PolarDB MySQL · 功能特性 · Auto Plan Cache
Author: 勉仁
背景信息
执行计划的选择需要考虑诸多因素,如统计信息、不同的连接顺序和不同的查询变换等。对于不同的查询语句,其优化时间不同,可能会存在某些SQL语句的查询优化时间在整体执行时间中占比很大的情况。如果这类SQL语句执行的次数较多,就会因为优化时间占比大导致系统负载增加。通过缓存并复用SQL语句的执行计划,可以减少每次执行SQL语句的优化时间,从而提升查询性能,降低数据库负载,提升吞吐能力。
除此之外,还有很多查询语句的查询优化时间占比很小,执行时间受执行计划的影响非常大,SQL语句中不同参数值对应不同的最优执行计划。某些场景下,MySQL会根据参数值从引擎获取实际数据做进一步优化。
上述两类查询一旦固定执行计划,查询响应时间和负载开销不会有明显优化,反而可能使查询性能回退。
为了提升优化时间占比太多的SQL语句的查询性能,降低系统负载,同时避免执行SQL语句时因采用固定执行计划而导致查询性能回退问题。PolarDB MySQL版提供了Auto Plan Cache功能。Auto Plan Cache功能提供了AUTO、DEMAND和ENFORCE三种模式,您可以根据需要将loose_plan_cache_type参数设置为三种模式中的任意一种模式,将SQL语句的执行计划缓存在Plan Cache中,以减少执行查询语句时的优化时间,提升查询性能。当缓存在Plan Cache中的执行计划涉及的表的统计信息发生变化,或对缓存中执行计划引用的表执行了DDL操作时,缓存的执行计划会自动失效。
实现
基础模块SQL Sharing
我们在PolarDB MySQL中增加了SQL Sharing模块。SQL Sharing模块存储了模板化后的SQL、SQL选择的执行计划、SQL和各个执行计划执行时收集的各类统计信息。在之前的月报”查询性能定位没有现场怎么办?如何统计TopSQL?PolarDBM新功能SQL Trace”中SQL Trace功能就是基于SQL Sharing模块。本文介绍的Auto Plan Cache也是基于SQL Sharing,SQL执行完会将执行计划存储到SQL Sharing中,SQL执行时会查找是否有对应计划缓存可以使用。
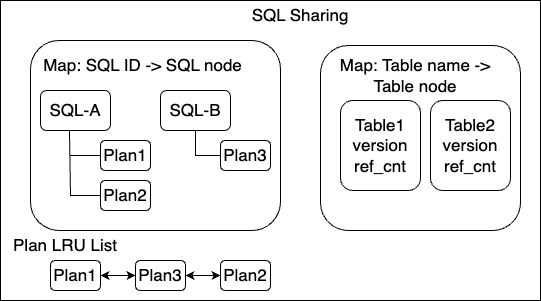
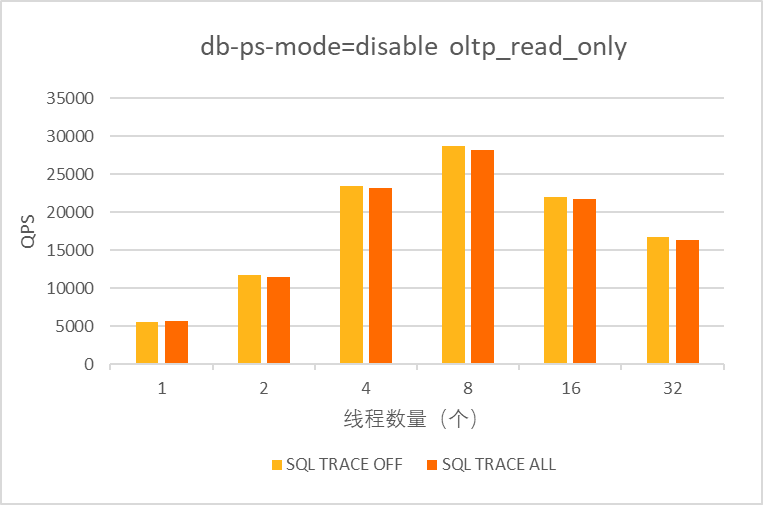
SQL Sharing整体设计没有全局锁,SQL Map和Table Map都是无锁hash结构,内部并发控制大量使用原子操作,可以很好支持高并发场景。同时执行计划和执行信息是在SQL将结果集返回客户端后才存储到SQL Sharing中,基本不影响SQL latency。这样SQL Sharing对系统吞吐和性能影响都非常小。跟踪全量查询时SQL Trace的性能测试数据,如下图(4C8G 非ps模式 2千张表oltp_read_only sysbench压测)所示,跟踪全量SQL执行的各类统计信息对性能影响不超过3%。
Auto Plan Cache的三种模式
Auto模式。
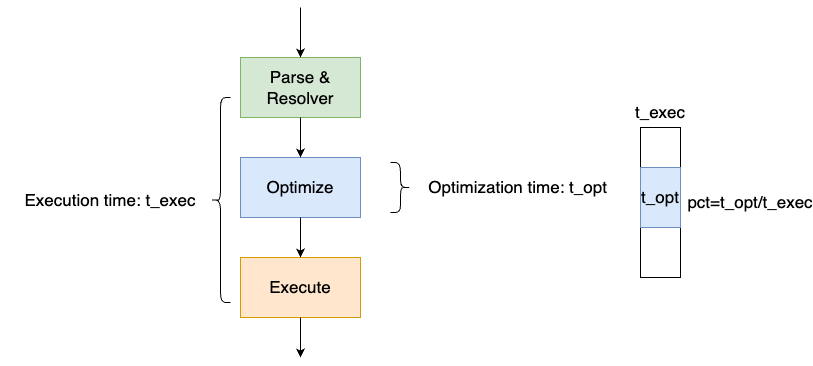
在PolarDB MySQL中,对于大多数业务查询都能够快速寻找到执行计划的时间,或者说优化时间在SQL执行时间中占比极小。这样的业务查询使用执行计划缓存并不会有明显的收益。但对于一些业务查询,在寻找执行计划时,不同索引路径cardinality的估算、不同join order的选择可能会导致优化时间在执行时间中占比较大。这个时候Plan cache可以有效减少查询执行时间。即使是短查询,如果优化时间占比较高,在高吞吐场景中,Plan Cache也可以大幅降低系统负载。例如对于执行时间300us的短查询,150us的优化时间虽然很短,但占比很高,如果DB中大量这类查询,Plan cache就可以有效降低负载,提高吞吐能力。当Auto Plan Cache配置为Auto模式,PolarDB会自动监控每个查询的优化时间和执行时间,对于优化时间占比较大的查询会自动加载到Plan Cache中。同时对于会产生不同执行计划,执行时间受执行计划影响较大的查询,Plan cache会自动识别,避免因应用Plan cache导致执行计划错误。
DEMAND模式
对于业务明确某几条SQL需要使用Plan cache的场景,可以配置plan_cache_type为DEMAND模式,同时配置需要使用plan cache的查询语句。这时,仅这些语句会将执行计划load到缓存中,当执行的时候会使用命中的执行计划。
ENFORCE模式
当所有查询都强制使用执行计划缓存时,可以配置为该模式。
Plan的失效
当表发生DDL,或者统计信息变更时候,会失效对应表涉及到的plan。同时这些plan可以配置失效时间,当plan超过该时间没有被命中后,就会被失效回收。
Auto Plan Cache的使用
相关参数
Auto Plan Cache模式可以通过plan_cache_type配置,该参数说明如下:
| 变量名 | 参数值 | 参数说明 |
|---|---|---|
| loose_plan_cache_type | OFF(默认值) | Plan Cache关闭 |
| AUTO | 自动加载有收益的查询到Plan Cache | |
| DEMAND | 指定语句加载到Plan Cache | |
| ENFORCE | 强制所有语句使用Plan Cache |
Plan Cache当存在内存中,超过plan_cache_expire_time时间没有被命中那么该Plan Cache也会淘汰内存被回收。
| 变量名 | 参数值 | 参数说明 |
|---|---|---|
| loose_plan_cache_expire_time | [0, UINT_MAX] | Plan Cache超过该时间没有被命中后内存可以被回收。单位秒。 默认:1800 (0.5小时) |
当配置为Auto模式,我们可以通过下面的变量来控制哪些语句load到Plan Cache中,SQL语句的整体执行时间阈值大于或等于loose_auto_plan_cache_time_threshold参数值,且SQL语句的优化时间占整体执行时间阈值的百分比阈值大于或等于loose_auto_plan_cache_pct_threshold参数值时,该SQL语句的执行计划会被缓存到Plan Cache中。
| 变量名 | 参数值 | 参数说明 |
|---|---|---|
| loose_auto_plan_cache_pct_threshold | [0-100] | 优化时间占语句整体执行时间的百分比阈值。 取值范围:0~100。默认值为20。 |
| loose_auto_plan_cache_time_threshold | [0-ULONG_MAX] | SQL语句整体执行时间阈值。单位为微秒。 取值范围:0~ULONG_MAX。默认值为400。 |
| loose_auto_plan_cache_count_threshold | [0-ULONG_MAX] | 满足缓存条件的SQL语句的执行计划缓存到Plan Cache中的次数阈值。 取值范围:0~ULONG_MAX。默认值为512。 当缓存到Plan Cache中的次数阈值大于或等于loose_auto_plan_cache_count_threshold参数值时,缓存中的执行计划才会生效。 |
相关接口
- 指定语句捕获Plan到Plan Cache
当plan_cache_type配置为DEMAND,可以通过内部存储过程dbms_sql.add_plan_cache(schema, query)来指定语句捕获Plan到Plan Cache。示例如下:
call dbms_sql.add_plan_cache("test", "select * from t_for_plan where c1 > 1 and c1 < 10");
- 查看当前Plan Cache引用的表信息
通过内部存储过程dbms_sql.display_plan_cache_table()查看Plan Cache引用到的表信息。
示例
call dbms_sql.display_plan_cache_table()\G
*************************** 1. row ***************************
SCHEMA_NAME: test
TABLE_NAME: t_for_plan
REF_COUNT: 1
VERSION: 0
VERSION_TIME: 2023-03-10 17:21:35.605264
- 删除指定语句捕获Plan
我们可以通过存储过程dbms_sql.delete_sharing_by_rowid(row_id)来删除指定语句捕获Plan,其中row_id是指存储在mysql.sql_sharing表中行的Id值。
上面我们指定捕获Plan后,查询mysql.sql_sharing可以得到如下结果:
mysql> SELECT Id, Schema_name, Type, Digest_text FROM mysql.sql_sharing WHERE Type = 'PLAN_CACHE'\G
*************************** 1. row ***************************
Id: 1
Schema_name: test
Type: PLAN_CACHE
Digest_text: SELECT * FROM `t_for_plan` WHERE `c1` > ? AND `c1` < ?
通过dbms_sql.delete_sharing_by_rowid(row_id)删除指定语句捕获Plan可以做如下调用:
call dbms_sql.delete_sharing_by_rowid(1);
获取缓存Plan的信息
SQL语句的执行计划存储在SQL Sharing模块中,您可以通过以下SQL语句在INFORMATION_SCHEMA.SQL_SHARING表中查询Plan Cache中的缓存信息。
SELECT TYPE, REF_BY, SQL_ID, SCHEMA_NAME, DIGEST_TEXT, PLAN_ID, PLAN, PLAN_EXTRA, EXTRA FROM INFORMATION_SCHEMA.SQL_SHARING WHERE json_contains(REF_BY, '"PLAN_CACHE"') or json_contains(REF_BY, '"PLAN_CACHE(DEMAND)"')\G
示例
- 数据准备。
CREATE TABLE t_for_plan AS WITH RECURSIVE t(c1, c2, c3) AS (SELECT 1, 1, 1 UNION ALL SELECT c1+1, c1 % 50, c1 %200 FROM t WHERE c1 < 1000) SELECT c1, c2, c3 FROM t;
CREATE INDEX i_c1_c2 on t_for_plan(c1, c2);
-
将Auto Plan Cache模式设置为DEMAND。
在当前数据库连接中执行以下命令,将当前会话中的plan_cache_type参数设置为DEMAND。
SET plan_cache_type=DEMAND;
- 执行相关接口介绍中指定语句捕获Plan到Plan Cache。
call dbms_sql.add_plan_cache("test", "select * from t_for_plan where c1 > 1 and c1 < 10");
- 执行查询语句。
SELECT * FROM t_for_plan WHERE c1 > 1 AND c1 < 10;
- 查询Plan Cache中的缓存信息。
SELECT TYPE, REF_BY, SQL_ID, SCHEMA_NAME, DIGEST_TEXT, PLAN_ID, PLAN, PLAN_EXTRA, EXTRA FROM INFORMATION_SCHEMA.SQL_SHARING WHERE json_contains(REF_BY, '"PLAN_CACHE"') or json_contains(REF_BY, '"PLAN_CACHE(DEMAND)"')\G
查询结果如下:
*************************** 1. row ***************************
TYPE: SQL
REF_BY: ["PLAN_CACHE(DEMAND)"]
SQL_ID: 9jrvksr3wjux6
SCHEMA_NAME: test
DIGEST_TEXT: SELECT * FROM `t_for_plan` WHERE `c1` > ? AND `c1` < ?
PLAN_ID: NULL
PLAN: NULL
PLAN_EXTRA: NULL
EXTRA: {"TRACE_ROW_ID":1}
*************************** 2. row ***************************
TYPE: PLAN
REF_BY: ["PLAN_CACHE"]
SQL_ID: 9jrvksr3wjux6
SCHEMA_NAME: test
DIGEST_TEXT: NULL
PLAN_ID: 08xftakma6pm6
PLAN: /*+ INDEX(`t_for_plan`@`select#1` `i_c1_c2`) */
PLAN_EXTRA: {"access_type":["`t_for_plan`:range"]}
EXTRA: {"PLAN_CACHE_INFO":{"tables":[`test`.`t_for_plan`], "versions":[0], "hits": 0}}
其中,EXTRA字段的PLAN_CACHE_INFO中会展示引用的表、引用的表的版本和执行计划命中次数。
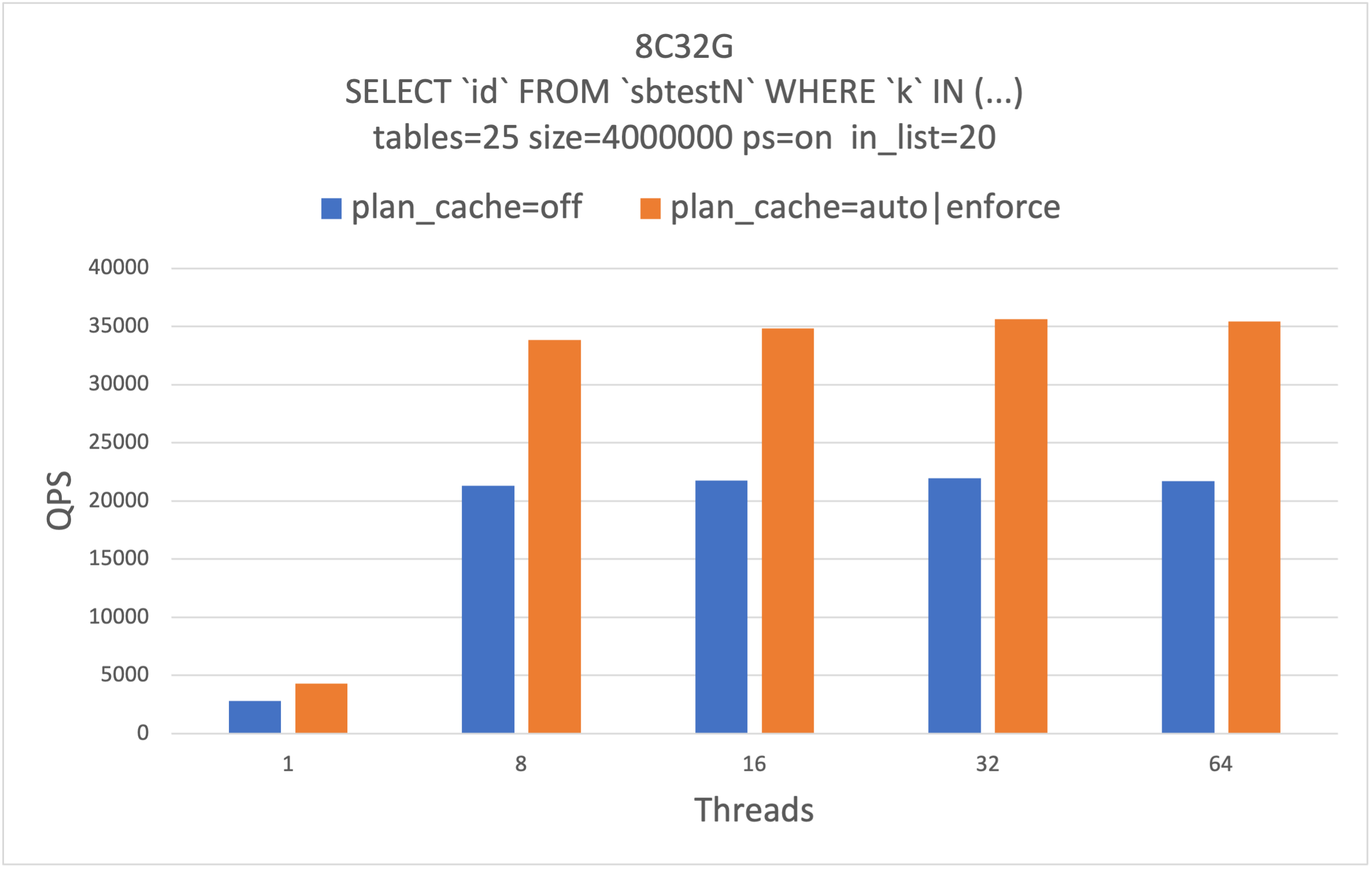
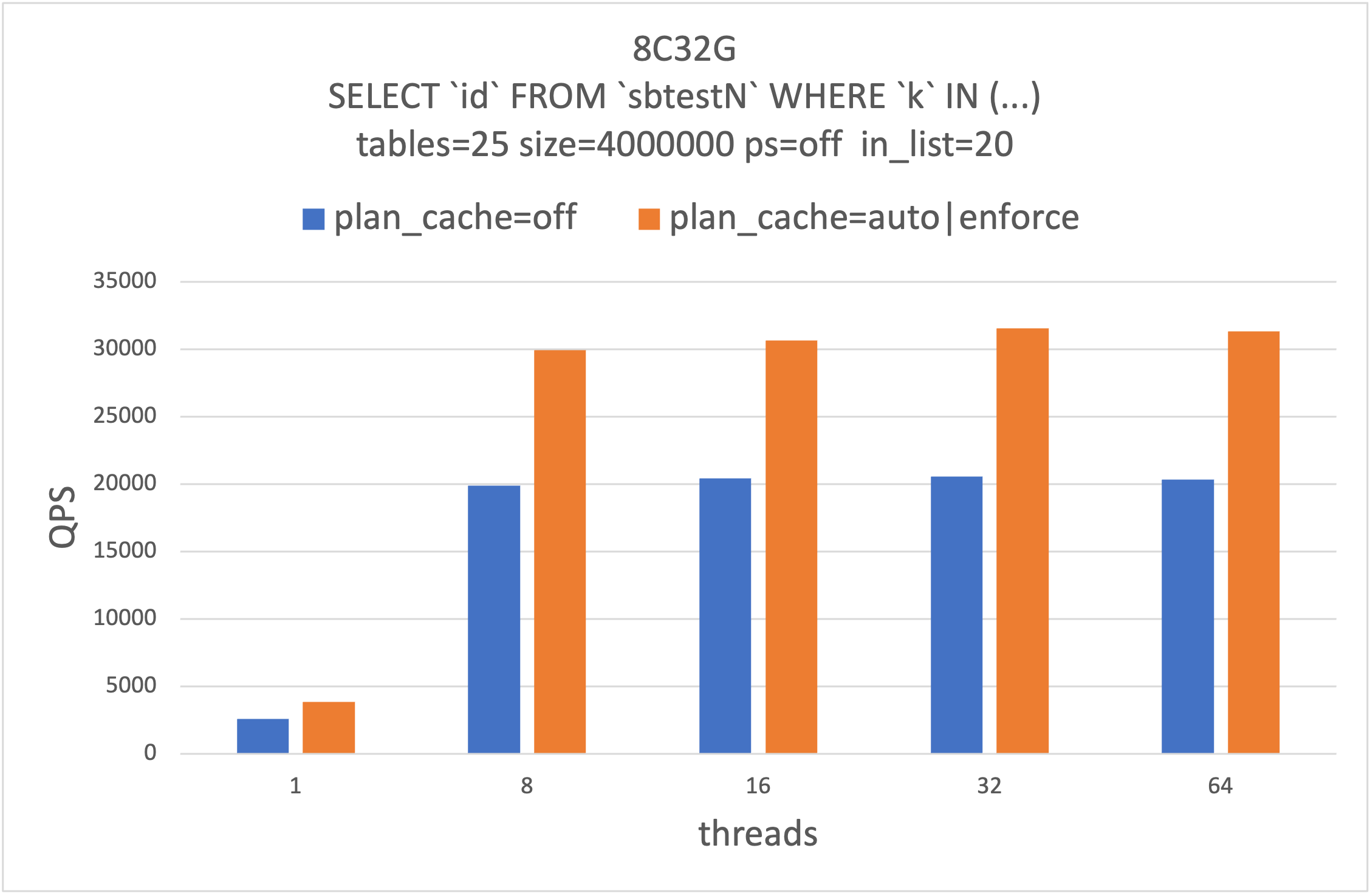
性能提升
对于优化时间占比较高的查询,Plan Cache可以获得大幅的性能提升。我们在8c32G规格25个表,每个表400w行上做压测。压测语句为SELECT id FROM sbtestN WHERE k IN(…),其中in list长度为20。可以看到Plan Cache在ps协议和非ps协议下都能够获得50%以上的性能提升。