PostgreSQL blink-tree implement notes
Author: ba0tiao
lehman blink-tree and Vladimir Lanin cocurrent Btree
PosegreSQL blink-tree 实现方式引用了两个文章
Lehman and Yao’s high-concurrency B-tree management algorithm
V. Lanin and D. Shasha, A Symmetric Concurrent B-Tree Algorithm
MySQL InnoDB 的 btree 实现主要参考的是
R. Bayer & M. Schkolnick Concurrency of operations on B-trees March 1977
lehman blink-tree
Blink-tree 的 2 个核心变化
-
Adding a single “link” pointer field to each node.
这里有一个当时时间点的背景, 我们现在见到的大部分的 Btree 实现里面, 都会有 left/right point 指向 left/right page. 但是当时对标准 Btree 的定义并没有这个要求. Btree 是非叶子节点也保存数据, B+tree 是只有叶子节点保存数据, 从而使 btree height 尽可能低. 但是并没有严格的要求把叶子节点连接到一起.
但是总体而言, 对 Btree 来说, 并没有强制要求有 left/right 指针指向左右 page.
像 InnoDB 里面的 btree 已经自带了 leaft page 和 right page 指针了, 同时在不同的 level 包含 leaf/non-leaf node left/right 指针都指向了自己的兄弟节点了.
所以到现在这里 right page 指针就可以和 link page 指针复用.
-
在每个节点内增加一个字段high key, 在查询时如果目标值超过该节点的high key, 就需要循着link pointer继续往后继节点查找
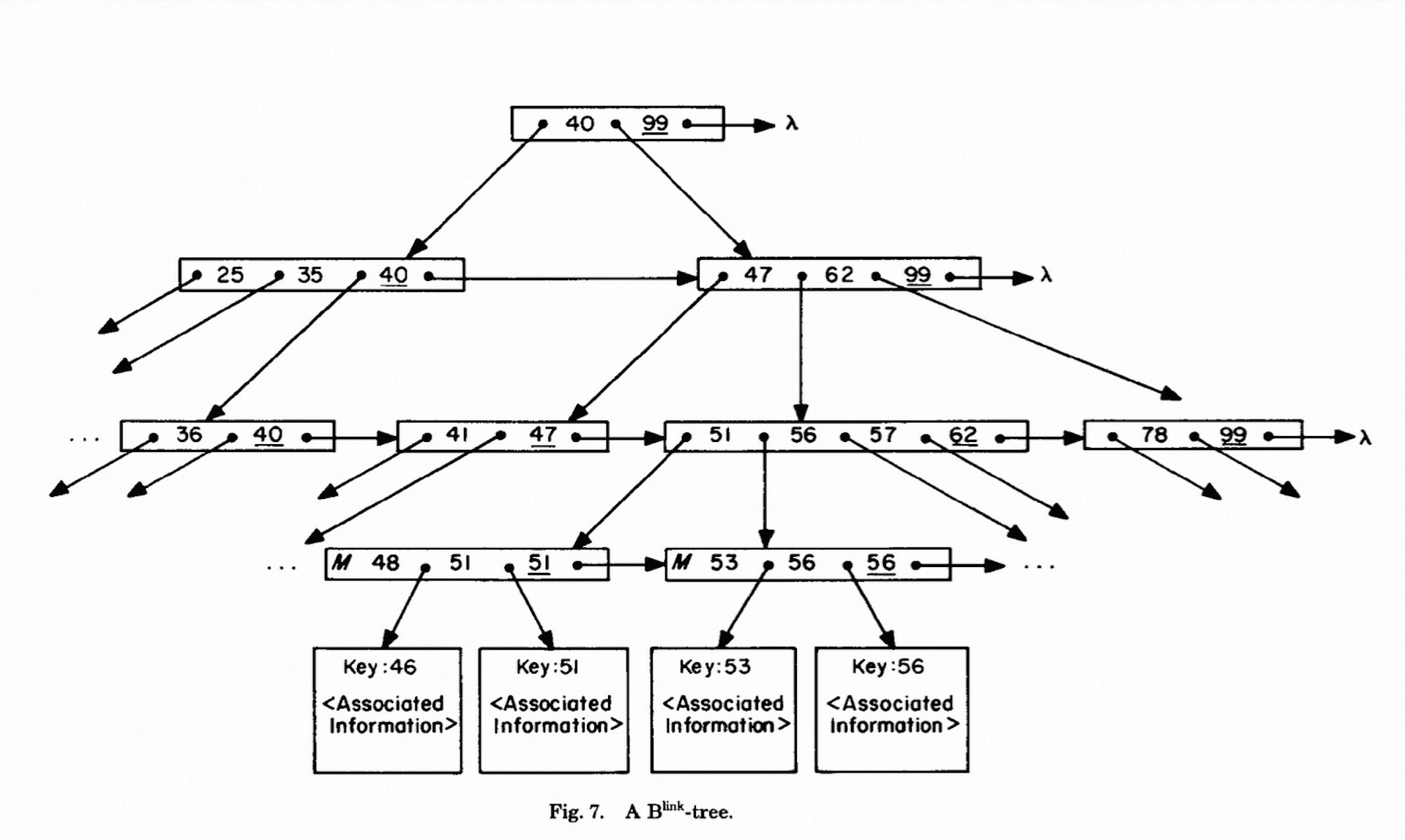
所以目前和 PolarDB 的 blink-tree 比较大的区别是取消了 lock-coupling 的操作, search 操作不加锁
PolarDB blink-tree
search 操作是通过 lock-coupling 操作, 自上而下进行加锁放锁操作.
SMO 操作则没有 lock-coupling, 是先加子节点lock, 然后释放子节点, 再去加父节点.具体是:
给 leaf-page 加锁完成操作要插入父节点的时候, 需要把子节点 page lock 释放, 然后重新 search btree, 找到父节点加 page lock 并且修改. 当然这里也可以通过把父节点指针保存下来, 从而规避第二次 search 操作, 但这个是一个优化
在标准的 blink-tree 中, 也就是 PostgreSQL Blink-tree
search 操作并没有lock coupling. 而是只需要加当前层的 latch, 如果查找到 child page id 到获得 child page 之间, 因为没有 lock-coupling, 释放完 parent node latch, 到加上 child nodt latch 这一段时间是完全不持有 latch 的, 因此child page 发生了SMO 操作, 要查找的 record 不在 child page 了, 那么该如何处理?
PolarDB blink-tree 中, 通过 lock-coupling 操作保证了不存在一个时刻, 同时不持有 parent node 和 child node latch, 从而不会发生这样的情况.
下面这个例子就是这样的情况:
search 15 操作和触发 SMO 的insert 9 操作再并发进行着
15 原本在 y 里面, find(15) 操作的时候 y 进行了分裂, 分裂成 y 和 y’. 15 到了新的 y’ 里面.
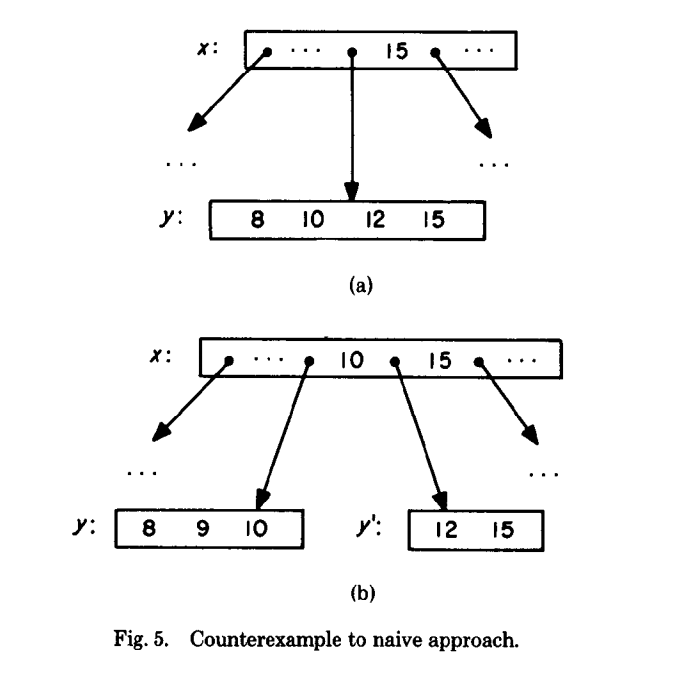
# This is not how it works in postgres. This demonstrates the problem:
"Thread A, searching for 15" | "Thread B, inserting 9"
| node2 = read(x);
node = read(x); |
"Examine node, 15 lies in y" | "Examine node2, 9 belongs in y"
| node2 = y;
| # 9 does not fit in y
| # Split y into (8,9,10) and (12,15)
| y = (8,9,10); y_prime = (12,15)
| x.add_pointer(y_prime)
|
"y now points to (8,9,10)!" |
node = read(y) |
find(15) "15 not found in y!" |
对于这个例子, 可以看到 PolarDB blink-tree 通过 lock-coupling 去解决了问题, 在 read(x) 操作之后, 同时去持有 node(y) s lock, 那么 Thread B SMO 操作的时候需要持有 node(y) x lock, 那么SMO 操作就会被阻塞, 从而避免了上述问题的发生.
lehman 介绍的 blink-tree 怎么解决呢?
在 node(y) 里面, 增加了 link-page 以及 high key 以后.
上述的find(15) 操作判断 15 > node(y)’s high-key, 那么就去 node(y)’s link-page 去进行查找. 也就是 y’. 那么在 y’ 上就可以找到 15
那么 SMO 操作是如何进行的呢?
lehman blink-tree SMO 操作是持有子节点去加父节点的锁, 并且是自下而上的latch coupling操作, 由于 search 操作不需要 lock coupling, 那么自下而上的操作也就不会有问题. 所以可以持有 child latch 同时去申请 parent node latch.
这里会同时持有 child, parent 两个节点的latch.
如果这个时候 parent 节点也含有 link page, 也就是需要插入到 parent node -> link page. 那么就需要同时持有 child, parent, parent->link page 这 3 个 page 的 latch.
如果在 parent->link page 依然找不到插入位置, 需要到 parent->link page->link page, 那么就可以把 parent node 放开, 再去持有 link page -> link page.
因此同一时刻最多持有 3 个节点的 latch
大部分情况下 link page 只会有一个, 很多操作可以简化.
这里在 Vladimir Lanin Concurrent Btree 里面会有进一步的优化.
按照现在PG 实现, 如果锁住子节点再向父节点进行插入, 只会出现一个 link page. 因为第一个 page 发生分裂的时候, 在分裂没有结束之前是不会放开 page lock, 那么新的插入是无法进行的.
只有像 PolarDB blink-tree 做法一样,插入child node完成以后, 放开child node latch, 然后再去插入parent node, 允许插入parent node过程中, link page 继续被插入才可能出现多个 link page 的情况了.
我理解 PG 这里也是做了权衡, 为了避免出现多个 link page 的复杂情况的.
这里虽然不会出现多个 Link-page, 但是有可能 search/insert 的时候需要走多个 link page 到目标 Page, 比如下面例子
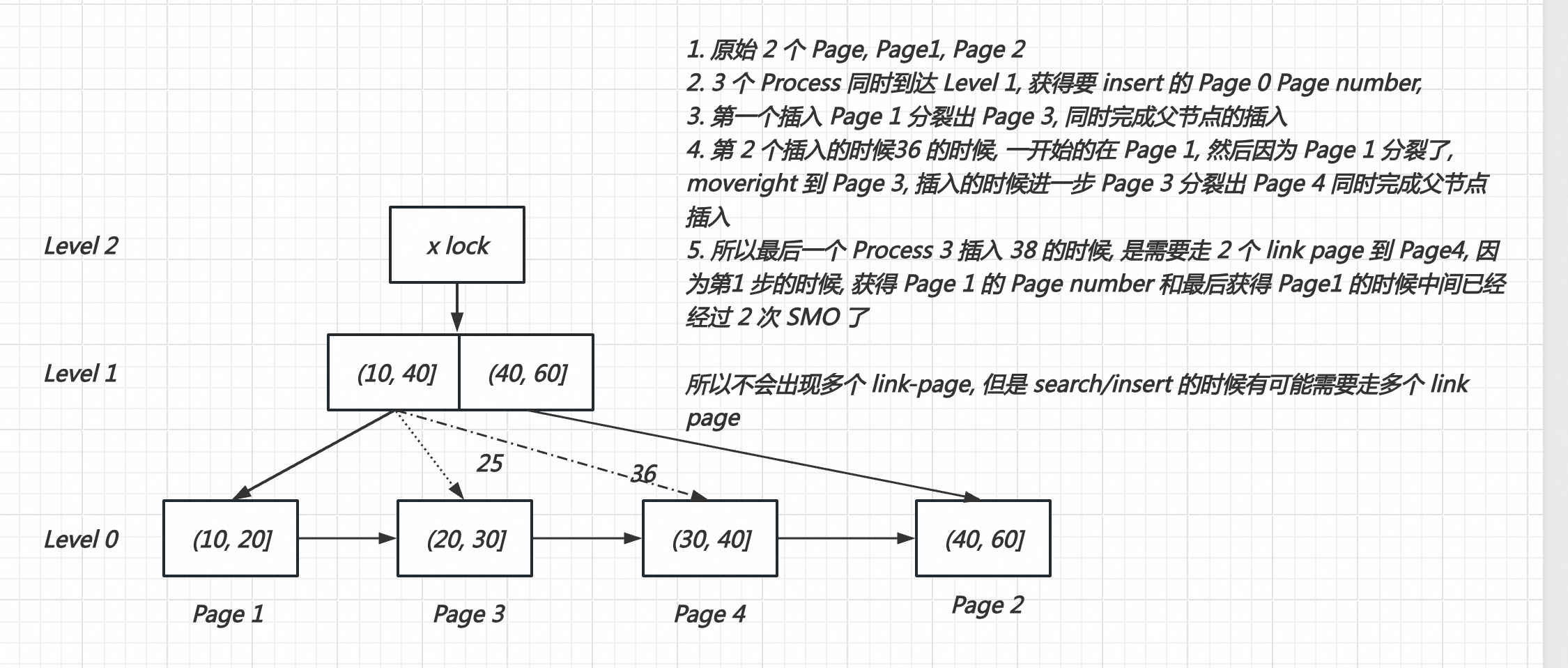
其实这里也可以使用类似 PolarDB blink-tree 的方式, 也就是插入子节点以后, 就可以把子节点的锁放开, 重新遍历 btree 去插入父节点, 从而可以进一步的让子节点的 latch 尽早放开.
其实 blink-tree 这个文章也讲到了 remembered list
We then proceed back up the tree (using our “remembered” list of nodes through which we searched)
Vladimir Lanin Cocurrent Btree
这里对比了原先通过search 的时候 lock coupling 同时 SMO 的时候 lock subtree 的加锁方式, 从而保证加锁的顺序都是自上而下
该文章出来之前的并发控制方式, 缺点在哪里呢?
-
很难计算清楚 lock subtree 的范围到底是多少.
-
lock coupling 并发的范围还是不够. 这里强调 lock-coupling 不一定需要配合 blink-tree 使用, 配合标准的 btree 使用也是可以的. 在这个文章里面就是配合 b+tree 使用的.
这 2 种方法都是牺牲并发去获得安全性.
其他做法和 lehman blink-tree 类似, 只不过在SMO 的时候, 实现了 only lock one node at a time, 不过在 PostgreSQL 具体实现的时候并没有这样实现, 我理解主要为了考虑安全性.
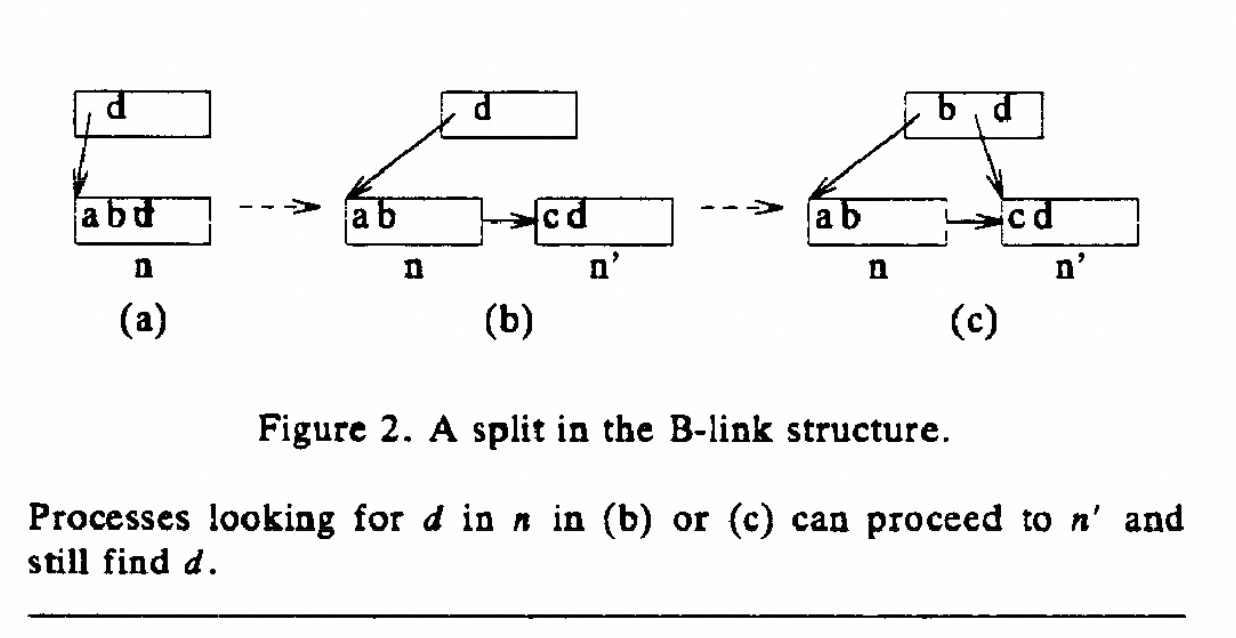
文章也提到:
Although it is not apparent in [Lehman, Yao 811 itself, the B-link structure allows inserts and searches to lock only one node at a time.
也就是可以实现 insert and search only one node, 这个也是我的想法.
Each action holds no more than one read lock at a time during its descent, an insertion holds no more than one write lock at a time during its ascent, and a deletion needs no more than two write locks at a time during its ascent.
After the completion of a half-split or a half-merge, all locks are released.
在文章里面确实是这样, half-split 之后, 所有的 locks 都释放了, 那么插入父节点的时候就会 PolarDB 现有做法类似, 也就是释放所有的 lock 重新去插入新的一层的数据, 从而保证 SMO 操作统一时刻也仅仅只有 Lock 一层.
Normally, finding the node with the right coverlet for the add-link or remove-link is done as in [Lehman, Yao 811, by reaccessing the last node visited during the locate phase on the level above the current node. Sometimes (e.g. when the locate phase had started at or below the current level) this is not possibie, and the node must-be found by a new descent from the top.
插入父节点的时候可以通过保存的 memory-list 或者重新遍历了
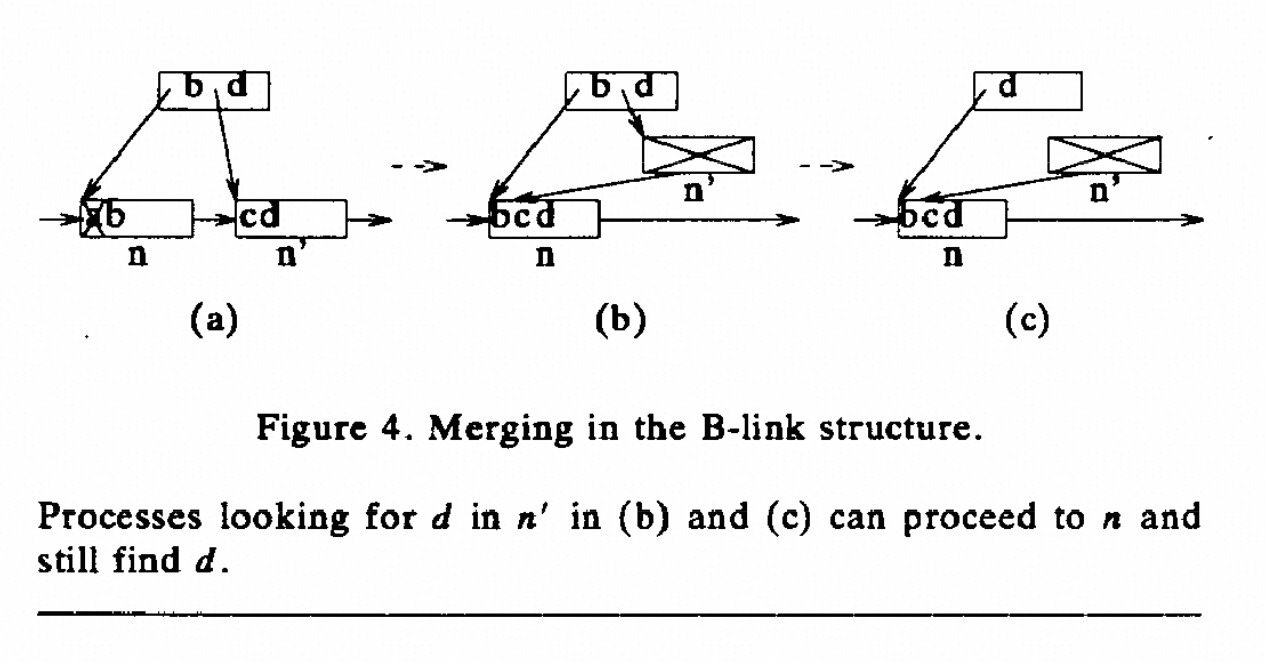
另外, 用类似 link-page 思路补充了再 lehman 文章中没有实现的delete 操作
如果仅仅是和 MySQL 的 InnoDB 对比, PG 的 Blink-tree 实现在加锁粒度上明显更加的细致, 避免的整个 Btree 的 Index lock 的同时, 也同时规避了通过 Lock subtree 的方式进行 Search 操作和 SMO 操作的冲突问题.