MSSQL · 最佳实战 · 巧用COLUMNS_UPDATED获取数据变更
Author: 风移
业务场景
在平时与数据库打交道的过程中,我们经常会有这样的疑惑:如何快速的获取数据变更记录呢?举个例子,搜索引擎要为外部客人提供快速准确的商品信息搜索功能,那么当有新的商品数据变更后,搜索引擎如何快速的发现这些新的变更数据呢?我们常见的两种做法:
全量更新
这种方法最为简单直接,反正不管三七二十一,搜索引擎每次全量拉取商品信息表所有数据,然后创建搜索索引,提供给外部客人查询。这种方法实现起来的确最为简单,当然同时也具有非常明显的缺点:
- 浪费资源: 假如商品的变更频率为20%,那么剩下的80%商品实际上是不需要更新的。换句话说全量更新会浪费掉80%的系统资源(IO/CPU/Memory)来做无用功。
- 耗时严重: 由于获取的是表的全量数据,所以全量更新大大增加了数据获取阶段和搜索索引生成阶段锁的概率,加之浪费资源做无用功,最终导致时间消耗大大拉长。
- 数据更新时效性差: 由于耗时严重,所以导致数据更新不及时,时效性差,随着商品量的不断扩大,这种时效性会越来越差,最终导致客户抱怨。
全量+增量更新
针对全量更新的种种“罪行”,我们可以有针对性的采用全量+增量更新的方式来有效解决。这种方法的思路是,我们可以周期性的做全量更新,比如每天或者每周,然后在两个全量更新周期之间,我们采用增量更新的方式来覆盖新的数据变更,比如每小时或者每分钟。增量更新问题的关键在于如何获取数据变更记录,让我们来看看关系型数据库MSSQL Server是如何提供解决方法的。
MSSQL获取数据变更
MSSQL Server提供了一个函数,名为COLUMNS_UPDATED可以解决这个问题。先让我们来看看微软官方的解释:返回 varbinary 位模式,它指示表或视图中插入或更新了哪些列。官方文档的解释非常的抽象,如果想要使用这个函数来获取数据变更记录,我们需要踩过很多坑,突破很多点,这也是这篇文章的价值。
COLUMNS_UPDATED
首先,我们来看看这个函数表达的含义。假如某张表有8个字段,那么COLUMNS_UPDATED使用一个byte,八个bit来表示哪些列发生了数据变更,表示方法如下:
| Col_id | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|
| Bit | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| Value | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
Col_id:表字段顺序ID
Bit:bit位顺序,从0开始
Value:2的bit次方
当某些列被更新后,COLUMNS_UPDATED函数会返回varbinary位模式(varbinary位模式是什么?可以理解为所有列Value的SUM值的二进制格式)。比如:当第二列和第四列被更新,那么COLUMNS_UPDATED的varbinary位模式是2 + 8 = 10。来看一个具体的例子。
use tempdb
GO
IF EXISTS(SELECT TOP 1 1
FROM sys.tables
WHERE name = 'employeeData')
DROP TABLE employeeData;
GO
CREATE TABLE dbo.employeeData (
col1 int identity(1,1) not null,
col2 int NOT NULL,
col3 int NOT NULL,
col4 int NOT NULL,
col5 int NOT NULL,
col6 int NOT NULL,
col7 int NOT NULL constraint uni unique,
col8 int NOT NULL,
);
GO
CREATE TRIGGER dbo.Trg_UID_employeeData
ON dbo.employeeData
AFTER UPDATE,INSERT,DELETE
AS
BEGIN
declare
@table_id int = 0
;
select top 1
@table_id = parent_id
from sys.triggers with(nolock)
where object_id = @@procid;
select updated_columns =
stuff
(replace(
replace(
(
select column_name = quotename(name)
from sys.columns with(Nolock)
where object_id = @table_id
and CONVERT(VARBINARY,COLUMNS_UPDATED()) & POWER(2, column_id - 1) = POWER(2, column_id - 1)
order by column_id asc
for xml path('')
)
,'<column_name>',',')
,'</column_name>','')
,1,1,'')
,columns_updated_value = cast(COLUMNS_UPDATED() as int)
END
GO
--test DML actions
--INSERT
INSERT INTO dbo.employeeData
VALUES ( 2, 3, 4, 5, 6, 7, 8);
GO
--UPDATE
UPDATE A
SET col2 = col2 + 10
,col4 = col4 + 11
FROM dbo.employeeData AS A
--DELETE
delete from dbo.employeeData
结果如下:
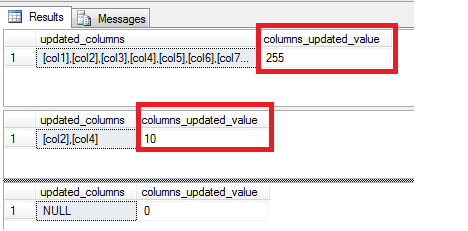
踩过的坑1: INT数据类型溢出
注意上面的代码POWER(2, column_id - 1),返回的应该是一个INT数据类型的值。在MSSQL SQL Server中INT类型使用4个字节来存储,也就是32bit,换句话说,当表的字段列个数达到32时,这个POWER操作会导致INT数据类型溢出而报告异常。当我们将上面的表字段加到32个后,INSERT和UPDATE操作会导致TRIGGER报告如下错误:
Msg 232, Level 16, State 3, Procedure Trg_UID_employeeData, Line 15
Arithmetic overflow error for type int, value = 2147483648.000000.
The statement has been terminated.
Msg 232, Level 16, State 3, Procedure Trg_UID_employeeData, Line 15
Arithmetic overflow error for type int, value = 2147483648.000000.
The statement has been terminated.
踩过的坑2:BIGINT数据类型溢出
关于这个问题,在没有完美的解决方法之前,很长一段时间,我们强制将POWER转化为BIGINT数据类型来暂时突破32个字段数量限制。但是,这个坑原理和上面一样,仅仅是将字段数量从32个扩大到64个。方法如下:
...
and CONVERT(VARBINARY,COLUMNS_UPDATED()) & POWER(cast(2 as bigint), column_id - 1) = POWER(cast(2 as bigint), column_id - 1)
...
如何完美的解决上面两个坑,我们先暂时留个悬念。
庖丁解牛
让我们回到最原始的需求,对于DML操作,不外乎三种,即INSERT,UPDATE和DELETE。我们的Trigger必须具备识别这三种操作类型的能力。
INSERT:Trigger需要具备识别表数据行唯一标识(RID)的能力(通常是主键),然后通过RID反过来查询正式表即可。
UPDATE:Trigger需要具备识别哪些字段被更新的能力,然后通过RID获取这些被更新的字段的值。
DELETE:Trigger获取到数据行唯一标识即可,通过RID删除对应的行。
综合了所有这些分析以后,我们可以使用如下的TRIGGER来捕获数据变更。
use tempdb
GO
--create table to save changed data.
if object_id('dbo.triggeredDataLog', 'U') is not null
drop table dbo.triggeredDataLog
GO
create table dbo.triggeredDataLog(
rowid bigint identity(1,1) not null primary key,
database_name sysname not null,
schame_name sysname not null,
table_object_name sysname not null,
operation char(1) not null,
RID nvarchar(1000) not null,
updated_columns nvarchar(max) null,
indate datetime not null default (getdate()),
intime timestamp not null,
)
IF EXISTS(SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'employeeData')
DROP TABLE employeeData;
GO
--create table for testing.
CREATE TABLE dbo.employeeData (
id int identity(1,1) not null,
c1 int null,
c2 int null,
c3 int null,
c4 int null,
c5 int null,
c6 int null,
c7 int null,
c8 int null,
c9 int null,
c10 int null,
c11 int null,
c12 int null,
c13 int null,
c14 int null,
c15 int null,
c16 int null,
c17 int null,
c18 int null,
c19 int null,
c20 int null,
c21 int null,
c22 int null,
c23 int null,
c24 int null,
c25 int null,
c26 int null,
c27 int null,
c28 int null,
c29 int null,
c30 int null,
c31 int null,
c32 int null,
c33 int null,
c34 int null,
c35 int null,
c36 int null,
c37 int null,
c38 int null,
c39 int null,
c40 int null,
c41 int null,
c42 int null,
c43 int null,
c44 int null,
c45 int null,
c46 int null,
c47 int null,
c48 int null,
c49 int null,
c50 int null,
c51 int null,
c52 int null,
c53 int null,
c54 int null,
c55 int null,
c56 int null,
c57 int null,
c58 int null,
c59 int null,
c60 int null,
c61 int null,
c62 int null,
c63 int null,
c64 int null,
c65 int null,
c66 int null,
c67 int null,
c68 int null,
c69 int null
);
GO
CREATE TRIGGER dbo.Trg_UID_employeeData
ON dbo.employeeData
AFTER UPDATE,INSERT,DELETE
AS
BEGIN
SET NOCOUNT ON;
--=======================================
-- get DML Action (INSERT,UPDATE,DELETE)
DECLARE
@OperationType CHAR(1)
,@table_id int = 0
;
select top 1
@OperationType = 'D'
,@table_id = parent_id
from sys.triggers with(nolock)
where object_id = @@procid
;
--get operation type:
--record in inserted & deleted, that means UPDATE DML operation
--record in inserted but not in deleted, that means INSERT DML operation
--by default, we set operation type as DELETE DML operation
IF EXISTS (SELECT TOP 1 1 FROM inserted)
BEGIN
IF EXISTS (SELECT TOP 1 1 FROM deleted)
BEGIN
SET @OperationType = 'U'; --UPDATE
END
ELSE
SET @OperationType = 'I'; --INSERT
END
-- end of getting DML Action
--=======================================
-- we need to konw PK column(s) or identity column or unqiue column
-- table exists PK
declare
@tb_unique_cols table(
column_name sysname not null
,data_type sysname not null)
IF EXISTS( --primary key
select * from sys.indexes WITH(NOLOCK)
where object_id = @table_id
and is_primary_key = 1
)
BEGIN
INSERT INTO @tb_unique_cols
SELECT
column_name = col.name
,data_type = ty.name
FROM sys.indexes AS i with(NOLOCK)
INNER JOIN sys.index_columns AS ic with(NOLOCK)
ON i.OBJECT_ID = ic.OBJECT_ID
AND i.index_id = ic.index_id
INNER JOIN sys.columns AS col with(NOLOCK)
ON i.object_id = col.object_id
INNER JOIN sys.types as ty with(NOLOCK)
ON col.user_type_id = ty.user_type_id
WHERE i.is_primary_key = 1
and i.object_id = @table_id
and ic.column_id = col.column_id
END
ELSE IF EXISTS( --table doesn't have primary key but table exists identity
select * from sys.columns
where object_id = @table_id
and is_identity = 1
)
BEGIN
INSERT INTO @tb_unique_cols
select column_name = col.name,data_type = ty.name
from sys.columns as col with(NOLOCK)
INNER JOIN sys.types as ty with(NOLOCK)
ON col.user_type_id = ty.user_type_id
where col.object_id = @table_id
and col.is_identity = 1
END
ELSE IF EXISTS( --table doesn't have primary key/indentity but table has unique index or constraint
select * from sys.indexes with(NOLOCK)
where object_id = @table_id
and is_unique = 1
)
BEGIN
INSERT INTO @tb_unique_cols
SELECT TOP 1 column_name = col.name
,data_type = ty.name
FROM sys.indexes AS i with(NOLOCK)
INNER JOIN sys.index_columns AS ic with(NOLOCK)
ON i.OBJECT_ID = ic.OBJECT_ID
AND i.index_id = ic.index_id
INNER JOIN sys.columns AS col with(NOLOCK)
ON i.object_id = col.object_id
and col.column_id = ic.column_id
INNER JOIN sys.types as ty with(NOLOCK)
ON col.user_type_id = ty.user_type_id
WHERE i.is_unique = 1
and i.object_id = @table_id
END
--=======================================
--get PK set: [pk1] = 1 and [pk2] = 'ABSDEF' and [pk3] = 'Jul 29 2016 5:04PM'
declare
@unique_cols_list nvarchar(max)
,@sql nvarchar(max)
,@RID nvarchar(max)
,@database_name sysname
,@schema_name sysname
,@table_object_name sysname
;
select @unique_cols_list = '''' +
stuff
(replace(
replace(
(
select column_name = N'+ ' + quotename( N' and ' + quotename(column_name)+ N' = ', '''') + N'+ ' +
case
when data_type in ('char','nchar','varchar','nvarchar','date','datetime','datetime2','smalldatetime') then N'quotename('
else ''
end +'cast('+quotename(column_name) +' as varchar)' +
case
when data_type in ('char','nchar','varchar','nvarchar','date','datetime','datetime2','smalldatetime') then N','''''''')'
else ''
end
from @tb_unique_cols
for xml path('')
)
,'<column_name>','')
,'</column_name>','')
,1,8,'')
,@database_name = db_name()
,@schema_name = schema_name(schema_id)
,@table_object_name = object_name(object_id)
from sys.tables
where object_id = @table_id
--end get PK set
--end of table PK/identity/unique generation
--=======================================
-- recording the DML into log
IF @OperationType = 'I' --INSERT
BEGIN
IF EXISTS(select TOP 1 1 from inserted)
BEGIN
select * into #inserted from inserted
set
@sql = N'SELECT @RID = '+ @unique_cols_list + N' FROM #inserted'
;
exec sys.sp_executesql @sql
,N'@RID nvarchar(max) output'
,@RID = @RID output
;
--select @sql,@RID
INSERT INTO dbo.triggeredDataLog(database_name,schame_name,table_object_name,operation,RID)
select @database_name,@schema_name,@table_object_name,@OperationType, @RID
END
END
ELSE IF @OperationType = 'U' --UPDATE
BEGIN
--we need to konw PK column(s) & updated columns
IF EXISTS(select TOP 1 1 from deleted)
BEGIN
/*start
get updated columns
*/
DECLARE
@Columns_Updated NVARCHAR(max)
,@maxByteCU INT
,@curByteCU INT
,@cByte INT
,@curBit INT
,@maxBit INT
;
SELECT
@maxByteCU = DATALENGTH(COLUMNS_UPDATED())
,@Columns_Updated = N''
,@curByteCU = 1
WHILE @curByteCU <= @maxByteCU
BEGIN
SELECT @cByte = SUBSTRING(COLUMNS_UPDATED(), @curByteCU, 1)
,@curBit = 1
,@maxBit = 8
;
WHILE @curBit <= @maxBit
BEGIN
IF CONVERT(BIT, @cByte & POWER(2,@curBit - 1)) <> 0
--SET @Columns_Updated = @Columns_Updated + '[' + CONVERT(VARCHAR, 8 * (@curByteCU - 1) + @curBit) + ']'
select @Columns_Updated = @Columns_Updated + QUOTENAME(name) + ','
from sys.columns with(Nolock)
where object_id = @table_id
and column_id = 8 * (@curByteCU - 1) + @curBit
SET @curBit = @curBit + 1
END
SET @curByteCU = @curByteCU + 1
END
/*end
get updated columns
*/
select * into #deleted from deleted
set
@sql = N'SELECT @RID = '+ @unique_cols_list + N' FROM #deleted'
;
exec sys.sp_executesql @sql
,N'@RID nvarchar(max) output'
,@RID = @RID output
;
INSERT INTO dbo.triggeredDataLog(database_name,schame_name,table_object_name,operation,RID,updated_columns)
select @database_name,@schema_name,@table_object_name,@OperationType, @RID,left(@Columns_Updated,len(@Columns_Updated) - 1)
END
END
ELSE --DELETE
BEGIN
--we need to konw PK column(s)
IF EXISTS(select TOP 1 1 from deleted)
BEGIN
select * into #deleted1 from deleted
set
@sql = N'SELECT @RID = '+ @unique_cols_list + N' FROM #deleted1'
;
exec sys.sp_executesql @sql
,N'@RID nvarchar(max) output'
,@RID = @RID output
;
INSERT INTO dbo.triggeredDataLog(database_name,schame_name,table_object_name,operation,RID)
select @database_name,@schema_name,@table_object_name,@OperationType, @RID
END
END
END
GO
--=======================================
-- table just has identity column
-- Testing INSERT
INSERT INTO dbo.employeeData(c1,c2,c3,c4)
VALUES(1,2,3,4)
--Testing UPDATE
UPDATE TOP(1) A
SET c64 = 64
,c65 = 65
FROM dbo.employeeData AS A
--Testing DELETE
DELETE TOP (1) A
FROM dbo.employeeData AS A
--=======================================
-- table has unique constraint
ALTER TABLE dbo.employeeData
DROP COLUMN ID;
ALTER TABLE dbo.employeeData ADD
c70 int NOT NULL constraint uni_c70 unique
GO
-- Testing INSERT
INSERT INTO dbo.employeeData(c1,c2,c3,c4,c70)
VALUES(1,2,3,4,70)
--Testing UPDATE
UPDATE TOP(1) A
SET c64 = 64
,c65 = 65
FROM dbo.employeeData AS A
--Testing DELETE
DELETE TOP (1) A
FROM dbo.employeeData AS A
--=======================================
-- table has primary key
ALTER TABLE dbo.employeeData ADD
pk1 int NOT NULL,
pk2 varchar(100) not null,
pk3 datetime not null default(getdate());
ALTER TABLE dbo.employeeData ADD
CONSTRAINT pk primary key(pk1,pk2,pk3)
GO
-- Testing INSERT
INSERT INTO dbo.employeeData(pk1,pk2,pk3,c70)
VALUES(1,2,GETDATE(),70)
--Testing UPDATE
UPDATE TOP(1) A
SET c64 = 64
,c65 = 65
FROM dbo.employeeData AS A
--Testing DELETE
DELETE TOP (1) A
FROM dbo.employeeData AS A
GO
select * from dbo.triggeredDataLog with(NOLOCK) order by intime asc
结果分析
最后一条查询语句结果如下截图:

Rowid 1-3:表无主键,但存在IDENTITY属性列的情况,RID为IDENTITY属性列的值,我们抓取到的RID和Updated_columns
Rowid 4-6:表无主键,但存在UNIQUE约束的情况,RID为UNIQUE列的值,取到的RID和Updated_columns
Rowid 7-9:表有主键,这里是更加复杂的联合主键,RID为联合主键的值,取到的RID和Updated_columns
在本例的表字段个数超过了64个,达到73个,我们是采用循环获取的方式来踩过坑1和2,具体代码268行到307行。
总结
到目前为止,我们的搜索引擎只需要从dbo.triggeredDataLog表中获取数据变更RID和相应发生了变化的字段Updated_columns,而不需要从正式表中整个拉取全量数据,节约了数据库系统开销,增加了搜索索引创建的时效性,提高了客户体验。
注意:
这里需要特别提醒,正式表dbo.employeeData上千万不要使用TRUNCATE TABLE的操作,因为TRUNCATE动作无法激活触发器。
--forbidden action
TRUNCATE TABLE dbo.employeeData;