PetaData · 架构体系 · PetaData第二代低成本存储体系
Author: 皓庭
背景
2015年7月,PetaData分布式数据库开放了低成本存储体系,随后便服务了天象等多个大数据业务,这些业务存量数据在数百T,日新增10T,新增数据大多是秒级监控数据,既要数据实时可见,又要支持多维度低延迟查询,还要大幅降低成本。
在PetaData第一代低成本存储体系中,融合了ApsaraDB团队多年的技术积累,包括方寸山分布式框架、MySQL TokuDB存储引擎、低成本机型等技术,最极限的一个业务,使用了少量sata盘机型满足了存量400T+,日新增数据10T+的更新需求,以及热数据查询毫秒级,冷数据查询亚秒级的查询需求。
随着业务的不断发展,第一代存储体系面对P级存量、日新增百T的数据业务,已经力不从心,PetaData不断探索,开发出了第二代低成本存储体系,本文将从多个角度进行介绍。
存储架构
-
整体外观
PetaData利用数据sharding的思想,将业务数据分布在多个MySQL实例上,这些MySQL实例是ApsaraDB团队为PetaData深度订制的存储引擎,实例间share nothing,从而支持水平扩展。整套系统运行在全新设计的软硬件一体资源容器中,并配套开发了改进的运维体系。
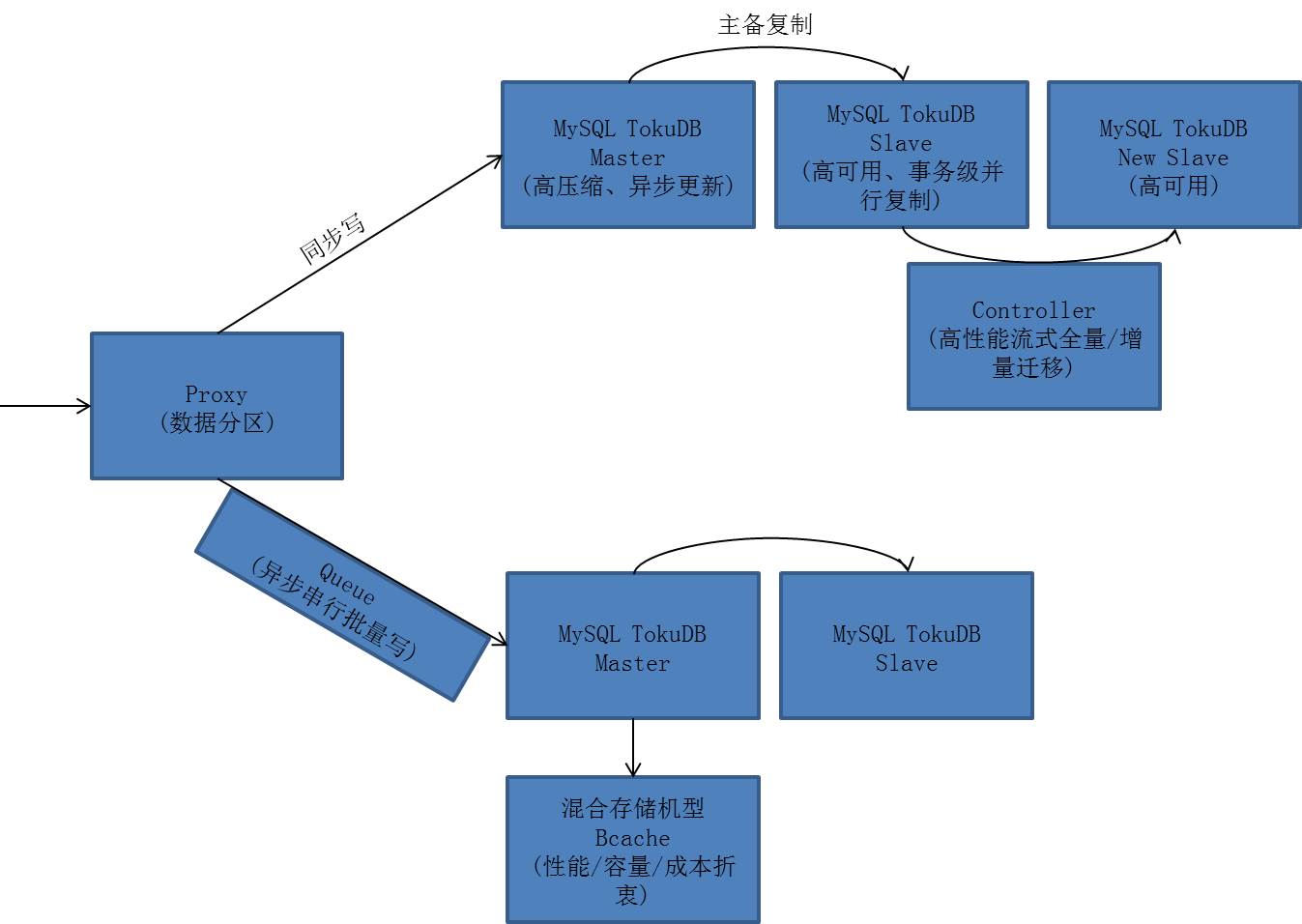
图中的关键技术包括分布式、单机存储引擎、迁移、软硬件结合等部分。
- 分布式
在分布式层,PetaData利用了分库分表的思想来支持数据sharding,数据被切分到若干数据库分库上,在MySQL的物理迁移和多主复制基础上开发了快速扩容。
-
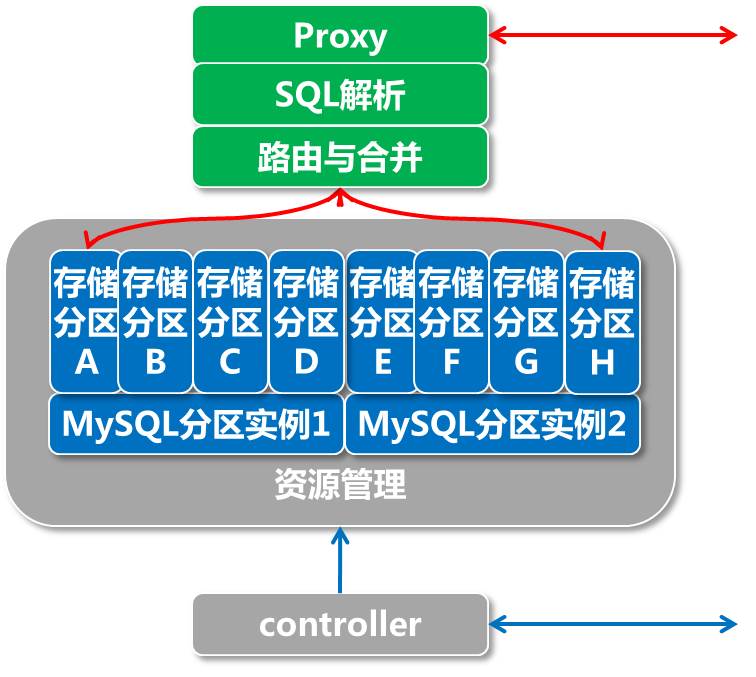
数据分区 数据分区是大数据的普遍策略,PetaData的数据入口Proxy,将用户的请求路由到各个存储分区上,以达到性能的线性扩展。
由于数据分区间share nothing,对于一些多分区更新和查询会有一定的限制,这主要从两个方面弥补:多分区的更新通过分布式事务来支持,多分区的查询通过计算引擎来支持。
-
数据扩容
传统分库分表中间件,在数据扩容时,需要将所有数据整体做逻辑导出导入,整体开销很大,为了避免影响用户业务,也要将多个源分区产生的增量更新,复制到目标分区上,这对于单复制通道的数据库极为复杂,甚至可能要分时复用复制通道。
PetaData将扩容分为全量迁移和增量复制二个阶段:在全量迁移阶段,使用MySQL的物理迁移,在分区间直接拷贝存储引擎的数据文件,大幅提升全量迁移的性能;在增量复制阶段,使用MySQL的多主复制,以供单个分区从多个分区复制增量数据,避免分时复用带来的复杂性;整个扩容方案干净而高效。
-
异步聚合
第二代架构下,PetaData在Proxy处支持了异步聚合能力,用户session的更新请求,送入每个存储分区的异步队列后便返回,由异步刷写线程存储分区递送请求,用户的session可以快速发出下一批请求,从而与异步刷写线程的工作时序重叠起来,既提升了吞吐量,也降低了写rt。
异步刷写线程,也可以将同个分区的写请求,打包成一个请求,送入存储分区,减少存储分区的事务开销,有效提升存储分区的吞吐率,异步聚合并不兼容传统数据库的隔离级别定义。
在存储分区压力过大,异步线程来不及刷写时,异步写会退化为同步写,此时用户session会暂时阻塞在单次的写请求上,此时rt会增大,也代表着存储分区带宽打满了。
- 单机存储引擎
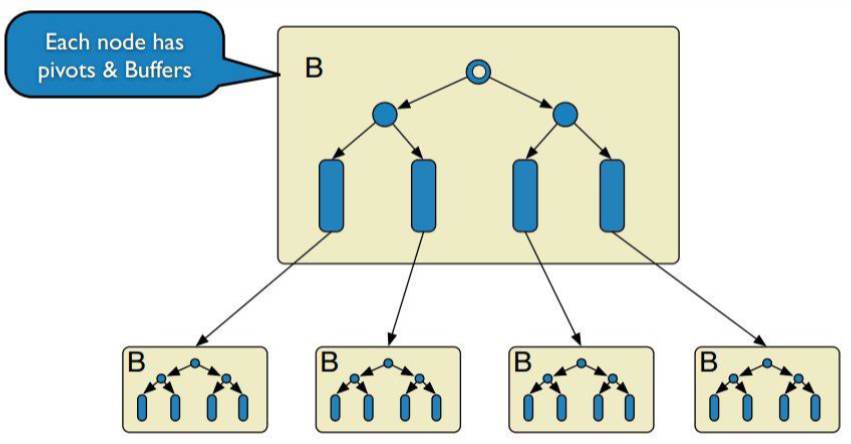
PetaData的单机存储引擎,使用了MySQL-TokuDB引擎,该引擎支持事务,写性能强劲,压缩比高,非常适合大数据业务场景。
-
异步更新
TokuDB引擎的数据结构为缓冲B树,每个中间节点均带有更新缓冲,写入时无需将更新实时刷入叶节点,而是缓存在中间节点,然后整批向下层合并。整个过程因为事务WAL的存在,数据无需实时写盘,而redolog本身近乎顺序写,对sata盘亲和度很高,使得低成本机型有了很大的应用空间。
最优情况下,写入根节点后,立刻返回。然后TokuDB的异步线程逐步将更新合并到叶节点,后续查询从叶节点取回数据;
最差情况下,写入根节点后,进行唯一性检查,从磁盘取回页面数据并更新,写延迟增大。写返会后,立刻查询,此时只能由读过程负责合并,增大读延迟;
第二代架构下,ApsaraDB团队先后为TokuDB增加了事务级并行复制等Patch,使得PetaData能适应更多的大数据场景。
-
压缩
TokuDB的缓冲B树节点,页面为4M,内部支持压缩,即使带上索引,日常压缩比也通常高达4以上,这也变相地降低了大数据用户的成本。目前TokuDB支持的压缩算法,包括zlib、snappy等,用户可以根据需要进行选择,也可以支持快速的变更。
- 迁移
-
流式全量/增量迁移
ApsaraDB的传统迁移方案,需要先对数据库进行热备(热备的数据包括数据库完整的全量数据,以及热备全量数据过程中产生的增量更新),将热备出来的数据完整上传到外部后备存储后,在将热备导入目标机器上。整个过程耗时很长,也易受网络带宽限制。
第二代架构下,ApsaraDB团队设计了新的流式迁移模型,将热备出来的全量数据,实时导入目标机器上,时间开销大幅缩减。为了避免在迁移热备数据时,过大的增量更新占满磁盘,热备过程中需要将binlog实时传递到外部后备存储,在热备完全进入目标机器后,再重放这部分binlog。此方案可以应对大全量、大增量的更新业务。
- 软硬件结合
为了尽可能优化PetaData的存储体系,ApsaraDB团队也将硬件机型纳入到存储体系的范畴,PetaData也为低成本存储体系选择了更合适的硬件。
-
混合存储
早在阿里去IOE时代,集团就考虑过ssd盘+sata盘组flashcache的混合存储方案,此方案在大部分场景下,既有ssd盘的访问性能,又有sata盘的容量,成本也较为可控。
第二代架构下,PetaData选择了类似的混合存储方案,来进一步提升整体存储的性价比。新的混合存储更加稳定,且拥有更强的弹性。
-
万兆网络
随着ApsaraDB数据库服务规模的扩大,网络带宽的需求愈发旺盛。PetaData的存储分区也处于这些数据库实例中。与ApsaraDB的其他关系型数据库产品不同,PetaData要解决高并发读写的问题,而读写一次数据,往往需要为外部运维、审计等功能成倍的放大读写请求,也会严重增请求的流量。
第二代架构下,PetaData接入了万兆网络,更高的带宽,可以极大提升备份和迁移的速度,改进产品的副本恢复策略,提升SLA。
展望
PetaData定位为HTAP分布式数据库,所谓HTAP,即为Hybrid Transactional/Analytical Processing,使用一份数据同时支持OLTP在线事务与OLAP在线分析,为此,PetaData团队还在如下几个领域不断耕耘着:
- 计算架构
PetaData支持的OLAP测试集包括TPC-H、TPC-DS等,并将OLAP业务划分为:
-
实时高并发类型:上万级qps,秒级rt,两阶段计算迭代可以完成,数据可预建模;
-
在线复杂分析类:个位数级qps,秒级到小时级rt,需多轮计算迭代可以完成,数据无法预建模;
这几类业务运行在一套计算引擎框架上,辅以列存索引加速计算性能,极大地扩展了PetaData的计算能力。
- 分布式事务
PetaData在跨分区更新时,需要通过分布式事务来保证,PetaData的架构中,有分布式事务协调者,配合各个存储分区的事务引擎,共同支持了两阶段提交分布式事务。
结语
在新的存储体系下,PetaData进一步改进了系统的吞吐量和rt,降低了成本,以迎接百T日新增数据的时代。
融合了大数据技术的PetaData,已经不仅仅是一个数据库,而更像是一类综合数据服务容器,让用户将更多精力放在大数据本身上,而无需关注外围的成本、存储、计算、一致性、可用性、接口等问题,降低了大数据的门槛。
PetaData的技术团队,致力于数据服务容器本身的改进上,打造出精致的分布式数据库服务,以迎接未来大数据的挑战。