DataBase · 理论基础 · 热点优化 (SIGMOD'21 Paper 解读)
Author: Dongyun
数据库中的热点指的是一小部分记录会被大量的事务频繁读写,这在并发控制时会造成大量的竞争。 热点记录的更新在现实生活中非常常见,比如在电商场景中,秒杀或限购时,会存在大量事务短时间内频繁更新某一行数据,比如更新库存。 本文接下来会先介绍 SIGMOD 2021 上的一篇优化热点竞争问题的论文,Releasing Locks As Early As You Can: Reducing Contention of Hotspots by Violating Two-Phase Locking,接着再介绍在阿里云PolarDB中是如何优化热点行竞争的,最后会简单对比下这两种设计的异同。
1. 背景和问题介绍
1.1 Two-Phase Locking (2PL)
2PL 被广泛用于并发控制。在 2PL 中,锁的类型分为两种, X 锁和 S 锁。
对某个数据进行操作时,必须获得该数据对应的锁。
2PL 将加锁和释放锁的过程分为两个阶段,
(1)加锁阶段:该阶段内只能进行加锁,不能释放任何锁
(2)释放阶段:该阶段内只能释放锁,不能新加锁。
也就是说,2PL 要求一个事务一旦释放了某个锁,就不能再请求新的锁。
在实际的系统中,除非预先知道事务的整个处理流程,否则很难知道在什么时间点之后,该事务不会再读写数据(也就是不会再请求新的锁),也就是说第一阶段结束的时间点无法确定。 所以,通常的做法是,事务完成整个处理流程之后,再进入到释放阶段开始释放锁。
1.2 问题介绍
上面说到事务总是在完成的时候才开始释放锁,这就会导致一个问题,对于某些热点数据,在整个事务过程中会只被访问一小会, 但是这个热点数据的锁需要到整个事务处理完才能释放,所有需要访问这个数据的其他事务都必须要等待这个事务处理完才能进行下去。
下图对比了在 2PL 中事务的加锁顺序和理想状态下的加锁顺序。

左图(1)展示的是 2PL 的案例,T1,T2,T3这三个事务都想更新热点数据 A。 但是在这三个事务中更新 A 的操作只占整个事务处理流程的一小部分。 如果 T1 首先获得了 A 的 X 锁,这个时候 T2 和 T3 尝试获取 A 的 X 锁时将会发生冲突,必须进行等待。T1 更新完 A 后继续处理其他数据, 最后提交整个事务时才释放 A 的 X 锁。如果此时T2 成功抢占到了 A 的 X 锁,T3 还需要继续等待,直到 T2 提交释放完 A 的 X 锁,T3 才可以开始执行。 在这个例子中,更新 A 只是这三个事务中的一个小操作,但是 T2 需要等到 T1 提交完才可以执行,T3 需要等到 T2 提交完才可以继续执行。 实际上,这三个事务完全是串行执行的。在非冲突的部分完全没有任何并行性。 理论上,为了保证一致性,只要保证冲突数据的顺序执行就可以了,但是由于 2PL 的限制,导致了整个事务级别的串行执行。
上面的右图(2)展示了理想的情况,在理想状态下,T2 只需要等待 T1 更新完 A 之后,就可以继续更新 A, T3 只需要等待 T2 更新完 A 后就可以继续更新 A 了。也就是说,在这种情况下,只有更新 A 的这个操作需要顺序执行, 在其他没有冲突的部分,这个三个事务还是可以并发执行的。
1.3 目标和挑战
这篇论文最主要的目标就是解决热点冲突时锁竞争的问题,实现上面右图中的理想模式。 但是,为了实现理想的并发控制模式,面临着 2 个主要的挑战
(1)理想状态下,T1 在事务提交前就释放了 A 的锁,导致 T2 读到了 T1 未提交的事务,这种情况下如何保证记录之间的依赖关系?
(2)理想状态下,T2 读到 T1 未提交的数据,而 T3 又读到了 T2 未提交的数据,在 T1 发生 abort 时,T2,T3 都需要 abort,如何减少系统中的这种级联 abort?
2. 设计和实现
2.1 事务依赖关系的维护
该论文提出了名为 Bamboo 的算法来解决上述的挑战。在 Bamboo 中引入了新的 Retire() 接口。
针对锁的操作分为 Lock(),Retire() 和 Release() 这三个。 Lock() 和 Release() 维持原有的语义。
Retire() 用以在事务提交之前释放锁。
如下图中(1)所示,当某个事务更新完某个热点数据后,调用 Retire() “释放” 该锁,其他事务可以获取该锁。
事务结束后,仍然需要调用 Release() 真正意义上去释放该锁。
如果完全不调用 Retire() 则退化到了传统的 2PL 算法。

上图中(2)展示了 Bamboo 中锁对象的结构。
传统的 2PL 算法中,锁对象只包含 owners 列表(保存当前拥有该锁的事务)和 waiter 列表(保存当前等待该锁的事务)。
在 Bamboo 中新增了 retired 列表,用来表示哪些事务在该锁上进行了 Retire() 操作。
如果一个事务调用了 Retire() ,会将该事务从 owner 列表移到 retired 列表。
调用 Release() 时会将该事务从 retired 或 owner 列表中移除。
事务进行 Lock() 操作判断加锁冲突时,只需要和 owner 中的事务进行冲突检测。
retired 列表最主要的作用就是维护了事务的依赖关系。如果没有 Retire(),事务 T1 更新完 A ,立刻释放锁,这个时候 T2 加锁更新 A。
T2 读取了 T1 未提交的数据,如果 T1 最后没有提交而是回滚了,T2 如何处理?
利用 Retire() 接口和 retired 列表就可以很好的维护这种依赖关系。每个事务维护了一个引用数,用来记录它依赖其他事务的数量,
该事务每次请求加锁时,如果成功加锁,需要和该锁的 retired 列表中的事务进行冲突检测,如果有冲突,引用数就加1,
每有一个依赖的事务提交了,该引用数就减1。 只有当引用数为0的时候,该事务才可以被提交。如果某个事务回滚了,所有依赖它的事务都需要回滚。
2.2 减少级联aborts
前面提到了如果一个事务abort了,所有依赖它的事务都需要abort。这样就会产生级联aborts,
Bamboo 中使用 Retire() 会使得系统中存在更多的事务依赖关系,
造成更严重的级联aborts。针对这个作者给了一些建议,如何来减少级联aborts。比如,
(1)在 Retire() 收益较少时就不进行 Retire()。通常来说,如果数据更新出现的位置越靠近事务结束的地方,
Retire() 的收益就越小。
因为事务结束时总是会释放锁。锁释放提前的时间变短了,收益自然也就小了。论文中提出了一个 delta 的参数,
如果更新操作位于整个事务的后 delta 的部分,就不进行Retire(),而是等到事务结束时直接释放锁。
(2)减少 read-after-write 时造成的aborts。事务 Retire 锁之后会保存该数据的一个本地副本, 如果后续需要读当前数据,只需要从本地副本中读,而不需要abort已经更新了这个数据的其他事务。
作者还通过一系列的数据分析,详细分析了Bamboo在减少事务等待时间上的收益和级联aborts时的损失, 通过理论分析得出 Bamboo 可以提升总的吞吐率。 详细的分析过程就不在这里给出了,感兴趣的读者可以去看看原文。理论分析是需要基于很多假设的,结果也只有一些参考意义。
3. 实验分析
作者在开源数据库 DBx1000中实现了Bamboo的这个算法。 原文中的实验结果非常丰富,对比了不同算法、不同工作负载下的加速比。但是由于篇幅限制,这里只给出了两组实验结果。 如下图所示,图中的比较基准是基于 wound-wait 的 2PL (在图中简称为 WW)。
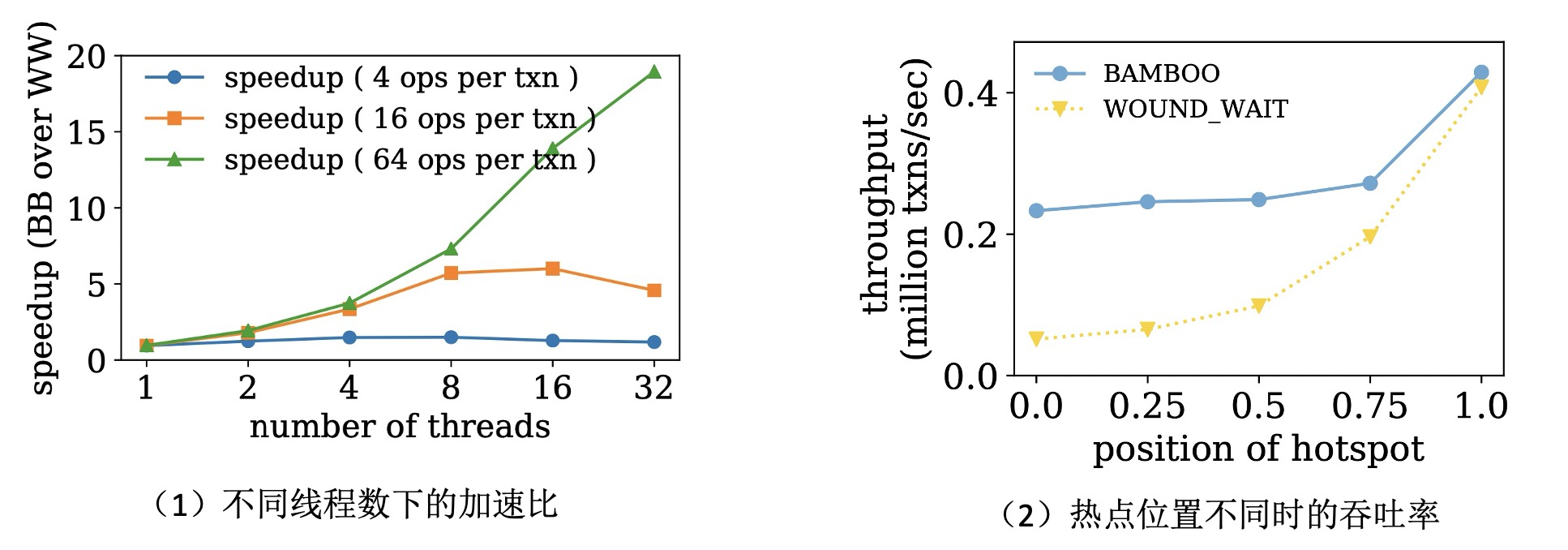
上图中(1)横坐标表示的是不同客户端的线程数,也可以理解成工作负载的并发程度。纵坐标是Bamboo对比WW的加速比。 图中三个不同颜色的线,表示每个事务中的操作数不同。在该图的负载中,只有 1 个 read-modify-write 的热点, 该热点在事务的最开始,事务中的其他操作都是读操作,这种情况下 Bamboo 的收益应该是最高的。 从图中我们也可以看到加速比随着线程数(并发数)不断增加而增加,Bamboo的加速比也在增加。最后趋于饱和,这个受限于机器本身的性能。 而且事务中操作数越多时,加速比越高。因为热点数据是在每个事务的开始,事务的操作数越多,释放锁的时间就提前的越多, 其他事务的等待时间的减少程度就越大。
上图中(2)展示的是热点位置不同时,Bamboo 和 WW 的吞吐率的对比。横坐标表示的是热点的位置,0表示热点在事务的开始, 1表示热点在事务的结束位置,比如0.5表示的是热点在事务的中间位置。纵坐标表示的是吞吐率。 这个结果也是符合预期的,热点位置越靠前,Bamboo性能提升就越多。如果热点在事务结束处,几乎没有提升了。 因为这个时候Bamboo算法发现 retire 没有收益,就不会执行 retire。算法也就退化到了传统的 2PL。
4. PolarDB中的热点优化
关于PolarDB热点行优化,前面也有一些文章已经介绍了,所以这里也不进行过于详细的介绍。 下面针对PolarDB热点优化的介绍也大量参考了前面的文章 https://help.aliyun.com/document_detail/178149.html。
4.1 设计
在电商平台业务中,限购、秒杀是常用的促销手段。在这些场景下, 大量对热点行的更新请求在极短时间间隔内到达后台数据库系统,必然造成严重的行锁竞争和等待,影响系统性能。 如果一个更新请求等待执行的时间变长,将会对业务层面产生显著负面影响。
针对上述问题,单纯提高计算机硬件配置已经无法满足这样的低延迟需求。因此PolarDB在数据库内核层进行了创新性的优化,不但能够自动识别热点行更新请求,而且将一定时间间隔内对同一数据行的更新操作进行分组,不同分组采用流水线的方式并行处理,通过这些优化,极大地提升了系统的性能。

上图展示了热点组提交的流程图。具体如下:
-
(1)对于需要进行热点优化的SQL语句(用户可以在SQL语句中设置参数表示需要进行优化),首先会对更新的主键或唯一键进行hash, 然后根据hash值将对应的请求放到队列中,也就是同一个队列中更新的都是相同的主键或唯一键。 同一个组内的第一个更新操作为Leader,其读取目标数据行并且加锁,后续更新操作为Follower,对目标数据行加锁时, 如果发现Leader已经持有行锁,不需要等待,直接获得行锁。这样一个组在只需要加一次锁,大大减少了锁竞争开销。 当一个组加锁后在进行处理时,所有针对该行的更新操作都需要在队列中等待,等当前组提交完了, 队列中的请求会形成一个行的组进行处理。 也就是说对一行的操作来说,系统中总是存在两个组,一个组正在处理请求,另外一个组正在队列中。上一个组正在处理请求时, 所有的新请求都放入到下一个组。当上一个组提交完了,当前队列中的所有请求形成一个新的组进行处理, 后续的请求放入队列形成下一个组。有点类似于流水线的处理方式。
-
(2)PolarDB是以B-tree索引的方式管理数据的,每次执行查询时,都需要遍历索引才能定位到目标数据行, 数据表越大,索引层级越多,遍历时间就越长。 在前面提到的对更新操作进行分组的机制中,只有每组的Leader遍历索引定位数据行, 之后把更新后的数据行缓存(row cache)在内存中,同组的Follower加锁成功后, 直接从内存中读取目标数据行,而不需要再次遍历索引。 这样一来,从整体上减少了索引遍历的次数和时间开销。
4.2 性能
我们利用 sysbench 模拟了一个库存更新的场景。采用 8 核 CPU 32GB 内存规格的 PolarDB 实例进行测试。
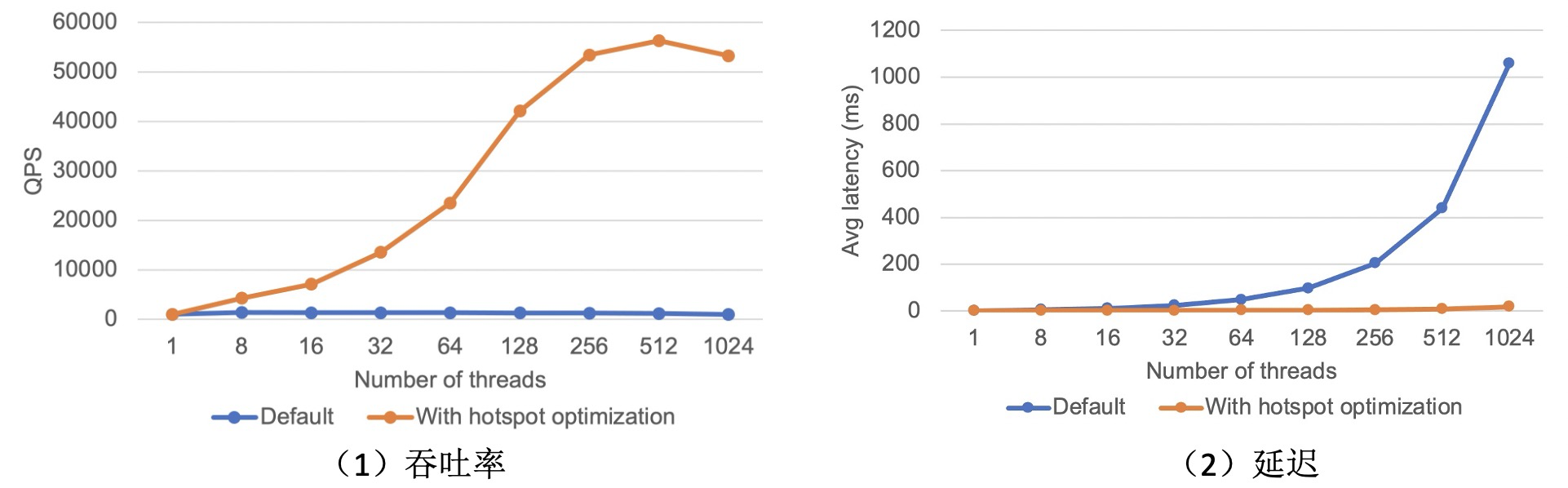
上面的实验室结果展示了 PolarDB 中不同线程数下开启热点行优化和没开启行优化的性能对比。左图展示的是吞吐,右图是延迟。 我们发现随着线程数的增加,热点行优化的性能提升越来越大,最后趋于稳定。 这主要是因为线程数越多,锁竞争越剧烈,使用热点行优化的收益越明显。
这两篇文章也有介绍如何在PolarDB中使用这个热点优化功能,同时也展示了一些测试结果, https://help.aliyun.com/document_detail/178149.html,http://mysql.taobao.org/monthly/2020/02/03/ 。
5.结束语
热点行的锁竞争问题是数据库中的一个常见问题。 PolarDB 和 Bamboo 其实都是用了相似的思想进行优化。 都是在热点行上,让一个事务可以读到另外一个事务未提交的数据。 在 PolarDB 上通过组提交的方式来实现,本质上来说,在一个组中 follower 的事务读到了 leader 事务未提交的数据。Leader 拿到行锁后,follower就不需要再申请行锁,也就类似于 Bamboo 中一个事务更新完数据后就 retire lock,其他事务就可以直接加锁。 但作为一款商业数据库,为了系统的稳定性,PolarDB 的做法也比较保守一些, 默认热点行的优化是关闭的,需要用户在SQL语句中添加一些标记,告诉数据库当前更新需要被优化。 而 Bamboo 作为学术研究,在算法设计方面也更加通用和激进一些,所有更新都可以提前释放锁, 所有事务都可以读到其他事务未提交的数据,其实现是基于DBx1000这种实验型的DBMS来做的,其难度也会远小于在InnoDB引擎中实现。不过作为学术研究,确实应该需要更加大胆的尝试和创新。