Memcached · 最佳实践 · 热点 Key 问题解决方案
Author: wenlong.ywl
背景
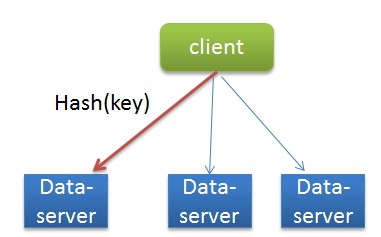
在分布式K-V存储系统中,对某个key进行读写时,会根据该key的hash计算出一台固定的server来存取该K-V,如果集群不发生服务器数量变化,那么这一映射关系就不会变化。
云数据库 memcached 就是这样一种K-V缓存系统。在实际应用中的某些高峰时段,有的云数据库 memcached 用户会大量请求同一个Key(可能对应应用的热卖商品、热点新闻、热点评论等),所有的请求(且这类请求读写比例非常高)都会落到同一个server上,该机器的负载就会严重加剧,此时整个系统增加新server也没有任何用处,因为根据hash算法,同一个key的请求还是会落到同一台新机器上,该机器依然会成为系统瓶颈。这个问题称为“热点key”问题。
现状
用户使用云数据库 memcached 就是为了提升业务性能,难免会触发“热点key问题”。但云数据库memcached做为公有云服务,在发现有热点的情况下,如果继续放任该热点无限激增,就会带来整个系统雪崩。所以当前的做法是对每个用户在每台服务器上分配一定的QPS或带宽,当用户在某台服务器上的请求超过该用户的配额,我们就会对用户进行流控,服务端返回TEMPORARY_FAILURE,该限制会影响用户正常请求,持续时间分钟级。
思考
用户触发热点问题是业务需要,是理所当然;云数据库 memcached 对热点 key 进行流控是保障系统稳定性,也在情理之中。但有没有一种既能提供用户热点 key 访问的需求,又能保护云数据库memcached服务器的方法呢,这正是本文所要阐述的。
解决热点问题有很多办法,比如用户如果提前知道某些key可能成为热点,那么客户端可以提前拆分热点key;也可以搭建一个备用集群,写的时候双写,然后随机双读。这些方案的实现前提和难度可想而知,下面给出的是对应用透明,且动态发现热点的解决方案。
解决方案
整体思路
本方案解决的是用户读热点问题,不解决写热点问题。
首先,云数据库memcached简单架构图如下:
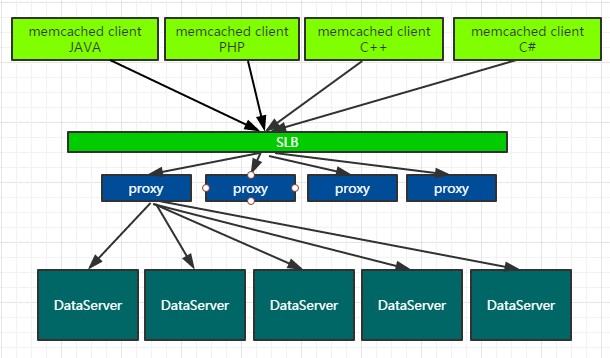
我们的proxy是无状态层,上面做了些访问控制功能,用户客户端到proxy是随机的,不受固定算法(如hash)控制。而proxy到DataServer的链路是根据key决定的,当用户访问热点key时,所有proxy上关于该key的请求都会落到同一台DataServer。
所以解决热点问题,其核心思路是:每台DataServer对所有key进行采样、定位,实时计算出当前热点key,将其反馈给proxy层,由proxy缓存备份。即负载压力由DataServer转向proxy。理由是:Proxy可以无状态扩容,而DataServer不可以。
DataServer如何发现热点
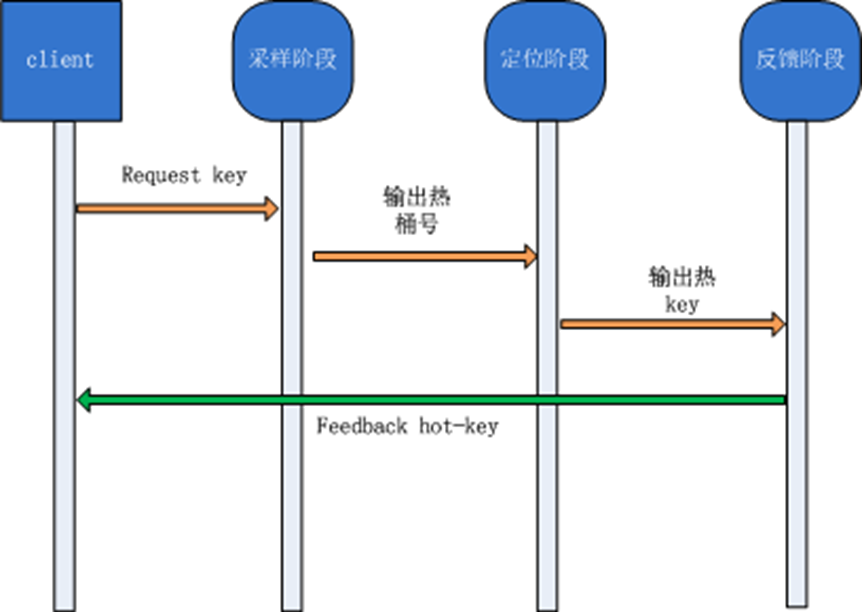
每台服务器有个HotKey逻辑,让每个到达服务器的目标请求(可配置不同类型请求)经历三个流水阶段:
- 采样阶段(根据配置设定采样次数sample_max) 本阶段输出:是否有热点现象,如果有热点,输出热点的桶号供下阶段使用。
- 定位阶段(根据配置设定采样次数reap_max) 本阶段输出:热点key(如果满足阈值),并添加到服务端的LRU链表。
- 反馈阶段 对到达服务器的目标请求,取出key,然后查询LRU链表判断该key是否为热点key。如果是热点,就会在请求结束后,向proxy发送一个feedback包,通知proxy。
至此,服务器hot-key逻辑结束。流程图如下:
发现热点后proxy怎么处理
当Proxy收到DataServer的热点反馈之后,会将该key写入到自己的LRU-cache里面,该cache的过期时间和容量大小都交由用户通过控制台设置,默认分别是100ms和30。这样热点的key就已经存在于与proxy中了,下次用户请求就可以直接返回了。
如何保证数据一致性呢?
下面讨论都是用户client已经触发了热点key问题,假设用户client跟每个proxy都建立了链接,并且每个proxy上都有对热点key的请求,那么理论上每个proxy的LRU-cache都有一份数据。
我们保证单条连接上的一致性。 当用户client和proxy1建立连接,用户修改了一个key(任何写操作),proxy1上会在LRU-cache中同步删除该key,新key就会写到DataServer上,然后在读数据的时候,由于LRU-cache不命中,就会从DataServer上拿到最新数据。
不同链接上只能提供弱一致性。 如果这个时候用户从proxy2上读热点数据呢?理论上就会读到老数据,该数据将于100ms之后从proxy-cache中过期淘汰掉,之后就会更新会最新数据,即不同连接间可能有100ms不一致。
怎样看待弱一致性。 事实上,不开启热点key功能,在不同链接上也会存在弱一致。假设用户client建立了两条链接到云数据库memcached,在链接1上写入key-value1,在链接1、2上分别读该key。当链接1上用户update了key-value2,这个请求需要一定的网络延迟才能写入到服务端,如果这个时候链接2上同时发起对key的读取操作,如果读请求先到服务端,它将读到的是value1的老值。
所以开启热点key功能,只是增加了不一致时间,且该功能为可选,控制权由用户掌握。
适用场景
由以上分析可以看到,开启热点key功能之后,只会对用户的读请求产生影响,该影响增加了不同链接上的弱一致性的时间。因此,该功能适合读多写少,且对强一致性要求不高的应用。
收益
整个方案核心是负载压力由DataServer转移到Proxy。好处如下:
- 因为DataServer扩容也解决不了热点问题,而Proxy可以无状态扩容,对用户来讲就极大提升了热点key访问的能力,不受单点制约;
- 缩短了服务端处理链路,对用户平均RT也所降低;
- 免除服务端热点流控的分钟级别影响。