通过 eBPF 进行跨线程的性能分析
Author: 谢榕彪(归墨)
1 背景
通过 前一篇文章 的介绍,我们很容易能够动态地得到某个函数的执行时延。当函数的开销只是线程内部的计算时,我们可以判断出造成函数时延较大的原因。
但当函数的开销依赖于其他线程时,如在一个信号量上等待其他线程唤醒,这时分析变得复杂起来。
举两个例子。
1.1 Redo 日志落盘分析
在 MySQL 中,用户线程在提交写事务时需要等待写入的 redo 日志先落盘,确保当发生 crash recovery 后,事务能正常恢复。而 redo 日志的落盘是由多个后台线程配合的 [1],只有后台线程 redo 日志写入的位点 (flush_to_lsn) 达到事务提交需要的位点 (commit_lsn) 时,由 log flush notifier 通知用户线程,事务才能提交。
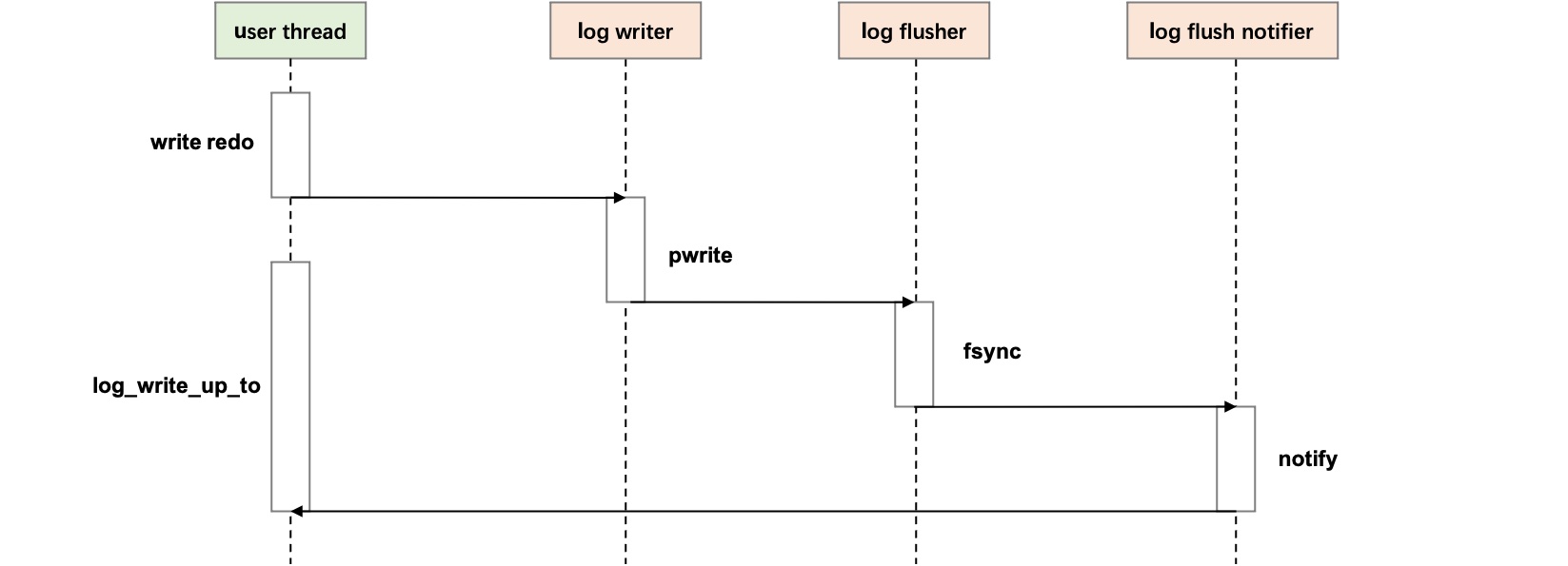
此时通过 PT_PERF,我们能看到用户等待落盘的时延是 2.6 ms 左右,那么造成这 2.6 ms 等待开销是如何组成的呢?
name : avg cnt sched_time cpu_pct(%)
log_write_up_to : 2583821 1522 2352067 7.05
1.2 锁等待分析
另一个在并发访问的场景,用户线程需要持有锁执行操作,因此有大量的时间是花费在锁等待上。只有其他线程释放锁后,当前线程才能获取到锁。
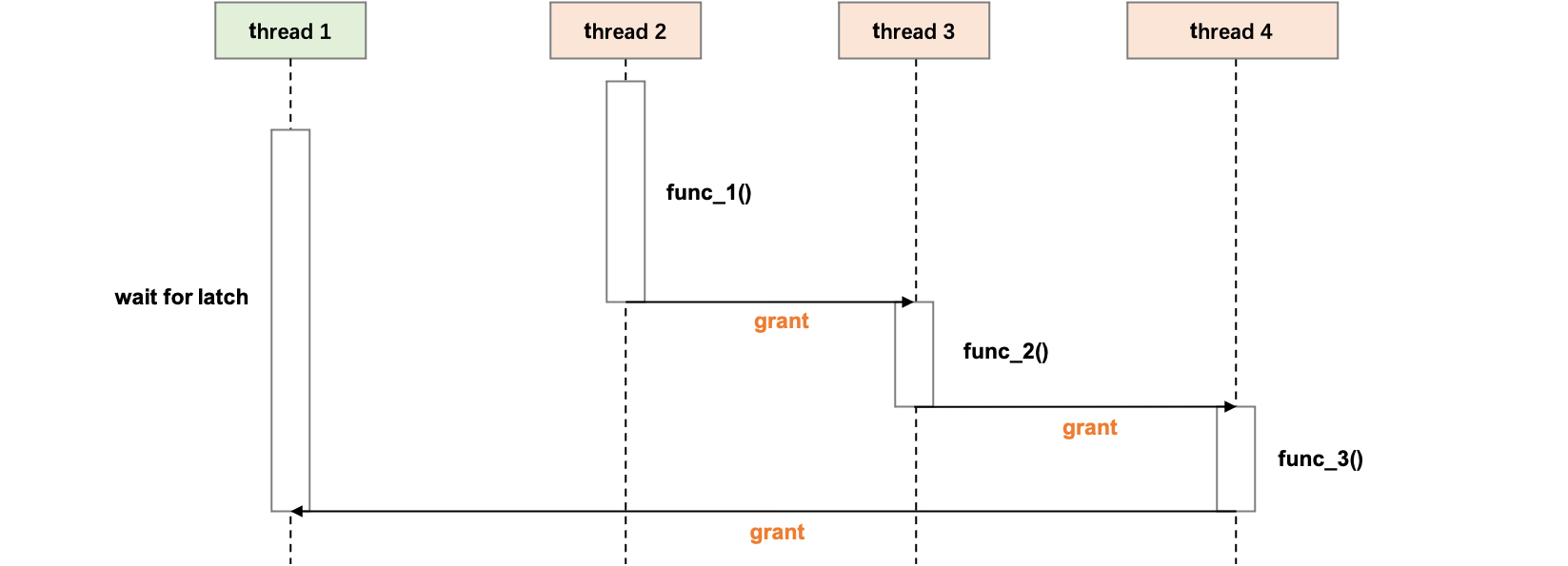
通过 PT_PERF,我们能看到用户在 trx_start_low 等锁等待了 637us 左右,那么这把锁被哪些线程持有,对应的函数栈是什么,持有了多久呢?
Histogram - Child functions's Latency of [trx_start_low]:
name : avg cnt sched_time cpu_pct(%)
mutex_spin_wait : 637017 693 609492 0.38
2 eBPF-USDT 性能分析
这类跨线程的开销监测依赖于程序的内部信息以及线程的上下文信息。目前的思路是
- 在程序内部自己实现复杂的统计代码进行收集统计,过于复杂,通用性也更差。
- 在程序定义一些探针(tracepoint),由 eBPF 程序进行收集输出。
eBPF 从 BPF (Berkeley Packet Filter) 发展而来,由 Linux 内核提供,在不修改内核代码的情况下,用户定义事件和执行简单的程序。
最开始 BPF 是提供在内核用于网络包过滤的性能,来避免大量的上下文切换开销。后来内核提供了大量的事件源(static/dynamic tracing,PMC),数据结构和一些辅助函数,将 eBPF 扩展成更通用的即时编译虚拟机模式,因此在性能分析中广泛应用起来。
Trace 期间,用户编写的程序嵌入到内核的事件回调上,当 trace 结束,将 bpf 收集的数据传回给用户态进行分析展示。

为了减少 trace 的性能衰减,本文主要基于用户定义的静态 tracepoint (USDT, User-level statically defined tracing) 来分析跨线程的性能。USDT 实现是在代码加入的静态指令,在不 enable 时,只是执行几个 nop 指令,enable 后会执行跳转的 trace 处理函数。
以前面介绍的两个场景为例来看如何进行分析,所使用的 bpf 工具放在了 bpf_tools 上,tracepoint 头文件来源于 Facebook 开源的 Folly C++ library,所有的 tracepoint 的格式如下。
#include "folly/tracing/StaticTracepoint.h"
FOLLY_SDT(trace_name, step_name, arg1, arg2, ...)
2.1 wakeup_latency
主要分析某个用户线程的任务,分配到在其他多个线程上的时延开销。
设置 tracepoint:
首先在用户线程等待 redo 落盘函数 log_write_up_to 前后,插入两个 tracepoint 分别追踪等待的开始和结束,wait_start 设置用户线程需要等待的 lsn。
// user thread
FOLLY_SDT(wakeup, wait_start, lsn);
log_write_up_to(lsn)
FOLLY_SDT(wakeup, wait_end);
在多个后台线程的唤醒点设置 tracepoint,tracepoint 的 name 设置为唤醒顺序的序号,arg1 传入当前线程已经处理的 lsn。当后台线程处理的 lsn 达到 wait_start 设立的 lsn,统计相应的时延开销。
// log_writer
FOLLY_SDT(wakeup, 1, ready_lsn);
log_writer_write_buffer()
FOLLY_SDT(wakeup, 2, log.write_lsn.load());
// log flusher
log_flush_low(log);
FOLLY_SDT(wakeup, 3, llog.flushed_to_disk_lsn.load());
// log_flush_notifier
os_event_set(log.flush_events[slot]);
FOLLY_SDT(wakeup, 4, lsn);
上述的 tracepoint 对应图 1 的时序图唤醒点如下。
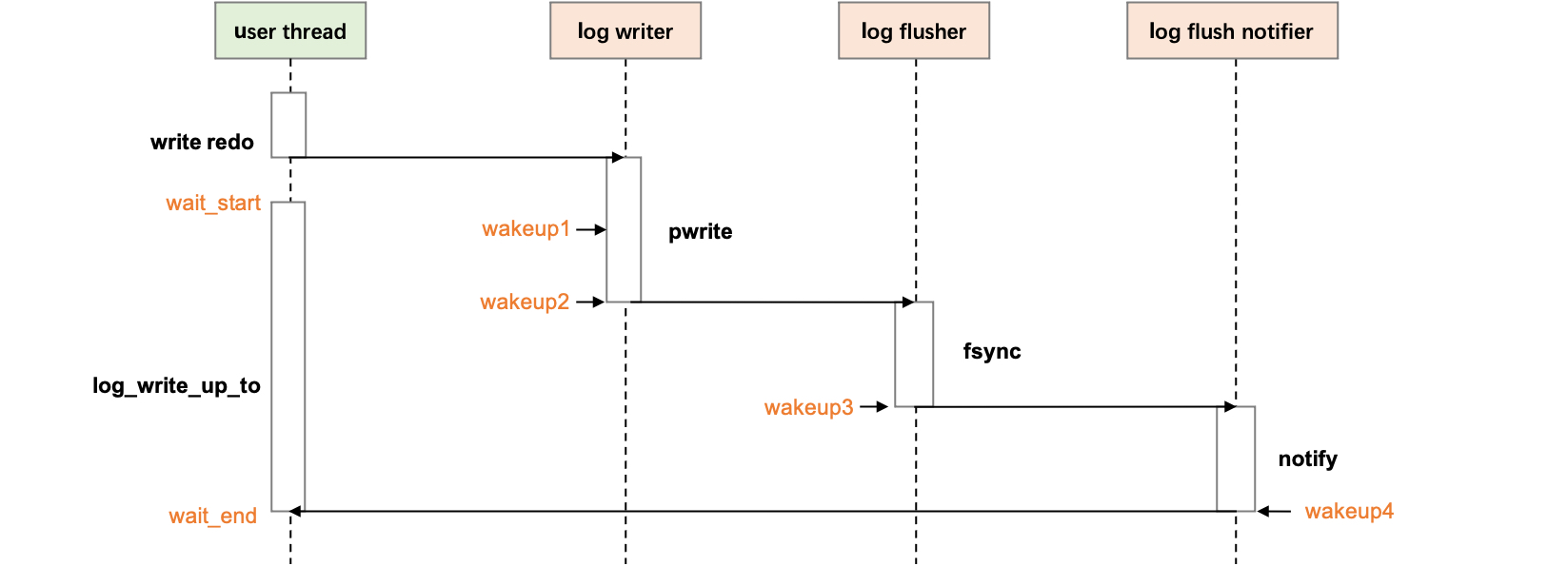
trace 结果:
trace 5s 后,得到等待的时延图,从结果可以看到,trace 一共 4 个唤醒点,因此我们可以看到 log_write_up_to 的 2.6 ms 的时延分解。从用户线程等待开始 (wait_start)到第一个唤醒点,即 log_writer 收到 commit_lsn 的 redo 内容(wakeup 1)平均时延为 298 us,1447 次。其中等待落盘最大的开销是 log_writer 写入到 commit_lsn 到 log_flusher fsync 完成的时延(wakeup 2 -> 3),和 log_flush_notifier 通知完成到用户线程成功被唤醒的时延(wakeup 4 -> wait_end)。当然一大原因主要是并发高,cpu 水位打满带来的,这里不细讨论。
$ sudo python wakeup_latency.py -p 36780 -d 1 -u
[ Attaching probes to pid 36780 for 5 seconds ]
[ 4 wakeup point are set ]
================================================================================
Graph of wakeup latency:
[ wait_start ]
| 298 usecs, 1447 counts
V
[ wakeup 1 ]
| 44 usecs, 1309 counts
V
[ wakeup 2 ]
| 948 usecs, 1369 counts
V
[ wakeup 3 ]
| 451 usecs, 1054 counts
V
[ wakeup 4 ]
| 1131 usecs, 1089 counts
V
[ wait end ]
average wait latency: 2656 usecs, cnt: 1453
...
2.2 latch_latency
主要分析某个用户线程请求的锁。被阻塞时,该锁被哪些线程持有,其对应的函数栈,以及平均持有时间。
设置 tracepoint:
首先在 trx_start_low,插入两个 tracepoint 分别追踪等待 trx_sys mutex 的开始和结束,wait_start 设置需要等待的 latch 地址。
FOLLY_SDT(latch, wait_start, &trx_sys->mutex);
mutex_enter(&trx_sys->mutex);
FOLLY_SDT(latch, wait_end);
在代码每个 mutex 释放位置增加一个 tracepoint,追踪上一次 latch 持有的信息。因为可能在多个函数中调用,USDT 的内存读取限制,需要用非内联的函数包一层。
__attribute__((noinline)) void latch_exit(void *mutex) {
FOLLY_SDT(latch, latch_exit, mutex);
}
void mutex_exit(ib_mutex_t *mutex){
...
latch_exit(mutex)
}
trace 结果:
trace 5 s,可以看到用户线程等待 trx->mutex 了 736 us,一共等待了 2214 次。等待的线程都是 mysqld 的用户线程,大头是等待开启事务 trx_start_low 和提交事务 trx_commit_low 的函数栈,主要是等待的次数多,平均一次获取,要多等待 30 多个线程持有完成之后才能拿到。
$ sudo python latch_latency.py -p 4480 -d 1 -u
[ Attaching probes to pid 4480 for 5 seconds ]
================================================================================
Latch wait latency:
avg : 726 usecs, cnt: 2251
================================================================================
Latency that other threads hold this latch when we are waiting:
| 2 usecs, 2 counts | mysqld | latch_exit(sync0sync.cc:1743);lock_rec_convert_impl_to_expl(buf0buf.ic:776);lock_clust_rec_read_check_and_lock(lock0lock.cc:7184);sel_set_rec_lock(row0sel.cc:1023);row_search_for_mysql(row0sel.cc:4587);ha_innobase::index_read(ha_innodb.cc:9783);handler::read_range_first(handler.cc:2779);handler::multi_range_read_next(handler.cc:6010);QUICK_RANGE_SELECT::get_next(opt_range.cc:10612);rr_quick(records.cc:368 (discriminator 1));mysql_update(sql_update.cc:847);mysql_execute_command(sql_parse.cc:4446);Prepared_statement::execute(sql_prepare.cc:4057);Prepared_statement::execute_loop(sql_prepare.cc:3703);mysqld_stmt_execute(sql_prepare.cc:2725);dispatch_command(sql_parse.cc:1702);do_handle_one_connection(sql_connect.cc:1112);handle_one_connection(sql_connect.cc:1026);start_thread(??:?)
| 18 usecs, 74 counts | mysqld | latch_exit(sync0sync.cc:1743);ReadView::clone_oldest(read0read.cc:455);PrivateReadView::open_purge(read0read.cc:959);trx_purge(trx0purge.cc:2416);srv_purge_coordinator_thread(srv0srv.cc:3224);start_thread(??:?)
| 6 usecs, 39383 counts | mysqld | latch_exit(sync0sync.cc:1743);trx_commit_low(sync0sync.ic:195);trx_commit(trx0trx.cc:2018);trx_commit_for_mysql(trx0trx.cc:2306);innobase_commit(ha_innodb.cc:5375);ha_commit_low(handler.cc:1693);TC_LOG_DUMMY::commit(log.h:122);ha_commit_trans(handler.cc:1611 (discriminator 2));trans_commit_stmt(transaction.cc:440);mysql_execute_command(sql_class.h:3628);Prepared_statement::execute(sql_prepare.cc:4057);Prepared_statement::execute_loop(sql_prepare.cc:3703);mysqld_stmt_execute(sql_prepare.cc:2725);dispatch_command(sql_parse.cc:1702);do_handle_one_connection(sql_connect.cc:1112);handle_one_connection(sql_connect.cc:1026);start_thread(??:?)
| 11 usecs, 39596 counts | mysqld | latch_exit(sync0sync.cc:1743);trx_commit_low(trx0trx.cc:1499);trx_commit(trx0trx.cc:2018);trx_commit_for_mysql(trx0trx.cc:2306);innobase_commit(ha_innodb.cc:5375);ha_commit_low(handler.cc:1693);TC_LOG_DUMMY::commit(log.h:122);ha_commit_trans(handler.cc:1611 (discriminator 2));trans_commit_stmt(transaction.cc:440);mysql_execute_command(sql_class.h:3628);Prepared_statement::execute(sql_prepare.cc:4057);Prepared_statement::execute_loop(sql_prepare.cc:3703);mysqld_stmt_execute(sql_prepare.cc:2725);dispatch_command(sql_parse.cc:1702);do_handle_one_connection(sql_connect.cc:1112);handle_one_connection(sql_connect.cc:1026);start_thread(??:?)
| 21 usecs, 40188 counts | mysqld | latch_exit(sync0sync.cc:1743);trx_start_low(sync0sync.ic:195);row_search_for_mysql(row0sel.cc:4110);ha_innobase::index_read(ha_innodb.cc:9783);handler::read_range_first(handler.cc:2779);handler::multi_range_read_next(handler.cc:6010);QUICK_RANGE_SELECT::get_next(opt_range.cc:10612);rr_quick(records.cc:368 (discriminator 1));mysql_update(sql_update.cc:847);mysql_execute_command(sql_parse.cc:4446);Prepared_statement::execute(sql_prepare.cc:4057);Prepared_statement::execute_loop(sql_prepare.cc:3703);mysqld_stmt_execute(sql_prepare.cc:2725);dispatch_command(sql_parse.cc:1702);do_handle_one_connection(sql_connect.cc:1112);handle_one_connection(sql_connect.cc:1026);start_thread(??:?)
3 总结
通过两个 MySQL 中典型的场景,使用 eBPF-USDT 分析了跨线程的时延开销。希望通过尽可能的少修改代码和影响性能,能看到我们关注的线程长时间等待信号量和锁的原因。因为工具大部分从某个用户线程的视角,因此主要在负载均衡或者已知线程 ID 的情况下进行分析。跨线程的并发性能分析较为困难,有更好的分析方式欢迎交流。
[2] Folly: Facebook Open-source Library
[3] BPF Performance tool, Brendan Gregg.