MySQL查询优化分析-PolarDB MySQL的查询加速与优化
Author: 杨泽(勉仁)
MySQL查询优化分析文章:
前言
在前面的文章中,讲述了社区MySQL查询优化概念和分析。MySQL作为一个广泛使用的开源数据库,其在查询优化基础能力上有着不错的表现,对很多场景也做了比较极致的优化。不过MySQL在充分利用当前硬件资源做查询加速,复杂的查询处理上也还有着一些欠缺。例如社区MySQL单查询只能使用一个线程执行,无法并行执行,无法充分利用CPU资源;不支持列存、SIMD指令加速;对复杂的查询缺少基于代价的查询变换能力。
随着社会数字化的不断发展,企业的业务规模、业务模式不断发展,企业业务需要存储与处理的数据量越来越大。PolarDB MySQL作为一款存算分离的云原生数据库,各类大中小客户都可以充分享受其带来的技术优势、成本优势。其中很多企业存储的数据量对比社区MySQL用户有着数量级上的增加,一些客户在一个实例中会存储几百T数据。同时PolarDB MySQL有非常多企业级特性,吸引各个行业的客户使用,很多客户有着复杂的SQL使用场景或者分析场景。在这样的背景下,PolarDB MySQL中做了大量企业级查询加速与优化功能,使得客户能够充分利用硬件资源、特性,能够更好的处理复杂查询,解决各类突发问题。而且PolarDB MySQL完全兼容MySQL,客户无需任何业务修改即可使用这些功能,不需担心业务SQL被厂商绑定。
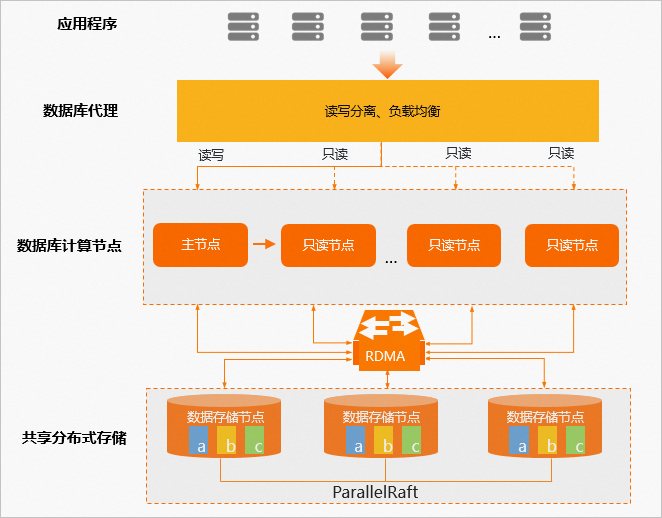
弹性并行执行(Elastic Parallel Query)
背景
PolarDB MySQL存算分离,突破了单机存储的限制,用户会存储几百T的数据。通过共享存储,可以快速拉起计算节点,获得极致的弹性能力。用户在PolarDB中存储数据量的增加,业务查询数据也不断增加。但是社区MySQL一直以来对于单个查询都只能够单线程执行,其在8.0版本中增加的并行也只能处理单表全量count(*)操作且有很多的限制与不足(这个场景PolarDB同时做了下推优化,比社区MySQL性能和表现更优)。
PolarDB的弹性并行执行(Elastic Parallel Query简称ePQ)能力,可以支持单机并行和多机并行,充分利用不断发展的硬件能力,通过客户的硬件资源加速用户查询。这样解决了慢查询的单核瓶颈,对客户一些轻分析查询可以快速返回结果,满足客户的实时性需求。
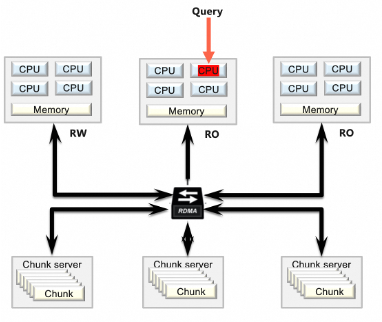
实现
PolarDB MySQL会基于代价选择并行执行计划,来避免性能的回退或者消耗大量计算资源却不能提升查询性能。同时PolarDB的ePQ支持Auto-DOP能力,会基于实例当前的负载、用户查询计算量、用户查询的加速比选择合适的并行度(degree)。这些可以使用户放心使用ePQ加速查询,而不必担心性能回退或者部分极端场景下计算资源使用的大幅增加导致系统负载过大而hang住。
ePQ基于代价选择合适的并行执行计划后,会对计划做clone并插入Exchange、Gather节点,对处理的数据做分片。这些数据分片会被启动的各个worker按轮询或者预分配方式消费处理。
最终数据会汇总到Leader节点返回给客户端。
效果
PolarDB的ePQ对各种类型的SQL都做了并行执行支持。32核单机并行,TPCH 100G的平均加速比达到17倍,最高加速比达到56倍(有部分计算下推优化)。4节点,TPCH 100G的平均加速在59倍,最高加速比达159倍。
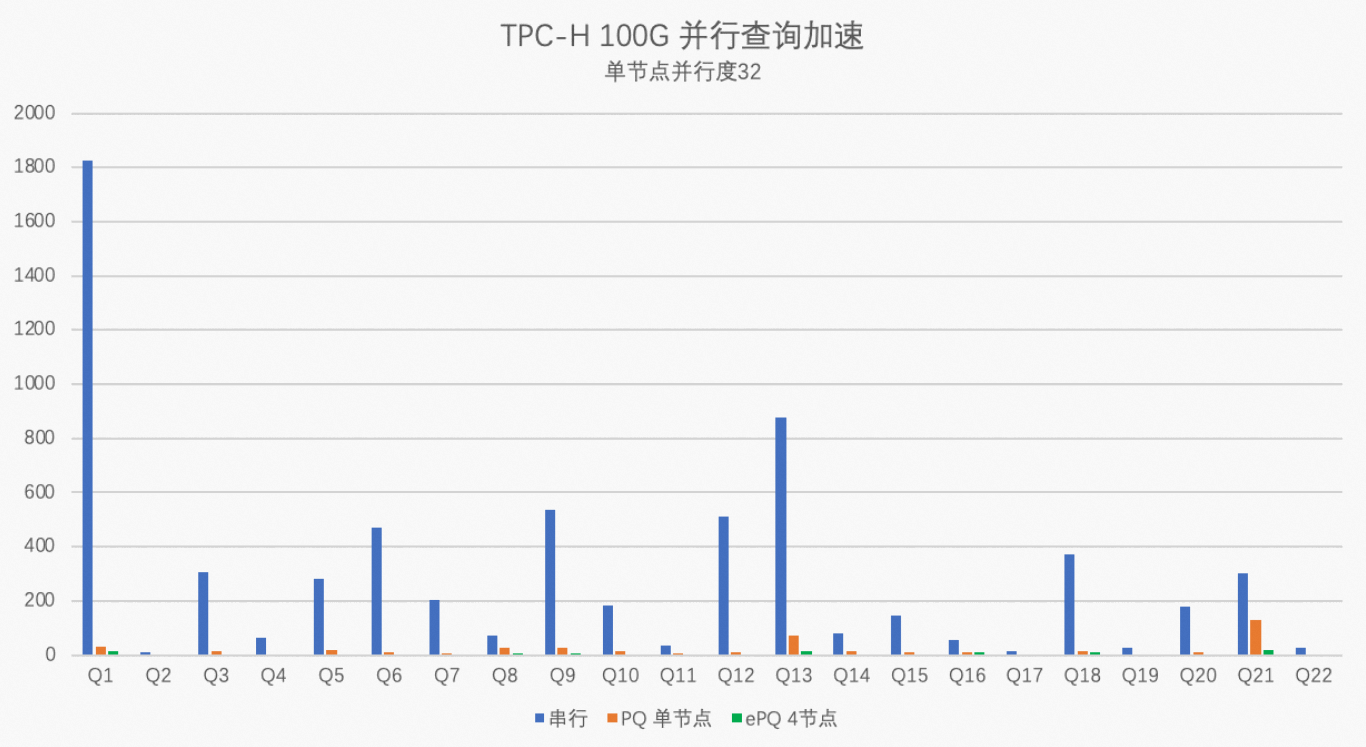
使用
开启ePQ可以在集群地址配置中开启,通过访问地址开启并行执行。
也可以直接配置并行执行相关参数,相关参数如下:
-
max_parallel_degree配置并行度,默认值和规格相关。
-
parallel_degree_policy配置并行度策略。默认是REPLICA_AUTO仅只读节点并行且使用自动dop功能,如果希望各个节点一致,可以配置为AUTO。
-
cost_threshold_for_parallelism考虑并行执行的代价阈值。当查询的代价超过该阈值的时候才会考虑并行,默认值是50000。
列存索引(IMCI)
背景
虽然PolarDB有行存的并行执行,但一些客户场景,行存的执行性能无法满足其场景需求。这些查询往往有更大的数据分析量,有更高的查询返回时间要求。
PolarDB MySQL通过列存索引(In-Memory Column Index,简称IMCI)实现了一体化处理实时事务和实时数据分析能力。客户可以通过一套数据库同时满足业务TP和AP需求。其使用完全兼容MySQL,客户业务SQL不需要做任何修改。
实现
PolarDB IMCI支持了事务级别一致性的行列混合存储;向量化执行引擎,核心算子SIMD加速,充分利用硬件能力;完全兼容MySQL。
创建列存索引后,表上的数据修改、DDL都会应用到列存存储。客户查询语句可以通过指定连接地址发给列存执行,也可以直接通过集群地址由行列优化器基于代价自动选择执行引擎。对于AP查询,优化器能够自动识别,并转给AP的RO生成列存的执行计划执行。
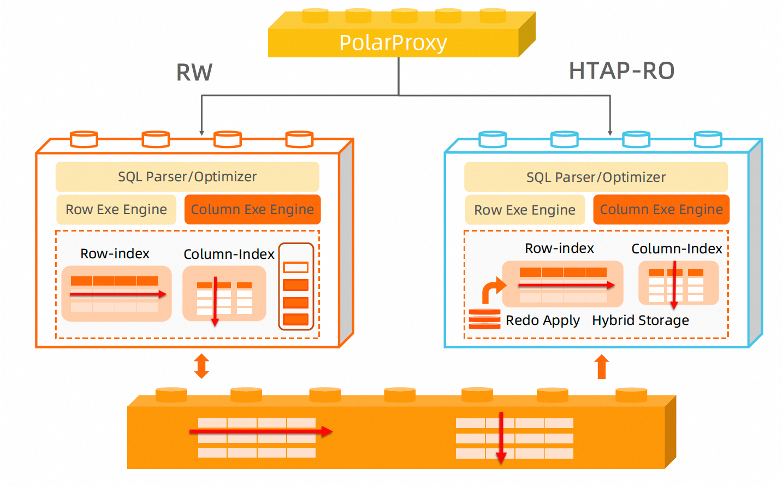
效果
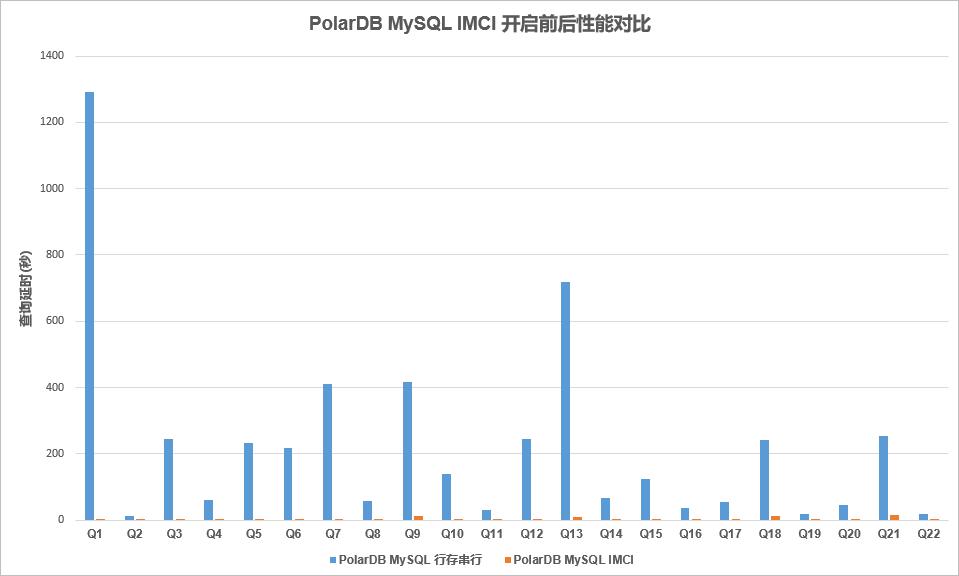
对TPCH 100G数据做性能对比测试。列存开启前后加速效果明显,部分语句可以达到百倍提升。
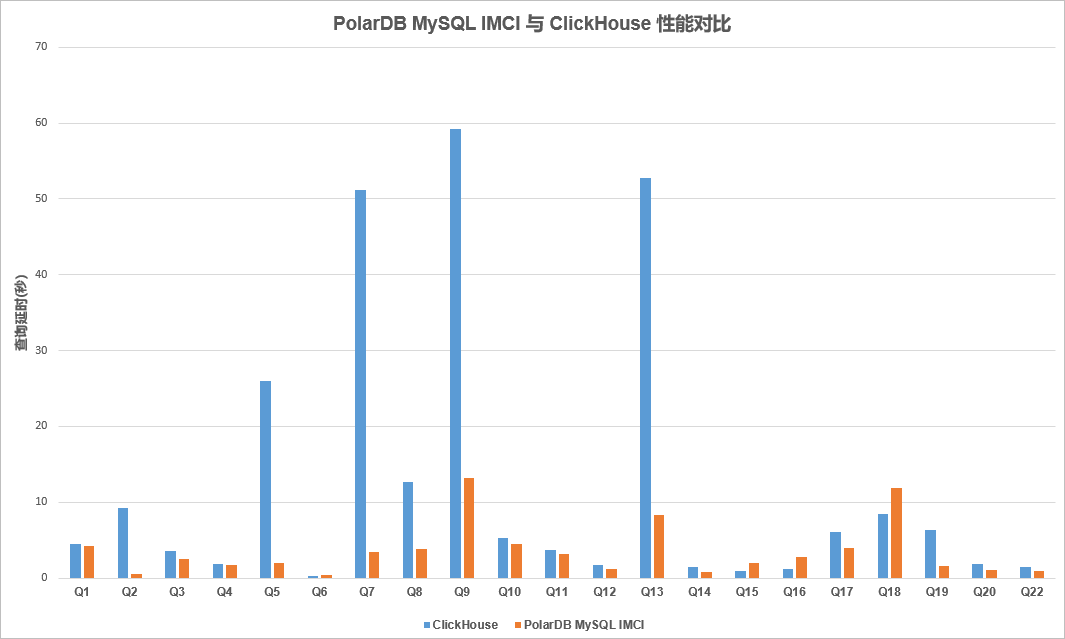
与ClickHouse对比,也有非常明显的性能优势,在Scan\Agg\Join上表现突出。
使用
在使用时,客户可以添加列存只读节点。

对需要创建列存索引的库、表添加列存索引。
-- 创建表COMMENT添加
CREATE TABLE t2(
col1 INT,
col2 DATETIME,
col3 VARCHAR(200)
) ENGINE InnoDB COMMENT 'COLUMNAR=1';
-- ALTER TABLE添加
ALTER TABLE t11 COMMENT 'COLUMNAR=1';
-- 表级添加
CREATE COLUMNAR INDEX ON <db_name>.<table_name>;
CREATE COLUMNAR INDEX ON <table_name>;
-- 库级别添加
CREATE COLUMNAR INDEX FOR TABLES IN <db_name>;
CREATE COLUMNAR INDEX FOR TABLES FROM <db_name>;
对于自动分流,参数loose_imci_ap_threshold是考虑列存执行的查询代价阈值,默认值是50000。
复杂查询变换
查询变换是将查询语句改写成关系代数等价的形式,是数据库优化中的一个非常重要的部分。合适的查询变换能够大幅提升查询效率,例如谓词下推可以提前过滤数据,子查询展开可以减少嵌套执行代价、生成更优Join Order。
PolarDB MySQL的客户来自各个行业,一些客户有着很复杂的SQL形式,一些SAAS场景的终端可以有大量选项自由选择。这些SQL很难被业务开发人员手动优化,而合适的等价变换往往可以获取十倍、百倍、千倍的性能提升。因此PolarDB开发了大量复杂查询变换,支持了基于代价的查询变换选择,包括但不限于:子查询解关联、LeftJoin消除、Join条件下推、IN转JOIN、子查询折叠、各类条件下推、谓词推导等等。
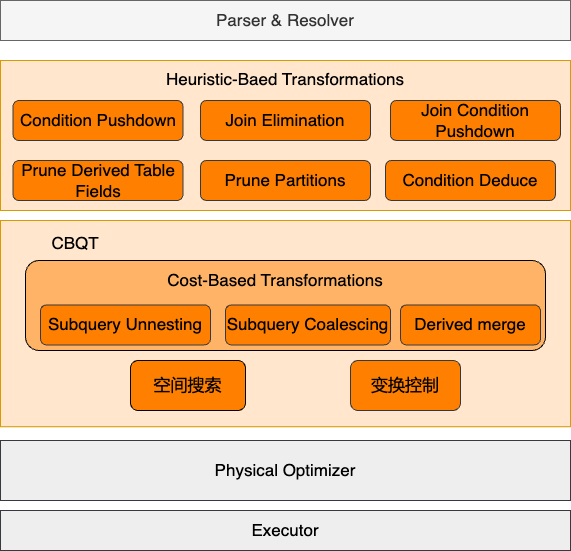
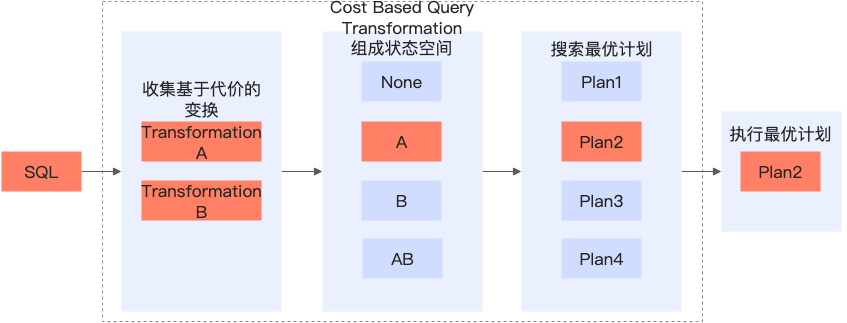
对这些查询变换我们仅对Join消除、谓词下推、子查询解关联做一个基本介绍。具体可以查看PolarDB MySQL的官网文档-查询改写。
- LeftJoin消除
对于一些报表业务,业务界面有各种不同的过滤选项可以填。对应的报表查询就是将不同选项对应的维度表用LeftJoin关联起来,叠加各类过滤条件。如果没有过滤条件,这些右表用唯一键关联,且查询除了关联条件没有使用右表相关列的场景,就可以把右表删除。例如下面的语句中,sales_fact是销售记录,product_dim和customer_dim分别是商品和顾客的维度表。当查询语句没有做product_dim和customer_dim其他过滤选项的时候,就可以把LEFT JOIN都消除,大幅提升查询性能。
-- 当开启join elimination
mysql> set @@join_elimination_mode=on;
-- 三张表的LEFT JOIN,优化后仅需要扫描一张表
mysql> EXPLAIN SELECT COUNT(*) FROM sales_fact s LEFT JOIN product_dim p ON s.productkey = p.productkey LEFT JOIN customer_dim c ON c.customerkey = s.customerkey\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: NULL
-- 当关闭join elimination
mysql> set @@join_elimination_mode=off;
Query OK, 0 rows affected (0.00 sec)
-- 需要对三张表做JOIN操作
mysql> EXPLAIN SELECT COUNT(*) FROM sales_fact s LEFT JOIN product_dim p ON s.productkey = p.productkey LEFT JOIN customer_dim c ON c.customerkey = s.customerkey\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: s
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: NULL
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: p
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: test.s.productkey
rows: 1
filtered: 100.00
Extra: Using index
*************************** 3. row ***************************
id: 1
select_type: SIMPLE
table: c
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: test.s.customerkey
rows: 1
filtered: 100.00
Extra: Using index
3 rows in set, 1 warning (0.00 sec)
-- 表结构
CREATE TABLE `sales_fact` (
`id` bigint(20) NOT NULL,
`productkey` bigint(20) DEFAULT NULL,
`customerkey` bigint(20) DEFAULT NULL,
`create_time` timestamp NOT NULL,
`update_time` timestamp NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE TABLE `product_dim` (
`productkey` bigint(20) NOT NULL,
`productname` varchar(20) DEFAULT NULL,
`productclass` bigint(20) DEFAULT NULL,
PRIMARY KEY (`productkey`)
) ENGINE=InnoDB;
CREATE TABLE `customer_dim` (
`customerkey` bigint(20) NOT NULL,
`customer_name` varchar(20) DEFAULT NULL,
`customer_address` varchar(40) DEFAULT NULL,
PRIMARY KEY (`customerkey`)
) ENGINE=InnoDB;
- 谓词下推
上面语句中,我们如果分析一些商品的销售量,写成如下语句。可以看到如果打开谓词下推,由于谓词条件列在group by列中,那么可以把外层的谓词条件下推到derived table中,从而提前过滤数据。
-- 打开derived condition pushdown功能
mysql> set derived_cond_pushdown_mode=on;
--可以看到谓词下推到derived table中
mysql> EXPLAIN SELECT p.productkey, p.productname, s.sale_count from product_dim p, (SELECT productkey, COUNT(*) sale_count FROM sales_fact GROUP BY productkey) s WHERE p.productkey = s.productkey AND p.productkey > 1 AND p.productkey < 10\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: p
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
partitions: NULL
type: ref
possible_keys: <auto_key0>
key: <auto_key0>
key_len: 9
ref: test.p.productkey
rows: 2
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: sales_fact
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where; Using temporary
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `test`.`p`.`productkey` AS `productkey`,`test`.`p`.`productname` AS `productname`,`s`.`sale_count` AS `sale_count` from `test`.`product_dim` `p` join (/* select#2 */ select `test`.`sales_fact`.`productkey` AS `productkey`,count(0) AS `sale_count` from `test`.`sales_fact` where ((`test`.`sales_fact`.`productkey` > 1) and (`test`.`sales_fact`.`productkey` < 10)) group by `test`.`sales_fact`.`productkey`) `s` where ((`s`.`productkey` = `test`.`p`.`productkey`) and (`test`.`p`.`productkey` > 1) and (`test`.`p`.`productkey` < 10))
-- 关闭derived condition pushdown功能
mysql> set derived_cond_pushdown_mode=off;
-- 可以看到谓词没有下推
mysql> EXPLAIN SELECT p.productkey, p.productname, s.sale_count from product_dim p, (SELECT productkey, COUNT(*) sale_count FROM sales_fact GROUP BY productkey) s WHERE p.productkey = s.productkey AND p.productkey > 1 AND p.productkey < 10\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: p
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
partitions: NULL
type: ref
possible_keys: <auto_key0>
key: <auto_key0>
key_len: 9
ref: test.p.productkey
rows: 2
filtered: 100.00
Extra: NULL
*************************** 3. row ***************************
id: 2
select_type: DERIVED
table: sales_fact
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1
filtered: 100.00
Extra: Using temporary
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `test`.`p`.`productkey` AS `productkey`,`test`.`p`.`productname` AS `productname`,`s`.`sale_count` AS `sale_count` from `test`.`product_dim` `p` join (/* select#2 */ select `test`.`sales_fact`.`productkey` AS `productkey`,count(0) AS `sale_count` from `test`.`sales_fact` group by `test`.`sales_fact`.`productkey`) `s` where ((`s`.`productkey` = `test`.`p`.`productkey`) and (`test`.`p`.`productkey` > 1) and (`test`.`p`.`productkey` < 10))
- 子查询解关联
子查询解关联以TPCH的Q17为例,该查询是获得比平均供货量20%还要低的小订单量。在没有解关联的情况下,该语句的执行对于外层查询的每一行都要执行关联子查询计算聚合结果。
SELECT SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM lineitem, part
WHERE p_partkey = l_partkey
AND p_brand = 'Brand#43'
AND p_container = 'WRAP PKG'
AND l_quantity < (
SELECT 0.2 * AVG(l_quantity) -- aggregate function
FROM lineitem
WHERE l_partkey = p_partkey -- correlated
);
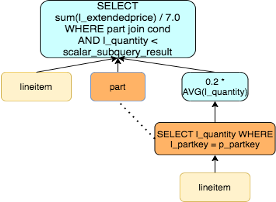
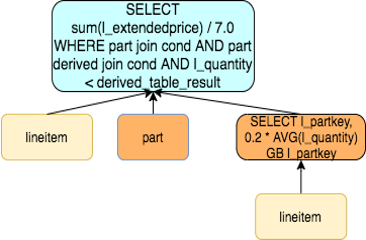
我们可以先分组聚合,再和外层做JOIN,即改写成如下语句。对于子查询没有关联索引的场景,这样可以大幅减少扫描行数,子查询中的表仅需要扫描一次。
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part,
(select
l_partkey as avg_lpartkey,
(0.2 * avg(l_quantity)) as avg_20ratio
from
lineitem
group by
l_partkey) as avg_lineitem
where
p_partkey = l_partkey
and p_brand = 'Brand#44'
and p_container = 'WRAP PKG'
and p_partkey = avg_lineitem.avg_lpartkey
and l_quantity < avg_20ratio;
当有唯一键关联,我们可以通过Window Function改写成如下形式,即在JOIN的同时,对要分析的数据做分组聚合。
SELECT Sum(V.avg_extprice) / 7.0 AS avg_yearly
FROM part,
(SELECT (CASE WHEN l_quantity < 0.2 * Avg(l_quantity) OVER (PARTITION BY l_partkey)
THEN l_extendedprice
ELSE NULL
END) avg_extprice,
l_partkey
FROM lineitem) V
WHERE p_partkey = V.l_partkey
AND p_brand = 'Brand#44'
AND p_container = 'WRAP PKG'
AND V.avg_extprice IS NOT NULL;
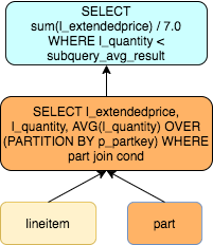
在PolarDB中通过基于代价的查询变换,会自动根据查询场景选择合适的变换方式。对TPCH的多个关联子查询都可以有不错的性能提升。
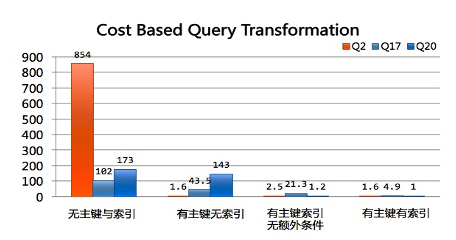
计算下推
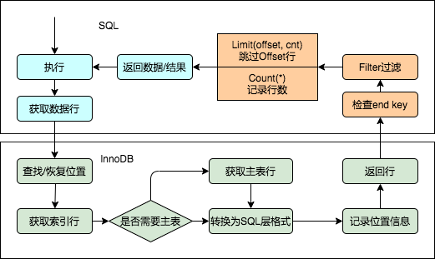
MySQL是一个多引擎数据库,在存储引擎和SQL计算层之间定义了清晰的数据访问接口,同时存储引擎和SQL计算引擎的行数据组织格式也有不同。这带来的好处是,存储引擎可以方便地对接MySQL。但同时也导致SQL层和存储引擎层缺少融合,不能充分利用存储引擎的特性来规避存储引擎一些较大的开销。
下图是社区MySQL在处理Limit Offset、Count时的逻辑,引擎层需要逐行扫描获取转换为SQL层数据格式,传递给SQL层。而SQL层对Offset的数据行在没有额外谓词情况下就会直接skip掉,对于Count也仅仅是计数。
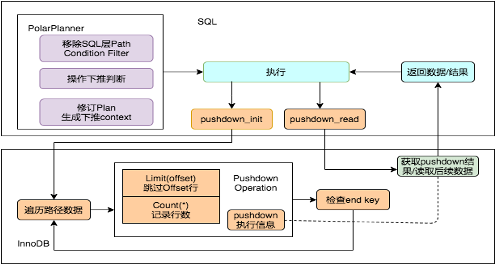
PolarDB MySQL针对InnoDB引擎做了很多的优化,可以将一些计算下推到存储引擎从而极大的提升性能。例如Limit Offset、Count、谓词等计算下推到引擎层后可以带来的好处有:
-
降低SQL层与引擎层交互的开销。
-
减少记录、恢复行位置的开销。
-
减少数据转换为SQL层格式的开销。
-
减少部分场景访问主表的开销。
计算下推在Limit Offset、Count的客户场景中可以获取的性能提升如下:
| 下推操作 | 是否回表 | 性能提升 |
|---|---|---|
| Limit | 否 | 6.69X |
| 是 | 75.90X | |
| Count | 否 | 2.38X |
自适应优化
在前面文章 MySQL查询优化分析 - 常见慢查问题与优化方法 中,我们提到了一些场景的慢查是由于优化器无法感知实际数据分布而导致计划选择错误。由于优化器无法感知真实数据情况导致估算偏差,最优计划和很差的计划之间代价可能差异不大。有时客户在业务验证期间发现这类问题,而有时会等业务迁移或者统计信息发生一些改变到临界点后,优化器才突然选择很差的计划从而影响业务。
我们可以看之前文章提到的场景,这类Order by Limit语句优化器选择提供ordering序的索引,而ordering序索引是否是较优的计划完全和用户数据的分布相关。这类问题在优化器行列路由选择中也会遇到,由于估算不准导致没有将慢查路由给列存执行。
--优化器认为索引i_c1仅需要扫描877行就能遇到满足条件的数据行。
--但实际满足条件的行在索引末尾,需要扫描166w行
mysql> EXPLAIN SELECT * FROM t9 WHERE c2 > 90100 AND c2 < 92000 ORDER BY c1 LIMIT 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t9
partitions: NULL
type: index
possible_keys: i_c2
key: i_c1
key_len: 9
ref: NULL
rows: 877
filtered: 0.11
Extra: Using where
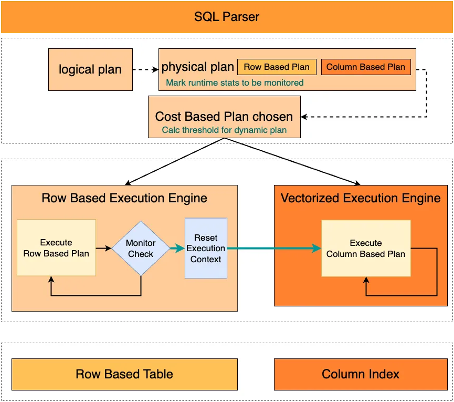
为了解决这一问题,PolarDB在优化器中会标记这类无法感知真实数据分布仅做推算的信息,在执行阶段收集真实扫描行数等信息。当真实执行达到优化器预先评估的阈值后,就会触发计划的切换。下图是自适应执行在行列路由中的应用。相关参数loose_adaptive_plans_switch有imci_chosen和ordering_index两个开关,分别控制自适应执行在行列路由和ordering index选择上的使用。
Fast Query Cache
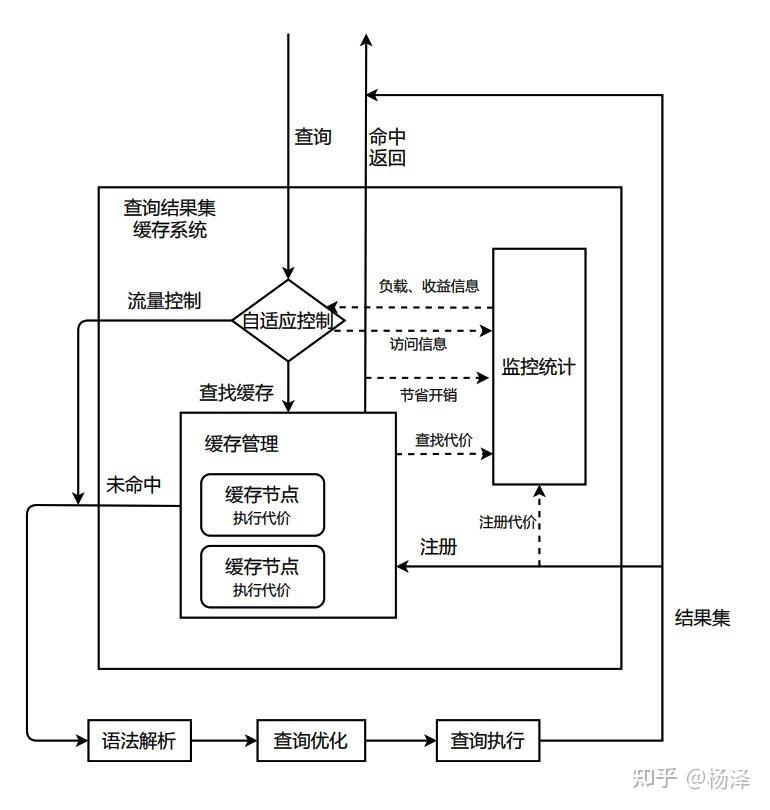
Fast Query Cache也是PolarDB MySQL研发的一项功能,做了大量无锁设计和自适应优化,能够支持高并发,能够使业务享受缓存命中带来的性能提升而无需担心有不适配场景使业务性能受影响。
社区MySQL的Query Cache是2001年引入,其对现代硬件的多核并发支持非常差,社区在MySQL 8.0将其移除。
PolarDB设计实现的Fast Query Cache功能,有以下特点:
极致并发能力。没有任何全局锁,主要缓存结构使用无锁HASH。失效和淘汰使用版本号和引用计数处理,相关行为简化为一个原子操作。
-
动态的内存使用和回收。维护LRU链表,缓存命中时间、lease时间。
-
支持集群架构。支持一主多读、多主等架构,集群代理访问。
-
正确性保证。各个场景设计、全量测试回归等等保证结果正确性。
-
自适应缓存。自适应控制模块记录了缓存命中收益、缓存额外开销,根据负载实际情况动态调整缓存策略。
其在sysbench压测下的读性能提升如下。
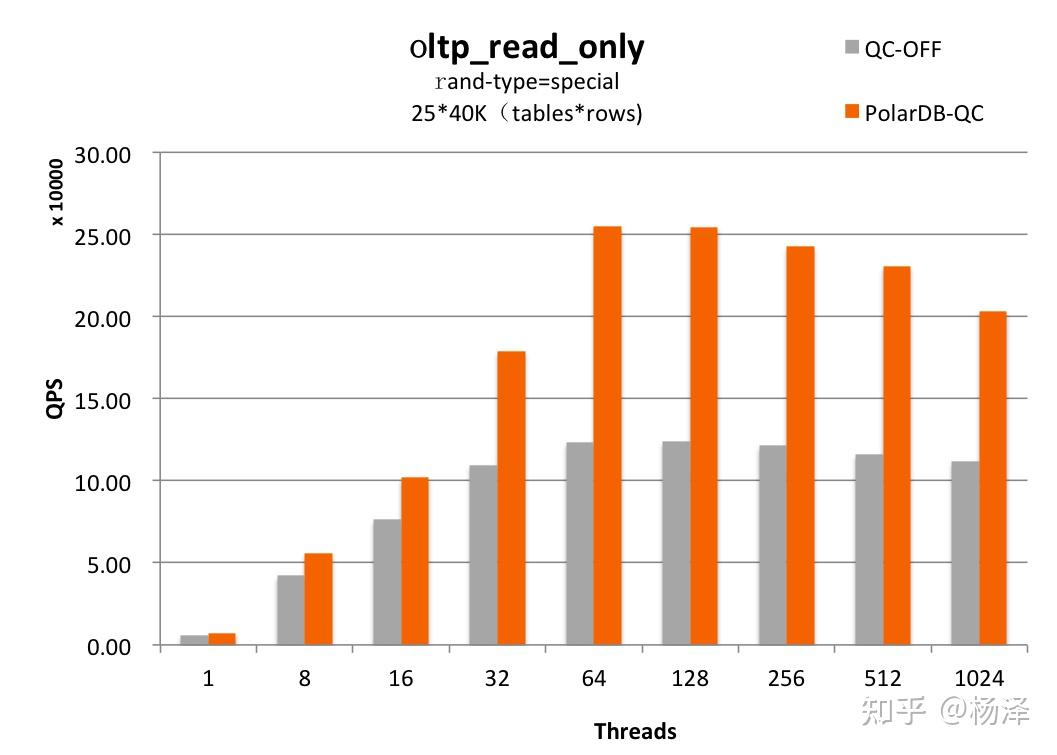
目前在最新版本的PolarDB MySQL中Fast Query Cache默认打开。各类客户业务场景都有很好的收益,缓存命中率往往在30%-60%,甚至更高。这些业务系统示例:营销系统,数据导入后更新少;教育行业,学生名单、成绩等很少更新;对于订单系统,其地理信息表、商品类目表、供应商表、用户表较少更新,也可以有不错的命中率。
Auto Plan Cache
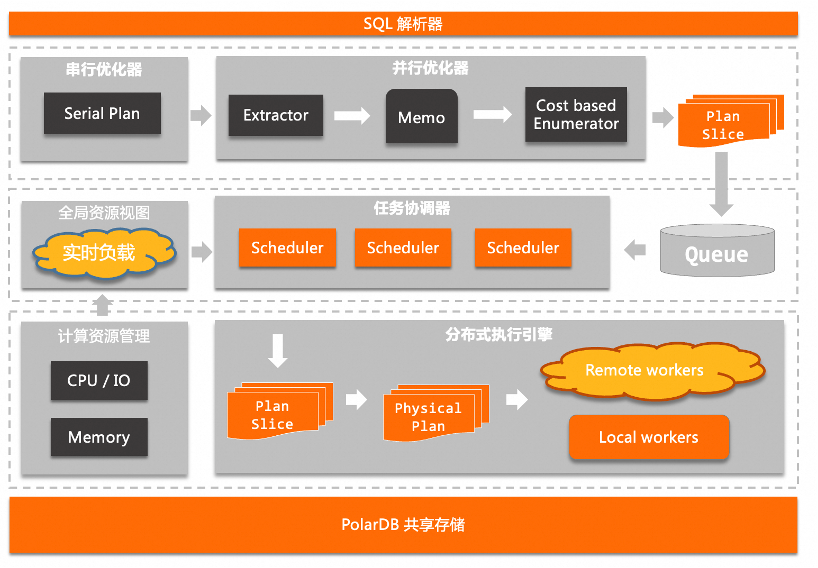
执行计划的选择需要考虑诸多因素,如统计信息、不同的连接顺序和不同的查询变换等。对于不同的查询语句,其优化时间不同,可能会存在某些SQL语句的查询优化时间在整体执行时间中占比很大的情况。如果这类SQL语句执行的次数较多,就会因为优化时间占比大导致系统负载增加。
为了提升优化时间占比太多的SQL语句的查询性能,降低系统负载,PolarDB MySQL版提供了Auto Plan Cache功能。Auto Plan Cache功能提供了AUTO、DEMAND和ENFORCE三种模式。用户可以根据需要将loose_plan_cache_type参数设置为三种模式中的任意一种模式,推荐模式为AUTO,将SQL语句的执行计划缓存在Plan Cache中,以减少执行查询语句时的优化时间,提升查询性能。当缓存在Plan Cache中的执行计划涉及的表的统计信息发生变化,或对缓存中执行计划引用的表执行了DDL操作时,缓存的执行计划会自动失效。
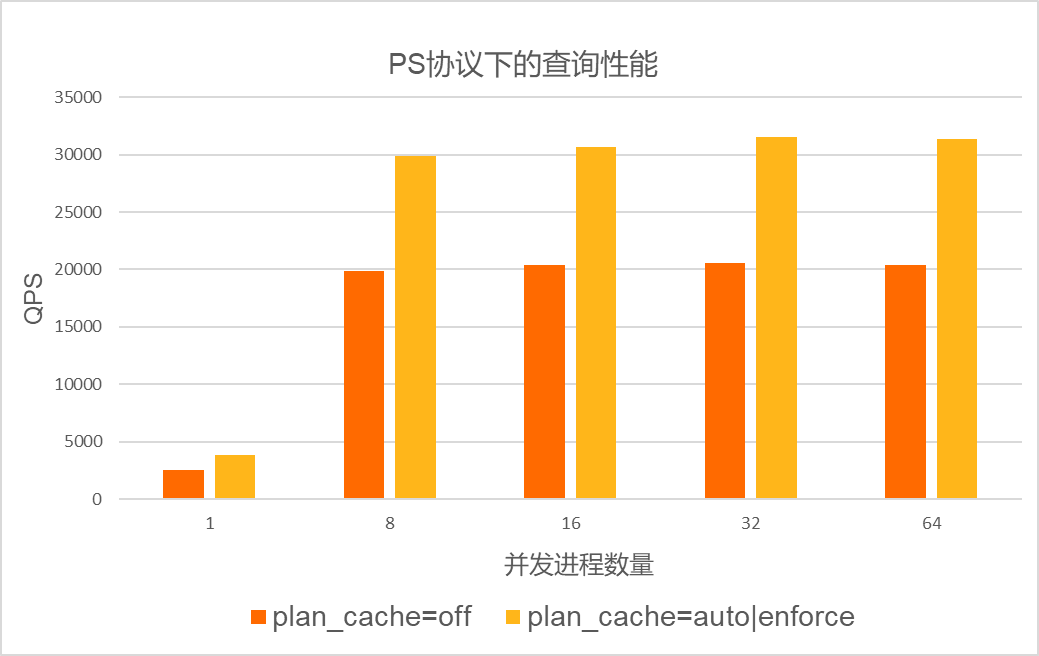
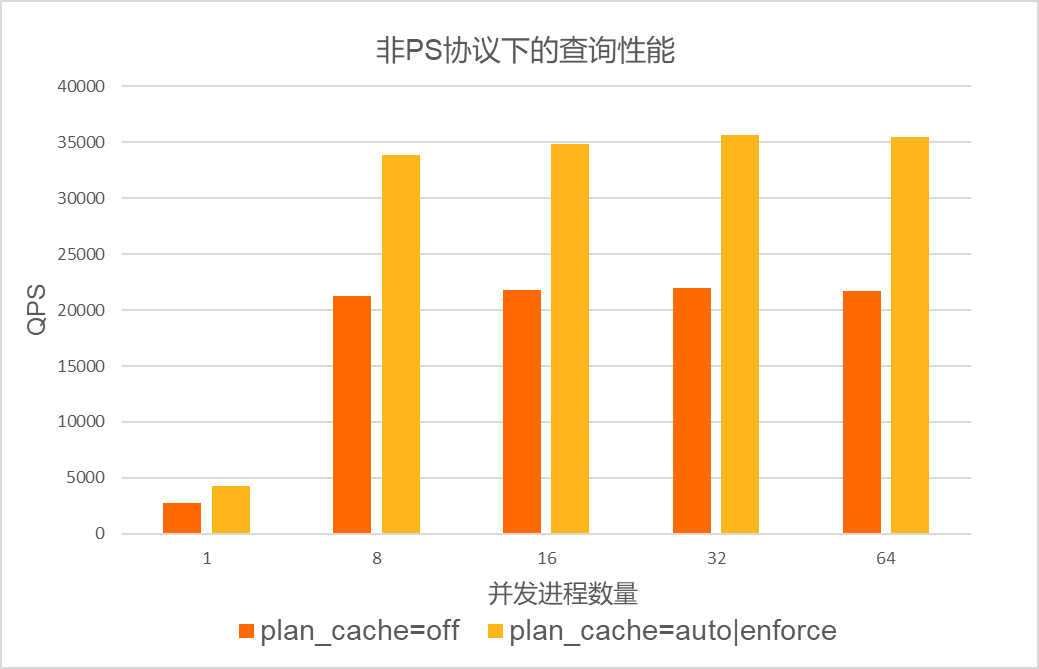
对于优化时间占比较多的场景,例如in list场景。在集群规格为8核32 GB,数据库中已创建25张表,单张表存储400万行数据的场景下进行压测。压测使用的SQL语句为:SELECT id FROM sbtestN WHERE k IN(...),其中,IN LIST的长度为20。在PS协议和非PS协议下,测试loose_plan_cache_type参数配置为OFF、AUTO和ENFORCE时的性能。测试结果如下:
- PS协议下的性能测试结果如下:
- 非PS协议下的性能测试结果如下:
常用的辅助功能
Outline固定执行计划
Outline是一个用于后台固定执行计划的功能。优化器是基于统计信息估算代价选择最优计划,其无法得知真实执行时的各种数据情况,也就无法保证能一直选择到正确的执行计划。对于自适应执行优化,也难以处理所有的复杂查询,数据分布场景。当在生产环境中,发生计划选择错误问题,如果要求数据库管理员在业务SQL中固定执行计划会面临诸多挑战:
-
发布流程的复杂性:在应用程序中手动添加HINT,并且每次调整HINT都需要发布新的应用版本,这不仅耗时耗力,还可能带来额外的风险。
-
添加HINT的复杂性:一些应用的SQL是通过中间件自动生成的,手动添加HINT既不现实又十分繁琐。
-
HINT管理的复杂性:在应用程序中添加了大量HINT后,管理成本随之增加,数据库管理员难以清晰了解整个系统中存在的HINT数量。
而用于后台固定执行计划的Outline功能允许数据库管理员在后台固定特定SQL语句的执行计划,并对这类SQL的HINT进行添加和修改。Outline提供了以下优势:
-
独立于应用程序:无需修改应用程序代码,也无需重新发布,仅在数据库层面进行配置即可生效。
-
快速响应和调整:及时响应并调整执行计划,以有效解决慢SQL问题,提升系统的稳定性与性能。
-
精细化控制和管理:为不同的SQL提供相应的Outline,可以清晰呈现整个系统的Outline及其状态(例如命中情况、是否开启等)。
Outline是根据语句模板匹配,同一个查询模板不同的常量值会匹配同一个规则。具体使用方法可以查看PolarDB MySQL的官网文档 计划固化 (Statement Outline)。
Concurrency Control(CCL)
CCL是一个基于SQL语句做并发控制的功能。在生产环境中,可能会遇到以下场景:
-
突发的数据库访问流量,导致数据库活跃线程数非常大,数据库Hang死。
-
消耗资源大的SQL,大并发执行。
-
一些SQL执行消耗的资源突然大幅增加,可能计划变差或者导入大量数据,数据量突然变化。
CCL就可以对SQL做并发控制,避免大的并发把使数据库雪崩,也可以在问题排查与处理期间控制业务影响范围。
CCL支持按照语句模板匹配、Schema\Table匹配、命令类型匹配多种方式。对触发最大并发限制后的行为,可以配置拒绝或者等待。其具体使用方法可以查看PoalrDB MySQL官网文档 Concurrency Control。
SQL Trace
在数据库使用过程中,面对负载的持续高位,我们可能会需要查看消耗负载比较大的TopSQL。当一条查询语句的性能突然下降,我们可能需要排查语句的执行计划是否变化,语句执行时扫描行数、物理IO读是否明显变化。
PolarDB MySQL版提供的SQL Trace功能,会跟踪SQL语句的各类执行信息,如:执行计划和执行统计信息(包括扫描行数、执行时间等)。可以帮助用户快速地发现因执行计划变更而引发的性能变化,统计当前集群中消耗负载较大的TopSQL。
当开启SQL Trace后,在查询优化阶段会记录当前查询选择的执行计划,包含了索引路径和访问方式的选择、JOIN ORDER、选择的查询变换等,还包含了是否选择并行执行、IMCI列存执行。
在执行阶段会收集执行时的统计信息,包含了等待时间、执行时间、返回行数、扫描行数、影响行数、逻辑读次数、物理同步读次数、物理异步读次数的总值、最小值、最大值,还有总的执行次数、第一次执行时间和最后一次执行时间等信息。同时会记录是普通执行方式还是Prepare/Execute方式。如果是命中query cache直接返回也会记录下来。
SQL Trace的信息存储在SQL Sharing的基础组件中,后台线程会根据SQL Trace的引用时间和过期时间判断是否可以回收。同时用户可以通过接口来控制SQL Trace的记录。
- 获取指定SQL的执行信息和执行计划信息。
SELECT * FROM information_schema.sql_sharing WHERE sql_id = polar_sql_id('select * from t');
- 分别获取按照总执行时间、平均执行时间和总扫描行数三个维度Top10的SQL语句。
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_EXEC_TIME DESC LIMIT 10;
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_EXEC_TIME/EXECUTIONS DESC LIMIT 10;
SELECT * FROM information_schema.sql_sharing WHERE TYPE='sql' ORDER BY SUM_ROWS_EXAMINED DESC LIMIT 10;
SQL Trace功能具体使用方法可以查看PoalrDB MySQL官网文档 SQL Trace。
总结
本文介绍了PolarDB MySQL对查询加速与优化做的一些功能,用户可以根据自己的需要选择适合的功能。例如:业务慢查希望有几倍的性能提升,又有较多的计算资源,可以尝试并行执行做加速;当业务是分析类查询,可以尝试选择列存加速。
在MySQL查询优化分析这个系列的文章中,我们介绍了MySQL优化执行的基础概念、常用分析方法、常见慢查问题与优化方法、PolarDB MySQL的查询加速与优化。希望读者能够通过这些文章,对查询优化分析有更多了解,使用PolarDB有更好的体验。
相关资料
弹性并行查询(Elastic Parallel Query) https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/elastic-parallel-query/
列存索引(IMCI) https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/imcis/
查询改写 https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/query-rewrite/
Fast Query Cache https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/fast-query-cache
计算下推 https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/computing-pushdown/
Auto Plan Cache https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/auto-plan-cache?spm=a2c4g.11186623.help-menu-2249963.d_5_15_1_1.418023d122lFoR
计划固化 (Statement Outline)https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/statement-outline
Concurrency Control https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/concurrency-control