PgSQL · 特性分析 · PostgreSQL 9.6 让多核并行起来
Author: digoal
背景
经过多年的酝酿(从支持work process到支持动态fork共享内存,再到内核层面支持并行计算),PostgreSQL 的多核并行计算功能终于在2016年发布的9.6版本中正式上线,为PG的scale up能力再次拔高一个台阶,标志着开源数据库已经攻克了并行计算的难题。
相信有很多小伙伴已经开始测试了。
在32物理核的机器上进行了测试,重计算的场景,性能程线性提升。
目前并行计算支持全表扫描,JOIN,聚合。
一、快速安装PostgreSQL 9.6
为了让大伙能够快速用上9.6,以下是一个简单的安装说明。
OS 准备
# yum -y install coreutils glib2 lrzsz sysstat e4fsprogs xfsprogs ntp readline-devel zlib zlib-devel openssl openssl-devel pam-devel libxml2-devel libxslt-devel python-devel tcl-devel gcc make smartmontools flex bison perl perl-devel perl-ExtUtils* openldap openldap-devel
# vi /etc/sysctl.conf
# add by digoal.zhou
fs.aio-max-nr = 1048576
fs.file-max = 76724600
kernel.core_pattern= /data01/corefiles/core_%e_%u_%t_%s.%p
# /data01/corefiles事先建好,权限777
kernel.sem = 4096 2147483647 2147483646 512000
# 信号量, ipcs -l 或 -u 查看,每16个进程一组,每组信号量需要17个信号量。
kernel.shmall = 107374182
# 所有共享内存段相加大小限制(建议内存的80%)
kernel.shmmax = 274877906944
# 最大单个共享内存段大小(建议为内存一半), >9.2的版本已大幅降低共享内存的使用
kernel.shmmni = 819200
# 一共能生成多少共享内存段,每个PG数据库集群至少2个共享内存段
net.core.netdev_max_backlog = 10000
net.core.rmem_default = 262144
# The default setting of the socket receive buffer in bytes.
net.core.rmem_max = 4194304
# The maximum receive socket buffer size in bytes
net.core.wmem_default = 262144
# The default setting (in bytes) of the socket send buffer.
net.core.wmem_max = 4194304
# The maximum send socket buffer size in bytes.
net.core.somaxconn = 4096
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_keepalive_intvl = 20
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 60
net.ipv4.tcp_mem = 8388608 12582912 16777216
net.ipv4.tcp_fin_timeout = 5
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syncookies = 1
# 开启SYN Cookies。当出现SYN等待队列溢出时,启用cookie来处理,可防范少量的SYN攻击
net.ipv4.tcp_timestamps = 1
# 减少time_wait
net.ipv4.tcp_tw_recycle = 0
# 如果=1则开启TCP连接中TIME-WAIT套接字的快速回收,但是NAT环境可能导致连接失败,建议服务端关闭它
net.ipv4.tcp_tw_reuse = 1
# 开启重用。允许将TIME-WAIT套接字重新用于新的TCP连接
net.ipv4.tcp_max_tw_buckets = 262144
net.ipv4.tcp_rmem = 8192 87380 16777216
net.ipv4.tcp_wmem = 8192 65536 16777216
net.nf_conntrack_max = 1200000
net.netfilter.nf_conntrack_max = 1200000
vm.dirty_background_bytes = 409600000
# 系统脏页到达这个值,系统后台刷脏页调度进程 pdflush(或其他) 自动将(dirty_expire_centisecs/100)秒前的脏页刷到磁盘
vm.dirty_expire_centisecs = 3000
# 比这个值老的脏页,将被刷到磁盘。3000表示30秒。
vm.dirty_ratio = 95
# 如果系统进程刷脏页太慢,使得系统脏页超过内存 95 % 时,则用户进程如果有写磁盘的操作(如fsync, fdatasync等调用),则需要主动把系统脏页刷出。
# 有效防止用户进程刷脏页,在单机多实例,并且使用CGROUP限制单实例IOPS的情况下非常有效。
vm.dirty_writeback_centisecs = 100
# pdflush(或其他)后台刷脏页进程的唤醒间隔, 100表示1秒。
vm.extra_free_kbytes = 4096000
vm.min_free_kbytes = 2097152
vm.mmap_min_addr = 65536
vm.overcommit_memory = 0
# 在分配内存时,允许少量over malloc, 如果设置为 1, 则认为总是有足够的内存,内存较少的测试环境可以使用 1 .
vm.overcommit_ratio = 90
# 当overcommit_memory = 2 时,用于参与计算允许指派的内存大小。
vm.swappiness = 0
# 关闭交换分区
vm.zone_reclaim_mode = 0
# 禁用 numa, 或者在vmlinux中禁止.
net.ipv4.ip_local_port_range = 40000 65535
# 本地自动分配的TCP, UDP端口号范围
# vm.nr_hugepages = 102352
# 建议shared buffer设置超过64GB时 使用大页,页大小 /proc/meminfo Hugepagesize
# sysctl -p
# vi /etc/security/limits.conf
* soft nofile 1024000
* hard nofile 1024000
* soft nproc unlimited
* hard nproc unlimited
* soft core unlimited
* hard core unlimited
* soft memlock unlimited
* hard memlock unlimited
# rm -f /etc/security/limits.d/*
安装
$ wget https://ftp.postgresql.org/pub/source/v9.6.0/postgresql-9.6.0.tar.bz2
$ tar -jxvf postgresql-9.6.0.tar.bz2
$ cd postgresql-9.6.0
$ ./configure --prefix=/home/digoal/pgsql9.6.0
$ make world -j 32
$ make install-world -j 32
$ vi ~/.bash_profile
export PS1="$USER@`/bin/hostname -s`-> "
export PGPORT=5281
export PGDATA=/u02/digoal/pg_root$PGPORT
export LANG=en_US.utf8
export PGHOME=/home/digoal/pgsql9.6.0
export LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/lib:$LD_LIBRARY_PATH
export DATE=`date +"%Y%m%d%H%M"`
export PATH=$PGHOME/bin:$PATH:.
export MANPATH=$PGHOME/share/man:$MANPATH
export PGHOST=$PGDATA
export PGUSER=postgres
export PGDATABASE=postgres
alias rm='rm -i'
alias ll='ls -lh'
unalias vi
$ . ~/.bash_profile
$ df -h
/dev/mapper/vgdata01-lv03
4.0T 1.3T 2.8T 32% /u01
/dev/mapper/vgdata01-lv04
7.7T 899G 6.8T 12% /u02
初始化集群
$ initdb -D $PGDATA -E UTF8 --locale=C -U postgres -X /u01/digoal/pg_xlog$PGPORT
配置数据库参数
$ cd $PGDATA
$ vi postgresql.conf
listen_addresses = '0.0.0.0'
port = 5281
max_connections = 800
superuser_reserved_connections = 13
unix_socket_directories = '.'
unix_socket_permissions = 0700
tcp_keepalives_idle = 60
tcp_keepalives_interval = 10
tcp_keepalives_count = 10
shared_buffers = 128GB
huge_pages = try
maintenance_work_mem = 2GB
dynamic_shared_memory_type = sysv
vacuum_cost_delay = 0
bgwriter_delay = 10ms
bgwriter_lru_maxpages = 1000
bgwriter_lru_multiplier = 10.0
bgwriter_flush_after = 256
max_worker_processes = 128
max_parallel_workers_per_gather = 16
old_snapshot_threshold = 8h
backend_flush_after = 256
synchronous_commit = off
full_page_writes = off
wal_buffers = 128MB
wal_writer_delay = 10ms
wal_writer_flush_after = 4MB
checkpoint_timeout = 55min
max_wal_size = 256GB
checkpoint_flush_after = 1MB
random_page_cost = 1.0
effective_cache_size = 512GB
constraint_exclusion = on
log_destination = 'csvlog'
logging_collector = on
log_checkpoints = on
log_connections = on
log_disconnections = on
log_error_verbosity = verbose
log_timezone = 'PRC'
autovacuum = on
log_autovacuum_min_duration = 0
autovacuum_max_workers = 8
autovacuum_naptime = 10s
autovacuum_vacuum_scale_factor = 0.02
autovacuum_analyze_scale_factor = 0.01
statement_timeout = 0
lock_timeout = 0
idle_in_transaction_session_timeout = 0
gin_fuzzy_search_limit = 0
gin_pending_list_limit = 4MB
datestyle = 'iso, mdy'
timezone = 'PRC'
lc_messages = 'C'
lc_monetary = 'C'
lc_numeric = 'C'
lc_time = 'C'
default_text_search_config = 'pg_catalog.english'
deadlock_timeout = 1s
$ vi pg_hba.conf
local all all trust
host all all 127.0.0.1/32 trust
host all all ::1/128 trust
host all all 0.0.0.0/0 md5
启动数据库
$ pg_ctl start
二、多核并行计算相关参数与用法
1. 控制整个数据库集群同时能开启多少个work process,必须设置。
max_worker_processes = 128 # (change requires restart)
2. 控制一个并行的EXEC NODE最多能开启多少个并行处理单元,同时还需要参考表级参数parallel_workers,或者PG内核内置的算法,根据表的大小计算需要开启多少和并行处理单元。
实际取小的。
max_parallel_workers_per_gather = 16 # taken from max_worker_processes
3. 计算并行处理的成本,如果成本高于非并行,则不会开启并行处理。
#parallel_tuple_cost = 0.1 # same scale as above
#parallel_setup_cost = 1000.0 # same scale as above
4. 小于这个值的表,不会开启并行。
#min_parallel_relation_size = 8MB
5. 告诉优化器,强制开启并行。
#force_parallel_mode = off
6. 表级参数,不通过表的大小计算并行度,而是直接告诉优化器这个表需要开启多少个并行计算单元。
parallel_workers (integer)
This sets the number of workers that should be used to assist a parallel scan of this table.
If not set, the system will determine a value based on the relation size.
The actual number of workers chosen by the planner may be less, for example due to the setting of max_worker_processes.
三、测试场景描述
在标签系统中,通常会有多个属性,每个属性使用一个标签标示,最简单的标签是用0和1来表示,代表true和false。
我们可以把所有的标签转换成比特位,例如系统中一共有200个标签,5000万用户。
那么我们可以通过标签的位运算来圈定特定的人群。
这样就会涉及BIT位的运算。
那么我们来看看PostgreSQL位运算的性能如何?
四、测试1 (数据量大于shared buffer)
创建一张测试表,包含一个比特位字段,后面用于测试。
postgres=# create unlogged table t_bit2 (id bit(200)) with (autovacuum_enabled=off, parallel_workers=128);
CREATE TABLE
并行插入32亿记录
for ((i=1;i<=64;i++)) ; do psql -c "insert into t_bit2 select B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010' from generate_series(1,50000000);" & done
单表32亿,180GB
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------+-------+----------+--------+-------------
public | t_bit2 | table | postgres | 180 GB |
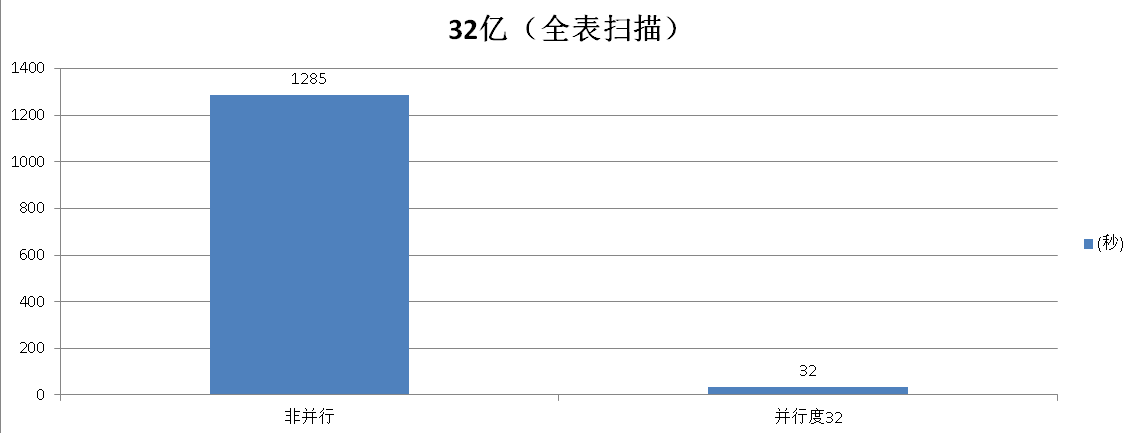
全表扫描测试
非并行模式
postgres=# set force_parallel_mode =off;
SET
postgres=# set max_parallel_workers_per_gather =0;
SET
postgres=# \timing
Timing is on.
执行计划
postgres=# explain (verbose,costs) select * from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
QUERY PLAN
Seq Scan on public.t_bit2 (cost=0.00..71529415.52 rows=16000001 width=32)
Output: id
Filter: (bitand(t_bit2.id, B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010'::"bit") = B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011'::"bit")
(3 rows)
取测试三轮后的结果,排除CACHE影响。
postgres=# explain (analyze,verbose,costs) select * from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
Seq Scan on public.t_bit2 (cost=0.00..71529415.52 rows=16000001 width=32) (actual time=0.033..1135403.694 rows=3200000000 loops=1)
Output: id
Filter: (bitand(t_bit2.id, B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010'::"bit") = B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011'::"bit")
Planning time: 0.576 ms
Execution time: 1285437.199 ms
(5 rows)
Time: 1285438.195 ms
并行模式
postgres=# set force_parallel_mode =on;
postgres=# set max_parallel_workers_per_gather = 64;
取测试三轮后的结果,排除CACHE影响。
postgres=# explain (analyze,verbose,costs) select * from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
Gather (cost=1000.00..26630413.18 rows=16000001 width=32) (actual time=30946.103..30946.103 rows=0 loops=1)
Output: id
Workers Planned: 32
Workers Launched: 32
-> Parallel Seq Scan on public.t_bit2 (cost=0.00..25029413.08 rows=500000 width=32) (actual time=30941.191..30941.191 rows=0 loops=33)
Output: id
Filter: (bitand(t_bit2.id, B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010'::"bit") = B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011'::"bit")
Rows Removed by Filter: 96969697
Worker 0: actual time=30938.594..30938.594 rows=0 loops=1
Worker 1: actual time=30939.353..30939.353 rows=0 loops=1
Worker 2: actual time=30939.419..30939.419 rows=0 loops=1
Worker 3: actual time=30939.574..30939.574 rows=0 loops=1
Worker 4: actual time=30939.692..30939.692 rows=0 loops=1
Worker 5: actual time=30939.825..30939.825 rows=0 loops=1
Worker 6: actual time=30939.850..30939.850 rows=0 loops=1
Worker 7: actual time=30940.028..30940.028 rows=0 loops=1
Worker 8: actual time=30940.287..30940.287 rows=0 loops=1
Worker 9: actual time=30940.466..30940.466 rows=0 loops=1
Worker 10: actual time=30940.436..30940.436 rows=0 loops=1
Worker 11: actual time=30940.649..30940.649 rows=0 loops=1
Worker 12: actual time=30940.733..30940.733 rows=0 loops=1
Worker 13: actual time=30940.818..30940.818 rows=0 loops=1
Worker 14: actual time=30941.083..30941.083 rows=0 loops=1
Worker 15: actual time=30941.086..30941.086 rows=0 loops=1
Worker 16: actual time=30940.612..30940.612 rows=0 loops=1
Worker 17: actual time=30941.342..30941.342 rows=0 loops=1
Worker 18: actual time=30941.617..30941.617 rows=0 loops=1
Worker 19: actual time=30941.667..30941.667 rows=0 loops=1
Worker 20: actual time=30941.730..30941.730 rows=0 loops=1
Worker 21: actual time=30941.207..30941.207 rows=0 loops=1
Worker 22: actual time=30942.115..30942.115 rows=0 loops=1
Worker 23: actual time=30942.049..30942.049 rows=0 loops=1
Worker 24: actual time=30941.440..30941.440 rows=0 loops=1
Worker 25: actual time=30942.361..30942.361 rows=0 loops=1
Worker 26: actual time=30942.562..30942.562 rows=0 loops=1
Worker 27: actual time=30942.430..30942.430 rows=0 loops=1
Worker 28: actual time=30942.697..30942.697 rows=0 loops=1
Worker 29: actual time=30942.577..30942.577 rows=0 loops=1
Worker 30: actual time=30942.985..30942.985 rows=0 loops=1
Worker 31: actual time=30942.356..30942.356 rows=0 loops=1
Planning time: 0.061 ms
Execution time: 32566.303 ms
(42 rows)
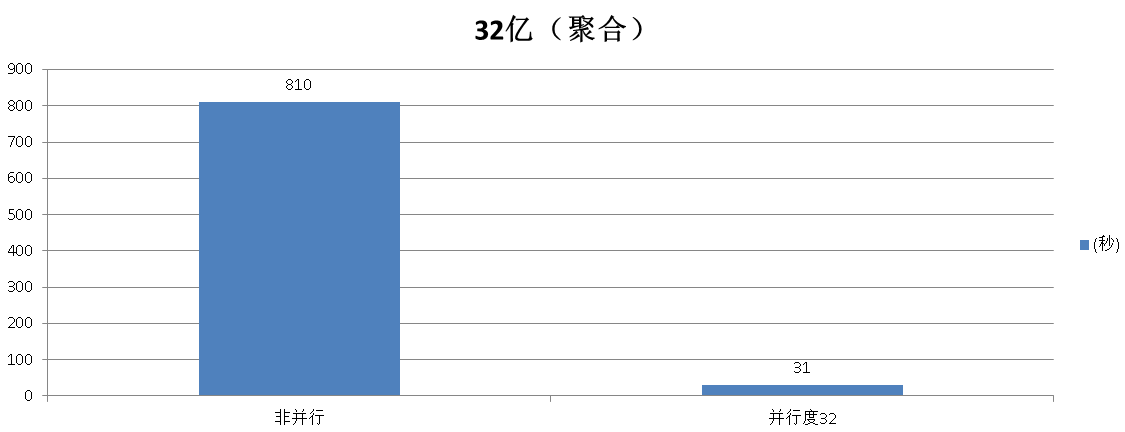
聚合测试
非并行模式
postgres=# set force_parallel_mode =off;
postgres=# set max_parallel_workers_per_gather = 0;
postgres=# select count(*) from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
count
-------
0
(1 row)
Time: 810115.643 ms
并行模式
postgres=# set force_parallel_mode =on;
postgres=# set max_parallel_workers_per_gather = 32;
postgres=# select count(*) from t_bit2 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
count
-------
0
(1 row)
Time: 31805.820 ms
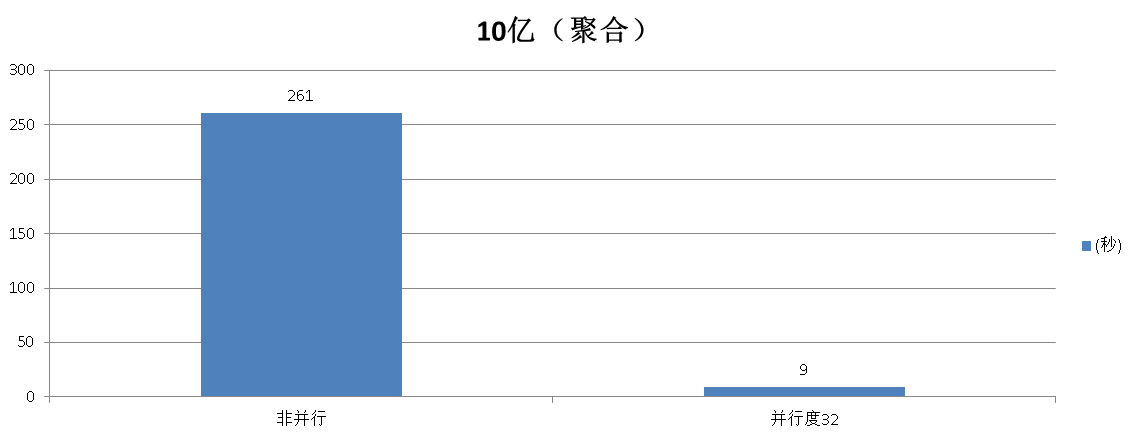
五、测试2 (数据量小于shared buffer)
创建一张测试表,包含一个比特位字段,后面用于测试。
postgres=# create unlogged table t_bit1 (id bit(200)) with (autovacuum_enabled=off, parallel_workers=128);
CREATE TABLE
并行插入10亿记录
for ((i=1;i<=50;i++)) ; do psql -c "insert into t_bit1 select B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010' from generate_series(1,20000000);" & done
单表10亿,56GB
postgres=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------+-------+----------+--------+-------------
public | t_bit1 | table | postgres | 56 GB |
聚合测试
非并行模式
postgres=# set force_parallel_mode =off;
postgres=# set max_parallel_workers_per_gather = 0;
postgres=# select count(*) from t_bit1 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
Time: 261679.060 ms
并行模式
postgres=# set force_parallel_mode = on;
postgres=# set max_parallel_workers_per_gather = 32;
postgres=# select count(*) from t_bit1 where bitand(id, '10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010')=B'10101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101010101011';
Time: 9704.983 ms
hash JOIN测试
1亿 JOIN 5000万
create unlogged table t1(id int, info text) with (autovacuum_enabled=off, parallel_workers=128);
create unlogged table t2(id int, info text) with (autovacuum_enabled=off, parallel_workers=128);
insert into t1 select generate_series(1,100000000);
insert into t2 select generate_series(1,50000000);
非并行模式
postgres=# set force_parallel_mode =off;
postgres=# set max_parallel_workers_per_gather = 0;
postgres=# set enable_merjoin=off;
postgres=# explain verbose select count(*) from t1 join t2 using(id);
QUERY PLAN
---------------------------------------------------------------------------------------
Aggregate (cost=296050602904.73..296050602904.74 rows=1 width=8)
Output: count(*)
-> Hash Join (cost=963185.44..276314071764.57 rows=7894612456066 width=0)
Hash Cond: (t1.id = t2.id)
-> Seq Scan on public.t1 (cost=0.00..1004425.06 rows=56194706 width=4)
Output: t1.id
-> Hash (cost=502212.53..502212.53 rows=28097353 width=4)
Output: t2.id
-> Seq Scan on public.t2 (cost=0.00..502212.53 rows=28097353 width=4)
Output: t2.id
(10 rows)
postgres=# select count(*) from t1 join t2 using(id);
count
----------
50000000
(1 row)
Time: 60630.148 ms
并行模式
postgres=# set force_parallel_mode = on;
postgres=# set max_parallel_workers_per_gather = 32;
postgres=# explain verbose select count(*) from t1 join t2 using(id);
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=28372817100.45..28372817100.46 rows=1 width=8)
Output: count(*)
-> Gather (cost=28372817097.16..28372817100.37 rows=32 width=8)
Output: (PARTIAL count(*))
Workers Planned: 32
-> Partial Aggregate (cost=28372816097.16..28372816097.17 rows=1 width=8)
Output: PARTIAL count(*)
-> Hash Join (cost=963185.44..8636284956.99 rows=7894612456066 width=0)
Hash Cond: (t1.id = t2.id)
-> Parallel Seq Scan on public.t1 (cost=0.00..460038.85 rows=1756085 width=4)
Output: t1.id
-> Hash (cost=502212.53..502212.53 rows=28097353 width=4)
Output: t2.id
-> Seq Scan on public.t2 (cost=0.00..502212.53 rows=28097353 width=4)
Output: t2.id
(15 rows)
select count(*) from t1 join t2 using(id);
Execution time: 50958.985 ms
postgres=# set max_parallel_workers_per_gather = 4;
select count(*) from t1 join t2 using(id);
Time: 39386.647 ms
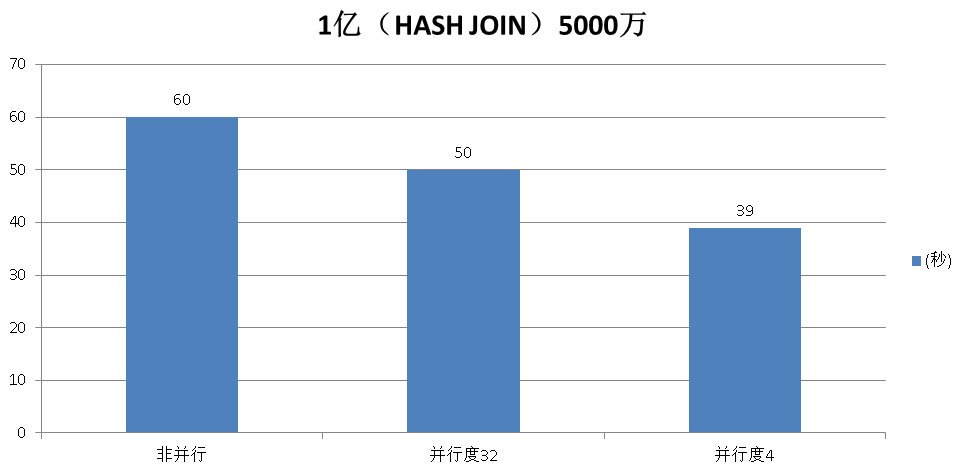
建议JOIN不要设置太大的并行度。
六、如何设置并行度以及源码分析
GUC变量
1. 控制整个数据库集群同时能开启多少个work process,必须设置。
max_worker_processes = 128 # (change requires restart)
2. 控制一个并行的EXEC NODE最多能开启多少个并行处理单元,同时还需要参考表级参数parallel_workers,或者PG内核内置的算法,根据表的大小计算需要开启多少和并行处理单元。
实际取小的。
max_parallel_workers_per_gather = 16 # taken from max_worker_processes
如果同时还设置了表的并行度parallel_workers,则最终并行度取min(max_parallel_degree , parallel_degree )
/*
* Use the table parallel_degree, but don't go further than
* max_parallel_degree.
*/
parallel_degree = Min(rel->rel_parallel_degree, max_parallel_degree);
如果表没有设置并行度parallel_workers ,则根据表的大小 和 parallel_threshold 这个硬编码值决定,计算得出(见函数create_plain_partial_paths)
依旧受到max_parallel_workers_per_gather 参数的限制,不能大于它,取小的,前面已经交代了。
代码如下(release后可能有些许修改)
src/backend/optimizer/util/plancat.c
void
get_relation_info(PlannerInfo *root, Oid relationObjectId, bool inhparent,
RelOptInfo *rel)
{
...
/* Retrive the parallel_degree reloption, if set. */
rel->rel_parallel_degree = RelationGetParallelDegree(relation, -1);
...
src/include/utils/rel.h
/*
* RelationGetParallelDegree
* Returns the relation's parallel_degree. Note multiple eval of argument!
*/
#define RelationGetParallelDegree(relation, defaultpd) \
((relation)->rd_options ? \
((StdRdOptions *) (relation)->rd_options)->parallel_degree : (defaultpd))
src/backend/optimizer/path/allpaths.c
/*
* create_plain_partial_paths
* Build partial access paths for parallel scan of a plain relation
*/
static void
create_plain_partial_paths(PlannerInfo *root, RelOptInfo *rel)
{
int parallel_degree = 1;
/*
* If the user has set the parallel_degree reloption, we decide what to do
* based on the value of that option. Otherwise, we estimate a value.
*/
if (rel->rel_parallel_degree != -1)
{
/*
* If parallel_degree = 0 is set for this relation, bail out. The
* user does not want a parallel path for this relation.
*/
if (rel->rel_parallel_degree == 0)
return;
/*
* Use the table parallel_degree, but don't go further than
* max_parallel_degree.
*/
parallel_degree = Min(rel->rel_parallel_degree, max_parallel_degree);
}
else
{
int parallel_threshold = 1000;
/*
* If this relation is too small to be worth a parallel scan, just
* return without doing anything ... unless it's an inheritance child.
* In that case, we want to generate a parallel path here anyway. It
* might not be worthwhile just for this relation, but when combined
* with all of its inheritance siblings it may well pay off.
*/
if (rel->pages < parallel_threshold &&
rel->reloptkind == RELOPT_BASEREL)
return;
// 表级并行度没有设置时,通过表的大小和parallel_threshold 计算并行度
/*
* Limit the degree of parallelism logarithmically based on the size
* of the relation. This probably needs to be a good deal more
* sophisticated, but we need something here for now.
*/
while (rel->pages > parallel_threshold * 3 &&
parallel_degree < max_parallel_degree)
{
parallel_degree++;
parallel_threshold *= 3;
if (parallel_threshold >= PG_INT32_MAX / 3)
break;
}
}
/* Add an unordered partial path based on a parallel sequential scan. */
add_partial_path(rel, create_seqscan_path(root, rel, NULL, parallel_degree));
}
3. 计算并行处理的成本,如果成本高于非并行,则不会开启并行处理。
#parallel_tuple_cost = 0.1 # same scale as above
#parallel_setup_cost = 1000.0 # same scale as above
4. 小于这个值的表,不会开启并行。
#min_parallel_relation_size = 8MB
5. 告诉优化器,强制开启并行。
#force_parallel_mode = off
表级参数
6. 不通过表的大小计算并行度,而是直接告诉优化器这个表需要开启多少个并行计算单元。
parallel_workers (integer)
This sets the number of workers that should be used to assist a parallel scan of this table.
If not set, the system will determine a value based on the relation size.
The actual number of workers chosen by the planner may be less, for example due to the setting of max_worker_processes.
七、参考信息
1. http://www.postgresql.org/docs/9.6/static/sql-createtable.html
parallel_workers (integer)
This sets the number of workers that should be used to assist a parallel scan of this table.
If not set, the system will determine a value based on the relation size.
The actual number of workers chosen by the planner may be less, for example due to the setting of max_worker_processes.
2. http://www.postgresql.org/docs/9.6/static/runtime-config-query.html#RUNTIME-CONFIG-QUERY-OTHER
force_parallel_mode (enum)
Allows the use of parallel queries for testing purposes even in cases where no performance benefit is expected.
The allowed values of force_parallel_mode are off (use parallel mode only when it is expected to improve performance),
on (force parallel query for all queries for which it is thought to be safe),
and regress (like on, but with additional behavior changes as explained below).
More specifically, setting this value to on will add a Gather node to the top of any query plan for which this appears to be safe,
so that the query runs inside of a parallel worker. Even when a parallel worker is not available or cannot be used,
operations such as starting a subtransaction that would be prohibited in a parallel query context will be prohibited unless the planner believes that this will cause the query to fail.
If failures or unexpected results occur when this option is set, some functions used by the query may need to be marked PARALLEL UNSAFE (or, possibly, PARALLEL RESTRICTED).
Setting this value to regress has all of the same effects as setting it to on plus some additional effects that are intended to facilitate automated regression testing. Normally,
messages from a parallel worker include a context line indicating that, but a setting of regress suppresses this line so that the output is the same as in non-parallel execution.
Also, the Gather nodes added to plans by this setting are hidden in EXPLAIN output so that the output matches what would be obtained if this setting were turned off.
3. http://www.postgresql.org/docs/9.6/static/runtime-config-resource.html#RUNTIME-CONFIG-RESOURCE-ASYNC-BEHAVIOR
max_worker_processes (integer)
Sets the maximum number of background processes that the system can support. This parameter can only be set at server start. The default is 8.
When running a standby server, you must set this parameter to the same or higher value than on the master server. Otherwise, queries will not be allowed in the standby server.
max_parallel_workers_per_gather (integer)
Sets the maximum number of workers that can be started by a single Gather node. Parallel workers are taken from the pool of processes established by max_worker_processes.
Note that the requested number of workers may not actually be available at run time. If this occurs, the plan will run with fewer workers than expected,
which may be inefficient. Setting this value to 0, which is the default, disables parallel query execution.
Note that parallel queries may consume very substantially more resources than non-parallel queries,
because each worker process is a completely separate process which has roughly the same impact on the system as an additional user session.
This should be taken into account when choosing a value for this setting, as well as when configuring other settings that control resource utilization, such as work_mem.
Resource limits such as work_mem are applied individually to each worker, which means the total utilization may be much higher across all processes than it would normally be for any single process.
For example, a parallel query using 4 workers may use up to 5 times as much CPU time, memory, I/O bandwidth, and so forth as a query which uses no workers at all.
For more information on parallel query, see Chapter 15.
4. http://www.postgresql.org/docs/9.6/static/runtime-config-query.html#RUNTIME-CONFIG-QUERY-CONSTANTS
parallel_setup_cost (floating point)
Sets the planner's estimate of the cost of launching parallel worker processes. The default is 1000.
parallel_tuple_cost (floating point)
Sets the planner's estimate of the cost of transferring one tuple from a parallel worker process to another process.
The default is 0.1.
min_parallel_relation_size (integer)
Sets the minimum size of relations to be considered for parallel scan. The default is 8 megabytes (8MB).
优化器选择并行计算的相关参数
PostgreSQL会通过这些参数来决定是否使用并行,以及该启用几个work process。
1. max_worker_processes (integer)
很显然,这个参数决定了整个数据库集群允许启动多少个work process,注意如果有standby,standby的参数必须大于等于主库的参数值。
如果设置为0,表示不允许并行。
Sets the maximum number of background processes that the system can support.
This parameter can only be set at server start.
The default is 8.
When running a standby server, you must set this parameter to the same or higher value than on the master server.
Otherwise, queries will not be allowed in the standby server.
2. max_parallel_workers_per_gather (integer)
这个参数决定了每个Gather node最多允许启用多少个work process。
同时需要注意,在OLTP业务系统中,不要设置太大,因为每个worker都会消耗同等的work_mem等资源,争抢会比较厉害。
建议在OLAP中使用并行,并且做好任务调度,减轻冲突。
Sets the maximum number of workers that can be started by a single Gather node.
Parallel workers are taken from the pool of processes established by max_worker_processes.
Note that the requested number of workers may not actually be available at run time. -- 因为work process可能被使用了一些,整个系统还能开启的work process=max_worker_processes减去已使用的。
If this occurs, the plan will run with fewer workers than expected, which may be inefficient.
The default value is 2.
Setting this value to 0 disables parallel query execution.
Note that parallel queries may consume very substantially more resources than non-parallel queries, because each worker process is a completely separate process which has roughly the same impact on the system as an additional user session.
This should be taken into account when choosing a value for this setting, as well as when configuring other settings that control resource utilization, such as work_mem.
Resource limits such as work_mem are applied individually to each worker, which means the total utilization may be much higher across all processes than it would normally be for any single process.
For example, a parallel query using 4 workers may use up to 5 times as much CPU time, memory, I/O bandwidth, and so forth as a query which uses no workers at all.
例子,WITH语法中,有两个QUERY用来并行计算,虽然设置的max_parallel_workers_per_gather=6,但是由于max_worker_processes=8,所以第一个Gather node用了6个worker process,而另一个Gather实际上只用了2个worker。
postgres=# show max_worker_processes ;
max_worker_processes
----------------------
8
(1 row)
postgres=# set max_parallel_workers_per_gather=6;
SET
postgres=# explain (analyze,verbose,costs,timing,buffers) with t as (select count(*) from test), t1 as (select count(id) from test) select * from t,t1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=159471.81..159471.86 rows=1 width=16) (actual time=7763.033..7763.036 rows=1 loops=1)
Output: t.count, t1.count
Buffers: shared hit=32940 read=74784
CTE t
-> Finalize Aggregate (cost=79735.90..79735.91 rows=1 width=8) (actual time=4714.114..4714.115 rows=1 loops=1)
Output: count(*)
Buffers: shared hit=16564 read=37456
-> Gather (cost=79735.27..79735.88 rows=6 width=8) (actual time=4714.016..4714.102 rows=7 loops=1)
Output: (PARTIAL count(*))
Workers Planned: 6
Workers Launched: 6
Buffers: shared hit=16564 read=37456
-> Partial Aggregate (cost=78735.27..78735.28 rows=1 width=8) (actual time=4709.465..4709.466 rows=1 loops=7)
Output: PARTIAL count(*)
Buffers: shared hit=16084 read=37456
Worker 0: actual time=4709.146..4709.146 rows=1 loops=1
Buffers: shared hit=2167 read=5350
Worker 1: actual time=4708.156..4708.156 rows=1 loops=1
Buffers: shared hit=2140 read=5288
Worker 2: actual time=4708.370..4708.370 rows=1 loops=1
Buffers: shared hit=2165 read=4990
Worker 3: actual time=4708.968..4708.969 rows=1 loops=1
Buffers: shared hit=2501 read=5529
Worker 4: actual time=4709.194..4709.195 rows=1 loops=1
Buffers: shared hit=2469 read=5473
Worker 5: actual time=4708.812..4708.813 rows=1 loops=1
Buffers: shared hit=2155 read=5349
-> Parallel Seq Scan on public.test (cost=0.00..73696.22 rows=2015622 width=0) (actual time=0.051..2384.380 rows=1728571 loops=7)
Buffers: shared hit=16084 read=37456
Worker 0: actual time=0.046..2385.108 rows=1698802 loops=1
Buffers: shared hit=2167 read=5350
Worker 1: actual time=0.057..2384.698 rows=1678728 loops=1
Buffers: shared hit=2140 read=5288
Worker 2: actual time=0.061..2384.109 rows=1617030 loops=1
Buffers: shared hit=2165 read=4990
Worker 3: actual time=0.046..2387.143 rows=1814780 loops=1
Buffers: shared hit=2501 read=5529
Worker 4: actual time=0.046..2382.491 rows=1794892 loops=1
Buffers: shared hit=2469 read=5473
Worker 5: actual time=0.070..2383.598 rows=1695904 loops=1
Buffers: shared hit=2155 read=5349
CTE t1
-> Finalize Aggregate (cost=79735.90..79735.91 rows=1 width=8) (actual time=3048.902..3048.902 rows=1 loops=1)
Output: count(test_1.id)
Buffers: shared hit=16376 read=37328
-> Gather (cost=79735.27..79735.88 rows=6 width=8) (actual time=3048.732..3048.880 rows=3 loops=1)
Output: (PARTIAL count(test_1.id))
Workers Planned: 6
Workers Launched: 2
Buffers: shared hit=16376 read=37328
-> Partial Aggregate (cost=78735.27..78735.28 rows=1 width=8) (actual time=3046.399..3046.400 rows=1 loops=3)
Output: PARTIAL count(test_1.id)
Buffers: shared hit=16212 read=37328
Worker 0: actual time=3045.394..3045.395 rows=1 loops=1
Buffers: shared hit=5352 read=12343
Worker 1: actual time=3045.339..3045.340 rows=1 loops=1
Buffers: shared hit=5354 read=12402
-> Parallel Seq Scan on public.test test_1 (cost=0.00..73696.22 rows=2015622 width=4) (actual time=0.189..1614.261 rows=4033333 loops=3)
Output: test_1.id
Buffers: shared hit=16212 read=37328
Worker 0: actual time=0.039..1617.258 rows=3999030 loops=1
Buffers: shared hit=5352 read=12343
Worker 1: actual time=0.033..1610.934 rows=4012856 loops=1
Buffers: shared hit=5354 read=12402
-> CTE Scan on t (cost=0.00..0.02 rows=1 width=8) (actual time=4714.120..4714.121 rows=1 loops=1)
Output: t.count
Buffers: shared hit=16564 read=37456
-> CTE Scan on t1 (cost=0.00..0.02 rows=1 width=8) (actual time=3048.907..3048.908 rows=1 loops=1)
Output: t1.count
Buffers: shared hit=16376 read=37328
Planning time: 0.144 ms
Execution time: 7766.458 ms
(72 rows)
3. parallel_setup_cost (floating point)
表示启动woker process的启动成本,因为启动worker进程需要建立共享内存等操作,属于附带的额外成本。
Sets the planner's estimate of the cost of launching parallel worker processes.
The default is 1000.
4. parallel_tuple_cost (floating point)
woker进程处理完后的tuple要传输给上层node,即进程间的row交换成本,按node评估的输出rows来乘。
Sets the planner's estimate of the cost of transferring one tuple from a parallel worker process to another process.
The default is 0.1.
代码如下
parallel_tuple_cost : Cost of CPU time to pass a tuple from worker to master backend
parallel_setup_cost : Cost of setting up shared memory for parallelism
//
double parallel_tuple_cost = DEFAULT_PARALLEL_TUPLE_COST;
double parallel_setup_cost = DEFAULT_PARALLEL_SETUP_COST;
//
/*
* cost_gather
* Determines and returns the cost of gather path.
*
* 'rel' is the relation to be operated upon
* 'param_info' is the ParamPathInfo if this is a parameterized path, else NULL
* 'rows' may be used to point to a row estimate; if non-NULL, it overrides
* both 'rel' and 'param_info'. This is useful when the path doesn't exactly
* correspond to any particular RelOptInfo.
*/
void
cost_gather(GatherPath *path, PlannerInfo *root,
RelOptInfo *rel, ParamPathInfo *param_info,
double *rows)
{
Cost startup_cost = 0;
Cost run_cost = 0;
//
/* Mark the path with the correct row estimate */
if (rows)
path->path.rows = *rows;
else if (param_info)
path->path.rows = param_info->ppi_rows;
else
path->path.rows = rel->rows;
//
startup_cost = path->subpath->startup_cost;
//
run_cost = path->subpath->total_cost - path->subpath->startup_cost;
//
/* Parallel setup and communication cost. */
startup_cost += parallel_setup_cost; // 累加启动成本
run_cost += parallel_tuple_cost * path->path.rows; // 累加tuple的worker与上层进程间传输成本
//
path->path.startup_cost = startup_cost;
path->path.total_cost = (startup_cost + run_cost);
}
5. min_parallel_relation_size (integer)
表的大小,也作为是否启用并行计算的条件,如果小于它,不启用并行计算。
但是也请注意,还有其他条件决定是否启用并行,所以并不是小于它的表就一定不会启用并行。
Sets the minimum size of relations to be considered for parallel scan.
The default is 8 megabytes (8MB).
代码如下
src/backend/optimizer/path/allpaths.c
/*
* create_plain_partial_paths
* Build partial access paths for parallel scan of a plain relation
*/
static void
create_plain_partial_paths(PlannerInfo *root, RelOptInfo *rel)
{
int parallel_workers;
//
/*
* If the user has set the parallel_workers reloption, use that; otherwise
* select a default number of workers.
*/
if (rel->rel_parallel_workers != -1) // 如果设置了表级的parallel_workers参数,则直接使用这个作为并行度。
parallel_workers = rel->rel_parallel_workers;
else // 如果没有设置表级并行度参数,则使用表的大小计算出一个合适的并行度
{
int parallel_threshold;
//
/*
* If this relation is too small to be worth a parallel scan, just
* return without doing anything ... unless it's an inheritance child.
* In that case, we want to generate a parallel path here anyway. It
* might not be worthwhile just for this relation, but when combined
* with all of its inheritance siblings it may well pay off.
*/
if (rel->pages < (BlockNumber) min_parallel_relation_size &&
rel->reloptkind == RELOPT_BASEREL) // 如果表的大小小于设置的min_parallel_relation_size(单位为block),不启用并行
return;
//
/*
* Select the number of workers based on the log of the size of the
* relation. This probably needs to be a good deal more
* sophisticated, but we need something here for now. Note that the
* upper limit of the min_parallel_relation_size GUC is chosen to
* prevent overflow here.
*/
// 以下算法目前还不完善,根据表的大小计算出需要开多大的并行。 算法如下
parallel_workers = 1;
parallel_threshold = Max(min_parallel_relation_size, 1);
while (rel->pages >= (BlockNumber) (parallel_threshold * 3))
{
parallel_workers++;
parallel_threshold *= 3;
if (parallel_threshold > INT_MAX / 3)
break; /* avoid overflow */
}
}
//
/*
* In no case use more than max_parallel_workers_per_gather workers.
*/
parallel_workers = Min(parallel_workers, max_parallel_workers_per_gather); // 根据计算出的并行度值,与max_parallel_workers_per_gather参数比较,取小的。 就是需要开启的并行度。
//
/* If any limit was set to zero, the user doesn't want a parallel scan. */
if (parallel_workers <= 0)
return;
//
/* Add an unordered partial path based on a parallel sequential scan. */
add_partial_path(rel, create_seqscan_path(root, rel, NULL, parallel_workers)); // 根据计算出来的并行度,添加execute worker path。
}
6. force_parallel_mode (enum)
强制开启并行,可以作为测试的目的,也可以作为hint来使用。
Allows the use of parallel queries for testing purposes even in cases where no performance benefit is expected.
The allowed values of force_parallel_mode are
off (use parallel mode only when it is expected to improve performance),
on (force parallel query for all queries for which it is thought to be safe),
regress (like on, but with additional behavior changes as explained below).
More specifically, setting this value to on will add a Gather node to the top of any query plan for which this appears to be safe, so that the query runs inside of a parallel worker.
Even when a parallel worker is not available or cannot be used, operations such as starting a subtransaction that would be prohibited in a parallel query context will be prohibited unless the planner believes that this will cause the query to fail.
If failures or unexpected results occur when this option is set, some functions used by the query may need to be marked PARALLEL UNSAFE (or, possibly, PARALLEL RESTRICTED).
Setting this value to regress has all of the same effects as setting it to on plus some additional effects that are intended to facilitate automated regression testing.
Normally, messages from a parallel worker include a context line indicating that, but a setting of regress suppresses this line so that the output is the same as in non-parallel execution.
Also, the Gather nodes added to plans by this setting are hidden in EXPLAIN output so that the output matches what would be obtained if this setting were turned off.
7. parallel_workers (integer)
以上都是数据库的参数,parallel_workers是表级参数,可以在建表时设置,也可以后期设置。
代码见create_plain_partial_paths()
create table ... WITH( storage parameter ... )
This sets the number of workers that should be used to assist a parallel scan of this table.
If not set, the system will determine a value based on the relation size.
The actual number of workers chosen by the planner may be less, for example due to the setting of max_worker_processes.
例子
设置表级并行度
alter table test set (parallel_workers=0);
关闭表的并行
alter table test set (parallel_workers=0);
重置参数,那么在create_plain_partial_paths中会通过表的pages计算出一个合理的并行度
alter table test reset (parallel_workers);
PG优化器如何决定使用并行或者如何计算并行度
其实前面在讲参数时都已经讲到了,这里再总结一下。
1. 决定整个系统能开多少个worker进程
max_worker_processes
2. 计算并行计算的成本,优化器根据CBO原则选择是否开启并行
parallel_setup_cost
parallel_tuple_cost
所以简单QUERY,如果COST本来就很低(比如小于并行计算的启动成本),那么很显然数据库不会对这种QUERY启用并行计算。
如果要强制并行,建议都设置为0.
3. 强制开启并行的开关
force_parallel_mode
当第二步计算出来的成本大于非并行的成本时,可以通过这种方式强制让优化器开启并行查询。
4. 根据表级parallel_workers参数决定每个Gather node的并行度
取min(parallel_workers, max_parallel_workers_per_gather)
5. 当表没有设置parallel_workers参数并且表的大小大于min_parallel_relation_size是,由算法决定每个Gather node的并行度
相关参数 min_parallel_relation_size
算法见 create_plain_partial_paths
取Min(parallel_workers, max_parallel_workers_per_gather)
注意实际上,每个Gather能开启多少个worker还和PG集群总体剩余可以开启的worker进程数相关。
因此实际开启的可能小于优化器算出来的。从前面的例子中也可以理解。
6. 用户也可以使用hint来控制优化器选择是否强制并行 , 参考pg_hint_plan插件的用法。