PolarDB 基于共享存储的 Binlog 一写多读
Author: 煜溟
在基于共享存储的 PolarDB 一写多读架构中,只读节点(RO)具备完整的 Binlog 获取能力,实现了计算节点的功能隔离,显著提升了读带宽的上限。
因跨部门业务隔离、权限控制及性能考量,许多大型客户选择创建独立 RO 节点,并赋予大数据团队该节点的只读权限,用于通过 CDC(Change Data Capture)同步数据至分析系统。这一实践已成为客户接入 MySQL 生态下游的最佳路径,同类共享存储架构的 MySQL 数据库产品(如 Aurora)则不支持这个功能,而传统主从节点独立部署的 MySQL 从库不具备 binlog 位点的一致性,缺少计算节点间无缝切换和负载均衡的能力。
早期版本中,PolarDB 仅主节点(RW)支持 Binlog Dump 功能,RO 节点因共享存储的分布式锁问题禁用 Binlog 操作。本文介绍如何在共享存储上设计 Binlog 多点读取能力,挑战在于协调共享文件的读写冲突。
通信协议
为了从 RO 上获取 Binlog,需要知道 Binlog 的基本信息,在 RO 上维护本地的 Binlog Index File。首次执行创建 IO 线程时,RO 会创建该文件;若 RO 升级为 RW 节点,该文件将被自动删除。
当 Binlog Dump 请求到达 RO 时,系统首先通过本地 Index File 定位起始文件名,并从共享存储读取实际 Binlog 文件。可读取的文件范围由 Index File 中的条目及内存变量 atomic_binlog_end_pos(记录当前 Binlog 写入末尾)共同限制。
为确保 RO 的 Index File 和 atomic_binlog_end_pos 始终同步,RW 节点通过独立的通信链路周期性向 RO 发送包含最新 Binlog End Position 的数据包。RO 收到后仅更新内存中的 atomic_binlog_end_pos,避免直接修改本地文件。
此设计确保 RW 发过来的 end pos 始终是完整 event 的结尾,避免了从 RO 上读取的 binlog event 数据截断。
purge 问题
RO 节点可能存在活跃的用户 Dump 线程正在读取 Binlog 文件,但 RW 节点无法感知这一状态,导致误删文件。例如:
RW的 Dump 线程已读至第 4 个 Binlog 文件,此时 RW 可能回收前 3 个文件(如下图)。但若 RO 节点仍在读取第 2 或 3 个文件,回收将引发读取失败。
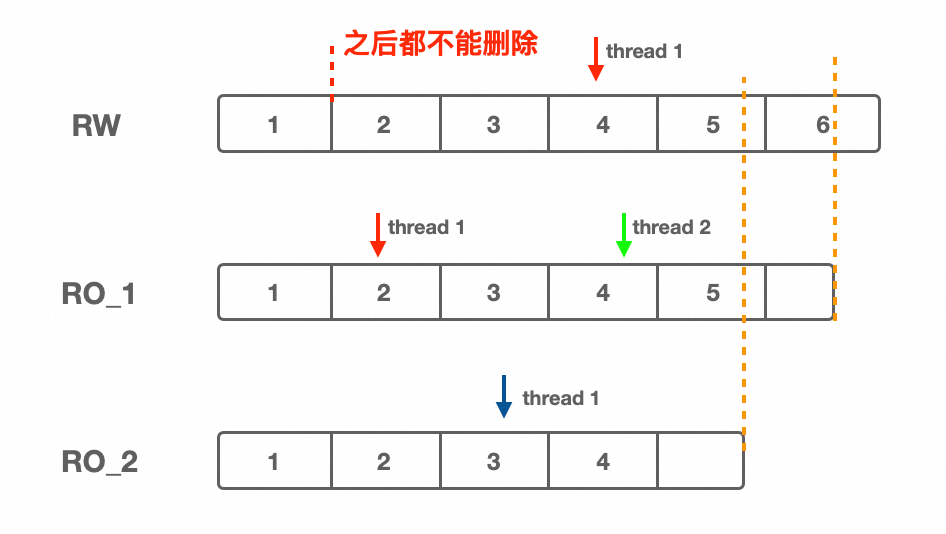
为了解决这个问题,RW 需要知道每个 RO 节点当前有哪些在使用的 Binlog 文件号。简化一下,就是 RO 只需要通知 RW 所有用户线程最早在使用哪个 binlog。通信时刻有两个:一个是有用户 dump 线程注册时,另外就是 RO 周期性给 RW 发包。这样,RW 上 purge limit 的位点由 RO 的回包来推进,在 purge 时除了要检查 thd->current_linfo,还需要检查 thd->slave_first_log_in_use。
当一个用户 dump 线程从 RO 本地 index 中拿到 binlog filename,准备开始读取之前,要发送一个 packet 去 RW 上查询这个 Binlog 是否还在,如果存在就在 RW 上标记一下并返回成功,然后 RW 就不能 purge 这个文件。
乱序风险
RO 给 RW 发包实际分为两个阶段,先遍历所有dump 线程找到最小的在访问的 binlog 文件编号,第二步是给 RW 发包。在发网络包时,RO 不应该持有任何锁,否则万一网络有问题,可能会导致 RO hang 住。
在第二步发包时如果不持有锁,可能会导致一种乱序的情况。
下图中这个例子:T1 和 T2 都是 RO 上的用户 dump 线程
理想情况是 T1->T2 或 T2->T1 执行顺序,线程之间是串行的:
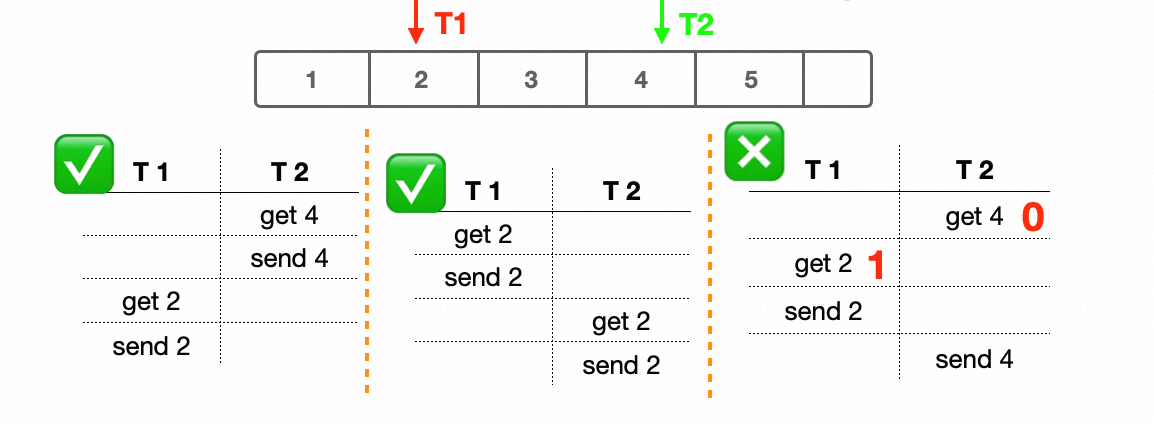
例如 T1->T2 的执行顺序:T1 先启动,从2开始读,T2后启动,从4开始读
T1 拿到了当前最早使用的 Binlog ,也就是 2,然后发送 2 给RW
这之后 T2 才启动,拿到的还是 2,不是 4(因为拿的是 RO 上被使用的最小的 Binlog) ,然后发送 2 给 RW
RW 上 purge 的位点一直是 2,不会造成问题。
乱序情况是什么?
T2 先启动拿到 4,但是发包有延迟,一直等到 T1 发包之后:也就是 T1 已经告诉 RW 从 2 开始读,T2 才发送包并且发送的是 4,显然这个 4 已经是这个 RO 很久之前的状态了。
RW 收到 T2 的包,就错误地推进了 purge 的位点到 4,这样会导致 Purge 决策错误。此时 RW 如果把 2 3 删掉了,T1 就读不到了,
逻辑时钟
在分布式系统中可以使用 Lamport clock 为事件定序,核心思想是为每个事件分配一个单调递增的 logical clock,需要满足局部顺序性和因果顺序性。
我们实现一个 logical clock,RO 节点每个 Dump 线程在获取活跃 Binlog 文件时,原子性递增本地的 psn(Packet Sequence Number),因此 psn 在进程内具有局部顺序性。在发送 packet 给 RW 节点时,将当前时钟 psn 附加在 packet 中。
RW 每次收到包时,不直接更新 purge 位点,先检查这个包的 psn 是否比之前的大,也就是检查包的时序。RW 仅处理 psn 递增的请求,忽略旧版本包,确保 Purge 决策基于 RO 的最新状态。
总结
PolarDB 主要通过以下机制实现了共享存储的 Binlog 多点读取:
- 通信协议:RO 维护本地状态,RW 主动同步关键元数据。
- Purge 协调:结合 RO 通报的活跃文件最小值,扩展 Purge 决策逻辑。
- 时钟同步:利用逻辑时钟解决分布式环境下的时序混乱问题。
这一设计充分利用了共享存储架构的优势,为复杂业务场景提供了灵活的逻辑日志扩展能力。