PostgreSQL · 一文搞懂PostgreSQL逻辑复制的全部原理
Author: 赵锐(惜元)
什么是逻辑复制?
一句话概括,逻辑复制是相对于物理复制的概念,物理复制是把对文件块的改动发送到下游,逻辑复制是把数据的改动(一般是修改前/修改后的行)发送到下游。
逻辑复制架构

逻辑复制的总架构,包含存量数据的复制、增量数据的复制。
图中 1~3 表示存量数据的复制过程。在CREATE SUBSCRIPTION时,可以请求全量的数据。发布端接收和回复COPY数据。
关键函数ApplyWorkerMain->start_table_sync->LogicalRepSyncTableStart->copy_table。
图中 4~10 表示增量数据的复制过程。在订阅端结束1~3后,或者断开后重新建连,都会经历这样的步骤。发布端使用walsender进程发送逻辑复制的数据。
关键函数ApplyWorkerMain->walrcv_startstreaming。
Publication
发布端创建,指定要发布什么给下游,目标是单个表或者一些表(指定shema下的表、所有表)。可以限制要发布什么行为:insert/update/delete/truncate,默认全部行为都发送。
CREATE PUBLICATION name
[ FOR ALL TABLES
| FOR publication_object [, ... ] ]
[ WITH ( publication_parameter [= value] [, ... ] ) ]
发布全部表(也包括新创建的表)
postgres=# CREATE PUBLICATION pub_alltables FOR ALL TABLES;
CREATE PUBLICATION
postgres=# SELECT * FROM pg_publication;
oid | pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate | pubviaroot
-------+---------------+----------+--------------+-----------+-----------+-----------+-------------+------------
16392 | pub_alltables | 10 | t | t | t | t | t | f
(1 row)
发布单个表
postgres=# CREATE PUBLICATION pub_employee FOR TABLE employee;
CREATE PUBLICATION
postgres=# SELECT oid, prpubid, prrelid::regclass FROM pg_publication_rel;
oid | prpubid | prrelid
-------+---------+----------
16407 | 16406 | employee
(1 row)
发布指定schema下的表(也包括新创建的表)
postgres=# CREATE PUBLICATION pub_sales_info FOR TABLES IN SCHEMA marketing, sales;
CREATE PUBLICATION
postgres=# SELECT oid, pnpubid, pnnspid::regnamespace FROM pg_publication_namespace;
oid | pnpubid | pnnspid
-------+---------+-----------
16410 | 16408 | marketing
16411 | 16408 | sales
(2 rows)
Subscription
订阅端创建,指定要对哪个或哪些publication发起订阅。
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
subscription_parameter:
create_slot:是否在源端创建logical replication slot
slot_name:使用源端已有的slot
binary:发布端直接以binary格式发送存量数据,无需转换成具体的类型。要求该数据类型必须定义send/receive函数。
copy_data:是否拷贝全量数据
streaming:默认为false:代表发布端解析到完整事务commit/abort后,才会发送到订阅端。
假如decode过程中,事务内存超过logical_decoding_work_mem配置,会存储在本地临时文件;
on: 代表发布端无需解析到完整事务,在内存超出logical_decoding_work_mem配置时,
选择最大的事务发送到订阅端(不管此事务是否提交),此事务称为stream事务。
订阅端将收到的内容存在本地临时文件,在收到commit或abort时,将事务提交或回滚。
parallel: 在streaming=on的基础上,订阅端会使用leader apply worker接收到内容,
再交由paralle apply worker或者leader apply worker自己apply。
synchronous_commit:与物理复制的synchronous_commit一样。
two_phase:二阶段提交事务的优化,无需等到commit再发送数据,在prepare阶段就可以发送。
origin:标识subscription的源头,下文双向逻辑复制会详解
postgres=# CREATE SUBSCRIPTION sub_alltables
CONNECTION 'dbname=postgres host=localhost port=5432'
PUBLICATION pub_alltables;
NOTICE: created replication slot "sub_alltables" on publisher
CREATE SUBSCRIPTION
postgres=# SELECT oid, subdbid, subname, subconninfo, subpublications FROM pg_subscription;
oid | subdbid | subname | subconninfo | subpublications
-------+---------+------------------+------------------------------------------+-----------------
16393 | 5 | sub_alltables | dbname=postgres host=localhost port=5432 | {pub_alltables}
(1 row)
每个publication可以有多个subscription,每个subscription也可以订阅多个publication。每个subscription都必须使用一个logical replication slot,主要用来记录订阅端复制的进度,也就是LSN。
postgres=# SELECT slot_name, plugin, type, datoid, database, temporary, active,
active_pid, restart_lsn, confrm_flush_lsn FROM pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | restart_lsn | confirmed_flush_lsn
---------------+----------+-----------+--------+----------+-----------+--------+------------+-------------+---------------------
sub_alltables | pgoutput | logical | 5 | postgres | f | t | 24473 | 0/1550900 | 0/1550938
(1 row)
订阅状态存储在pg_stat_subscription视图中。
postgres=# SELECT subid, subname, received_lsn FROM pg_stat_subscription;
subid | subname | received_lsn
-------+-----------------+----------------
16399 | sub_alltables | 0/1550938
(1 row)
逻辑复制流程解析
Replication launcher
Replication launcher是PG的background worker,PG启动后就常驻下来,这个进程会周期性检查pg_subscription表,并为每个订阅启动一个Apply worker。
xiyuan.zr 24438 /home/postgres/build/bin/postgres -D subscriber
xiyuan.zr 24439 postgres: checkpointer
xiyuan.zr 24440 postgres: background writer
xiyuan.zr 24442 postgres: walwriter
xiyuan.zr 24443 postgres: autovacuum launcher
xiyuan.zr 24444 postgres: logical replication launcher
xiyuan.zr 24472 postgres: logical replication apply worker for subscription 16399
此步骤对应文章初始架构图的第一步。
Apply worker
每个subscription对应一个Apply worker。Apply worker既负责启动Tablesync worker拷贝存量数据,又负责消费增量数据。

为什么每个Tablesync worker需要单独创建一个slot?为什么不复用发布订阅原始的slot呢?这两个问题后面揭晓。
此步骤对应文章初始架构图的第2步。
Tablesync worker
Tablesync worker是由Apply worker调度的,每个Tablesync worker都只负责唯一一个表的存量数据同步。
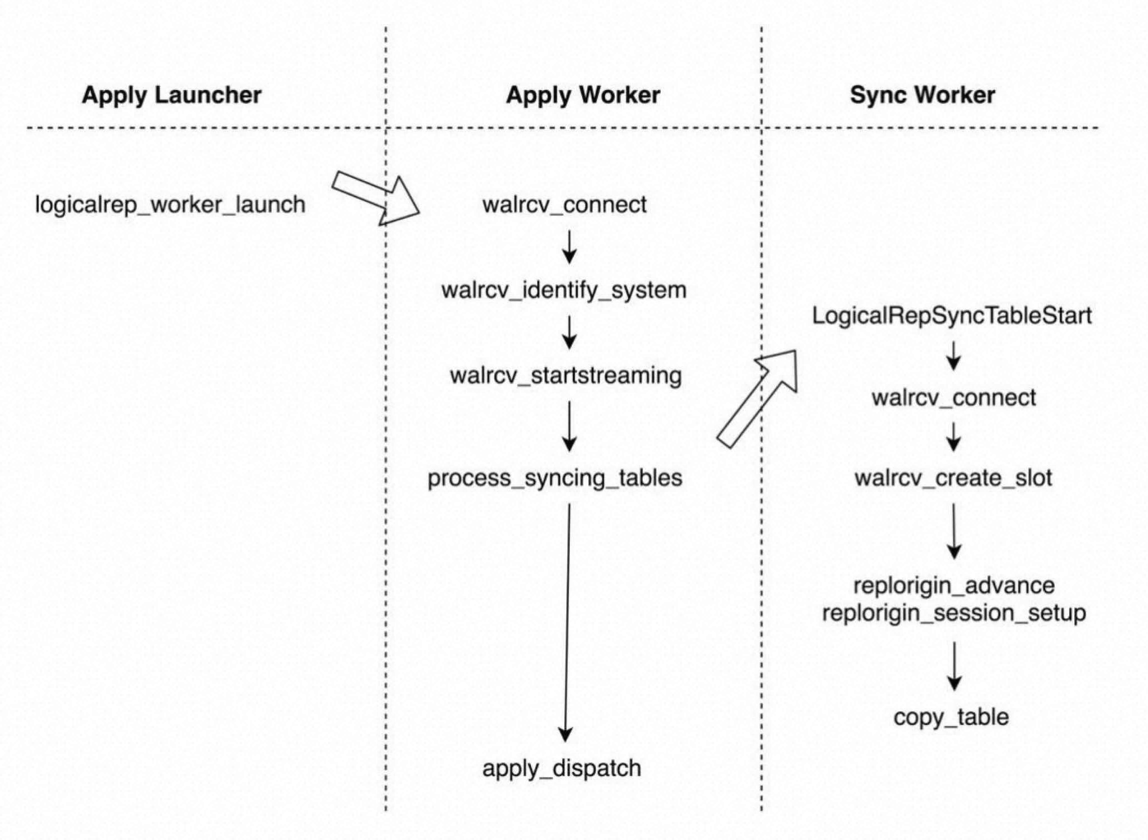
Tablesync worker和Apply worker整体工作流程如下图所示。这里我们简单地了解:Apply worker轮询所有未同步的表,启动Tablesync worker去同步,并促使Tablesync worker经过7个状态。详细的工作流程我们往下看。
对应文章初始架构图里的第3步。

数据复制流程
上图只说明了Tablesync worker的状态轮换,下面会详细解读全量数据和增量数据的复制流程。
- 每个Tablesync worker都会为表创建一个slot(下图的copy slot),加上subscription对应的slot,所有slot按LSN递增的顺序,如下图所示:
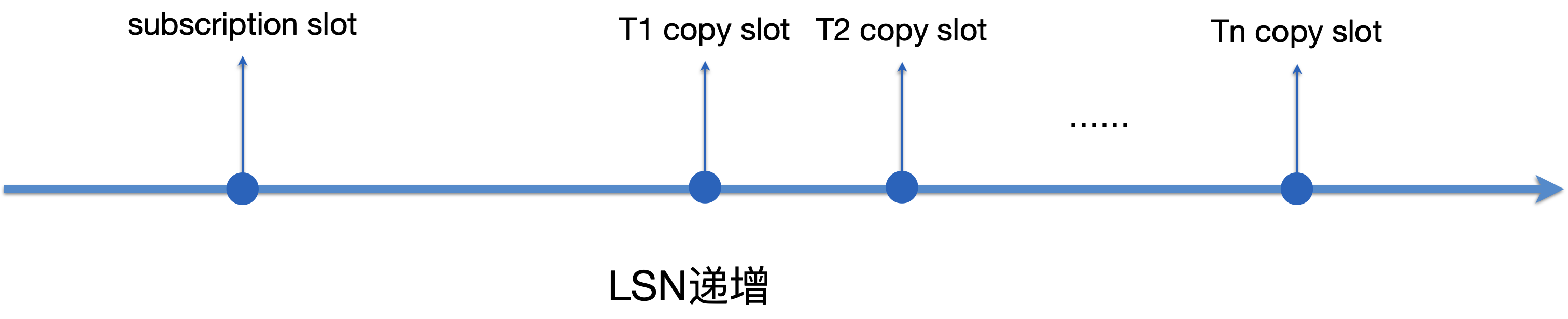
-
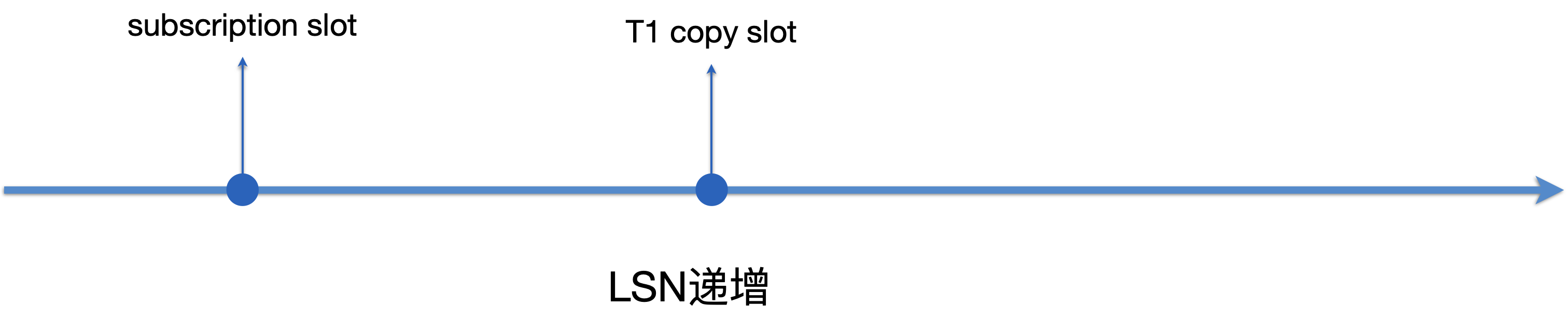
我们以T1 copy slot为例,讲解Table sync worker工作的全流程。Table sync worker会做以下几个事情:
-
开启repeatable read事务,状态更新为STATE_INIT。
-
创建logical replication slot(即下图的T1 copy slot),参数传递USE_SNAPSHOT,该参数的含义为当slot到达SNAPBUILD_CONSISTENT状态后,会产生一个snapshot,此快照被设置为当前事务的快照。
-
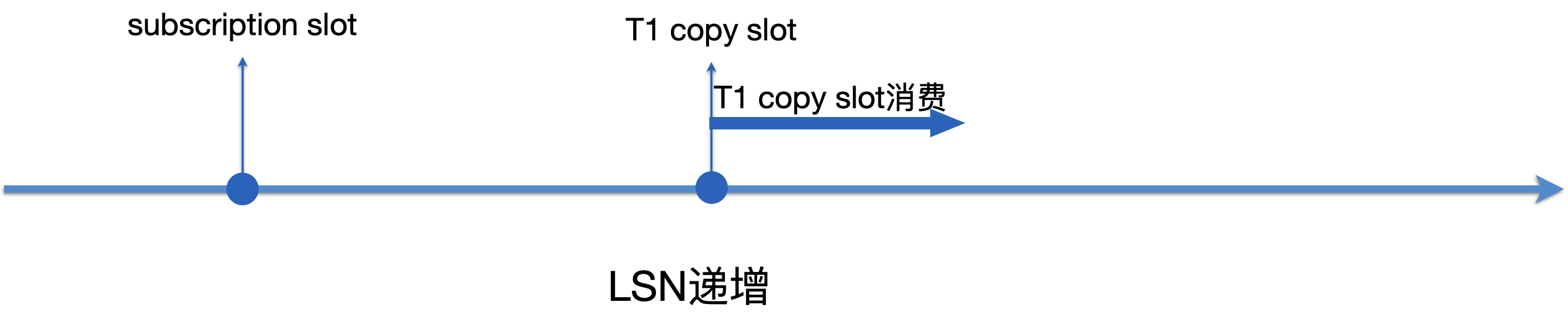
libpq执行COPY TO STDOUT,本地通过CopyFrom函数接收copy存量数据,状态更新为STATE_DATASYNC。
-
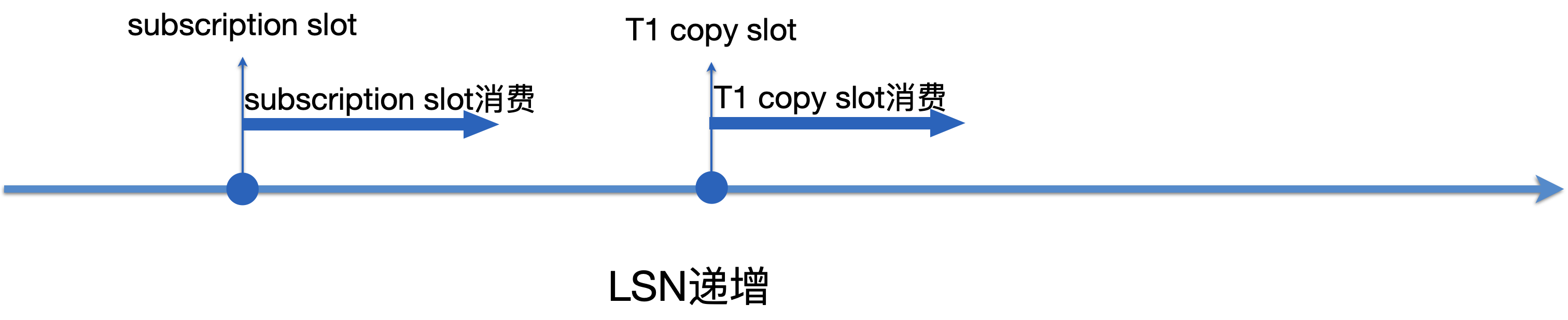
- 存量数据copy结束后,状态更新为STATE_FINISHEDCOPY(持久化),再更新为STATE_SYNCWAIT(共享内存)。Tablesync worker也不会立刻退出,而是继续消费T1 copy slot的数据,通过函数process_syncing_tables做到只回放T1的数据。每处理完一条消息就会进入状态推进函数process_syncing_tables,如果到达一定状态即退出。具体满足什么状态请见5a。
- 同时Apply worker也没有一直等待Tablesync worker,Apply worker也一直在正常回放数据,通过函数should_apply_changes_for_rel决定哪些数据要被回放,哪些要被忽略,只有存量数据同步结束的表的数据才会回放。同样每处理完一条消息也进入状态推进函数process_syncing_tables。
-
所以Apply worker和Tablesync worker孰快孰慢,存在两种情况:
-
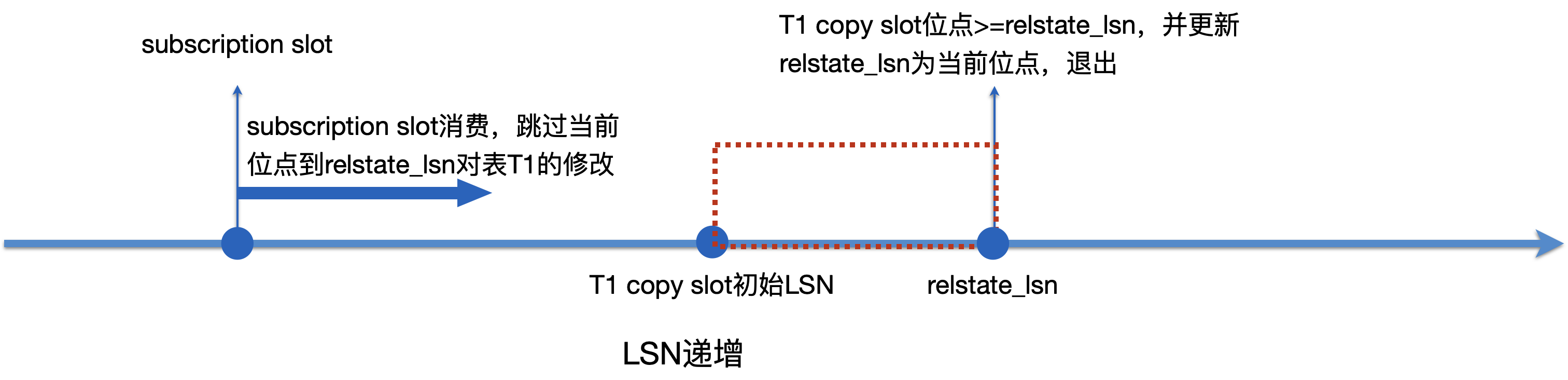
Apply worker消费subscription slot,没有超过T1 copy slot初始LSN。
-
Apply worker检查到T1同步状态为STATE_SYNCWAIT,把T1 copy slot的当前位点设置为其结束位点relstate_lsn,并同步等待Tablesync worker结束。
-
Tablesync Worker进入到状态推进函数后,判断当前的位点>=relstate_lsn时就退出,并更新relstate_lsn为当前位点。
-
Apply worker回放时会跳过从当前位置到relstate_lsn之间对表T1的修改。
-
-
-
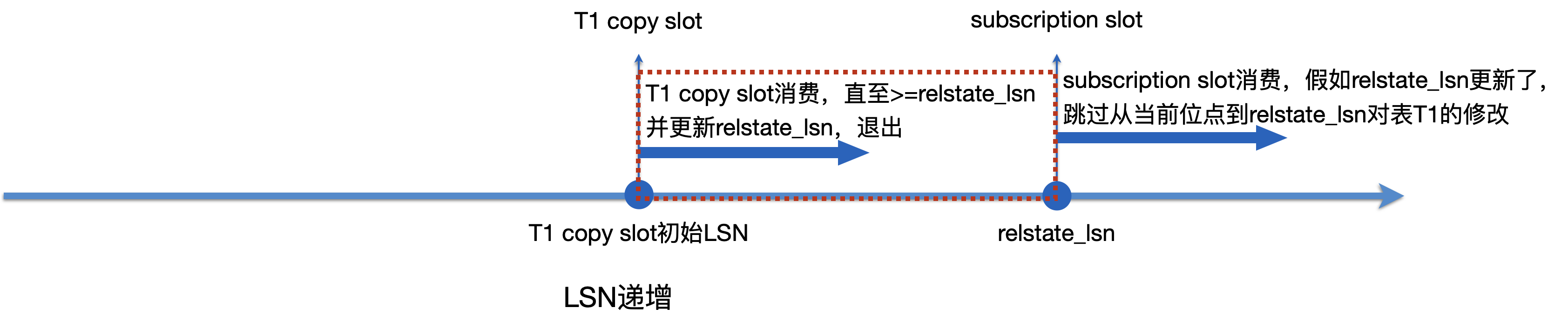
Apply worker消费subscription slot,超过了T1 copy slot初始LSN。
-
Apply worker检查到T1同步状态为STATE_SYNCWAIT,把Apply worker的当前位点设置为T1 copy slot的结束位点relstate_lsn,并同步等待Tablesync worker结束。
-
Tablesync Worker进入到状态推进函数后,判断当前的位点>=relstate_lsn时就退出,并更新relstate_lsn为当前位点。
-
Apply worker回放时会跳过从当前位置到relstate_lsn之间对表T1的修改。
-
在这个过程中,假如Tablesync worker中途遇到错误,比如copy下游遇到了主键冲突,Tablesync worker会退出,交由Apply worker重新启动新的Tablesync worker,并重新开始同步存量数据。只有当状态到达STATE_FINISHEDCOPY,才不用重新开始同步。
代码路径:ApplyWorkerMain->start_table_sync->LogicalRepSyncTableStart
->start_apply->LogicalRepApplyLoop->process_syncing_tables->process_syncing_tables_for_sync
回到上面的两个问题。
问题一:为什么每个Tablesync worker需要单独创建一个slot?为了拿到snapshot做快照读。
问题二:为什么不复用发布订阅原始的slot呢?subscription slot和copy slot都可以一起消费,互不阻塞,加快了消费进度,减少了源端堆积WAL的概率。
Replication launcher、Apply worker、Tablesync worker
如何逻辑解码(从WAL到数据)
逻辑解码整体流程
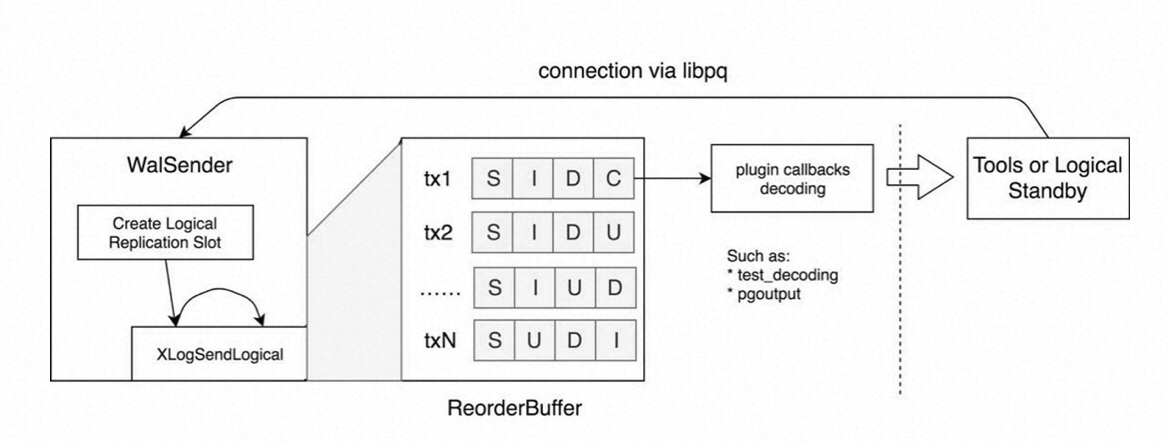
所有逻辑解码流程发生在Walsender进程中,Walsender进程读取WAL,使用rmgr模块解析,解析好后放入内存中的ReorderBuffer,在每次解析到commit/abort时,将对应的事务通过预先设定的plugin逻辑解析和输出(当subscription的streaming选项设成on或parallel,无需等到commit)。
下图事务tx中的S、I、D、C等代表逻辑解码时不同的动作,S代表事务开始,C代表事务提交,只有提交的事务才有可能发送到下游。
PG里目前支持以下几种类型SQL的逻辑解码,分别从Walsender和Apply worker的视角来讲述逻辑解码的具体步骤,对应文章初始架构图里的第9步。

Snapshot Builder
slot刚创建好时,是不能直接给下游消费的,需要由Snapshot Builder模块建立到一个SNAPBUILD_CONSISTENT的状态。为什么呢?
首先说明一点,开启逻辑复制后(wal_level = logical),WAL中会多记录一些信息,UPDATE SQL会记录old tuple和new tuple,DELETE SQL会记录old tuple,只是都以二进制形式存储,需要元数据做基础,才能解析出来。如果没有系统表做元数据,是无法从二进制中反解出逻辑修改的。因此,逻辑解码的过程中要访问系统表,就需要先构建访问系统表的事务快照,然后带着快照去读系统表。注意:快照是持久化到磁盘的。
而快照的构建是需要一定条件的,下面的四个状态记录了构建快照的流程:
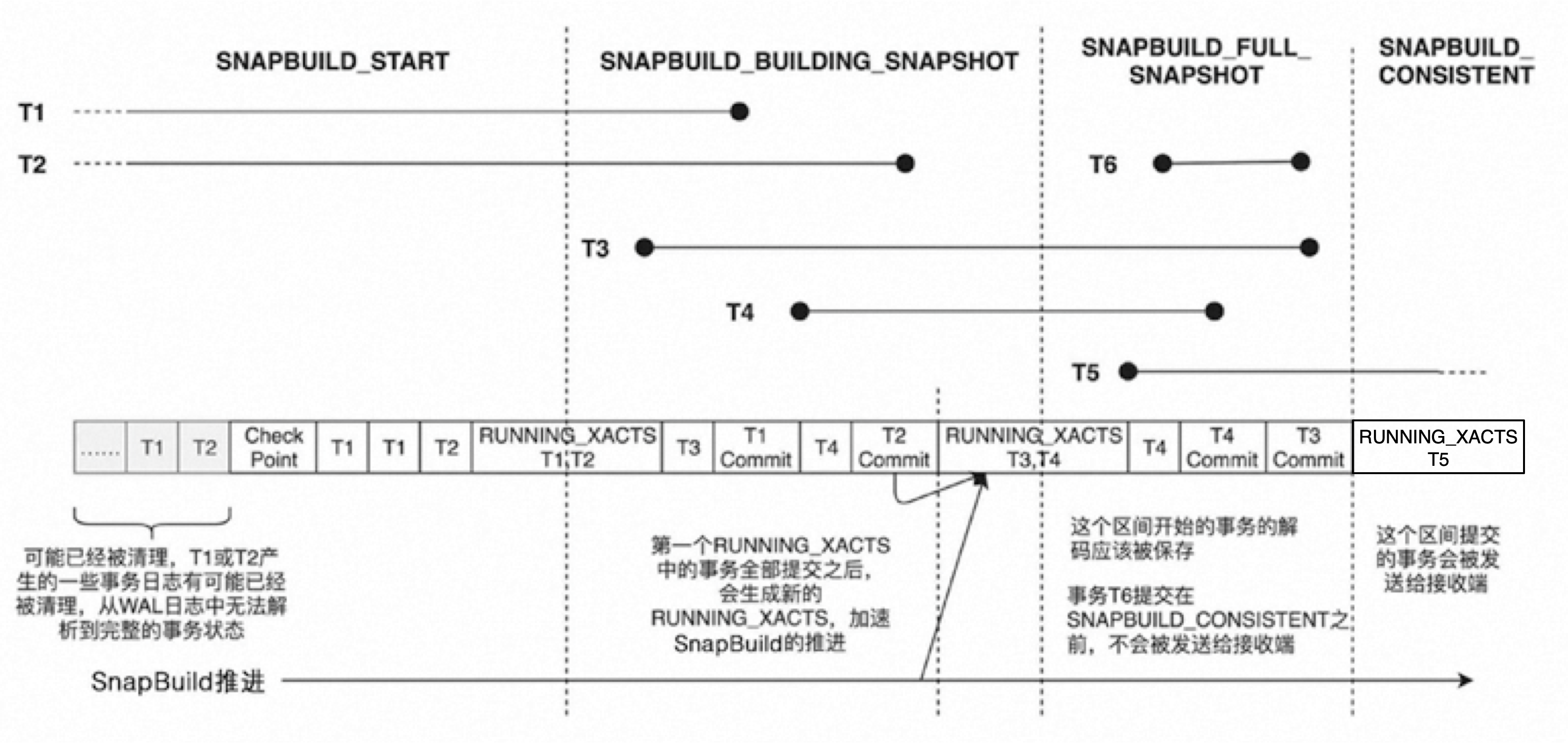
-
初始状态:SNAPBUILD_START
-
从第一条RUNNING_XACTS的WAL1开始,进入到第二状态:SNAPBUILD_BUILDING_SNAPSHOT。等待WAL1前正在运行的事务全部结束,打RUNNING_XACTS的WAL2。
-
从第二条RUNNING_XACTS的WAL2开始,同时满足上一步的nextXid <= RUNNING_XACTS.oldestRunningXid,进入到第三状态:SNAPBUILD_FULL_SNAPSHOT。此时WAL1前正在运行的事务全部结束,WAL2只有WAL1到WAL2新增的事务,所以此时包含所有正在运行事务的完整状态。从这一点开始解析所有的WAL,但不发送。等待WAL2前正在运行的事务全部结束,打RUNNING_XACTS的WAL3。
-
从第三条RUNNING_XACTS的WAL3开始,同时满足上一步的nextXid <= RUNNING_XACTS.oldestRunningXid,进入到第四状态:SNAPBUILD_CONSISTENT。第二条RUNNING_XACTS的WAL2前的事务全部结束,此时能拿到所有对系统表的修改。所有提交的事务会开始发送。
特殊情况:上图每次遇到RUNNING_XACTS的WAL,假如不包含正在运行的事务,直接进入第四状态。
上面Tablesync worker创建replication slot时携带CRS_USE_SNAPSHOT标志,也会经过上面图中的过程,直到SNAPBUILD_CONSISTENT状态,生成事务快照。之后的COPY都是在该事务快照下进行的。这里还有个细节:SNAPBUILD_CONSISTENT状态拿到的快照是系统表快照,{xmin;xips;xmax}中xips记录的是修改系统表的xid,在PG里叫做SNAPSHOT_HISTORIC_MVCC,与正常MVCC的快照不同,PG内部还会做一次快照转换。
逻辑解码的断点续传
初始状态,创建replication slot
Walsender从最新的LSN开始读WAL,直至构建好一个一致性快照,才可以对下游进行发送。
下游断连后重新消费,上游从哪里开始decode?
slot中保存了一个重要的位点restart_lsn,代表此大于此LSN的WAL不允许删除。上文讲到每次SNAPBUILD_CONSISTENT状态时会生成一个快照,此时对应的位点就可能成为restart_lsn,换句话说,每个restart_lsn都必然会在磁盘上有一个快照。每次断连重新消费时,Walsender从restart_lsn开始读,加载磁盘上存储的restart_lsn对应的事务快照,才可以开始消费。
restart_lsn的更新:在每次解码RUNNING_XACTS类型的WAL时,如果到达了SNAPBUILD_CONSISTENT状态,此时的LSN可以更新为candidate_restart_lsn。如果下游上报的confirmed_flush_lsn大于candidate_restart_lsn,此时把restart_lsn更新为candidate_restart_lsn。所以DTS等下游一定要及时上报confirmed_flush_lsn。
postgres=> select * from pg_replication_slots ;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase
-----------+----------+-----------+---------+----------+-----------+--------+------------+------+--------------+--------------+---------------------+------------+---------------+-----------
myslot | pgoutput | logical | 1882379 | postgres | f | f | | | 586571653 | 97B/B60002A0 | 97B/B60002D8 | reserved | | f
(1 row)
下游断连后重新消费,上游从哪里开始往下游发送?
下游建连时会可以携带startpoint,上游从restart_lsn开始decode,直至超过startpoint,才可以往下游消费。这样就避免了下游消费同样的内容。当下游不携带startpoint,或者携带的startpoint比slot记录的confirmed_flush小时,都使用confirmed_flush作为开始发送的LSN。
下游携带的startpoint,是在下游的pg_logical/replorigin_checkpoint记录的remote_lsn字段,每当下游事务提交时,会通过replorigin_session_advance推进remote_lsn。
双向逻辑复制
双向逻辑复制里,最重要的问题是循环消费。PG使用replication origin解决,使用方式:
CREATE SUBSCRIPTION subscription_name
CONNECTION 'conninfo'
PUBLICATION publication_name [, ...]
[ WITH ( subscription_parameter [= value] [, ... ] ) ]
subscription_parameter:
origin:
默认为any:publication会发送所有数据;
none: publication只发送不带origin标识的数据
注:上面的存量数据的同步阶段,是不受origin影响的。即使有数据来自其他origin也没办法过滤,下游消费时会有warning日志。
增量同步阶段,如何解决循环消费?
PG1->PG2的链路:PG2 create subscription时使用replorigin_create()创建origin,后面从PG1消费的数据,写WAL时都会带着origin=PG1标识。
PG2->PG1的链路:PG2发送数据时,会过滤掉origin=PG1的WAL。
反之,PG1发送数据时,也会过滤掉origin=PG2的WAL。
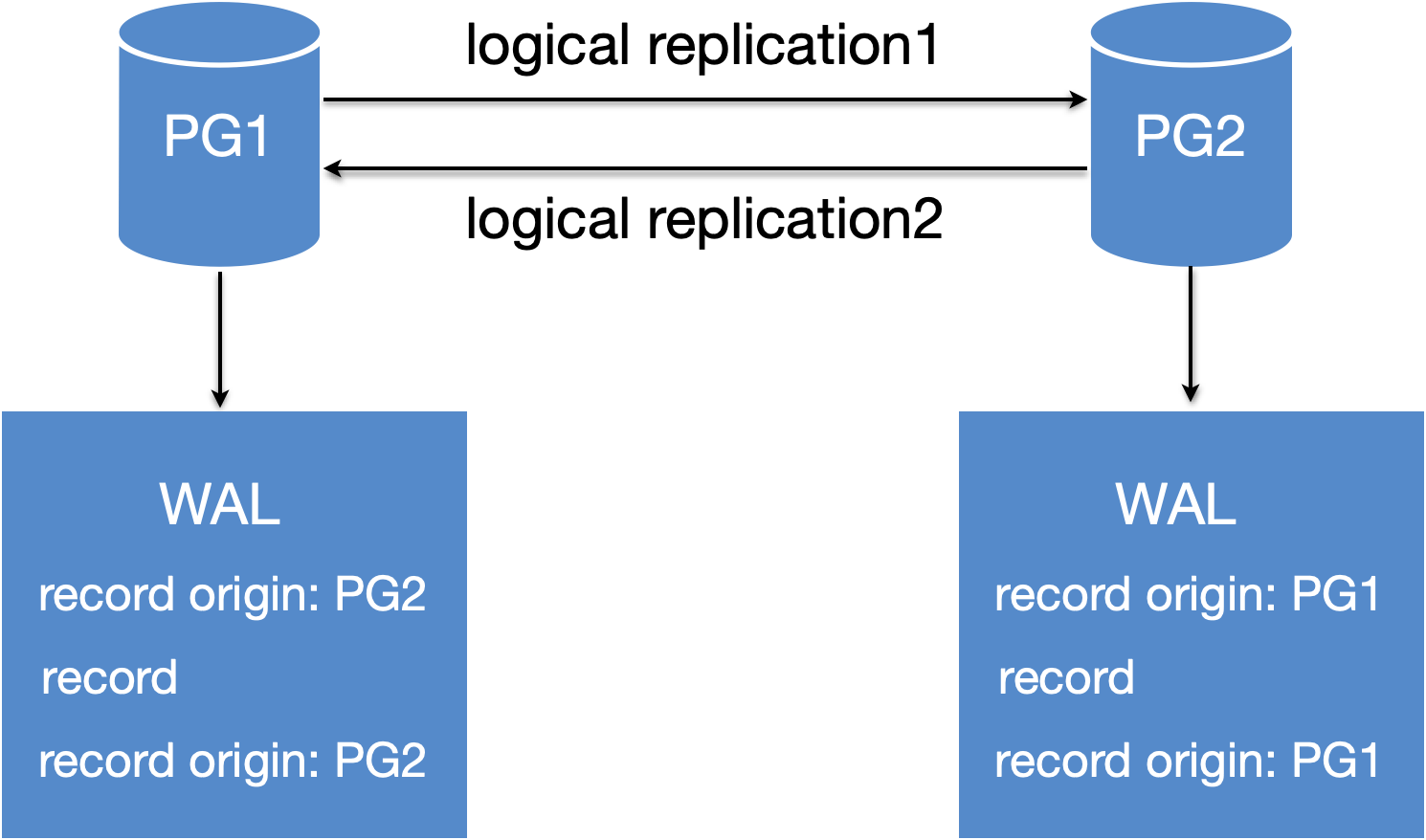
但这种架构只解决了循环消费的问题,主键冲突、自增ID等问题依然存在。
逻辑复制冲突及解决办法
典型的逻辑复制冲突如下,订阅端在回放时遇到主键冲突,Apply worker会退出,Replication launcher会重新启动Apply worker,如此反复。
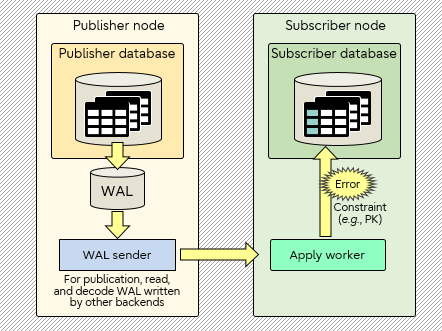
常用解决办法:
-
CREATE SUBSCRIPTION时设置disable_on_error=true,代表遇到错误就暂时终止订阅;
-
从订阅端获取日志:CONTEXT: processing remote data for replication origin ”pg_16389” during ”INSERT” for replication target relation ”public.tab” in transaction 730 finished at 0/1566D10,并执行ALTER SUBSCRIPTION xxx DISABLE。
发布端使用pg_replication_origin_advance(‘slot_name’, ’0/1566D11’)。
订阅端执行ALTER SUBSCRIPTION xxx ENABLE。
- ALTER SUBSCRIPTION xxx SKIP LSN ’0/1566D10’,skip有冲突的LSN。(PG15及以上)
备库创建逻辑复制
从使用方式解释实现原理
-
设置参数hot_standby_feedback = on
-
主备的物理复制推荐使用physical replication slot(可选)
-
create subscription。如果需要等待,可以调用一次或多次pg_log_standby_snapshot()(可选)
实现原理
为什么设置hot_standby_feedback参数
原因
一句话概括,备库的快照读所需要的tuple,在主库上可以被vacuum物理删除,备库周期性通知主库,哪些tuple不可以删除。
详细解释
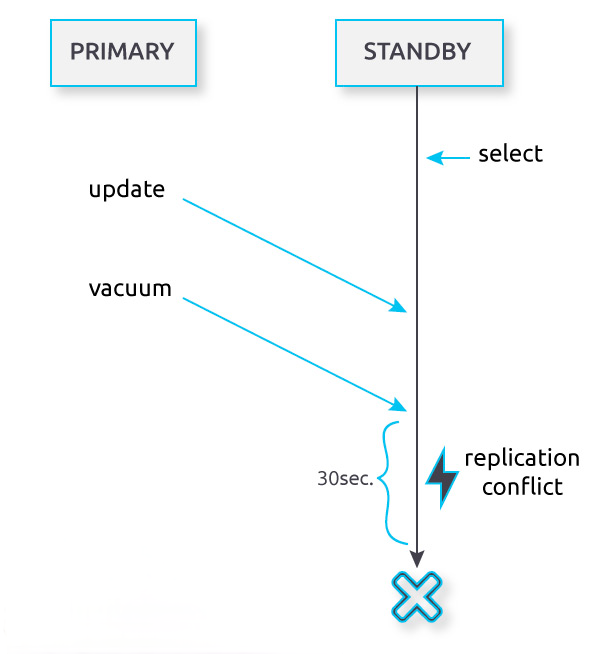
下图是一个只读实例的例子。
hot_standby_feedback=off时,standby上的只读事务,在standby回放主库上的vacuum WAL遇到冲突时,默认会等待max_standby_streaming_delay=30s的时间。30s后standby上的select就会报错ERROR: canceling statement due to conflict with recovery。
hot_standby_feedback=on时,备库定时上报需要保留的xmin和catalog_xmin,主库vacuum时就会保留>=xmin和>=catalog_xmin的tuple。
逻辑复制也是同理,主库需要保留一些系统表的tuple。为什么是系统表,下文会有解释。
代码路径:
备库上报:WalReceiverMain->XLogWalRcvSendHSFeedback
备库回放与只读事务冲突:heap_redo/xxx_redo->ResolveRecoveryConflictWithSnapshot->ResolveRecoveryConflictWithVirtualXIDs->VirtualXactLock
备库回放与逻辑复制冲突:heap_redo/xxx_redo->ResolveRecoveryConflictWithSnapshot->InvalidateObsoleteReplicationSlots
为什么推荐physical replication slot?
原因
主备连接断开后,之前上报的xmin和catalog_xmin会清空,主库就不会保留备库需要的tuple。
详细解释
-
没有使用physical replication slot时,备库反馈的xmin和catalog_xmin是只存储在MyProc本地内存和ProcGlobal全局内存中。主备因网络等原因断连后,主库的walsender进程退出,walsender本地内存销毁、ProcGlobal关于此进程的信息也销毁,xmin和catalog_xmin不复存在,主库就可以删除备库需要的tuple。备库重连后,备库再使用logical replication slot消费,会因为拿不到系统表元信息,逻辑解析失败,无法向下游发送。此时备库只能kill掉下游消费连接、drop logical replication slot。
-
使用physical replication slot时,备库反馈的xmin和catalog_xmin也存储在replication slot中,在ReplicationSlotCtl全局内存中,也持久化到了磁盘,不受进程退出影响,不会丢失。
代码路径:
主库接收备库上报,存储到physical replication slot:WalSndLoop->ProcessRepliesIfAny->ProcessStandbyMessage->ProcessStandbyHSFeedbackMessage->PhysicalReplicationSlotNewXmin
为什么需要pg_log_standby_snapshot()?
原因
上文的Snapshot Builder章节里讲过,slot自创建开始,需要先构建快照,经历4个步骤,最终到达一致性状态才能对下游发送数据。
快照的构建过程是要不断逻辑解析RUNNING_XACTS类型的WAL,备库要想进行逻辑复制,需要主库产生RUNNING_XACTS类型的WAL,所以需要一次或多次pg_log_standby_snapshot()。
逻辑复制并行回放
为什么要做这个功能?
逻辑订阅在大事务下,只能在事务提交后,subscriber才能回放。为了解决大事务回放慢的问题,有了这个功能。
实现难点
死锁问题(下文会解释)
从使用方式解释实现原理
CREATE SUBSCRIPTION test_sub
CONNECTION 'host=127.0.0.1 dbname=postgres port=5432'
PUBLICATION pub
WITH (streaming=parallel);
实现原理
streaming参数
streaming = enum{off, on, parallel}
默认为false:代表发布端解析到完整事务后,才会发送到订阅端。假如解析过程中,内存超过logical_decoding_work_mem配置,会存在在本地临时文件;
等于on:代表发布端无需解析到完整事务,在内存超出logical_decoding_work_mem配置时,选择最大的事务发送到订阅端(不管此事务是否提交),此事务称为stream事务。订阅端将收到的内容存在本地临时文件,在收到commit或abort时,将事务提交或回滚。
等于parallel:在streaming=on的基础上,订阅端会使用leader apply worker接收stream事务,再交由parallel apply worker或者自己进行apply。
parallel apply原理
leader apply worker,以下简称LA。
parallel apply worker,以下简称PA。
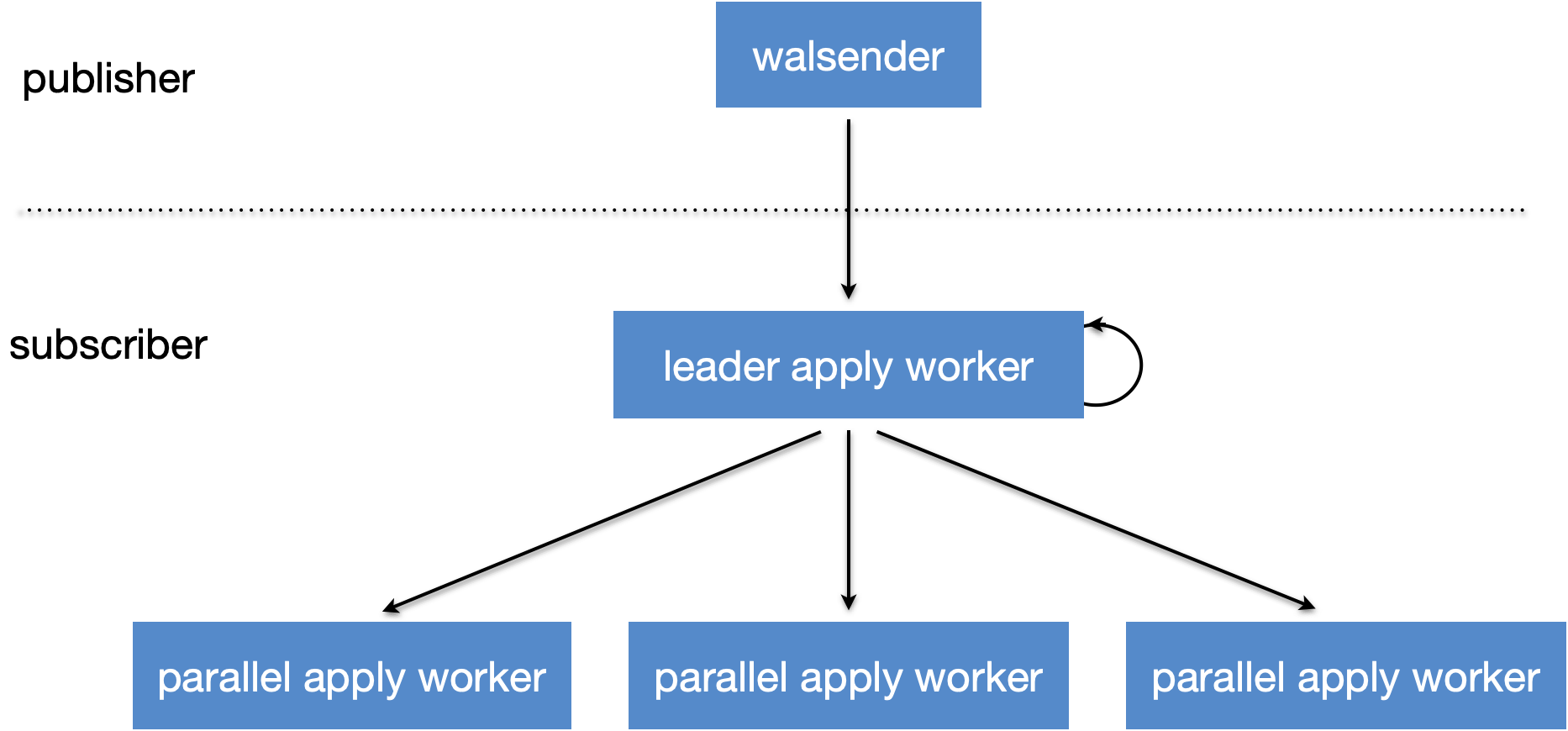
代码路径:ApplyLauncherMain->logicalrep_worker_launch->ParallelApplyWorkerMain->LogicalParallelApplyLoop->apply_dispatch->pa_allocate_worker->pa_launch_parallel_worker->logicalrep_worker_launch
parallel apply只针对stream事务:
-
非stream事务都在LA直接执行;
-
stream事务的数据包分为stream_start、insert/update/delete/truncate、stream_stop、stream_commit/stream_abort,会经过以下流程:
-
当包为stream start时,代表事务中的一个stream的开始。LA接收后,会选择一个空闲PA。假如没有空闲,就申请一个新的PA。假如申请失败(超过上限等原因),LA就把数据保存到临时文件中。
-
当包为insert/update/delete/truncate时,代表正常的数据包。LA接收后,假如#a成功选择到了PA,就转发到PA执行。假如#a没有成功选择,LA就把数据保存到临时文件中。
-
当包为stream_stop时,代表事务中的一个stream的结束。LA接收后,假如#a成功选择到了PA,就转发到PA执行。假如#a没有成功选择,LA就把数据保存到临时文件中。
-
当包为stream_commit/stream_abort时,代表事务要提交/回滚。LA接收后,假如#a成功选择到了PA,就转发到PA执行。假如#a没有成功选择,LA会执行此事务。
-
如何解决事务依赖问题
上述的d过程,当包为stream_commit/stream_abort时:
-
假如事务在PA里运行,LA会转发到PA,同步等待PA执行成功。
-
假如事务在LA里运行,LA会在本进程做事务提交。
通过以上方式,保证事务的提交序,就不会产生事务依赖问题。
思考:只保证提交序,真的不会有事务依赖问题吗?
如下例子:


逻辑复制传输的不是SQL,而是修改的行的原值和目标值!如果没有匹配到原值,就直接跳过。
如何解决死锁问题
保证提交序后,逻辑复制本应没有死锁问题了。
但订阅者与发布者的表结构可能不一样,死锁会发生在订阅者新加的唯一性约束上。例如下面例子:
publisher上name列没有唯一约束:

subscriber上name列存在唯一约束:

LA和PA之间存在死锁关系,但PA等待LA的锁不存在,无法做死锁检测。
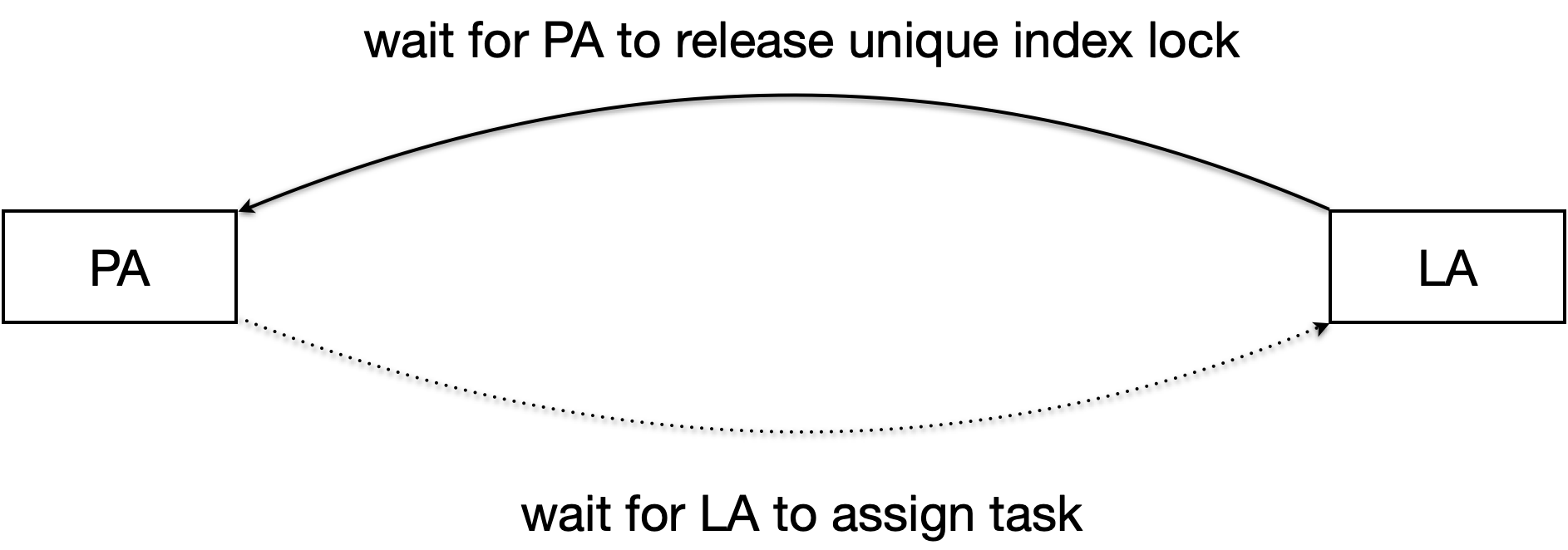
解决办法:逻辑复制新加了LA与PA之间的锁,复用PG的LockAcquireExtended锁机制,实现死锁的自动检测。
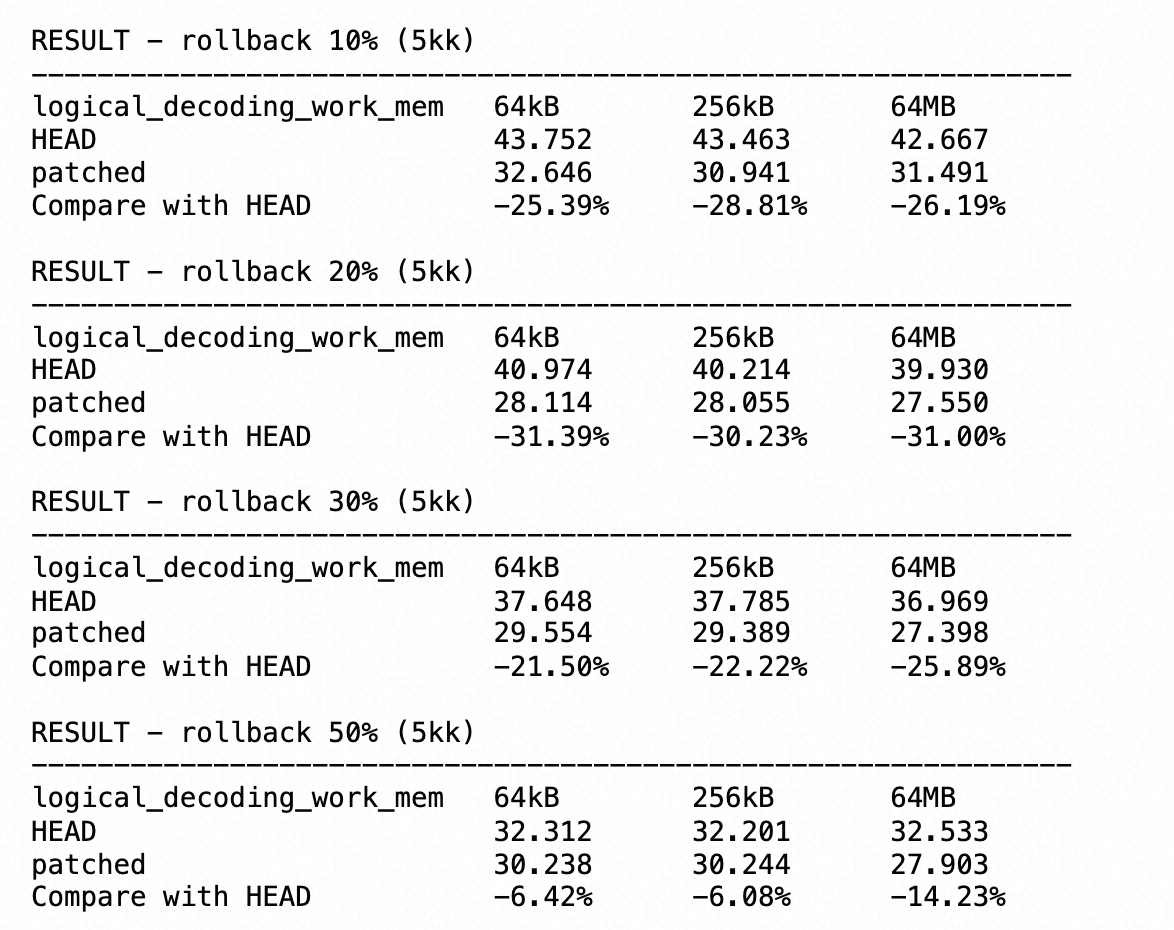
性能提升
参考社区测试结果:按照不同测试集和参数配置,bulk insert有30%+的性能提升,子事务有6%~31%的性能提升。

使用限制
逻辑复制建立在一个发布、订阅的模型下,发布端是PG,订阅端可以是PG、JDBC客户端、其他应用。此功能只限制在订阅端是PG。
逻辑复制限制
-
不复制DDL(发布端和订阅端的表结构不要求相同)。
-
sequence不会复制。
-
订阅端回放truncate操作时,只会影响在发布集合中的表,非发布集合里的表不会外键关联删除。
-
大对象不会被复制(lo对象有自己的存储文件)。
-
逻辑复制的对象只针对表、分区表,其他对象都不行:视图、物化视图、FDW表。
-
当订阅分区表时,发布端发送时默认以子表形式发送,可以通过publish_via_partition_root指定发布时以父表形式发送。
物理复制 vs 逻辑复制
| 物理复制 | 逻辑复制 | |
|---|---|---|
| 实现方式 | 基于redo的文件块级别复制,物理复制的主备库文件一模一样 | 基于数据的改动,包含原值和修改后的值,类似于MySQL的binlog。 |
| 粒度 | 整个实例 | 最小粒度为表,最大粒度为单个数据库 |
| 兼容性 | 不同大版本间无法兼容 | 不同大版本间兼容 |
| 事务影响 | 无需等待事务提交 | 需要等待事务提交,streaming=off在发布端等待,streaming=on/parallel在订阅端等待。 |
| 下游的查询受上游影响 | 备库需要查询的旧版本数据被主库删除后,回放会延时 | 不受影响,上下游完全独立(synchronous_commit>=remote_write除外)。 |
Reference
-
《PostgreSQL 技术内幕——事务处理深度搜索》