Long-lived Transactions 产生的影响
Author: 巴彦
背景
MVCC已经成为现代数据库解决高并发访问的关键技术;MVCC为用户提供了快读读取数据,同时也允许对冲突数据并发写入;其基原理是每次更新记录时创建一个新版本,而不是直接去覆盖旧版本。这样可以确保每个事务都只能访问到自己可以访问到的数据,这样就保持了其读取的数据始终是一致的。如果记录的版本数据不再被所有活跃的事务所需要,就可以将其清理掉,这样就可以保证数据库的容量在一个合理的范围之内。
从上面的描述中我们不难发现,数据库中MVCC有效的运行在于数据库可以及时清理那些已经不再被需要的旧版本数据;如果旧版本数据没有被及时清理,旧版本数据就会膨胀,甚至会导致性能问题。而这些成本最终都会被转嫁到客户身上。而Long-lived Transactions(后面简称LLT)的存在,会使旧版本的数据逐渐膨胀,加剧这个问题的影响,这篇文章我们详细讨论下LLT是如何对数据库产生的影响,以及最后介绍一下业界是如何想进一步解决这个问题的。
Version Engine的实现
在记录多版本数据时,有一个重要的基本原则:版本数据和如何定位版本数据的指针;在这个原则之下,有两种记录多版本数据的方式:in-row和off-row。
in-row:所有版本的数据记录都在一个数据页上;在进行版本数据查找时,通常会使用一个在索引叶子节点上的单独的数据结构来查找数据;具体实现可见参考文章[1]中对undo log在Oracle中的实现。这样做的好处是查找速度快,但是当过期的版本数据膨胀时,会有相当大的索引修改成本。具体情况查看附录图1。
off-row:这种方式是将第一个版本的数据记录在原本的数据记录中,其他旧版本数据记录在单独的空间中;每个版本都存有指向上一个版本的指针;具体实现可见参考文章[1]中对undo log在MySQL中的实现或者直接阅读MySQL中undo log模块的代码实现。这种方式在查找旧版本数据时可能会消耗更多的时间,因为这种实现需要额外的IO从单独的空间中读取旧版本数据;但是这种方式的有点在于随着旧版本数据的增多,也不会发生索引的修改。具体情况查看附录图2。
上面介绍了记录多版本数据的两种实现方式,这两种实现方式虽然各有优劣;但是其在LLT的场景下都会有性能的影响,in-row的实现就会产生大量的版本遍历和索引修改操作;而off-row的实现会有大量额外的IO产生,这种情况会进一步加剧page latch的争抢。
内存数据库和磁盘数据的对比
从上面我们已经知道MVCC能有效的发挥作用,需要数据库及时清理那些不被所有活跃事务需要的老版本数据;然而在具体的实践中,这是非常具有挑战性的。
内存数据库因为所有的数据都在内存中,所以数据的访问和处理都可以非常的快速;这就意味着内存数据库需要更快以及更加激进的处理过期的数据,否则会导致内存膨胀;内存数据库在处理旧数据这方面已经有很多办法,主要设计目标是更加细粒度的垃圾回收。例如SAP HANA提出了interval-based垃圾回收方案,定期扫描整个版本链,后台回收已经过期的版本数据。
相比于磁盘数据库,内存数据库有明显的优势;内存数据库可以方便的扫描整个版本链来回收过期版本而不用担心额外的IO;磁盘数据库必须面临高昂的IO成本;所以在磁盘数据库具体实现清理过期版本数据时,仍然使用最老的活跃事务作为回收过期版本数据的边界。这种版本已经使用了很长时间,虽然不能把所有不被所有活跃事务访问的版本数据清理掉,但是这种方式已经非常成熟与稳定。
现在LLT带来的问题
- 数据库存储空间膨胀:由于磁盘数据库清理老版本数据原则的限制;LLT会加剧过期版本数据的膨胀,用户将继续为这部分额外产生的数据付费。线上的某些实例的undo log空间可能会达到数百G的规模,占实例总空间的两成。
- 性能下降:从上面的介绍我们知道;由于LLT的存在,没有清理的旧版本数据会越来越多;对于in-row类型的Version Engine会产生更大的索引修改成本,对于off-row类型的Version Engine,随着额外IO的增多,会加剧page latch的争抢。
- 启动慢:众所周知,数据库系统在启动时,会把之前未完成的事务进行回滚;如果之前有LLT存在,那么会大大的拖慢数据库启动的时间。在线上有时候会发现如果有超大LLT的存在,数据库恢复的时间可能会达到数十小时。
如何降低LLT带来的影响
从上面我们可以知道,LLT对数据库产生影响的根本原因在于磁盘数据库清理过期数据版本的逻辑是用最老的活跃事务作为回收过期版本数据的边界;这样的策略会导致有很多不会所有活跃事务所需要的版本数据无法被及时清理。所以如果有一个办法可以尽可能的找出那些不被活跃事务需要的数据并清理掉,那么就可以降低LLT带来的影响。
参考文章2中提出了Dead Zone的概念,只要一个版本的开始和结束时间落入了连续的Dead Zone,那么这个版本就可以被清理;对于如何寻找,合并,管理Dead Zone, 参考文章2 提出了一系列创新的办法;运用这种版本可以更加高效的清理过期的数据版本。但是这种办法如何可以应用到真实的生产环境中,还需要进一步进行验证。
总结
LLT问题从传统数据诞生之初就一直存在;尽管很多优秀的学者与工程师一直在这方面寻找最终的解决办法,但是还是没有彻底的解决这个问题。
所以,在我们使用数据库时;一方面,在生产活动中,应该尽量减少LLT的存在,这会降低系统的鲁棒性;另一方面,持续关注业界探索各种可以减少LLT影响的办法。
附录
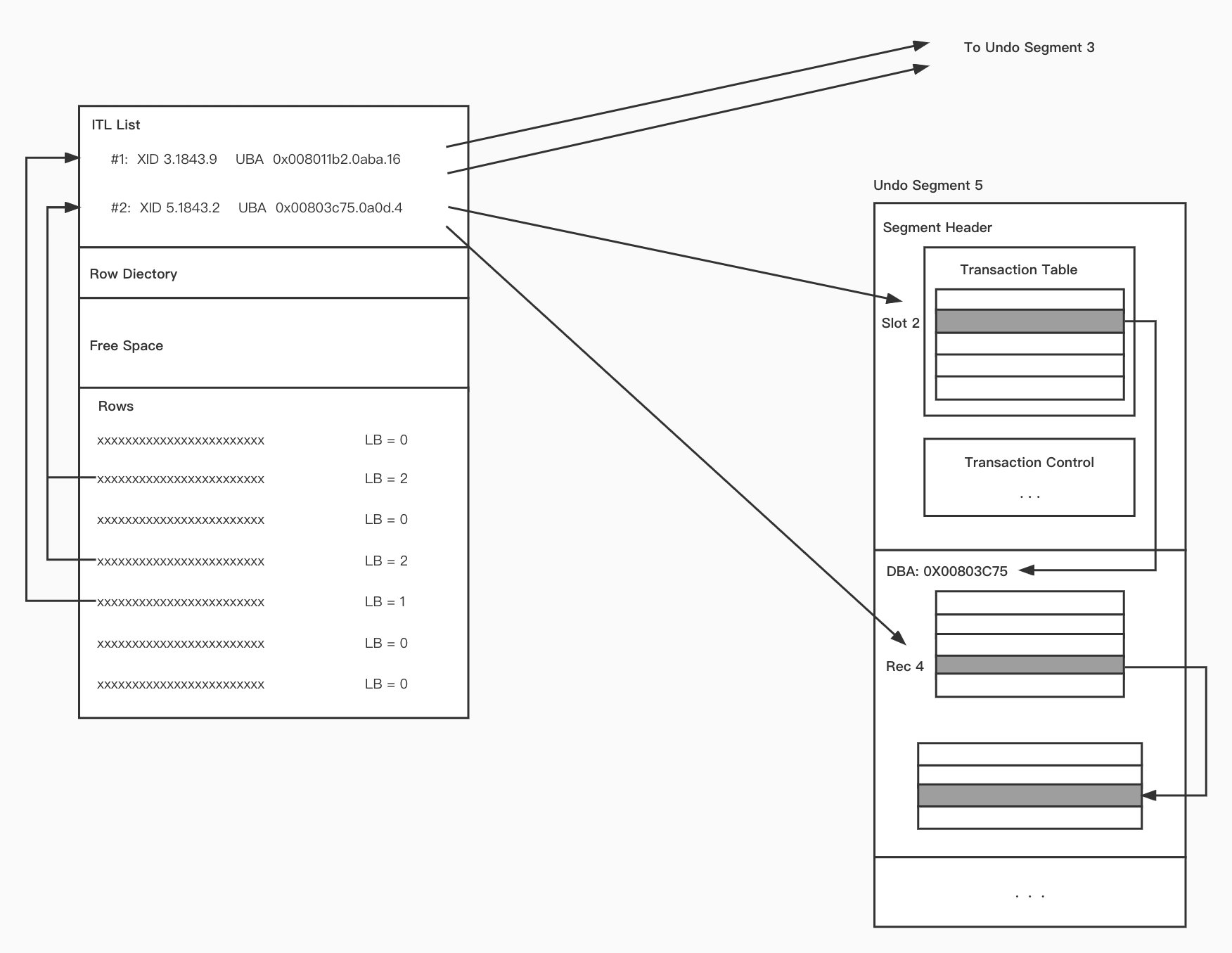 图1
图1
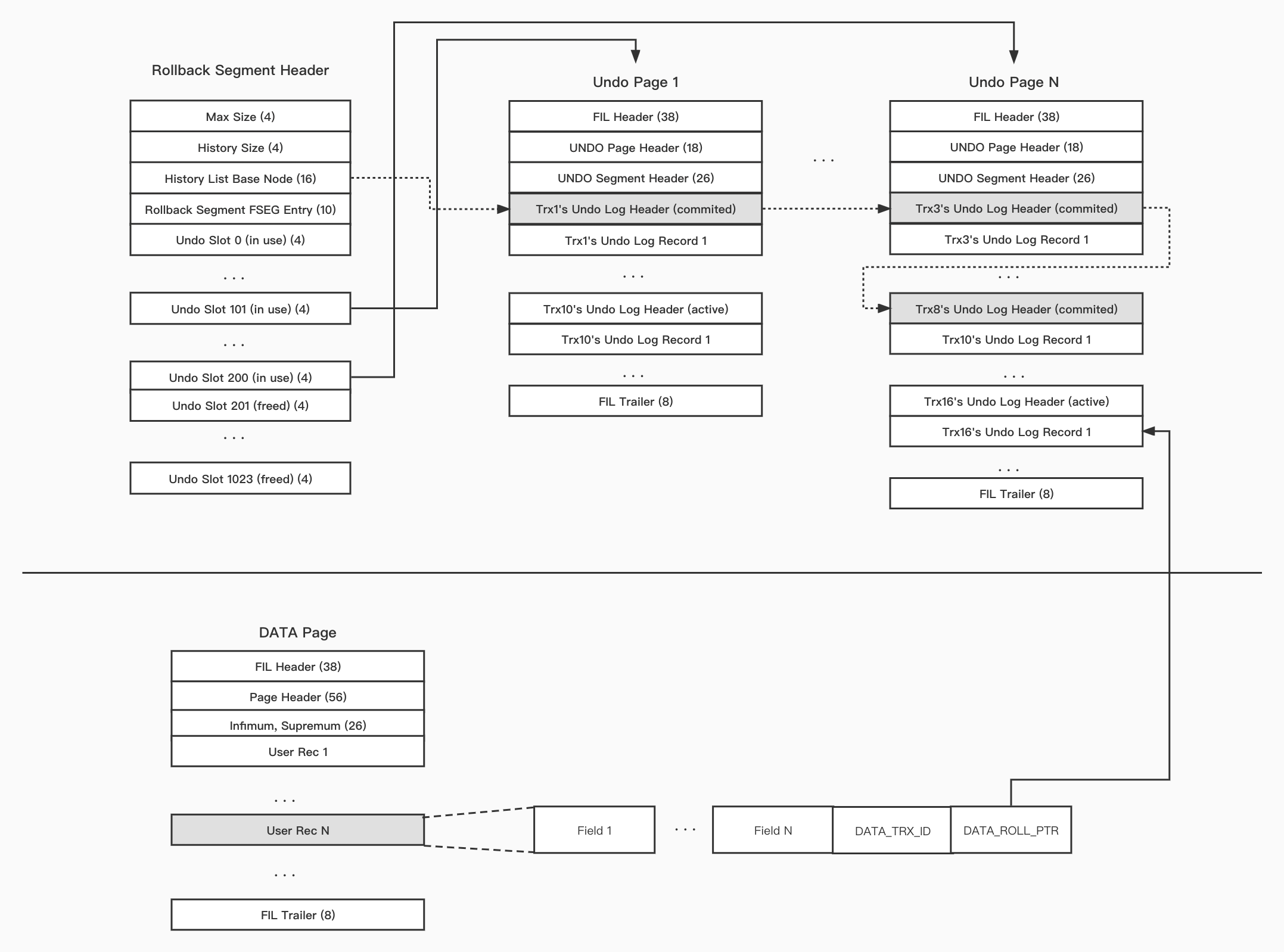 图2
图2
关于上面图中的详细情况请参考文章1.