MySQL · myrocks · myrocks统计信息
Author: 张远
概述
mysql查询优化主要是在代价统计分析的基础上进行的。合理的代价模型和准确的代价统计信息决定了查询优化的优劣。myrocks基于mysql5.6, 目前的代价模型依赖的主要因素是IO和CPU,mysql5.7及以上的版本代价模型做了较多改进,具体可以参考这里 IO主要跟数据量和缓存相关,而CPU主要跟参与排序比较的记录数相关。 因此mysql5.6的统计信息的指标主要是数据量和记录数。例如:
- table scan:全表扫描统计信息包括数据量和记录数。
- index scan:索引统计信息,索引键值分布情况,即cardinality。
- range scan:索引范围扫描统计信息,一定范围内的记录数和数据量。
统计信息
mysql5.6 代价计算都是在server层完成,且代价只关心引擎层的数据量和行数,没有考虑不同引擎存储方式的差异,其代价也会存在差异。相对来说,5.7的代价统计方式更为合理。 对server层来说,不同存储引擎都应提供以下统计信息
- 索引的大小
- 索引的总行数
- 索引的键值分布, 不同长度前缀的键值分布
- 一定范围内的记录数
下面分别介绍innodb和rocksdb的统计信息
InnoDB统计分析
统计信息存储
innodb的统计信息可以通过下列表查询
information.statistics
mysql.innodb_table_stats
mysql.innodb_index_stats
实际上innodb的统计信息持久化在mysql.innodb_table_stats和mysql.innodb_index_stats这两个表中
CREATE TABLE `innodb_table_stats` (
`database_name` varchar(64) COLLATE utf8_bin NOT NULL,
`table_name` varchar(64) COLLATE utf8_bin NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`n_rows` bigint(20) unsigned NOT NULL,
`clustered_index_size` bigint(20) unsigned NOT NULL,
`sum_of_other_index_sizes` bigint(20) unsigned NOT NULL,
PRIMARY KEY (`database_name`,`table_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin STATS_PERSISTENT=0
CREATE TABLE `innodb_index_stats` (
`database_name` varchar(64) COLLATE utf8_bin NOT NULL,
`table_name` varchar(64) COLLATE utf8_bin NOT NULL,
`index_name` varchar(64) COLLATE utf8_bin NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`stat_name` varchar(64) COLLATE utf8_bin NOT NULL,
`stat_value` bigint(20) unsigned NOT NULL,
`sample_size` bigint(20) unsigned DEFAULT NULL,
`stat_description` varchar(1024) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`database_name`,`table_name`,`index_name`,`stat_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin STATS_PERSISTENT=0
统计方法
- 索引大小
从segment描述项直接得到索引占用的page数(btr_get_size),索引总数据量=总page数*page大小。 索引大小的计算是比较精确的。 -
索引键值分布
通过扫描所有数据的方式来统计键值分布虽然得到的数据是准确的,但是非常耗时。因此innodb是通过采样的方式来实现的,参数innodb_stats_persistent_sample_pages、innodb_stats_sample_pages 、innodb_stats_transient_sample_pages可以控制采样的page数。一般来说采样的page越分散,数据越准确。采样有两种方式,transient方式和persistent方式。 1) transient方式:快速但不精确(dict_stats_update_transient) 从根开始每层随机取一条记录到下一层,直到叶子节点。这样采样得到page过于随机,采样page可能出现比较集中的情况,极端情况下多次采样的page有可能是重复的。
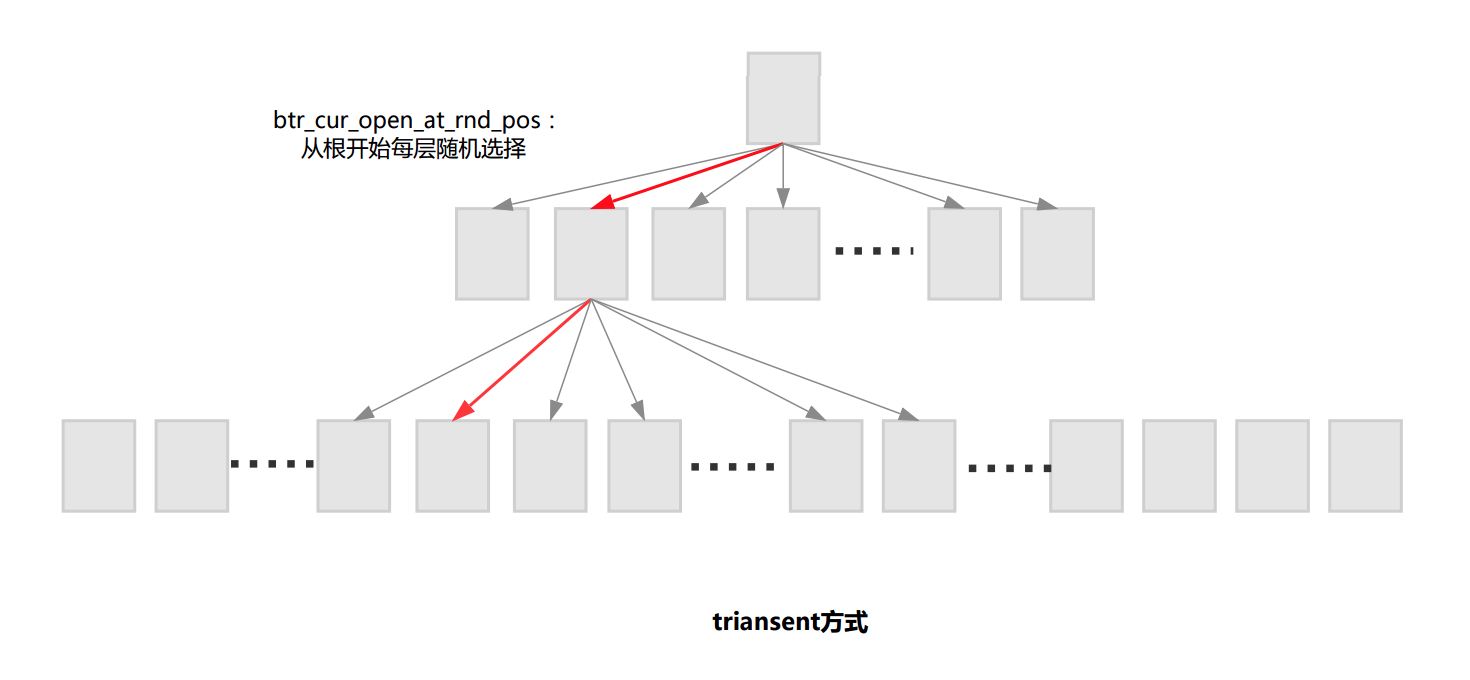 2) persistent方式:慢但相对精确(dict_stats_update_persistent)
presistent方式分为两个阶段。第一阶段,找到一个合适的层次(非叶子层)用于分段,这个层次的不同值个数须>=10*采样页个数即N_DIFF_REQUIRED(index))。第二阶段,在找到的层次上进行分段,分段个数为N(N<=采样数),再从每个分段随机取记录向下层找采样页,如果下层节点所有记录都相等,那么采样可以提前结束,不需要一直向下找到叶子节点,因为叶子节点中记录必定也是相同的。
persistent方式采样比较分散,但第一阶段分段可能比较耗时,如果索引区分度不高,可能需要到Level=1层才分段。
2) persistent方式:慢但相对精确(dict_stats_update_persistent)
presistent方式分为两个阶段。第一阶段,找到一个合适的层次(非叶子层)用于分段,这个层次的不同值个数须>=10*采样页个数即N_DIFF_REQUIRED(index))。第二阶段,在找到的层次上进行分段,分段个数为N(N<=采样数),再从每个分段随机取记录向下层找采样页,如果下层节点所有记录都相等,那么采样可以提前结束,不需要一直向下找到叶子节点,因为叶子节点中记录必定也是相同的。
persistent方式采样比较分散,但第一阶段分段可能比较耗时,如果索引区分度不高,可能需要到Level=1层才分段。
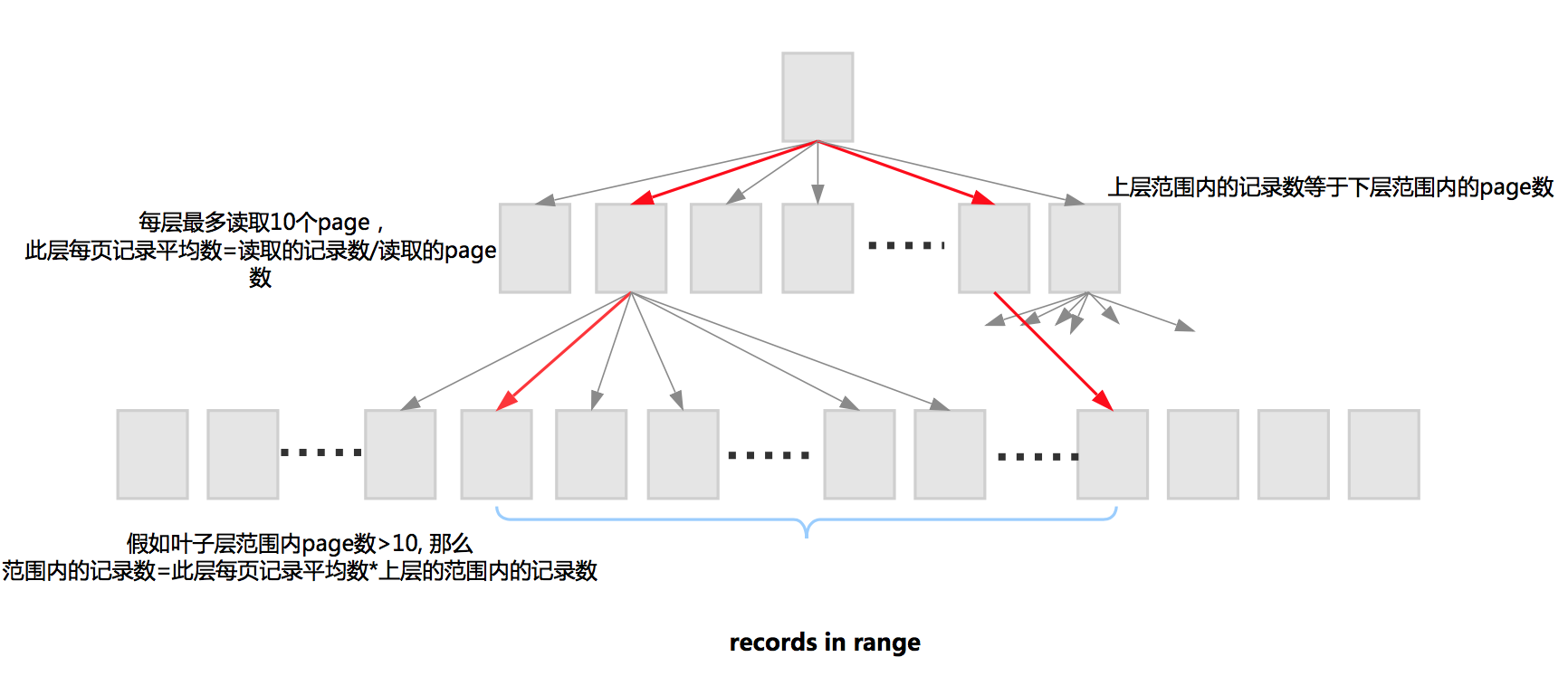 遍历采样页可以得到采样页的键值分布情况,从segment描述项可以得到叶子节点page数,再根据叶子节点page数和采样页比例可以得出最终的键值分布情况。
遍历采样页可以得到采样页的键值分布情况,从segment描述项可以得到叶子节点page数,再根据叶子节点page数和采样页比例可以得出最终的键值分布情况。 -
总行数
前面已经计算出主键索引的分布情况, 总行数=主键不同值的个数。 - 范围统计
范围统计,先从B树中查找起始值和结束值,并记录查找路径,从而每层的范围能够确定下来。 有一个规律是,上层范围内的记录数等于下层范围内的page数。 每层最多读取10个page,此层每页记录平均数=读取的记录数/读取的page数。
假如此层范围内page数>10, 那么范围内的记录数=此层每页记录平均数*上层的范围内的记录数。
下层范围内的记录数依赖于上层范围内的记录数。这样每层计算直到叶子层。
统计信息更新
以下情况会触发统计信息更新
- analyze table
- 距离上一次更新统计信息,发生变化的行数超过一定数值时自动更新(transient:1/16, persistent :1/10)
- create table/truncate table 会初始化统计信息
- 查询information_schema.tables information_schema.statistic(innodb_stats_on_metadata=ON)
Rocksdb统计分析
统计信息存储
从server层来看,rocksdb统计信息存储在rocksdb数据字典INDEX_STATISTICS中
key: Rdb_key_def::INDEX_STATISTICS(0x6) + global_index_id
value: version, {materialized PropertiesCollector::IndexStats}
实际包含以下信息
struct Rdb_index_stats
{
......
GL_INDEX_ID m_gl_index_id;
int64_t m_data_size, m_rows, m_actual_disk_size;
int64_t m_entry_deletes, m_entry_single_deletes;
int64_t m_entry_merges, m_entry_others;
std::vector<int64_t> m_distinct_keys_per_prefix;
......
}
INDEX_STATISTICS并没有像innodb统计信息一样提供mysql 下的表来查询,但我们仍可以从information_schema.statistic查看部分统计信息。
从rocksdb层来看,统计信息在每个SST file meta中都单独保存了自己的统计信息
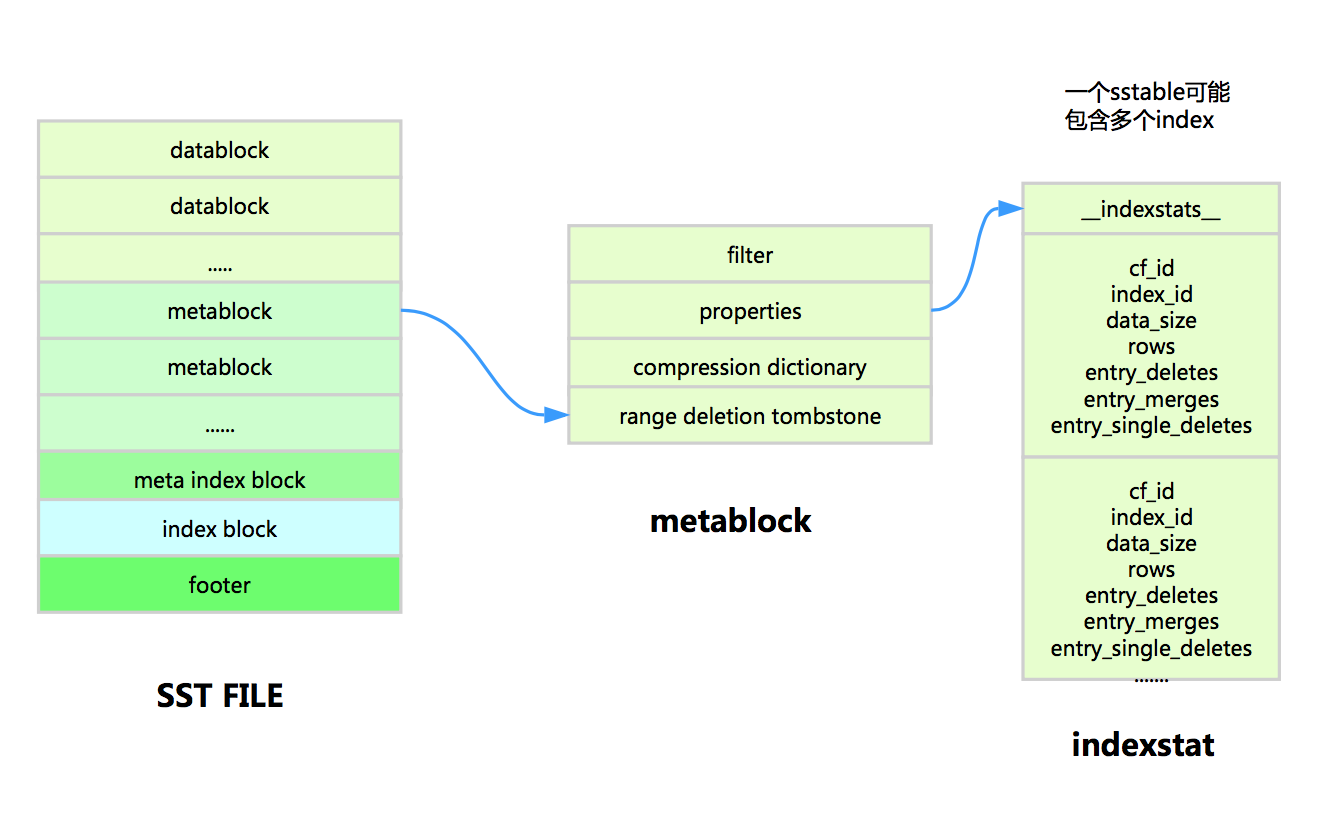
而数据字典NDEX_STATISTICS的数据是汇总了memtable和所有sstable统计信息后的数据。
统计方法
memtable 每插入一行数据会统计行数(num_entries_)和数据量(data_size_) memtable flush时会将SST 统计信息持久化到SST的meta中。 compact时新的统计信息也会持久化到新生成的SST的meta中。
- 范围分布
范围分布需从memtable和sstable中查找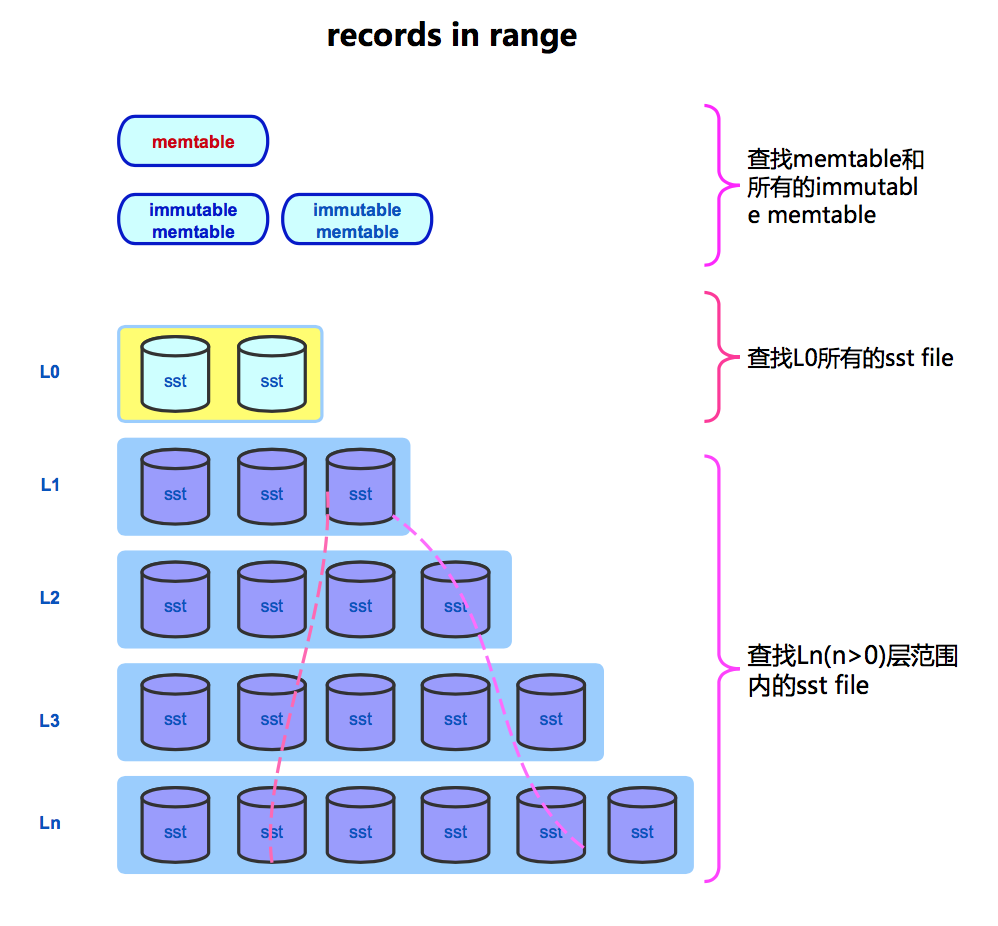
查找memtable(skiplist),一个估算规则是, 下层范围内节点数=上层节点数*branching_factor。根据此规则可以估算memtable范围内的数据。
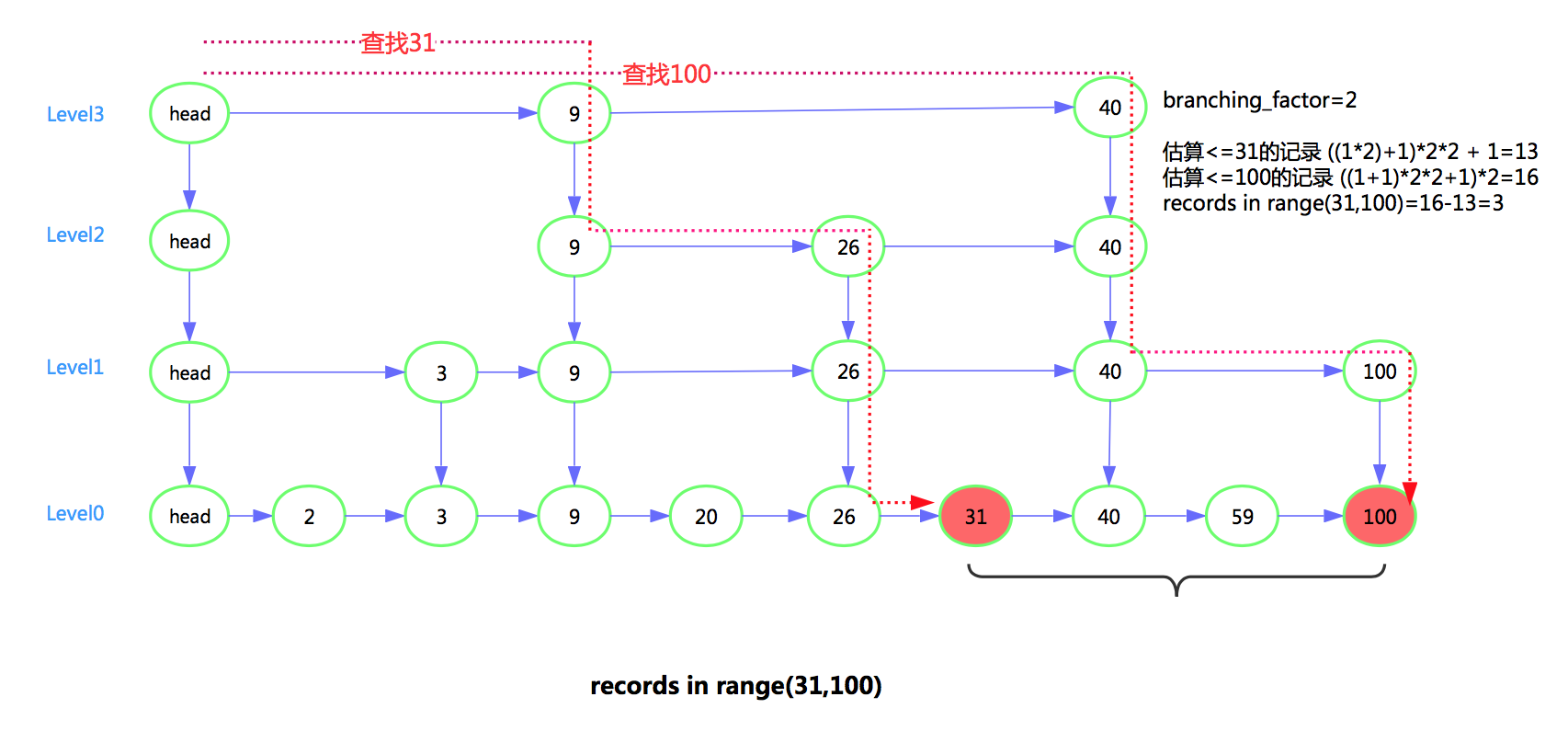
相关代码如下
template <typename Key, class Comparator>
uint64_t SkipList<Key, Comparator>::EstimateCount(const Key& key) const {
uint64_t count = 0;
Node* x = head_;
int level = GetMaxHeight() - 1;
while (true) {
assert(x == head_ || compare_(x->key, key) < 0);
Node* next = x->Next(level);
if (next == nullptr || compare_(next->key, key) >= 0) {
if (level == 0) {
return count;
} else {
// Switch to next list
count *= kBranching_;
level--;
}
} else {
x = next;
count++;
}
}
}
查sstable,先定位每层范围涉及的sstable,再估算范围内的数据大小。如果某个sstable全包含在范围内,则大小可以直接从sstable 的meta中获取;如果sstable只是半包含,那么需要计算范围在sstable中的offset,从而得到sstable中被包含的数据大小。

算出每层的范围内的数据大小,汇总得到范围内的总大小。
范围内的总行数=范围内的sstable总大小*sstable总行数/sst总大小 + memtable范围内的总行数。
官方代码存在bug,已提交给官方,详见这里
- 总行数
总行数=memtable中行数+sstable中行数 memtable中行数估算方法同上一节
官方代码实现假设记录大小为100字节(ROCKSDB_ASSUMED_KEY_VALUE_DISK_SIZE),stats.records = sz/ROCKSDB_ASSUMED_KEY_VALUE_DISK_SIZE; 实际没有必要,实际上是可以通过上面的方法估算的。
sstable中行数只需要从meta中获取并汇总即可。 而实际上如果每此从memtable估算行数还是有一定开销的。所以,官方在仅有memtable而没有sstable的情况下才估算memtable的行数。而对于memtable和sstable共存的情况则只考虑sstable,忽略memtable中行数。
这里应该可以优化,比如可以考虑immutable memtable的行数
-
总大小
不需要统计memtable,只需要汇总sstable meta中的大小。 -
键值分布
每个sstable meta有键值分布信息,只需要汇总即可。
这里也存在一个bug
对于memtable,如果仅有memtableer没有sstable,那么键值分布只是简单的给了初始值。
// Fake cardinality implementation. For example, (idx1, idx2, idx3) index
// will have rec_per_key for (idx1)=4, (idx1,2)=2, and (idx1,2,3)=1.
// rec_per_key for the whole index is 1, and multiplied by 2^n if
// n suffix columns of the index are not used.
x = 1 << (k->actual_key_parts-j-1);
而对于memtable和sstable共存的情况则只考虑sstable,忽略memtable的键值分布
统计信息更新
- 实例启动时会从数据字典INDEX_STATISTICS读取并初始化所有索引统计信息。
- analyze table 汇总memtable和所有sstable的统计信息,并持久化到数据字典INDEX_STATISTICS。
- flush memtable/compact 都会更新内存统计信息,并不持久化。
flush memtable 新文件的统计信息会merge加入内存统计信息中。
compact时会去掉老文件的统计信息,同时加上新生成文件的统计信息。
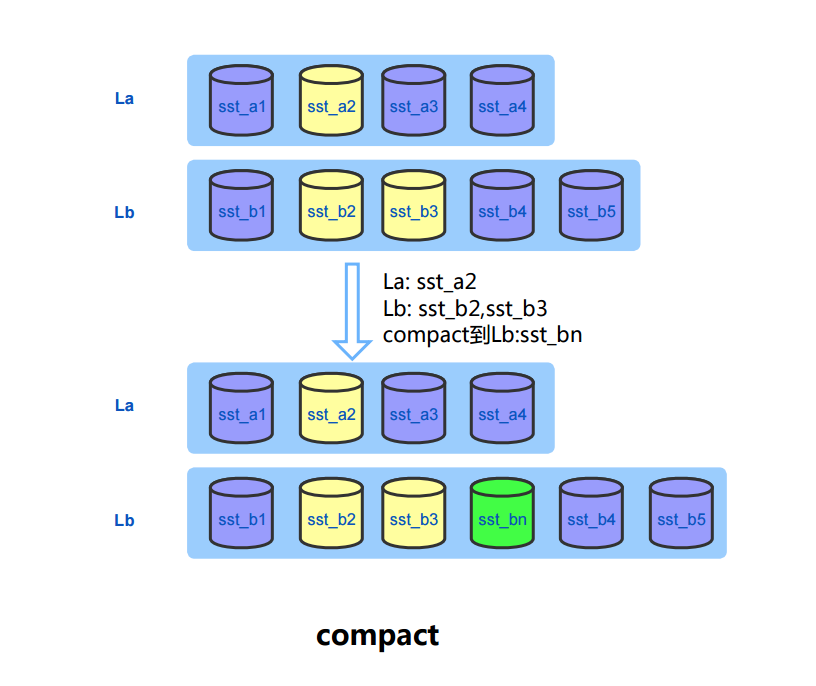
- 后台线程会定时持久化统计信息到数据字典INDEX_STATISTICS
总结
rocksdb和innodb统计信息有很多相似之处,但rocksdb sstable单独维护了统计信息,因此rocksdb的统计信息收集比innodb更快也更精确。同时,我们也看到了rocksdb的统计信息还有需要改进的地方,官方也逐步在完善。