PolarDB B-tree 并发控制技术演进
Author: 煜溟
作为一款先进的云原生数据库,PolarDB 通过存算分离架构突破传统数据库性能边界的同时,也不断地在索引高并发优化技术上深耕,推出了 PolarIndex 一系列索引优化特性:B-tree 细粒度并发控制、轻量化索引压缩、溢出页预分配等,相关技术参考这篇月报的介绍: 再演进,更全面、更极致的 PolarIndex 2.0 。本文聚焦 PolarDB 的 InnoDB 存储引擎核心数据结构 B-Tree,介绍我们在并发访问控制机制的技术演进路径。
背景
PolarDB 存储引擎的核心结构是 B-tree 索引组织数据,B-tree 的并发访问能力决定了系统的可扩展能力。
对于索引结构并发访问的处理,可以将索引整体作为一个数据项,应用事务系统的并发控制机制,例如基于 2PL、时间戳、MVCC 等机制。但是由于索引访问频繁,将成为锁竞争的集中点,导致系统低并发度。
考虑到索引不必像其它数据项那样处理,对于事务而言,对一个索引查找两次,并在期间发现索引结构发生了变化,这是完全可以接受的,只要索引查找返回正确的数据项。因此只要维护索引的准确性,对索引进行非可串行化的并发调度是可接受的。
在 B-tree 索引的并发访问控制上,通常利用物理锁 latch 来实现互斥,在共享数据访问结束后就可以立即释放。这区别于事务系统的逻辑锁 lock,事务锁需要在事务提交时释放,通常会持续较长时间。
在本文中以下术语是通用的,节点和 page,latch 和 lock。
B-tree 并发控制要解决的两个问题:
并发问题 1:page 的并发读写
InnoDB 允许多个线程访问共享的 buffer pool page,因此在 page 粒度上需要进行并发访问控制,即一个线程读写某个 page 时,其它线程不能修改这个 page 的内容,否则会导致 page 内部结构变化。换句话说,page 上的读写和写写并发都要进行加锁互斥,或者采用多版本等方法保证一致性。
InnoDB 采用 rw latch 的方式来实现 page 的并发访问控制:
- 每个 page 关联一个读写锁,读 page 需要获取 S latch,修改 page 获取 X latch;
- 整个 B-tree 关联一个读写锁,锁住整个 B-tree 之后保证没有 page 的并发访问,就不需要获取 page rw latch;
这就是多线程访问共享数据结构的临界区问题,在数据库系统中的各个模块,共享数据结构都有相应的临界区保护。
本文中,所有内容建立在 page 并发读写需要加锁互斥的前提下,不考虑 page 无锁的实现。
并发问题 2:B-tree 结构的并发读写
除了在 B-tree page 内部的修改和读取,B-tree 还有结构调整的操作(SMO),结构调整涉及到多个 page 之间关联的改动,单独使用 page 级别的读写锁,不能避免树结构变换导致的访问问题,线程可能看到不一致的树结构。
在下图所示的一个 B-tree 分支上(图a),有两个线程在并发访问:线程 1 查找 15;线程 2 插入 9;
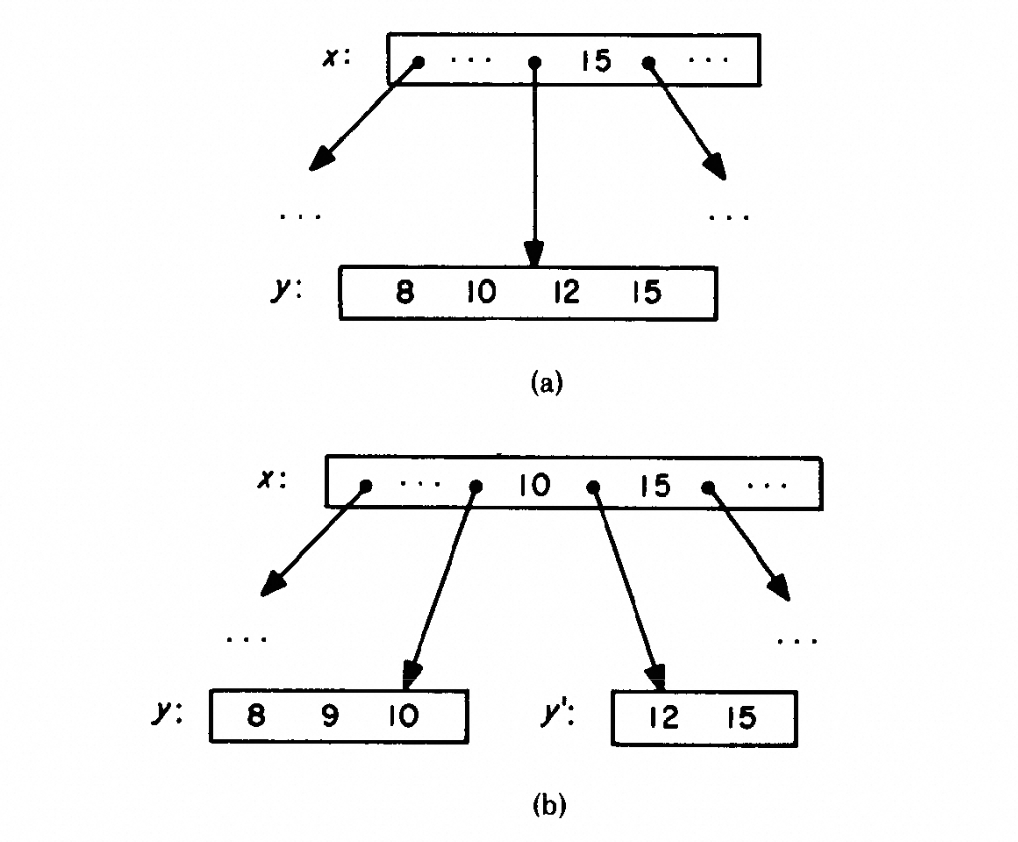
线程 1 包含两个操作步骤:
- 读取节点 x,拿到了 y 的 page no,然后释放节点 x 的 S latch。
- 通过 page no 获取节点 y,预期会在节点 y 上面读取到 15 这个值;
可能发生的问题是,在线程 1 进行上述两个操作之间,线程 2 插入 9 导致节点 y 发生分裂(图b),12 和 15 两个值被移动到 y’(树结构改变)。这就导致线程 1 最终拿到的 page y 上面找不到 15,也就是通过 B-tree 索引无法查找到一个真实存在的数据。
我们把这个问题描述为,发生树结构变化导致的结点指针失效。为了避免这个问题,最简单的做法是 B-tree 级别的大锁,所有读取操作加 index S latch,所有修改操作加 index X latch。
这个方法的问题是粒度太大了,即便在不同线程访问的数据完全没有冲突的情况下,整个 B-tree 读写操作和写写操作也只能低效率地串行访问。
除了上述两个问题,range scan 在 leaf level 的正反向扫描也会带来若干并发问题,本文暂不讨论支持 range scan 相关问题。
本文主要针对这两个问题,来介绍 PolarDB 的优化历程。
MySQL 5.6 —— latch leaf + latch entire tree
论文(R. Bayer & M. Schkolnick, Concurrency of operations on B-trees)提出了一个写线程先乐观再悲观的方法:
主要思想是,大部分的修改操作不会改变树结构,只在目标 leaf page 内部进行增删改,而这种情况下只需要加目标 page 级别的 X latch,而不需要获取 index 级别的 X latch 来阻塞其它线程读写其它 page。
因此,一个线程执行的修改操作,可以先乐观地假设不会发生 SMO,只 ”乐观地“ 获取 leaf page X latch,在大部分情况下可以完成操作(假设 leaf page 中 record 个数在 k 到 2k 之间,乐观修改成功的概率是 (k-1)/k)。否则,如果该节点太满或太空,就需要放掉 page X latch,重新获取 index X latch,再进入悲观操作流程。
这种方法缓解了修改操作 latch entire B-tree 的问题,在写不密集的场景下(不频繁发生分裂/合并)性能会表现的很好。本文后续会把线程分为两类,乐观线程只读写一个 leaf page,悲观线程会修改 B-tree 结构。
5.6 版本的 InnoDB 就基于上述方法实现了 B-tree 并发控制,具体的:
- 读操作先获取 index S latch,再自上而下无锁遍历 non-leaf page,找到目标 leaf page 对其加 S latch;
- 写操作先乐观进行:遍历过程与读操作完全一致,获取 index S latch,无锁遍历 non-leaf page,对目标 leaf page 加 X latch;
- 如果写操作乐观尝试失败:释放目标 page X 和 index S,重新获取 index X latch,此时整个 B-tree 不再有其它线程访问。进行树结构调整时,再获取需要修改的 page X latch;
我们看到读操作和乐观写操作在 top-down 遍历时,都不需要获取 non-leaf page 的任何 page latch,这是因为它们都先持有了 index S latch,保证了在遍历过程中不会有树结构调整,也就不会有其它线程对 non-leaf page 的修改。就是说在 non-leaf page 上面不存在读写冲突,并且因为悲观写先持有 index X latch,更不会存在写写冲突。
总结一下,5.6 InnoDB 解决 B-tree 并发控制两个问题的方法:
- page 并发读写/写写冲突:index latch 解决 non-leaf page 的冲突,page latch 解决 leaf page 的冲突;
- B-tree 结构并发读写冲突:SMO 持有 index X latch,限制整个 B-tree 的访问;
5.6 版本虽然使用先乐观写的方法,但是 index latch 在频繁并发写入的场景仍然成为明显的性能瓶颈。问题在于 SMO 持有 index X latch 后会进行一系列操作:分配 new page、移动数据、修改多个 page 的关联,这个耗时的过程中其它任何线程都无法访问 B-tree。
更坏的情况是,大表的数据页无法被 buffer pool 容纳,SMO 过程中需要多个 read IO 获取相关节点,这进一步增加了 SMO 的耗时,在 IO 延迟大的云存储环境下,这个问题更是雪上加霜。
因此 InnoDB index 上的并发能力是一个主要的系统瓶颈,一个长久以来的说法是,mysql 大表性能不好,表越大越慢,需要进行分区等操作。由于 index latch 的存在,单表上无法获得线性扩展能力。
MySQL 5.7/8.0 —— latch coupling + latch sub-tree
为了优化 index latch 的性能瓶颈,重新考虑下 SMO 持有 index X latch 解决的问题:
并发写线程修改树结构,导致读线程在 parent 结点获取的 child 指针失效。
就是说这种读写冲突发生在 parent 和 child 两个节点之间,那么很自然的想法是只对两个节点加锁,就可以锁住它们之间的边。
一个优化方法是 latch coupling:一个自上而下的遍历,先获取到 child page 的锁,再放开 parent page 的锁。这样就可以避免获取到的指针失效。
这引入了一个问题:top-down 遍历先后获取了两个锁,而 SMO 需要先修改 child page 再修改 parent page(down-top),他们获取节点锁的方向正好相反,出现死锁问题。
解决这个死锁问题的一个方法是,SMO 线程提前持有要修改的 parent X latch,避免持有 child X latch 之后再请求 parent X latch:
SMO 线程下降过程中获取 parent X latch,拿到其 child page X latch 之后,判断子结点是否可能发生分裂或合并,以此来确定 parent X latch 是否释放。需要注意的是,parent 节点本身也可能调整,因此会锁住 grandparent 节点,结果是 SMO 锁住了一个 sub-tree 上面到目标 leaf page 路径上的所有节点。
5.7 之后 InnoDB 就采用了 latch coupling + SMO latch sub-tree 的方法,将 SMO 锁范围降低到 sub-tree 级别,因此 B-tree 内部节点需要 加 page 读写锁进行并发控制,这解决了问题 1。对于问题 2,读线程 latch coupling 不会允许并发修改父子节点关系。
latch sub-tree 相比于 5.6 版本直接锁 B-tree,在并发读写场景下性能会好很多。不过 InnoDB 在实现这个方法时,也存在一定问题:
- latch sub-tree 导致的单一操作加锁范围大:
- SMO 线程:SMO 下降过程中无法精确判断 latch sub-tree 的最小范围,因此会充分加锁保证正确性,对于 B-tree 3-4 层的结构很容易锁住 root 节点,这就和 latch entire tree 没有差别了;
- 乐观线程:latch coupling 没有实现最多持有 2 个节点。SMO 只锁住了 sub-tree 的一条路径,而 B-tree 存在节点左右指针,可能需要修改 uncle 节点。不能让 latch coupling 下降走到 sub-tree 内部形成死锁,需要在 sub-tree 根节点做互斥,因此下降路径上的所有节点都要保持 S latch,直到拿到 leaf page 后才释放上层所有 page latch;
- 不允许 SMO 线程并发:SMO 线程持有 index SX latch,导致并发插入场景下 index latch 成为系统瓶颈。如果将这个限制放开,多个 SMO 线程并发进入 B-tree,每个线程要获取多个 page latch,会导致设计死锁避免的加锁规则异常困难;
InnoDB B-tree 并发控制的细节分析:http://mysql.taobao.org/monthly/2020/06/02/
PolarDB 初步优化(1.0)—— all latch coupling
上述 InnoDB 的问题在于 latch sub-tree 导致的加锁范围大和 SMO 无法并发。
去掉 latch sub-tree
优化的方向首先是去掉 latch sub-tree。
产生死锁的线程:SMO 线程自下而上 X latch;search/modify 线程自上而下 S/X latch;
死锁形成的四个条件:互斥、请求与保持、不可抢占、循环等待
死锁预防:通过设计协议,破坏四个必要条件中的一个或多个,使死锁永远无法满足。
死锁避免:不会事先去破坏死锁的必要条件,允许系统进入死锁状态,然后用某种方法检测到死锁后,选取一个 victim 释放资源进行恢复。
latch sub-tree 方法是死锁预防:通过资源有序分配(规定 latch order),破坏循环等待条件,来预防死锁发生。
这种死锁预防实现简单,但是由于限制条件太严格,可能会导致系统资源利用率和系统吞吐量降低。
我们考虑采用死锁避免,在真正发生死锁前,不会对系统效率造成影响。即系统进入死锁状态的概率不是很高,就没必要提前引入开销,这样系统效率会更高。
一个类比是事务系统的数据冲突判断方法,主要分为悲观和乐观两类。悲观方法,事务每次数据访问都在并发控制机制监控下执行,进行严格的冲突判断。而乐观方法,乐观地假设事务能够完成执行并最终有效,只在事务提交时对所有数据进行一次冲突判断,如果有冲突再进行回滚。 乐观方法避免了事务执行过程中,并发控制机制带来的代码执行开销和可能的延迟,在系统冲突不严重的情况下,一般具有更好的效率。
实现 1: 乐观线程 retry
采用死锁避免的方法:当一个线程等待 page latch 时,一旦感知到自己与另一个线程发生死锁,就释放已经持有的资源并重试。
我们选择让乐观线程(search/modify)感知到正在进行的 SMO,如果存在死锁,就释放乐观线程资源。具体的,PolarDB 对 page 添加一个 SMO 标记:
在 SMO 线程向上申请 parent X latch 之前,对当前持有 X latch 的 leaf page 添加一个 SMO 标记。
乐观线程下降 latch coupling,一旦发现要获取的 child page 具有 SMO 标记,就释放自己持有的 parent page latch,并 retry from root。
这种方法在产生冲突时,通过牺牲乐观线程的效率,来进行死锁避免。
实现 2: move right
乐观线程可以分为 search 和 modify,是否能单独优化?
search 线程只对目标 page 获取 S latch,不涉及 page 内部任何修改操作。SMO 修改完 child page 之后,请求parent page X latch 之前,是否可以允许 search 线程读取 child page?
这样就可以破坏请求与保持(hold and wait)条件:
SMO 自下而上不再使用 latch coupling,这产生的问题是 search 线程会获取到失效的 child 指针,就是说 search 线程看到了 SMO 中间状态(B-tree 并发问题2)。
我们借鉴 Blink tree 的方法解决这个问题,SMO 操作划分为两个阶段,第一阶段完成就提前允许 child page 读取。具体的,SMO 中间状态节点设置一个指向其右侧 new page 的指针,读操作访问到 SMO 中间状态的节点,可以同时在其 right page 中检索 record,解决了读线程拿到的 child 指针失效问题。
由于 search 线程依然是 latch coupling,在找到目标 record 所在 page 之前不会释放 parent S latch,这样就导致 SMO 不会完成第二阶段,而相同 child page 的 SMO 不能并发(modify 线程不允许看到 SMO 中间状态的 child page),因此 search 只需要移动一个 right page 就可以保证找到目标 record,这与 blink tree 是有区别的。
对于 modify 线程,因为 SMO 对 page 的修改还没有提交,不能允许其它线程修改处于 SMO 中间状态的节点,否则会导致 WAL 中 page 修改乱序。
总结上述实现 1/2,根据乐观线程请求 child page 的锁类型:
- X 锁(modify 线程)优先级低于 SMO:申请 X latch 时发现 page SMO 标记,立即返回失败并释放持有的 parent latch,等待 SMO 结束后再从 root 重试下降;
- S 锁(search 线程)兼容 SMO 标记:page 上的 SMO 标记与其它线程获取 S latch 不冲突,让读操作能继续执行;
简单来说,这个并发控制方法解决死锁的原理:
- 死锁避免:写线程判断冲突,释放资源,让 SMO 线程优先执行,之后写线程再重试;
- 死锁预防:SMO 线程中间阶段放锁,读线程自己处理看到的不一致树结构;
最终,我们实现了减小了各种操作的锁范围,降低线程间冲突:
所有乐观线程实现了 latch coupling,最多只拿两个 page latch;
从 search 线程的视角,SMO 线程只拿一个 page latch,没有 latch coupling;
从 modify 线程的视角,SMO 线程使用 latch coupling,最多拿两个 page latch;
去掉 latch index
为了实现 SMO 并发,PolarDB 又去掉了 index latch,允许 SMO 并发访问 B-tree,线程间冲突只在 page 级别,并在加锁规则的设计上避免 SMO 获取多个 page 时可能发生的死锁问题。
实现细节参考文档:zeromean:PolarDB B-tree 优化之路
性能结果对比
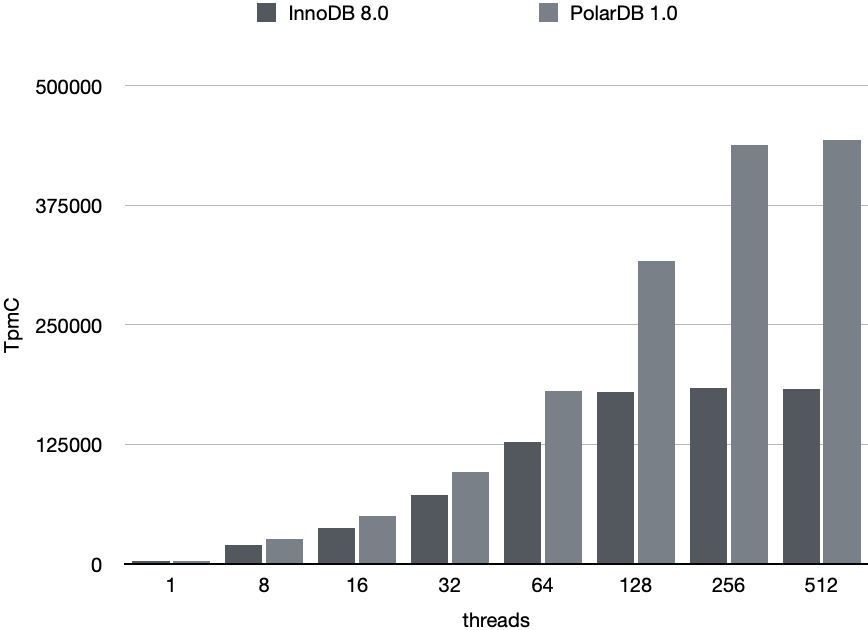
测试场景:
标准 tpcc 场景,warehouse 1000
PolarDB 的性能整体优于 InnoDB,峰值性能是 InnoDB 的 2.5 倍左右。
PolarDB 深度优化(2.0)—— no latch coupling
分析上述实现,PolarDB 在下降过程使用 latch coupling,最多同时持有两个 page latch,在高并发场景下仍然会出现 page 锁争抢的瓶颈。例如在 autoinc insert 场景下,parent page 的锁争抢严重:下降线程 latch coupling 持有 parent S latch,SMO 线程请求 parent X latch,具体分析:http://mysql.taobao.org/monthly/2023/03/01/
latch coupling 是否已经最优,锁范围是否还有优化空间?
有一种更高效的解决方案,也就是 L&Y blink tree 论文中的优化(P. Lehman and S. Yao, Efficient latching for Concurrent Operations on B-Trees)
L&Y 怎么高效解决 B-tree 并发问题
blink tree 允许读线程下降过程看到 split 中间状态的 B-tree 结构,由读线程自己去处理这种中间状态。
论文中的假设是线程每次访问 page 都从磁盘读取到线程私有内存,因此不需要加 page latch 避免 page 读写冲突。下降过程通过 parent 拿到了 child page no,再去获取 child page 时可能发生 B-tree 并发问题 2。
如果这期间 child page 发生过多次分裂,一定是向右发生的(blink tree 只允许向右分裂),之前拿到的 child page no 一定是左边界,只需要向右一直 move to next page,就一定能找到目标数据或者到达 B-tree 边界。
基本的原理是,一个节点会有 parent / left sibling 两个节点指向它,只要完成了一个指针,就可以被 search 看到了。
postgres nb-tree 分析
我们分析了 postgres 对 L&Y 论文的工程实现:https://github.com/postgres/postgres/blob/master/src/backend/access/nb-tree/README
pg 遍历下降过程中只持有当前读取 page 的 latch,读取到 child page no 就放掉 parent latch。每次读取到一个 page,需要判断 search key 与 page high key 的大小关系,通过 while 循环 move right 到一个目标 page。
因此, top-down 遍历可以不使用 latch coupling,最多同时只拿一个 page latch。
在 SMO 自底向上的方向,pg 采用了保守实现,需要先插入 parent 再释放 child X latch,也就是 child -> parent 路径上的 latch coupling,避免了 child page 出现多个 link page。由于没有 top-down 方向加锁,SMO 获取 child page 和 parent page 不会发生死锁。
可以看到 pg 分裂时最多只拿 child page + parent page 两个锁,而 L&Y 论文在 parent level 需要 latch coupling 右移,因此最多拿三个锁。
L&Y 在 parent 里查找插入位置为什么需要 latch coupling?
查找 new child page 在 parent level 中的插入位置:pg 使用 child block no 来查找定位,而 L&Y 里使用 sep key。 用 block number 和 sep key 查找的区别是: block number 是被分裂 old child page 的 block number,在 parent level 中一定存在,顺序找就一定能 match。而 sep key 是 new child page 的 first key,在 parent level 中是不存在,需要根据 key 范围找到一个合法位置,才会出现夹在 page 中间的特殊情况。所以 L&Y 使用 latch coupling 可以完全拿到两个 page 后,判断插入位置到底在哪后,再放掉锁。这个是工程实现上要考虑的问题。
pg 基于(V. Lanin and D. Shasha, A Symmetric Concurrent B-Tree Algorithm)实现了一个简化版本的 deletion 逻辑。
他们认为支持 merge 操作在工程上过于复杂且收益甚微,一般来说 insert 比 delete 多,不做 merge 浪费的空间并不多。
因此 pg 实现的是 page 所有 record 都删除后,再做一次 page discard,分为两阶段,并标记 half dead 等没人访问了再做回收。
PolarDB 与 Postgres 的对比
我们可以发现,PolarDB 读线程遇到 page SMO 标记的 move right 处理与 blink tree 类似,PolarDB 借鉴了 blink 方法。不同的是,PolarDB 遍历下降过程保留 latch coupling,持有父节点 S latch,如果走到的 child page 上有 SMO 标记,说明 SMO 肯定还没有完成(父节点被读线程锁住),而 SMO 中间状态的节点不可能再次分裂,因此只需要一次 move right 就够了。
在锁范围上对比:pg 保留自下而上 latch coupling,polar 保留自上而下 latch coupling。
pg 的 latch coupling 发生在 SMO 线程,插入 new page 指针到 parent page 之前,child page 是一直持有 X latch 的。其它遍历在此时无法访问到 child page,而 PolarDB 在 SMO 中间阶段是允许 child page 被读取的。
读线程不需要 latch coupling 的优势在于,SMO 获取 parent latch 时,不会被读线程持有 parent S latch 影响,相当于把 SMO 优先级提高。在并发 insert 场景中,parent page 的锁竞争是一个比较大的影响。
PolarDB 与 postgres 在 B-tree 并发控制机制上的细节对比:http://mysql.taobao.org/monthly/2024/08/04/
PolarDB no latch coupling
在 1.0 基础上,基于 L&Y’s blink tree 描述的算法,实现了一个去掉 latch coupling 的 B-tree 并发访问控制方法。相比于 L&Y 算法,我们在实现中主要做了如下几点改动:
page 读写锁
L&Y 的算法不需要读锁,它假设内存中的 page 是不共享的,这意味着每个进程或线程都有自己独立的 page 副本,因此在读取数据时不需要担心其他进程会修改这些 page。
而 PolarDB 允许不同线程共享内存中的 buffer pool,这种共享机制可以提高资源利用率,但也带来了并发访问的问题,为了确保读取的 page 不会被其他线程修改,PolarDB 采用了 page 级别的读锁,这降低了并发性但保证了正确的行为。
下降遍历
与传统的 B-tree 相比,L&Y 算法给每个 page 上增加了一个指向其右兄弟页面的连接,以及一个 high key 表示该页面允许存储的 key 的上界。这两个改进使得算法能够检测到并发的页面分裂,从而允许在 search 下降过程中不需要 latch coupling,而是通过右移找到正确的目标 page。
为了避免添加 high key 影响原有的 page 数据格式,我们采用一种先乐观后悲观的 search 方法(假设 search_mode = LE):
乐观:search key >= 当前节点 last record,说明可能需要右移到 next page,此时先采取乐观方式,先释放当前节点,再获取 right page,判断其 first record 和 search key 的大小关系,如果 search key >= first record 说明右移是正确的,否则右移失败进入悲观流程;
悲观:search key >= 当前节点 last record,持有当前节点,同时获取 right page,判断 search key 和 first record 大小,根据比较结果确定是否右移,并释放一个节点;
我们认为乐观操作成功的概率为(k-1/k),k 是节点分裂前的 record 数量,一般来说成功概率较高。采用这种乐观方式和 high key 对比性能影响在 3% 以内。
范围遍历
InnoDB B-tree 每层 page 通过前后指针形成了一个双向链表,可以高效地支持正向和反向的 range scan,而 L&Y 描述的 blink tree 只有一个向右指针。
这就需要在 L&Y 分裂算法中增加额外的一个步骤:持有当前分裂节点的 X latch,需要再获取 right page X latch 来修改其左指针,这个从左向右的加锁是安全的,我们规定不允许从右向左加锁。
forward scan:向右扫描时,不需要使用 latch coupling 的方式获得 right page,因为即使当前 page 发生了分裂,数据记录的移动不会越过原本 page 的上界,而这些数据已经被扫描过了,这样不会漏掉没读过的数据,也不会重复扫描数据。
backward scan:向左反向扫描会比较复杂,获得当前 page 的 left-link 后,释放当前 page,再获取 left page,这期间 left page 可能已经发生过分裂,因此还需要进行右移来处理这种情况。
SMO
在 SMO 执行的自下而上的方向,L&Y 算法需要使用 latch coupling ,先修改父节点再释放子节点,避免了子节点出现多个 link page。并且 L&Y 在 parent 层定位 child page downlink 的过程,需要用 latch coupling 右移。可以看到 L&Y 在做 SMO 时最多同时持有三个节点的 latch。
在我们的右移实现中,parent 层查找 downlink 过程不再需要 latch coupling。
另外,我们去掉了 SMO 自下而上的 latch coupling,通过给 child page 增加 SMO 标记的方式,使其它线程可以感知到 child page 处于 SMO 中间状态,等待 SMO 结束再 try again,避免继续分裂当前的 child page。
通过 ”wait and try again“ 的乐观方式来解决冲突,因此可以实现 SMO 在上升过程中最多只持有一个 page latch,这在 PolarDB 1.0 版本中就已经实现。
总结
上述几种 B-tree 访问操作,最多只持有一个 page latch,最小化加锁粒度,降低并发操作的锁冲突。
性能结果对比
测试场景:并发线程 insert 数据行,pk 使用 autoinc 自增。
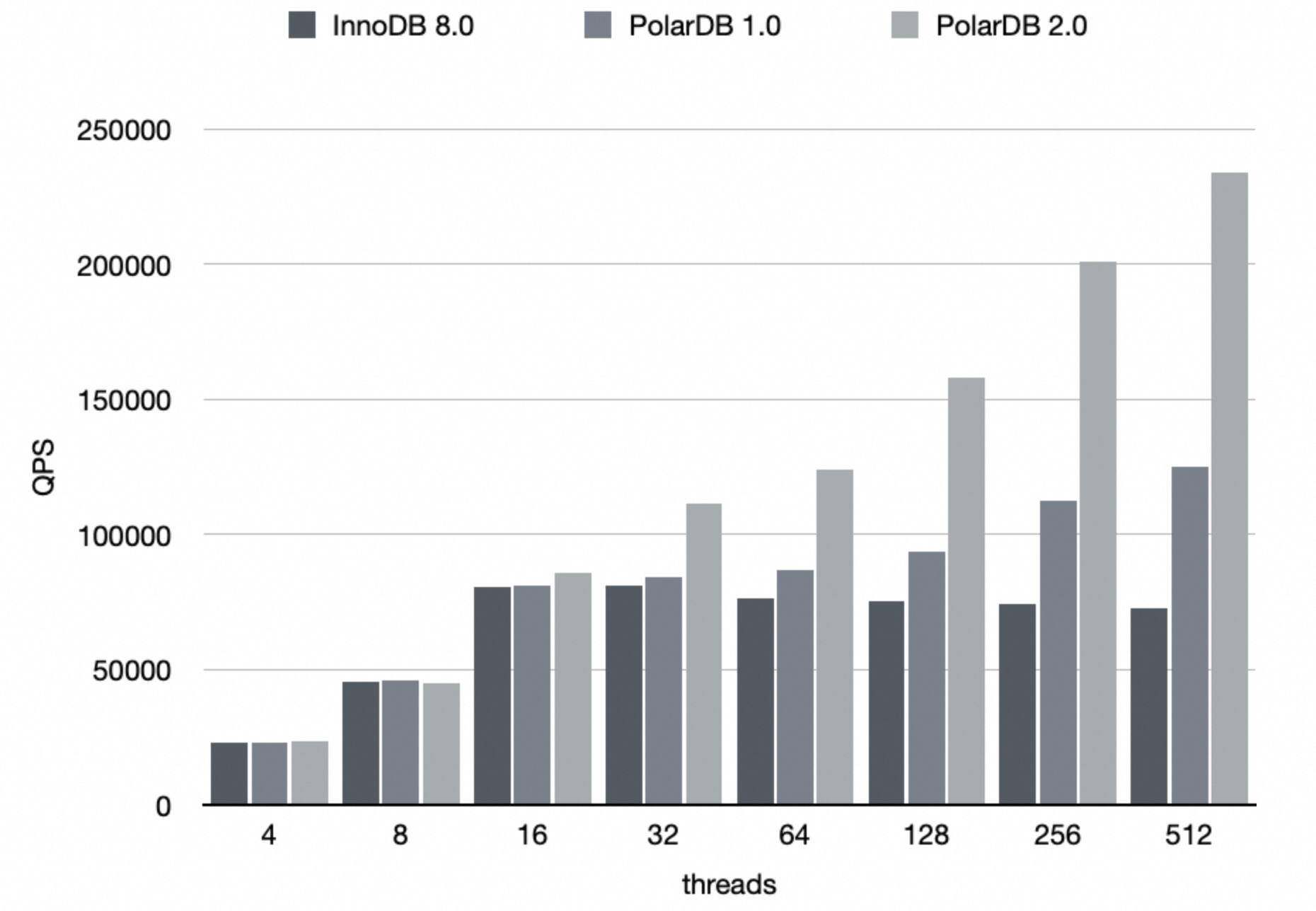
InnoDB 在 32 并发时达到性能峰值,并发线程数继续增加后,由于锁竞争开销增大,性能呈现缓慢下降的趋势,说明其扩展能力达到上限。
PolarDB 1.0 随着并发数增加,整体吞吐呈上升趋势,峰值性能达到 InnoDB 的 150%。
PolarDB 2.0 相比于 1.0,在并发线程数超过 16 之后,可以看到明显优势。可以证明去除 latch coupling 减少锁范围,获得非常显著的并发吞吐性能提升,峰值性能达到 InnoDB 的 3 倍左右。并且随着并发线程数增加,可以看到其具有很好的线性扩展能力。