久化格式(Unified Persistency Format),统一持久化格式提供了一系列兼容字节寻址的基于页的基本存储单元,列存的各个模块通过这些基本存储单元进行组织,在全内存形式和磁盘形式之间转换时不需要改变存储格式,只需要在内存中分配连续的内存将磁盘上的内容拷贝到内存中,或者将内存中的数据写入磁盘。
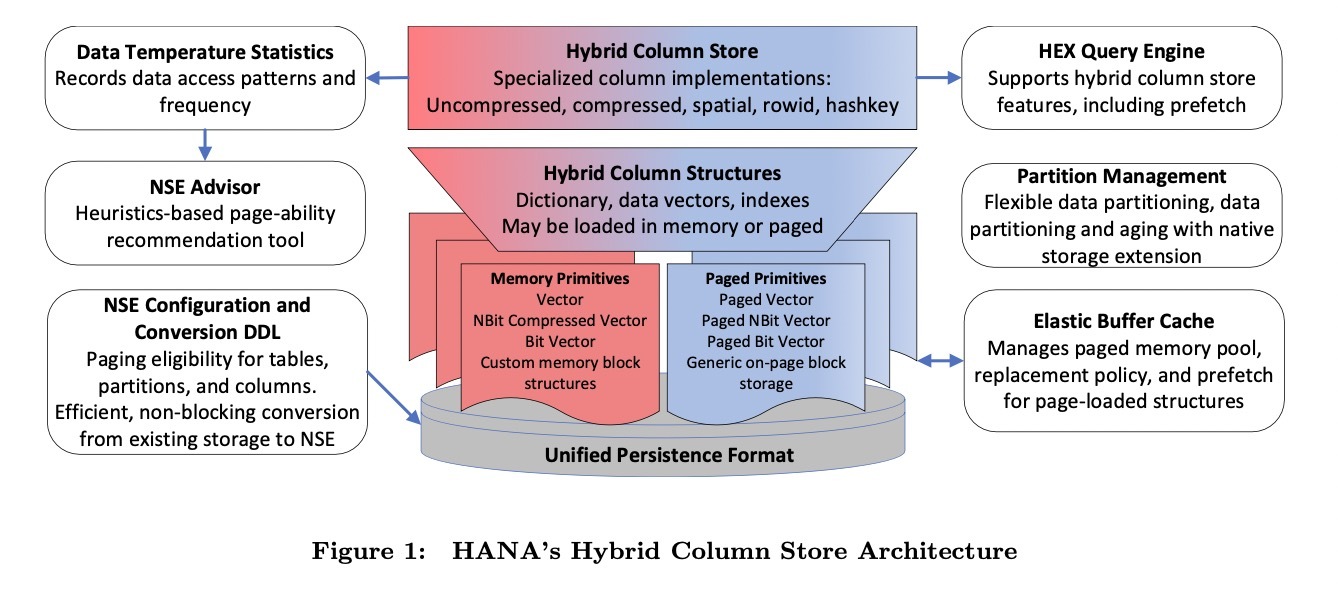
SAP HANA这样的设计优势和缺陷都很明显,优势是:
- 能获得较好的压缩率,降低内存和磁盘成本,Domain Coding的字典可以有效避免重复字段的冗余存储,有序的特性非常适合前缀编码取得优异的压缩效果,Data Vector中的整数应用Bit Packing以及附加的其他整型压缩算法也能取得比较好的压缩率。特别是当表中有大量重复字段、默认字段、空缺字段时效果特别明显,而这样的表在AP场景中是比较常见的。
- 系统具有较好的弹性,能够适应资源受限的场景,借助统一持久化格式,各个模块都可以采用混合存储的模式,在全内存形式和磁盘形式之间动态转换,适应不同的硬件环境
缺陷是由于没有行存的聚簇索引,点查询和unique check的代价比较高,并且列存scan时需要归并获得正确的查询结果,效率较低。
TiFlash:与行存松耦合的列存
TiDB是基于Raft的HTAP数据库,行存数据存储在TiKV中,列存数据存储在TiFlash中,行存和列存的松耦合,通过异步复制Raft log的方式将更新从行存同步到列存,列存不参与Raft协议的日志提交和leader选举,因此列存几乎不会对行存产生影响。
TiFlash根据主键范围将表划分为不同的partition,每个partition采用类似LSM-tree的Delta tree存储。划分partition的目的是为了减少一个Delta tree存储的数据量,使得Delta tree只需要两层,相对多层的LSM-tree能有效减少读放大。随着数据量的变化,partition也会被进一步被划分或合并,保持每个partition的数据量在一定范围内。
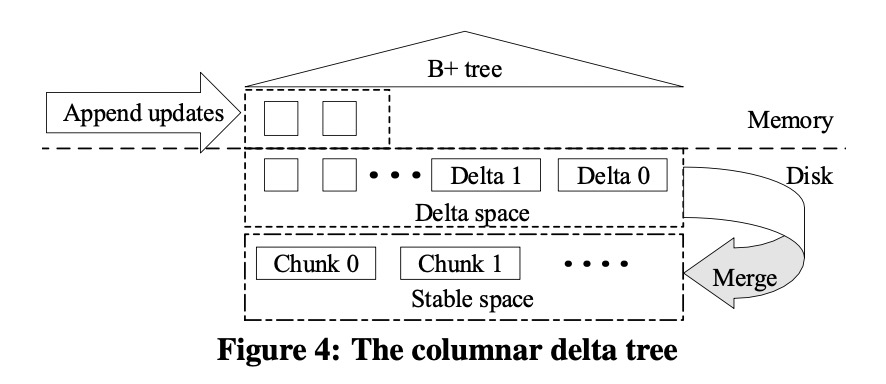
Delta tree中的两层分别被称为Delta Space和Stable Space,其中Delta Space中的数据是无序的,和Raft log中同步的顺序一致,而Stable Space中的数据是全局有序的。更新会以追加的方式写入内存中的Delta Cache,写满之后持久化到磁盘上的Delta Space,当Delta Space写满后则会和Stable Space进行合并。列上的scan需要扫描Delta Space中的多个文件和Stable Space,由于采用追加写入的更新方式,扫描的结果中一条记录可能存在多个版本,需要进行归并得到事务可见的正确结果。
由于Delta Space中数据是无序的,因此Delta Space和Stable Space合并以及scan后归并得到正确结果的过程相对LSM-tree会产生很大的额外开销,Delta tree通过引入基于B+tree的Delta Index来解决这两个问题。Delta Index以主键顺序索引Delta Space中的每条记录。为了节省内存开销,Delta Index中存储的是Delta RowID到(Stable RowID,N)的映射,通过Delta RowID可以很方便地获得对应Delta Space记录的主键实现顺序索引,而(Stable RowID,N)则表示了Delta Index索引中相邻两条Delta Space记录范围内的Stable Space记录,因为Stable Space的数据全局有序,因此范围内的记录一定是连续的,可以简化表示。借助Delta Index,Delta tree实现了全局逻辑有序,合并和scan后的整合都可以高效进行。
HTAP列存引擎设计选择
根据对上述四种HTAP列存引擎的调研,我们分析HTAP列存引擎的设计选择本质上就是回答三个问题:
- 是否依赖行存?
- 如果依赖行存,那么可以借助行存的事务系统,也可以通过行存进行unique check,服务简单的点查询和范围查询,但会使系统设计变得复杂。
- 如果不依赖行存,类似SAP HANA,可以使用一种架构存储一份数据,系统设计相对简单,但会影响unique check和点查询的效率。采用这种设计选择的列存引擎往往都会选择Delta-Main架构,因为本身按列存储就不利于更新,因此需要使用写优化的架构来支持事务处理中频繁的更新。
- 如果依赖行存,是基于索引组织表还是基于堆表?
- 如果基于堆表,类似Oracle,堆表的特性会给列存的设计实现带来很大的便利,可以充分利用堆表和列索引之间的对应关系。
- 如果基于索引组织表,堆表和列索引之间并没有天然的对应关系,需要在行存和列存之间实现低延时的数据同步就必然使用Delta-Main架构的列存,原因也是需要写优化的架构弥补列存自身的更新缺陷。
- 如果依赖行存且基于索引组织表,列存与行存是否紧耦合?
- 如果紧耦合,类似SQL Server,列存的数据管理直接依赖行存,列存可以不依赖额外的辅助数据结构实现高效的更新/删除并由此获得出色的scan性能、减少存储开销,这是因为行存已经实现了辅助数据结构的功能。不足之处是列存的维护可能会影响行存。
- 如果松耦合,类似TiFlash,就会存在存储成本和scan性能之间的trade-off,在Delta-Main架构下如果不引入任何额外的辅助数据结构,那么只能通过增量更新的方式进行删除,scan结果需要归并,性能相对较差,如果引入额外的辅助数据结构,可以加速归并过程或者实现标记删除直接在扫描过程剔除记录,scan性能相对较好,但增加了存储成本。不过在松耦合的架构下,列存几乎不会对行存产生影响。
参考文献
[1] Larson P Å, Clinciu C, Hanson E N, et al. SQL server column store indexes[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of data. 2011: 1177-1184.
[2] Larson P A, Clinciu C, Fraser C, et al. Enhancements to SQL server column stores[C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. 2013: 1159-1168.
[3] Larson P Å, Birka A, Hanson E N, et al. Real-time analytical processing with SQL server[J]. Proceedings of the VLDB Endowment, 2015, 8(12): 1740-1751.
[4] Lahiri T, Chavan S, Colgan M, et al. Oracle database in-memory: A dual format in-memory database[C]//2015 IEEE 31st International Conference on Data Engineering. IEEE, 2015: 1253-1258.
[5] Oracle Database In-Memory with Oracle Database 19c Technical Overview https://www.oracle.com/technetwork/database/in-memory/overview/twp-oracle-database-in-memory-2245633.pdf
[6] Sikka V, Färber F, Lehner W, et al. Efficient transaction processing in SAP HANA database: the end of a column store myth[C]//Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. 2012: 731-742.
[7] Sherkat R, Florendo C, Andrei M, et al. Page as you go: Piecewise columnar access in SAP HANA[C]//Proceedings of the 2016 International Conference on Management of Data. 2016: 1295-1306.
[8] Sherkat R, Florendo C, Andrei M, et al. Native store extension for SAP HANA[J]. Proceedings of the VLDB Endowment, 2019, 12(12): 2047-2058.
[9] Huang D, Liu Q, Cui Q, et al. TiDB: a Raft-based HTAP database[J]. Proceedings of the VLDB Endowment, 2020, 13(12): 3072-3084.