PolarDB MySQL跨可用区强一致解决方案
Author: 邑雄
背景
PolarDB MySQL在单个可用区部署时,采用分布式存储架构,数据具有三副本。这种设计确保了即使单个存储节点发生故障,系统的可用性和数据一致性也不会受到影响。与单可用区部署相比,双可用区部署在另一个可用区中额外部署了一套实例,并通过异步复制或半同步复制在可用区之间同步数据,从而提供了更高的容灾能力。然而,这种配置不能完全保证两个可用区之间的数据一致性。为了应对机房故障,保证多个可用区之间数据强一致,我们提出了新的PolarDB MySQL跨可用区强一致解决方案:三可用区部署模式。下面从架构,高可用,性能3个方面介绍一下三可用模式。
架构
首先来看一下整体的架构图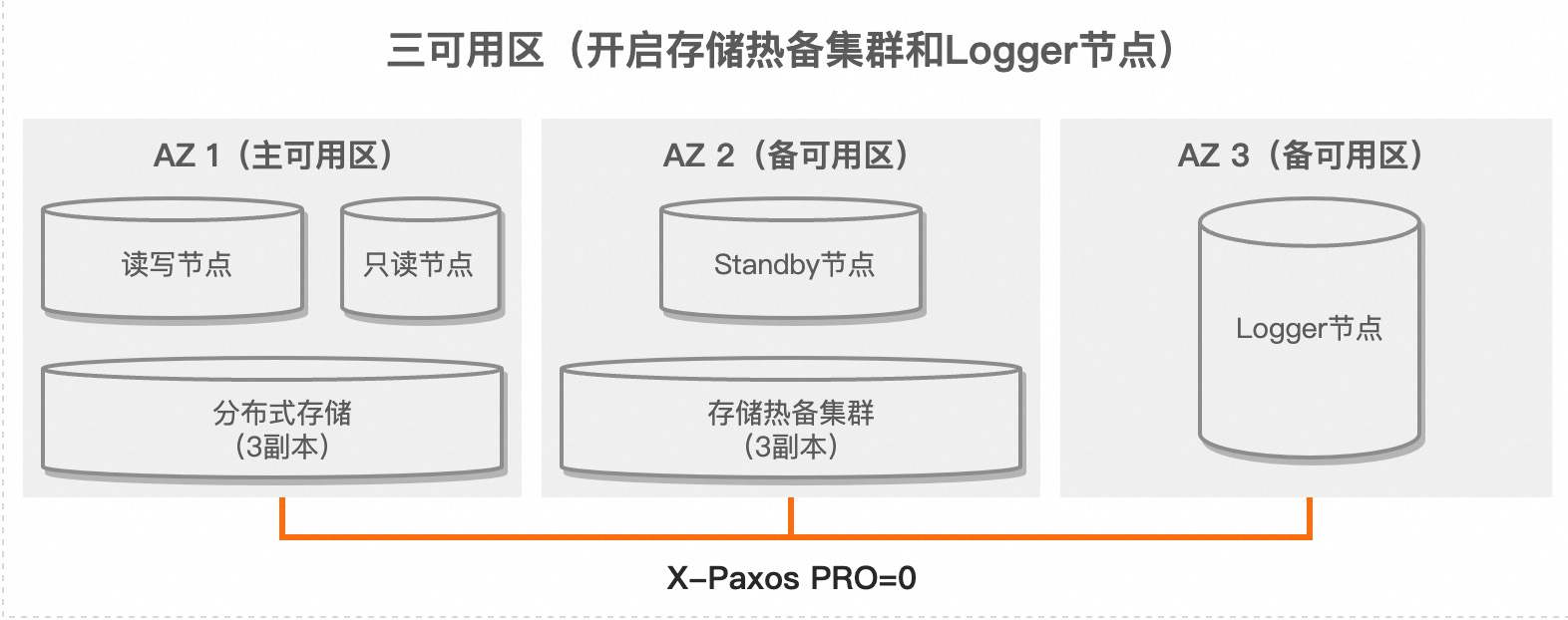 与半同步和异步复制方式相比,采用一主一备一日志的三节点架构通过结合物理复制和X-Paxos协议来实现数据同步,提供了更可靠的数据一致性保障。在主节点上,写操作必须等待对应的Redo日志发送给备节点,并且达成多数派后才会客户端返回成功,从而确保数据的强一致性。主节点和备节点都存储完整数据和完整日志,而日志节点仅存储Redo日志。与双可用区部署相比,这种架构只是多了一个日志节点,存储成本增加很少。由于日志节点不包含数据,因此它不对外提供读写服务。
与半同步和异步复制方式相比,采用一主一备一日志的三节点架构通过结合物理复制和X-Paxos协议来实现数据同步,提供了更可靠的数据一致性保障。在主节点上,写操作必须等待对应的Redo日志发送给备节点,并且达成多数派后才会客户端返回成功,从而确保数据的强一致性。主节点和备节点都存储完整数据和完整日志,而日志节点仅存储Redo日志。与双可用区部署相比,这种架构只是多了一个日志节点,存储成本增加很少。由于日志节点不包含数据,因此它不对外提供读写服务。
MySQL官方也提供了一种强一致性的方案:MySQL Group Replication (MGR)。然而,MGR模式的一些缺点导致其在实际生产环境中的使用体验不尽如人意:
- Binlog要求:MGR模式必须开启binlog,对于某些业务来说,binlog并不是必需的。开启binlog会导致性能下降。
- 大事务处理:对于大事务,MGR的性能较差,甚至会直接报错。
关键点
为了实现我们的方案,需要对内核代码进行大量修改,Redo日志本身是通过LSN变量区分,引入了consensus_lsn变量,表示对于lsn < consensus_lsn的Redo日志都已经达多数派。
Buffer Pool刷脏限制
在刷脏时需要加一个限制,不能随意刷脏。要等待page的newest_modification <= consensus_lsn,以保证写入磁盘的数据不是脏数据。避免磁盘文件数据超过目前达成的一致性状态。
Checkpoint推进
因为checkpoint_lsn之前的Redo日志都可以删除,所以为了防止Redo日志还没有发送给备节点就被删除了,同样需要等待新checkpoint_lsn <= consensus_lsn。
节点启动
节点启动需要先进行选主操作,然后和其他节点对齐Redo日志,删除脏日志,最后进行崩溃恢复。
备节点日志回放
备节点运行的时候接收主节点发送过来的日志,不能直接回放,同样也要等日志达成多数派。
事务提交
为了保证已经提交的事务不丢失,必须保证日志已达成多数派后才会返回成功,否则事务提交失败。
DDL
主节点文件操作以后,可能出现故障了,此时主节点的文件和备节点的文件是不一样。备节点被选成新的主节点会回滚DDL事务。原来主节点故障消除以后,需要把对应的文件操作还原回去。具体细节后续的文章中详细解释。
Redo log
为了提高消息发送的性能,我们直接从内存中的log.buf里面copy数据发送给follower节点,那么我们需要限制数据还没被copy出去的时候,log.buf不能被overwrite。
高可用
主节点会定期通过心跳机制与备节点和日志节点进行通讯,以保持运行状态。当检测到主节点发生故障(假设机房没有发生故障),主节点上挂载的只读节点将被提升为主节点,继续对外提供读写服务。如果发生机房故障,导致主可用区完全无法服务,备节点将被选举为新的主节点(Leader),对外提供读写服务。这些故障转移过程是自动进行的,无需人工介入处理。
性能
基于Binlog日志的同步机制必须等待事务提交时才能生成完整的Binlog日志,然后才能将这些日志同步到备可用区。相比之下,PolarDB MySQL版采用基于物理复制(Redo日志)的同步机制,具备更高的同步效率。在事务执行过程中,Redo日志会不断生成,并通过X-Paxos协议实时传输到另外两个备可用区。这种机制使得日志的传输时机比Binlog日志更早,从而提高了同步效率。
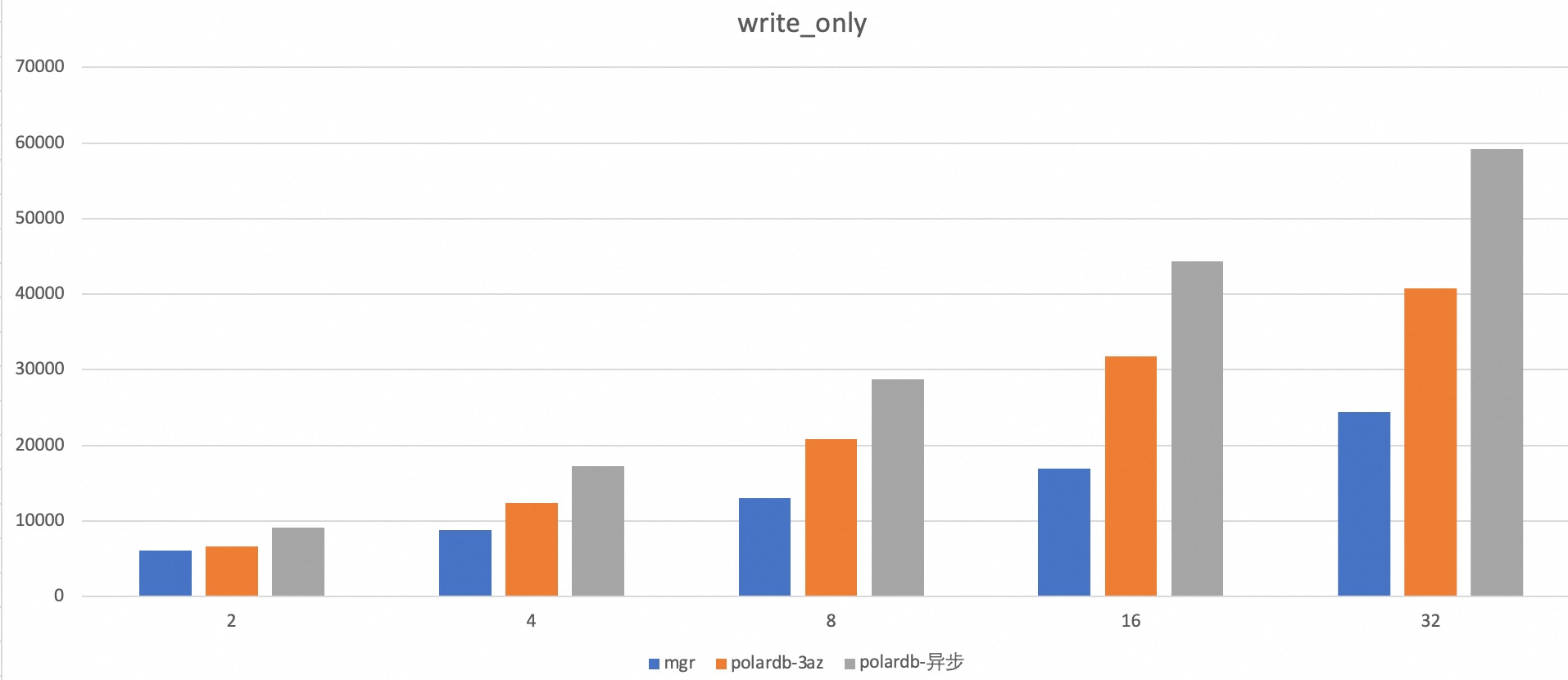
测试工具:Sysbench下的oltp_write_only。
数据量:10张数据表,每张表500万行数据。
在相同的物理环境测试结果如下,可以看到polardb强一致方案性能优化官方的mgr。