MySQL · myrocks · myrocks之事务处理
Author: 张远
前言
mysql目前支持的事务引擎有innodb,tokudb。 rocksdb加入mysql阵营后,mysql支持的事务引擎增长至3个。
myrocks目前支持的事务隔离级别有read-committed和repeatable-read。 同innodb一样,myrocks也支持MVCC机制。
可以说,myrocks提供了很好的事务支持,能够满足的一般业务的事务需求。
sequence number
谈到rocksdb事务,就必须提及rocksdb中的sequence number机制。rocksdb中的每一条记录都有一个sequence number, 这个sequence number存储在记录的key中。
InternalKey: | User key (string) | sequence number (7 bytes) | value type (1 byte) |
对于同样的User key记录,在rocksdb中可能存在多条,但他们的sequence number不同。
sequence number是实现事务处理的关键,同时也是MVCC的基础。
snapshot
snapshot是rocksdb的快照信息,snapshot实际就是对应一个sequence number。 简单的讲,假设snapshot的sequence number为Sa, 那么对于此snapshot来说,只能看到sequence number<=sa的记录,sequence number>sa的记录是不可见的。
- snapshot 结构
snapshot 主要包含sequence number和snapshot创建时间,sequence number 取自当前的sequence number。
class SnapshotImpl : public Snapshot {
SequenceNumber number_; // sequence number
int64_t unix_time_; // snapshot创建时间
......
};
-
snapshot 管理
snapshot由全局双向链表管理,根据sequence number排序。snapshot的创建和删除都需要维护双向链表。 -
snapshot与compact
rocksdb的compact操作与snapshot有紧密联系。以我们熟悉的innodb为例,rocksdb的compact类似于innodb的purge操作, 而snapshot类似于InnoDB的read view。 innodb做purge操作时会根据已有的read view来判断哪些undo log可以purge,而rocksdb的compact操作会根据已有snapshot信息即全局双向链表来判断哪些记录在compace时可以清理。
判断的大体原则是,从全局双向链表取出最小的snapshot sequence number Sn。 如果已删除的老记录sequence number <=Sn, 那么这些老记录在compact时可以清理掉。
MVCC
有了snapshot,MVCC实现起来就很顺利了。记录的sequence number天然的提供了记录的多版本信息。 每次查询用户记录时,并不需要加锁。而是根据当前的sequence number Sn创建一个snapshot, 查询过程中只取小于或等于Sn的最大sequence number的记录。查询结束时释放snapshot。
关键代码段
DBIter::FindNextUserEntryInternal
if (ikey.sequence <= sequence_) {
if (skipping &&
user_comparator_->Compare(ikey.user_key, saved_key_.GetKey()) <= 0) {
num_skipped++; // skip this entry
PERF_COUNTER_ADD(internal_key_skipped_count, 1);
} else {
switch (ikey.type) {
case kTypeDeletion:
case kTypeSingleDeletion:
// Arrange to skip all upcoming entries for this key since
// they are hidden by this deletion.
saved_key_.SetKey(
ikey.user_key,
!iter_->IsKeyPinned() || !pin_thru_lifetime_ /* copy */);
skipping = true;
num_skipped = 0;
PERF_COUNTER_ADD(internal_delete_skipped_count, 1);
break;
case kTypeValue:
valid_ = true;
saved_key_.SetKey(
ikey.user_key,
!iter_->IsKeyPinned() || !pin_thru_lifetime_ /* copy */);
return;
case kTypeMerge:
......
隔离级别
隔离级别也是通过snapshot来实现的。在innodb中,隔离级别为read-committed时,事务中每的个stmt都会建立一个read view, 隔离级别为repeatable-read时,只在事务开启时建立一次read view。 rocksdb同innodb类似,隔离级别为read-committed时,事务中每的个stmt都会建立一个snapshot, 隔离级别为repeatable-read时,只在事务开启时第一个stmt建立一次snapshot。
关键代码片段
rocksdb_commit:
if (my_core::thd_tx_isolation(thd) <= ISO_READ_COMMITTED)
{
// For READ_COMMITTED, we release any existing snapshot so that we will
// see any changes that occurred since the last statement。
tx->release_snapshot();
}
- 隔离级别实现差异
在read committed隔离级别下,如果一个大事务要更新1000w行,当它更新了前900w行时,
同时另一个事务已经更新了后100w行,那么myrocks会重新获取快照,再次尝试更新,这样 更新的是新提交的数据,也符合read committed逻辑。具体的讨论可以参考最近的issue#340. 而之前的处理方式是直接报死锁错误。
rocksdb::Status ha_rocksdb::get_for_update(
Rdb_transaction* tx,
rocksdb::ColumnFamilyHandle* column_family,
const rocksdb::Slice& key,
std::string* value) const
{
rocksdb::Status s= tx->get_for_update(column_family, key, value);
// If we have a lock conflict and we are running in READ COMMITTTED mode
// release and reacquire the snapshot and then retry the get_for_update().
if (s.IsBusy() && my_core::thd_tx_isolation(ha_thd()) == ISO_READ_COMMITTED)
{
tx->release_snapshot();
tx->acquire_snapshot(false);
s= tx->get_for_update(column_family, key, value);
}
return s;
}
innodb不会出现上述情况,当第一个大事更新是会持有b树的index lock, 第二个事务会一直等待index lock直至第一个事务提交完成。
锁
myrocks目前只支持一种锁类型:排他锁(X锁),并且所有的锁信息都保存在内存中。
- 锁结构
每个锁实际上存储的哪条记录被哪个事务锁住。
struct LockInfo {
TransactionID txn_id;
// Transaction locks are not valid after this time in us
uint64_t expiration_time;
......
}
每个锁实际是key和LockInfo的映射。 锁信息都保存在map中
struct LockMapStripe {
std::unordered_map<std::string, LockInfo> keys;
......
}
为了减少全局锁信息访问的冲突, rocksdb将锁信息进行按key hash分区,
struct LockMap {
std::vector<LockMapStripe*> lock_map_stripes_;
}
同时每个column family 存储一个这样的LockMap。
using LockMaps = std::unordered_map<uint32_t, std::shared_ptr<LockMap>>;
LockMaps lock_maps_;
锁相关参数:
max_num_locks:事务锁个数限制
expiration:事务过期时间
通过设置以上两个参数,来控制事务锁占用过多的内存。
- 死锁检测
rocksdb内部实现了简单的死锁检测机制,每次加锁发生等待时都会向下面的map中插入一条等待信息,表示一个事务id等待另一个事务id。 同时会检查wait_txn_map_是否存在等待环路,存在环路则发生死锁。
std::unordered_map<TransactionID, TransactionID> wait_txn_map_;
死锁检测关键代码片段
TransactionLockMgr::IncrementWaiters:
for (int i = 0; i < txn->GetDeadlockDetectDepth(); i++) {
if (next == id) {
DecrementWaitersImpl(txn, wait_id);
return true;
} else if (wait_txn_map_.count(next) == 0) {
return false;
} else {
next = wait_txn_map_[next];
}
}
死锁检测相关参数
deadlock_detect:是否开启死锁检测
deadlock_detect_depth:死锁检查深度,默认50
- gap lock
innodb中是存在gap lock的,主要是为了实现repeatable read和唯一性检查的。 而在rocksdb中,不支持gap lock(rocksdb insert是也会多对唯一键加锁,以防止重复插入, 严格的来讲也算是gap lock)。
那么在rocksdb一些需要gap lock的地方,目前是报错和打印日志来处理的。
相关参数
gap_lock_write_log: 只打印日志,不返回错误
gap_lock_raise_error: 打印日志并且返回错误
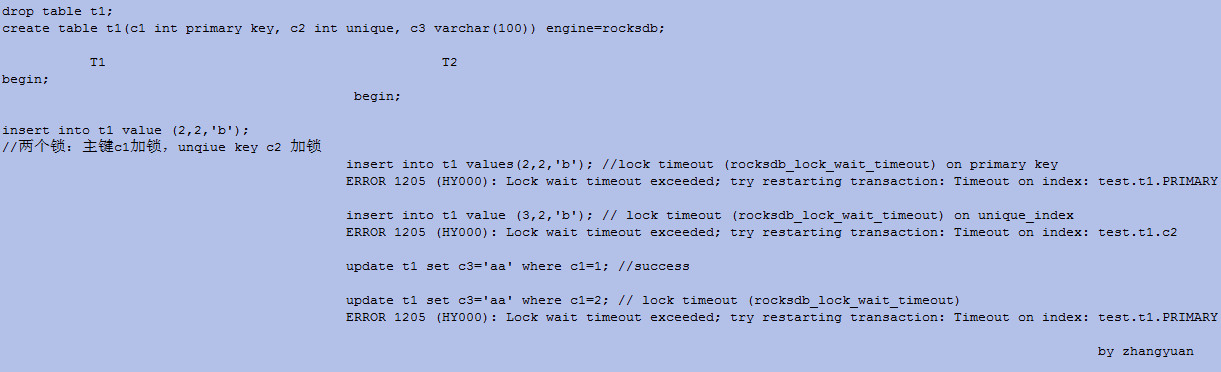
- 锁示例
直接看例子
binlog XA & 2pc
myrocks最近也支持了binlog xa。 在开启binlog的情况下,myrocks提交时,会经历两阶段提交阶段。 prepare阶段,根据server层生成的xid(由MySQLXid+server_id+qurey_id组成),在rockdb内部执行2pc操作,生成Prepare(xid),EndPrepare()记录。 commit阶段,根据事务成还是失败,生成Commit(xid)或Rollback(xid)记录。
rocksdb 2pc参考这里
总结
myrocks在事务处理方面还有些不完善的地方,比如锁类型只有单一的X锁,不支持gap lock,纯内存锁占用内存等。 myrocks社区正在持续改进中,一起期待。