Range-Prefix Skip Scan介绍
Author: 于良永(良缘)
背景
在 MySQL 中,当我们访问一个表时,有两种主要的数据访问方式:全表扫描(Full Table Scan)和索引扫描。索引扫描又可以分为全索引扫描(Index Scan)和范围索引扫描(Range Scan)。一般而言,范围索引扫描的效率高于全索引扫描,而全索引扫描的效率又高于全表扫描。当查询的 WHERE 条件中包含索引列的范围条件时,我们可以利用这些条件进行范围扫描,从而减少扫描次数。然而,并不是所有索引列的范围条件都能有效地利用范围扫描,尤其是在复合索引的情况下。
示例分析:我们创建了一个表,有6列数据(为a, b, c, d, e, f),其中前5列组成一个复合索引。
Case 1: Full Table Scan
对上述table进行如下查询:
select a,b,c,d,e,f from ss limit 10;
得到的EXPLAIN计划如下:
这个例子中我们访问了所有列,因此Mysql优化器选择了Full Table Scan的方式进行查询。
Case 2: Index Scan
将查询换成如下形式:
select a,b,c,d,e from ss limit 10;
得到的EXPLAIN计划如下:
由于我们没有扫描f列,直接扫描索引即可获得查询所需的全部数据。因此优化器选择了index scan,即全索引扫描。
Case 3: Range Scan
将查询继续换成如下形式:
select a,b,c,d,e from ss where a > 2;
得到的EXPLAIN计划如下:
我们设置了where条件,令a > 2,因此优化器选择Range Scan的方式进行扫描。Range Scan是范围索引扫描,是对于全索引扫描的优化。Mysql执行器在执行此查询时,会通过索引的B+树快速定位到where条件约束的区间范围内,只在该区间内部进行扫描,而无需对全部的索引进行扫描。
Case 4: 回退到Index Scan
将查询继续换成如下形式:
select /*+no_skip_scan(ss)*/ a,b,c,d,e from ss where b > 2;
查询中的hint是禁止优化器做Skip Scan的优化。我们得到的EXPLAIN计划如下:

根据EXPLAIN的结果,我们发现优化器采用了index scan,而没有采取看起来更优的Range Scan,这是因为这个例子中无法直接使用b列的条件做Range Scan。由于Mysql的索引是B+树的形式,复合索引在B+树的排列顺序是按照复合索引的第一个key part(在这个例子中是a列)来排序的;只有当a列的值相同,才会按照b列的值排序;b列的值相同才会按照c列的值排序,以此推类。下图展示了复合索引的B+树结构(主要关注叶子节点的顺序):
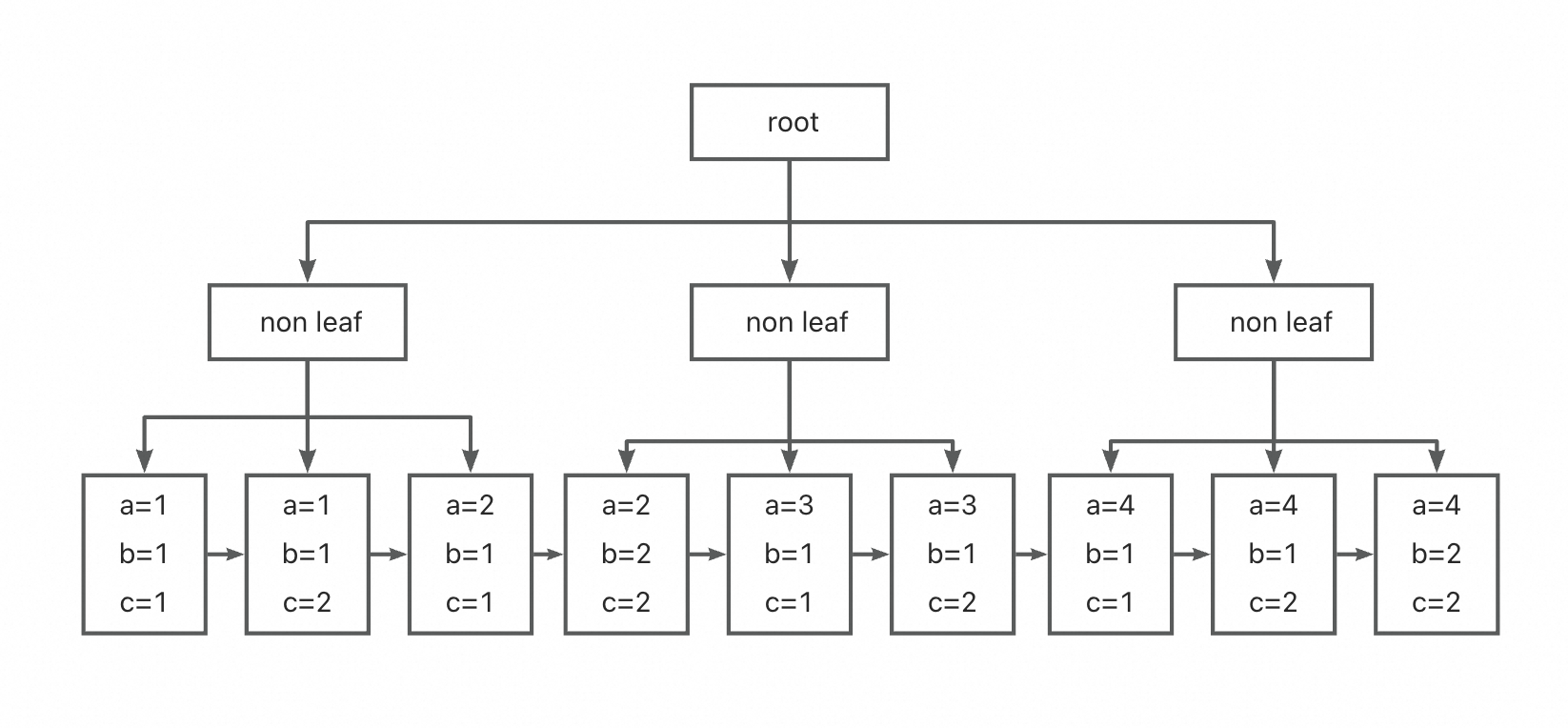
一般来说,对于复合索引idx(a, b, c),由于复合索引在B+树是按照复合索引的第一个key part的大小进行排列的,所以传统的Range Scan适用于如下的场景:
- 仅有a列的范围过滤(where a > 1)
- a列等值过滤,b列范围过滤(where a = 1 and b > 2)
- a,b列等值过滤,c列范围过滤(where a = 1 and b = 2 and c > 3)
例如在where a = 1 and b > 2的场景,传统的Range Scan首先在B+树中定位到满足a = 1 and b > 2条件的第一个key,然后进行顺序遍历索引,直到遍历完所有a = 1 and b > 2的条件为止,最后结束索引的范围扫描。
由于复合索引在B+树是按照复合索引的第一个key part的大小进行排序,因此对于如下几个例子,传统Range Scan则不能很好地利用全部key part的索引信息:
- b列范围过滤(where b > 2)
- c列范围过滤(where c > 3)
- a,b列范围过滤(where a > 1 and b > 2)
- a,c列范围过滤(where a > 1 and c > 2)
传统Range Scan对于情况1和2,直接进行全索引扫描;对于情况3,4只会对索引a进行范围索引扫描,而对于索引b和c进行全索引扫描。
因此,下面会介绍Mysql的Skip Scan以及PolarDB的新特性Range-Prefix Skip Scan。Skip Scan可以对情况1和2进行b列/c列的范围索引扫描;Range-Prefix Skip Scan可以对情况3和4进行b列/c列的范围索引扫描。
Case 5: Skip Scan
对上述table进行如下查询:
select a,b,c,d,e from ss where b > 2;
得到的EXPLAIN计划如下:

在这个例子中,Mysql优化器采用了Skip Scan优化。Skip Scan是一种在复合索引中应用范围索引扫描的技术。和Range Scan不同的是,Skip Scan可以跳过复合索引的前几个keypart,对后面带有range条件的keypart做范围索引扫描。在表很大且b列选择率很高(filter剩的行数很少)的场景下,Skip Scan能有效减少索引的扫描次数。
Skip Scan的工作原理如下:对于查询select a, b from tbl where b >= 1 and b <= 2,执行器会对于每一个a列的值,都对b列在从1到2之内做一次范围扫描:
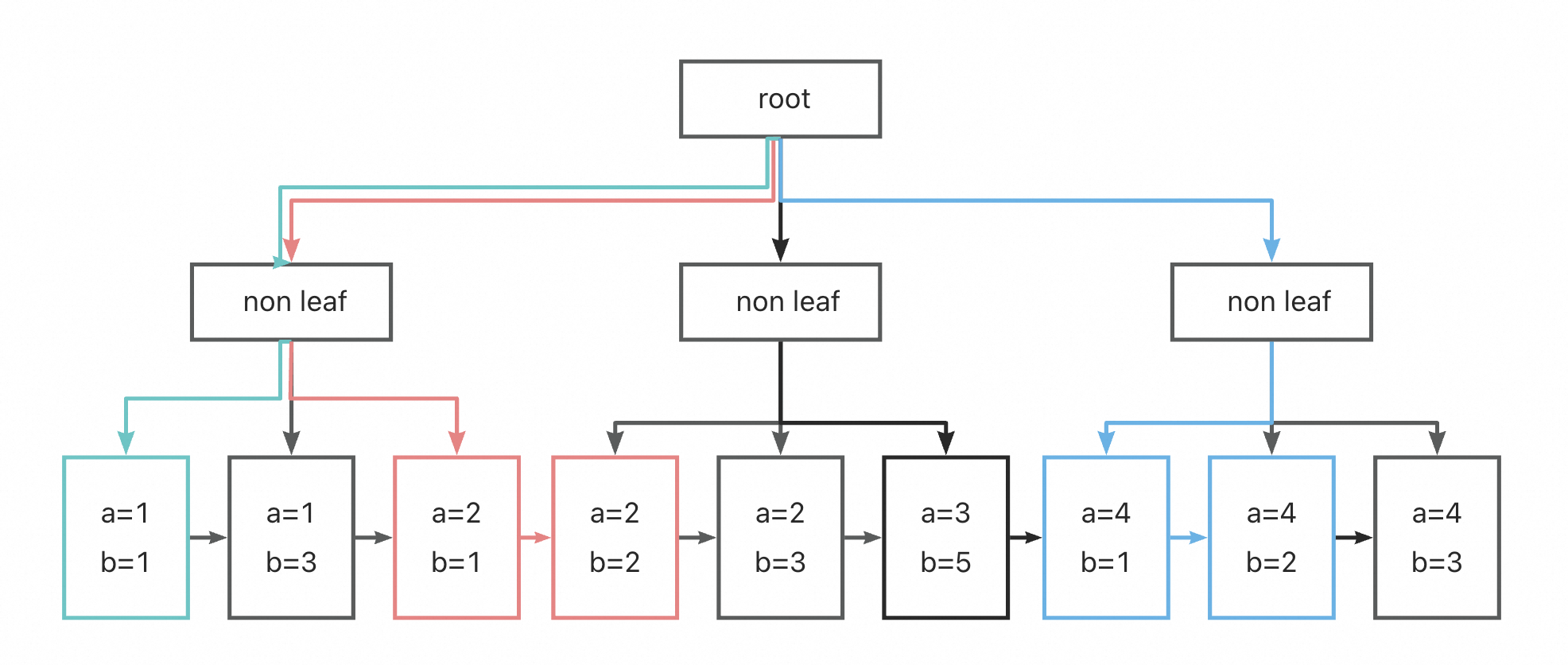
- 在B+树中定位到满足a = 1 and b = 1条件的第一个key(绿色线)
- 顺序遍历所有a = 1的索引,直到b不满足b <= 2
- 在B+树中定位到满足a = 2 and b = 1条件的第一个key(红色线)
- 顺序遍历所有a = 2的索引,直到b不满足b <= 2
- 在B+树中定位到满足a = 4 and b = 1条件的第一个key(蓝色线)
- 顺序遍历所有a = 4的索引,直到b不满足b <= 2
根据上述的例子,我们可以总结出适用Skip Scan优化的查询模版:
SELECT A_1,...,A_k, B_1,...,B_m, C
FROM T
WHERE
EQUAL(A_1,...,A_k)
AND RANGE(C);
其中:
- A_1,…,A_k, B_1,…,B_m, C组成一个复合索引。且该复合索引中索引的顺序严格满足A_1,…,A_k, B_1,…,B_m, C
- A_i列在谓语中出现的形式为等值,即col = val或者col in (val1, val2,…);B_i列在谓语中不存在任何条件;C列为范围查询。
- 满足k >= 0,m > 0,即谓语中可以没有等值条件。
例如查询select a,b,c,d from ss where a = 1 and b in (1,2) and d > 3中,A_1为a列,A_2为b列,B_1为c列,C为d列。
Range-Prefix Skip Scan介绍
原理介绍
Mysql原生的的Skip Scan只能处理where语句中有一个range条件的情况。然而,当一个复合索引内部涉及两列的范围查询时,例如 SELECT a, b FROM tbl WHERE a >= 2 AND b >= 1 and b <= 2,这种情况只能走普通的Range Scan,而不能用到Skip Scan。为了解决这个问题,PolarDB Mysql新的特性Range-Prefix Skip Scan支持对这种类型的查询做Skip Scan优化。
和传统的Skip Scan技术类似,Range-Prefix Skip Scan也可以跳过复合索引的若干keyparts。然而二者的区别是,Skip Scan只能对查询中复合索引的某一列做范围索引扫描,而Range-Prefix Skip Scan可以同时对两列做范围索引扫描。
例如,在SELECT a, b FROM tbl WHERE a >= 2 AND b >= 1 and b <= 2的场景下,优化器无法选择Skip Scan的扫描方式,但是可以选择Range-Prefix Skip Scan。在执行阶段:在满足a的谓语条件的前提下,对于每一个a列的值,都做一次b列在从1到2之内的范围扫描:
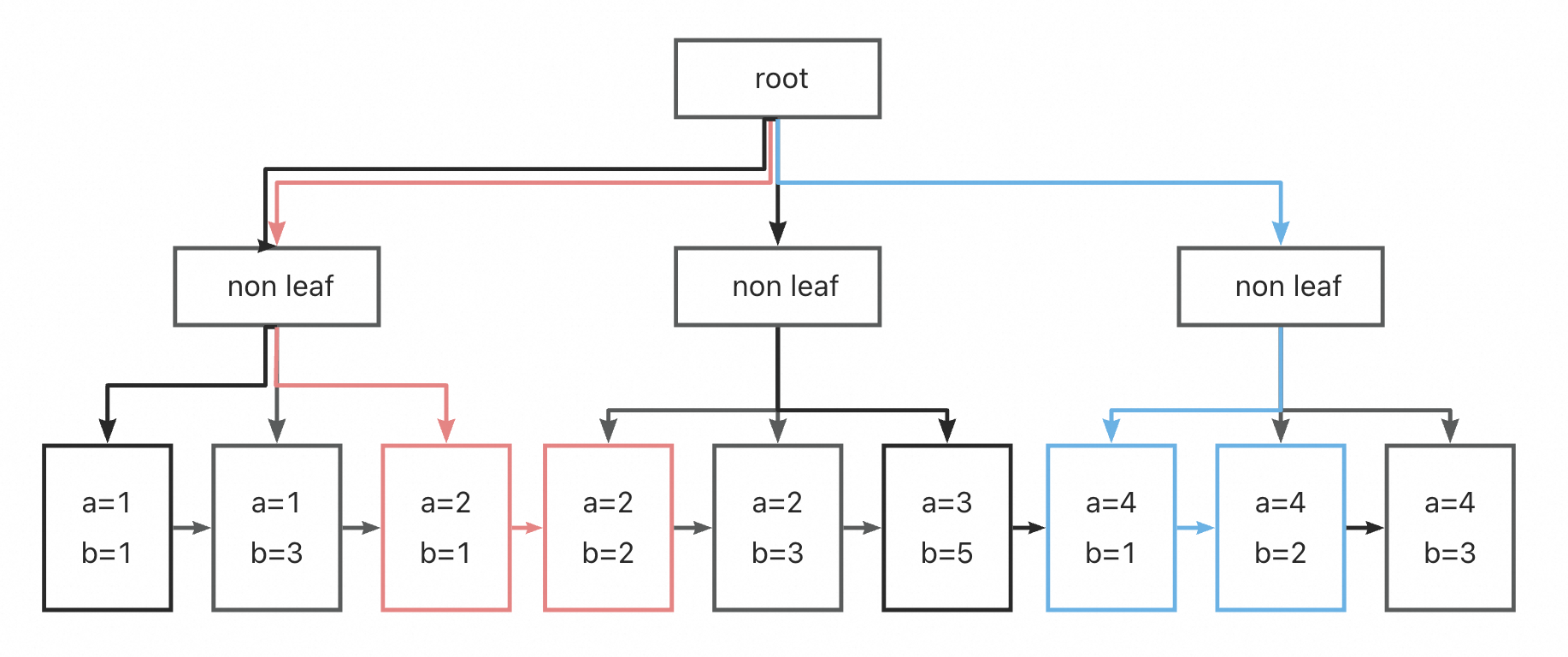
- 在B+树中定位到满足a = 2 and b = 1条件的第一个key(红色线)
- 顺序遍历所有a = 2的索引,直到b不满足b <= 2
- 在B+树中定位到满足a = 4 and b = 1条件的第一个key(蓝色线)
- 顺序遍历所有a = 3的索引,直到b不满足b <= 2
和上文的skip scan的执行示意图相比,Range-Prefix Skip Scan在执行时跳过了原本为绿色的线,因为a = 1的所有B+树节点均不满足查询谓语条件。
根据上述的例子,我们可以总结出适用Range-Prefix Skip Scan优化的查询模版:
SELECT A_1,...,A_k, C_1, B_1,...,B_m, C_2
FROM T
WHERE
EQUAL(A_1,...,A_k)
AND RANGE(C_1) AND RANGE(C_2);
- A_1,…,A_k, C_1, B_1,…,B_m, C_2组成一个复合索引。且该复合索引中索引的顺序就是A_1,…,A_k, C_1, B_1,…,B_m, C_2
- A_i列在谓语中出现的形式为等值,即col = val或者col in (val1, val2,…);B_i列在谓语中不存在任何条件;C_1列为范围查询,C_2列为范围或等值查询。
- 满足k >= 0,m > 0,即谓语中可以没有等值条件。
- 满足k >= 0,m >= 0
根据上述介绍,我们发现Range-Prefix Skip Scan的优化场景也可以使用普通的Range Scan。而最终使用哪种scan方式取决于优化器计算出来的两种扫描方式预估出来的代价。下文会简单介绍Range-Prefix Skip Scan的代价计算原理。
代价计算
根据上文表述,适用于Range-Prefix Skip Scan的查询模式如下:
SELECT A_1,...,A_k, C_1, B_1,...,B_m, C_2
FROM T
WHERE
EQUAL(A_1,...,A_k)
AND RANGE(C_1) AND RANGE(C_2);
为了方便表述,我们对以下概念进行介绍:
- eq-prefix:表示每一组A_1, …, A_k的值。例如在以下查询中:
select a,b,c,d,e from tbl where a IN (1,2,3) and b IN (4,5) and d >= 1 and d <= 4 and e >= 4 and e <= 7这个查询中有6个eq-prefix,分别为(1,4),(1,5),(1,6),(2,4),(2,5),(2,6)。
- distinct-prefix: 表示每一组A_1,…,A_k, C_1, B_1,…,B_m的值。其中A_1, …, A_k为eq-prefix,由谓语条件的等式部分决定;C_1由表中满足C_1列谓语条件的范围的记录组成;B_1,…,B_m的值由表中所有记录组成。
代价公式如下:
IO代价:读取每个index的IO代价 * 扫描的总行数(不是表的总行数)
CPU代价由三部分组成,分别为:
-
B+树的单次lookup代价 * distinct-prefix的总数:对应图中从上到下的绿色,红色和蓝色箭头的代价
-
index的比较代价 * 扫描的总行数:对应图中叶子节点表示的索引调用next指向下一个叶子节点的代价
-
filter算子的compare代价 * 扫描的总行数:Range-Prefix Skip Scan算子的上游为filter算子。filter算子会对Range-Prefix Skip Scan的输出再做一次compare操作,过滤掉Range-Prefix Skip Scan的不满足其他谓语条件的输出。
总结
在 MySQL 中,全表扫描、全索引扫描和范围索引扫描是三种常见的数据访问方式。范围索引扫描通常比全索引扫描更高效,而全索引扫描又比全表扫描更高效。然而,并不是所有索引列的范围条件都能有效利用范围扫描,特别是在复合索引的情况下。Skip Scan 和 Range-Prefix Skip Scan 是两种优化技术,可以在特定条件下提高查询性能。
Skip Scan 可以跳过复合索引的前几个keypart部分,对后面的keypart部分进行范围扫描。
Range-Prefix Skip Scan 可以同时对一个复合索引的两个范围列进行范围扫描,适用于更复杂的查询场景。