TokuDB · 特性分析 · 导入数据大杀器:Loader
Author:
Loader简介
Loader设计思路是把<pk_key,pk_value>二元组缓存在内存中,对每个索引在后台计算索引key。等所有的数据插入操作完成后,对每个索引进行排序,最后用排好序的索引key数组建立FT文件。
创建FT的过程:依次创建每个叶子节点(leaf node)和中间节点(internal node)。最后维护元数据,这里包括index descriptor,block allocation table和FT header。
对于数据量很大的索引,因为loader预留的空间有限无法保存所有的key,所以排序的过程可能会有多轮。
每轮把内存的索引key进行merge sort,之后写入临时文件。最后,把所有经过部分排序的临时文件进行多路归并,得到一个有序的索引key数组。
Tokudb loader的主要应用场景:1)外部导入数据,2)同步创建索引。
使用loader有个限制:每个索引必须是空的。所以,loader不适合增量数据插入场景。
以导入数据场景为例:
- 创建表:(pk和二级索引)
- 调用db_env->create_loader创建loader
- 不断调用loader->put()插入数据
- 中途出错,调用loader->abort()
- 全部成功,最后调用loader->close()
- 若loader处理出错,loader使用者需显式drop table删除第一步中创建的表
酱,新的表就可以使用了。
主要数据结构
Note:由于篇幅有限,本文只列出了数据结构重要字段和代码片段。
DB_LOADER
描述了loader提供给Tokudb handler的接口。
typedef struct __toku_loader DB_LOADER;
struct __toku_loader {
struct __toku_loader_internal *i;
int (*set_error_callback)(DB_LOADER *loader, void (*error_cb)(DB *db, int i, int err, DBT *key, DBT *val, void *error_extra), void *error_extra);
int (*set_poll_function)(DB_LOADER *loader, int (*poll_func)(void *extra, float progress), void *poll_extra);
int (*put)(DB_LOADER *loader, DBT *key, DBT* val);
int (*close)(DB_LOADER *loader);
int (*abort)(DB_LOADER *loader);
};
__toku_loader_internal
描述了一些全局信息(如env和事务txn),还有一些callback函数(poll,error)
除此之外,__toku_loader_internal还包含索引的信息:
- env:全局的db_env
- txn:创建loader上下文指定的事务
- N指的是新建索引个数
- src_db是源索引,一般是NULL
- dbs是新建索引数组,共N个
- db_flags是数组,表示每个新建索引的put_flags,pk的put_flags是在set_main_dict_put_flags生成;非pk索引的一般是0
- dbt_flags也是数组,一般是DB_DBT_REALLOC
- loader_flags:可能是LOADER_COMPRESS_INTERMEDIATES表示临时文件保存的中间结果需要压缩,一般是0
- temp_file_template:临时文件的文件名模板
- err_key:记录loader->put失败的key
- err_val:记录loader->put失败的value
- err_i:未使用,本意是希望记录loader->put在写哪个dictionary失败的。loader是pipleline方式实现的,而在loader->put阶段无法确定是在哪个dictionary失败的
- err_errno:记录loader->put失败的errno
- inames_in_env:每个新建索引对应的文件名
struct __toku_loader_internal {
DB_ENV *env;
DB_TXN *txn;
FTLOADER ft_loader;
int N;
DB **dbs; /* [N] */
DB *src_db;
uint32_t *db_flags;
uint32_t *dbt_flags;
uint32_t loader_flags;
void (*error_callback)(DB *db, int i, int err, DBT *key, DBT *val, void *error_extra);
void *error_extra;
int (*poll_func)(void *poll_extra, float progress);
void *poll_extra;
char *temp_file_template;
DBT err_key; /* error key */
DBT err_val; /* error val */
int err_i; /* error i */
int err_errno;
char **inames_in_env; /* [N] inames of new files to be created */
};
ft_loader
Loader内部主要数据结构的定义在ft_loader,用于生成FT文件。这个数据结构比较重要,也比较大,我们分成几个部分来介绍。
struct ft_loader_s {
...
generate_row_for_put_func generate_row_for_put;
CACHETABLE cachetable;
bool did_reserve_memory;
bool compress_intermediates;
bool allow_puts;
uint64_t reserved_memory;
...
}
- generate_row_for_put:为每个索引生成索引key的callback函数
- cachetable:全局buffer pool指针
- did_reserve_memory:是否从cachetable里reserve内存
- compress_intermediates:中间结果是否需要压缩
- allow_puts:是否接收数据输入;设置成false,表示把directory重定向到空的FT
- reserved_memory:did_reserve_memory为TRUE,表示从cachetable中reserve了多少内存;did_reserve_memory为FALSE时,使用是512M内存
struct ft_loader_s {
...
DB *src_db;
int N;
DB **dbs; // N of these
DESCRIPTOR *descriptors; // N of these.
TXNID *root_xids_that_created; // N of these.
const char **new_fnames_in_env; // N of these.
ft_compare_func *bt_compare_funs; // N of these
...
}
- N,src_db,dbs跟__toku_loader_internal里相应字段的是一样的
- descriptors:descriptors[which_db]表示索引的descriptor
- root_xids_that_created:root_xids_that_created[which_db]表示索引创建时的root txnid
- new_fnames_in_env:new_fnames_in_env[which_db]表示索引的文件名
- bt_compare_funs:bt_compare_funs[which_db]表示索引的比较函数
struct ft_loader_s {
...
uint64_t n_rows;
struct rowset primary_rowset;
struct rowset primary_rowset_temp;
QUEUE primary_rowset_queue;
toku_pthread_t extractor_thread;
bool extractor_live;
struct rowset *rows;// N of these.
uint64_t *extracted_datasizes; // N of these.
DBT *last_key;// N of these.
struct file_infos file_infos;
...
}
- n_rows:一共有多少行数据
- primary_rowset:缓存<pk_key,pk_value>二元组的数组,loader->put的数据先被缓存到这里
- primary_rowset_temp:没有被使用,怀疑是legacy code
- primary_rowset_queue:当primary_rowset占用一定量的内存时,loader->put所在线程会调用函数enqueue_for_extraction,把当前primary_rowset克隆一份,然后挂到primary_rowset_queue队尾。后台extractor线程在不停取这个队列上的rowset,依次进行处理
- extractor_thread:extractor线程
- extractor_live:extractor线程是否正在工作
- rows:rows[which_db]保存索引的key
- extracted_datasizes:extracted_datasizes[which_db]表示索引缓存了多少数据
- last_key:没有被使用,怀疑是legacy code
- file_infos:记录打开文件的信息
struct ft_loader_s {
...
LSN load_lsn;
TXNID load_root_xid;
struct merge_fileset *fs;// N of these.
QUEUE *fractal_queues; // N of these.
toku_pthread_t *fractal_threads;// N of these.
bool *fractal_threads_live; // N of these.
unsigned fractal_workers;
...
};
- load_lsn:第一个loader->put之前的lsn位置
- load_root_xid:创建ft_loader时,局部事务loader_txn的txnid
- fs:fs[which_db]表示索引的merge信息
- fractal_queues:fractal_queues[which_db]表示索引的fractal线程使用的队列
- fractal_threads:fractal_threads[which_db]表示索引的fractal线程
- fractal_threads_live:fractal_threads_live[which_db]索引的fractal线程是否正在运行
- fractal_workers:是否有fractal线程正在构建索引FT,因为merge和构建FT的过程可能会并发,这个字段主要用来计算merge阶段可用的内存大小
Loader主要流程
Loader处理过程大致分为两个阶段:extractor阶段和merge阶段。
Extractor阶段创建extractor后台线程生成索引的key,并存储到rows[which_db]中;merge阶段创建fractal后台线程生成FT文件。
Extractor阶段,loader使用者不停地调用loader->put插入数据,当primary_rowset里面缓存的数据超过一定量后,它会把primary_rowset克隆一份挂到primary_rowset_queue尾部;后台的extractor线程不停地从primary_rowset_queue读取rowset,并对rowset中的每行row计算索引key,然后把生成的索引key缓存到其对应的rowset(rows[which_db])中。如果rows[which_db]中缓存的数据超过一定量后,需要对属于当前primary_rowset的索引key排序并写到临时文件中。每个临时文件中存储的是部分排序的key的有序序列。
Loader插入数据过程结束,每个索引需要对所有的key进行排序。rows[which_db]的空间有限,前面排好序的key可能已经写入临时文件中。
此时,primary_rowset可能还有数据需要extractor线程处理,那么需要把primary_rowset挂到primary_rowset_queue队尾,最后把primary_rowset_queue队列设置成EOF,等待evictor线程处理完退出。
当evictor线程结束后,loader会为每个索引创建fractal_threads[which_db]线程,在loader当前上下文把索引的所有临时文件中的数据按照key升序的方式排序,然后把排好序的key发送给fractal_queues[which_db], 由fractal线程创建FT文件。
创建loader
Loader使用者调用db_env->create_loader创建loader数据结构并进行初始化,也就是初始化前面我们介绍的这些字段。
真正执行创建loader的函数是toku_loader_create_loader。
在外部数据导入和同步创建索引的场景下,loader_flags中并没有设置DB_PRELOCKED_WRITE标记,需要调用toku_db_pre_acquire_table_lock获取区间整个表区间的range锁。
前面提过,loader只适用空表/空索引的情况,因为在loader->close的阶段会创建一个新的FT文件,并在tokudb.directory里修改索引和索引文件的映射关系。整个过程都执行成功的情况下,老的FT文件在关闭时被删除。所以,在创建loader的过程一般都需要确认db是空的。
在locked_load_inames对每个索引生成新的FT文件名,并修改tokudb.directory里面的映射关系,最后对每个FT索引生成loader相关的undo和redo log。这些操作是在loader_txn保护下进行的。
int
toku_loader_create_loader(DB_ENV *env,
DB_TXN *txn,
DB_LOADER **blp,
DB *src_db,
int N,
DB *dbs[],
uint32_t db_flags[/*N*/],
uint32_t dbt_flags[/*N*/],
uint32_t loader_flags,
bool check_empty) {
// lock tables and check empty
for(int i=0;i<N;i++) {
if (!(loader_flags&DB_PRELOCKED_WRITE)) {
rval = toku_db_pre_acquire_table_lock(dbs[i], txn);
if (rval!=0) {
goto create_exit;
}
}
if (check_empty) {
bool empty = toku_ft_is_empty_fast(dbs[i]->i->ft_handle);
if (!empty) {
rval = ENOTEMPTY;
goto create_exit;
}
}
}
{
if (env->i->open_flags & DB_INIT_TXN) {
rval = env->txn_begin(env, txn, &loader_txn, 0);
if (rval) {
goto create_exit;
}
}
ft_compare_func compare_functions[N];
for (int i=0; i<N; i++) {
compare_functions[i] = env->i->bt_compare;
}
// time to open the big kahuna
char **XMALLOC_N(N, new_inames_in_env);
for (int i = 0; i < N; i++) {
new_inames_in_env[i] = nullptr;
}
FT_HANDLE *XMALLOC_N(N, fts);
for (int i=0; i<N; i++) {
fts[i] = dbs[i]->i->ft_handle;
}
LSN load_lsn;
rval = locked_load_inames(env, loader_txn, N, dbs, new_inames_in_env, &load_lsn, puts_allowed);
if ( rval!=0 ) {
}
TOKUTXN ttxn = loader_txn ? db_txn_struct_i(loader_txn)->tokutxn : NULL;
rval = toku_ft_loader_open(&loader->i->ft_loader,
env->i->cachetable,
env->i->generate_row_for_put,
src_db,
N,
fts,
dbs,
(const char **)new_inames_in_env,
compare_functions,
loader->i->temp_file_template,
load_lsn,
ttxn,
puts_allowed,
env->get_loader_memory_size(env),
compress_intermediates,
puts_allowed);
if ( rval!=0 ) {
}
loader->i->inames_in_env = new_inames_in_env;
toku_free(fts);
if (!puts_allowed) {
rval = ft_loader_close_and_redirect(loader);
assert_zero(rval);
loader->i->ft_loader = NULL;
// close the ft_loader and skip to the redirection
rval = 0;
}
rval = loader_txn->commit(loader_txn, 0);
assert_zero(rval);
loader_txn = nullptr;
rval = 0;
}
*blp = loader;
create_exit:
if (loader_txn) {
int r = loader_txn->abort(loader_txn);
assert_zero(r);
loader_txn = nullptr;
}
if (rval == 0) {
}
else {
free_loader(loader);
}
return rval;
}
一般使用loader的场景都需要往loader里面插入数据,所以allow_puts一般是TRUE。初始化结束后,需要创建extractor线程。
Extractor线程前面有提到过,是从primary_rowset_queue不断地拉rowset,对rowset里面的每行数据生成索引<key,value>的二元组,并把这些二元组缓存到rows[which_db]里面。当rows[which_db]缓存的数据量积累到一定程度会进行排序,然后把排序好的<key,value>写到临时文件中。
顺便说下,除了pk和clustering index以外,二级索引的value都是NULL。
toku_ft_loader_internal_init负责初始化数据,这里主要是初始化rowset(索引的rowset:rows[which_db]和接收输入的primary_rowset),创建primary_rowset_queue队列。这部分代码比较直观,读者可以自行分析。
函数toku_ft_loader_internal_init注册了3个重要的callback函数loader->put,loader->close和loader->abort分别处理数据插入,loader关闭和loader异常退出。
int toku_ft_loader_open (FTLOADER *blp, /* out */
CACHETABLE cachetable,
generate_row_for_put_func g,
DB *src_db,
int N, FT_HANDLE fts[/*N*/],
DB* dbs[/*N*/],
const char *new_fnames_in_env[/*N*/],
ft_compare_func bt_compare_functions[/*N*/],
const char *temp_file_template,
LSN load_lsn,
TOKUTXN txn,
bool reserve_memory,
uint64_t reserve_memory_size,
bool compress_intermediates,
bool allow_puts) {
int result = 0;
{
int r = toku_ft_loader_internal_init(blp, cachetable, g,
src_db,
N, fts, dbs,
new_fnames_in_env,
bt_compare_functions,
temp_file_template,
load_lsn,
txn,
reserve_memory,
reserve_memory_size,
compress_intermediates,
allow_puts);
if (r!=0) result = r;
}
if (result==0 && allow_puts) {
FTLOADER bl = *blp;
int r = toku_pthread_create(&bl->extractor_thread, NULL, extractor_thread, (void*)bl);
if (r==0) {
bl->extractor_live = true;
} else {
result = r;
(void) toku_ft_loader_internal_destroy(bl, true);
}
}
return result;
}
值得一提的是memory_per_rowset_during_extract函数。在extractor阶段rowset的大小是函数memory_per_rowset_during_extract计算出来的。
这个阶段分配的内存主要包括两个部分:
- rowset:primary row + rows(N个) + primary_rowset_queue队列的长度 + 挂到primary_rowset_queue分配的rowset + 存放索引排序结果的rowset(N个)
- 临时文件写缓冲区(N个):大小16M
static uint64_t memory_per_rowset_during_extract (FTLOADER bl)
// Return how much memory can be allocated for each rowset.
{
if (size_factor==1) {
return 16*1024;
} else {
// There is a primary rowset being maintained by the foreground thread.
// There could be two more in the queue.
// There is one rowset for each index (bl->N) being filled in.
// Later we may have sort_and_write operations spawning in parallel, and will need to account for that.
int n_copies = (1 // primary rowset
+EXTRACTOR_QUEUE_DEPTH // the number of primaries in the queue
+bl->N // the N rowsets being constructed by the extractor thread.
+bl->N // the N sort buffers
+1 // Give the extractor thread one more so that it can have temporary space for sorting. This is overkill.
);
int64_t extra_reserved_memory = bl->N * FILE_BUFFER_SIZE; // for each index we are writing to a file at any given time.
int64_t tentative_rowset_size = ((int64_t)(bl->reserved_memory - extra_reserved_memory))/(n_copies);
return MAX(tentative_rowset_size, (int64_t)MIN_ROWSET_MEMORY);
}
}
loader->put
Loader的处理过程分为两个阶段:extract阶段和merge阶段。
Extract阶段是从extractor线程命名而来,extractor线程不断地从primary_rowset_queue拉rowset,对rowset里面的row计算索引key并保存到loader->rows[which_db]里面。
Merge阶段是数据插入结束,显式调用loader->close方法。Loader对每个db,把所有部分排序的数据进行归并得到一个按索引key升序的<key,value>二元组序列,最后根据这个序列生成FT文件。
Loader->put的处理过程就是extract阶段。
- 前景线程(创建loader上下文所在线程)不断的接收数据,并把数据缓存到primary_rowset,当其缓存的数据量大于primary_rowset->memory_budget时,会把primary_rowset克隆一份挂到primary_rowset_queue队尾并重新初始化primary_rowset,前景线程就可以继续接收数据了
- 背景线程(extractor)不断从primary_rowset_queue拉rowset,并计算索引key和value。当其缓存的数据量大于primary_rowset->memory_budget时,对索引的<key,value>二元组按照key升序方式进行merge-sort并把排好序的<key,value>序列转存到临时文件中
在extractor阶段,只有一个背景线程(extractor线程),连接前景线程和extractor线程的是primary_rowset_queue。
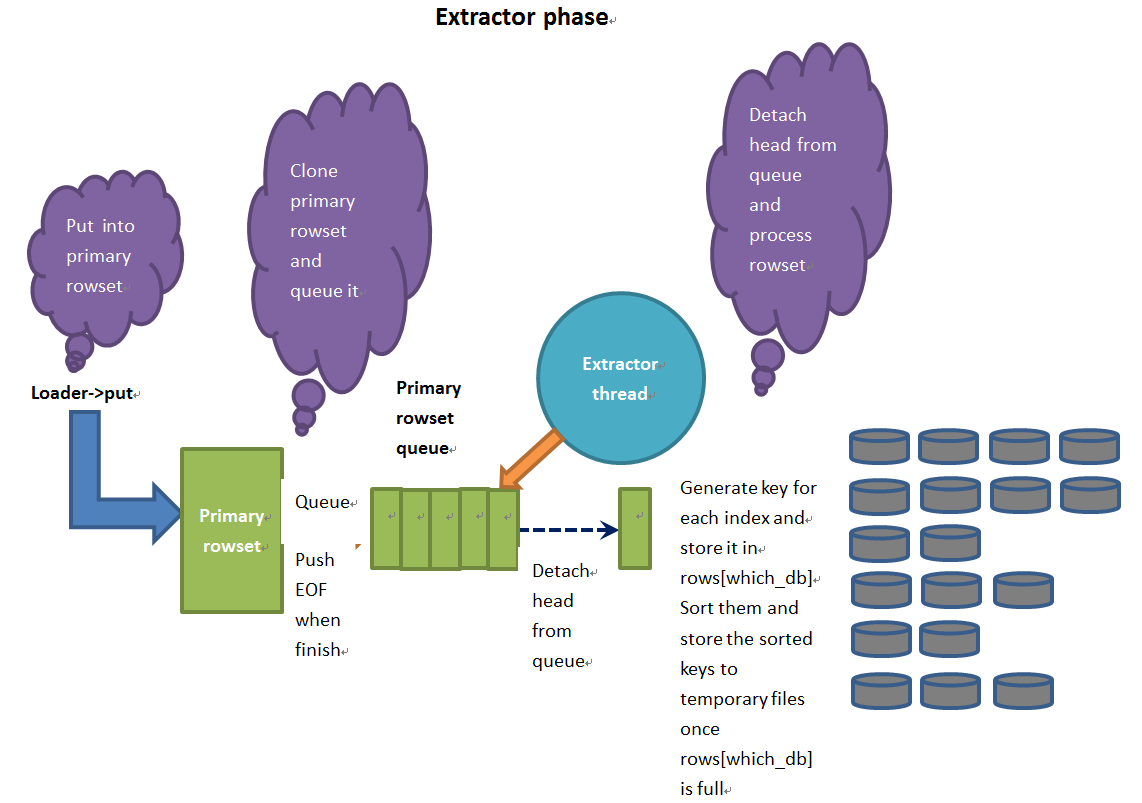
Loader的使用者调用loader->put,其实是调用函数toku_loader_put,这个函数是在loader创建阶段注册的put方法的callback函数。
这个函数首先需要检查LOADER_DISALLOW_PUTS是否设置,这个标记设置表示只使用loader来重定向director,而不是真正插入数据。所以,检查到这个标记被设置就直接退出了。
一般使用loader的用法都没有设置LOADER_DISALLOW_PUTS标记。
插入数据是在函数toku_ft_loader_put处理的。
int toku_loader_put(DB_LOADER *loader, DBT *key, DBT *val)
{
int r = 0;
int i = 0;
if (loader->i->loader_flags & LOADER_DISALLOW_PUTS) {
r = EINVAL;
goto cleanup;
}
else {
r = toku_ft_loader_put(loader->i->ft_loader, key, val);
}
if ( r != 0 ) {
}
cleanup:
return r;
}
在toku_ft_loader_put中,重复检查是否设置了LOADER_DISALLOW_PUTS,如果设置了返回EINVAL并退出。
n_rows表示loader一共接收了多少行数据,这是个全局的counter。
toku_ft_loader_put是loader_do_put简单封装,真正处理put的在loader_do_put。
int toku_ft_loader_put (FTLOADER bl, DBT *key, DBT *val)
/* Effect: Put a key-value pair into the ft loader. Called by DB_LOADER->put().
* Return value: 0 on success, an error number otherwise.
*/
{
if (!bl->allow_puts || ft_loader_get_error(&bl->error_callback))
return EINVAL; // previous panic
bl->n_rows++;
return loader_do_put(bl, key, val);
}
在loader_do_put,首先把<pk_key,pk_value>插入到primary_rowset。
rowset包括两部分:
- rows:是行数据的描述符
- data:是存储数据的缓冲区
每个<key,value>二元组是按照到达的顺序存储到primary_rowset->data指向的缓冲区中,先key后value连续存储;row.off记录了这行数据在rows.data中的偏移位置;row.klen和row.vlen分别表示key/value的长度。
rows和data都是动态数组,随着数据量增大可以动态扩展内存。
struct row {
size_t off; // the offset in the data array.
int klen,vlen;
};
struct rowset {
uint64_t memory_budget;
size_t n_rows, n_rows_limit;
struct row *rows;
size_t n_bytes, n_bytes_limit;
char *data;
};
数据插入到primary_rowset,如果primary_rowset中缓存的数据量(rows+data)大于memory_budget,意味着primary_rowset满了,loader前景线程会把primary_rowset克隆一份挂到primary_rowset_queue尾部,并重新初始化primary_rowset。
Extract阶段,rowset的memory_budget是memory_per_rowset_during_extract计算的。前面有介绍过,这里不再赘述。
static int row_wont_fit (struct rowset *rows, size_t size)
/* Effect: Return nonzero if adding a row of size SIZE would be too big (bigger than the buffer limit) */
{
// Account for the memory used by the data and also the row structures.
size_t memory_in_use = (rows->n_rows*sizeof(struct row)
+ rows->n_bytes);
return (rows->memory_budget < memory_in_use + size);
}
static int loader_do_put(FTLOADER bl,
DBT *pkey,
DBT *pval)
{
int result;
result = add_row(&bl->primary_rowset, pkey, pval);
if (result == 0 && row_wont_fit(&bl->primary_rowset, 0)) {
// queue the rows for further processing by the extractor thread
enqueue_for_extraction(bl);
{
int r = init_rowset(&bl->primary_rowset, memory_per_rowset_during_extract(bl));
// bl->primary_rowset will get destroyed by toku_ft_loader_abort
if (r != 0)
result = r;
}
}
return result;
}
static void enqueue_for_extraction (FTLOADER bl) {
struct rowset *XMALLOC(enqueue_me);
*enqueue_me = bl->primary_rowset;
zero_rowset(&bl->primary_rowset);
int r = toku_queue_enq(bl->primary_rowset_queue, (void*)enqueue_me, 1, NULL);
resource_assert_zero(r);
}
呵呵,到这里extract的前景线程就处理完了,可以等待新的数据到来。
下面,我们一起看下extract阶段的背景线程。这个线程是在函数toku_ft_loader_open创建的。Extractor线程不断从primary_rowset_queue拉rowset,对每个rowset调用process_primary_rows进行处理。如果插入数据结束,用户会调用loader->close往primary_rowset_queue挂一个EOF,让extractor线程结束。
static void* extractor_thread (void *blv) {
FTLOADER bl = (FTLOADER)blv;
int r = 0;
while (1) {
void *item;
{
int rq = toku_queue_deq(bl->primary_rowset_queue, &item, NULL, NULL);
if (rq==EOF) break;
invariant(rq==0); // other errors are arbitrarily bad.
}
struct rowset *primary_rowset = (struct rowset *)item;
{
r = process_primary_rows(bl, primary_rowset);
if (r)
ft_loader_set_panic(bl, r, false, 0, nullptr, nullptr);
}
}
if (r == 0) {
r = finish_primary_rows(bl);
if (r)
ft_loader_set_panic(bl, r, false, 0, nullptr, nullptr);
}
return NULL;
}
函数process_primary_rows是process_primary_rows_internal的简单封装。
函数process_primary_rows_internal有两个循环:外层循环是依次处理每个索引的db,里层循环是为extractor线程当前的primary_rowset的每行row生成索引的key和value。
bl->generate_row_for_put是为索引生成key和value的函数,基于<pkey,pval>二元组为索引bl->dbs[which_db]生成索引key和value。
生成的索引key和value会被缓存到索引的rowset里面,即bl->rows[which_db];bl->rows[which_db]满时,会对这个索引的rowset按照key升序的顺序排序并转存到临时文件中。
static int process_primary_rows_internal (FTLOADER bl, struct rowset *primary_rowset)
{
int error_count = 0;
int *XMALLOC_N(bl->N, error_codes);
for (int i = 0; i < bl->N; i++) {
error_codes[i] = 0;
struct rowset *rows = &(bl->rows[i]);
struct merge_fileset *fs = &(bl->fs[i]);
ft_compare_func compare = bl->bt_compare_funs[i];
for (size_t prownum=0; prownum<primary_rowset->n_rows; prownum++) {
if (error_count) break;
struct row *prow = &primary_rowset->rows[prownum];
DBT pkey,pval;
pkey.data = primary_rowset->data + prow->off;
pkey.size = prow->klen;
pval.data = primary_rowset->data + prow->off + prow->klen;
pval.size = prow->vlen;
DBT_ARRAY key_array;
DBT_ARRAY val_array;
if (bl->dbs[i] != bl->src_db) {
int r = bl->generate_row_for_put(bl->dbs[i], bl->src_db, &dest_keys, &dest_vals, &pkey, &pval);
if (r != 0) {
error_codes[i] = r;
inc_error_count();
break;
}
paranoid_invariant(dest_keys.size <= dest_keys.capacity);
paranoid_invariant(dest_vals.size <= dest_vals.capacity);
paranoid_invariant(dest_keys.size == dest_vals.size);
key_array = dest_keys;
val_array = dest_vals;
} else {
key_array.size = key_array.capacity = 1;
key_array.dbts = &pkey;
val_array.size = val_array.capacity = 1;
val_array.dbts = &pval;
}
for (uint32_t row = 0; row < key_array.size; row++) {
DBT *dest_key = &key_array.dbts[row];
DBT *dest_val = &val_array.dbts[row];
bl->extracted_datasizes[i] += ft_loader_leafentry_size(dest_key->size, dest_val->size, leafentry_xid(bl, i));
if (row_wont_fit(rows, dest_key->size + dest_val->size)) {
int r = sort_and_write_rows(*rows, fs, bl, i, bl->dbs[i], compare);
init_rowset(rows, memory_per_rowset_during_extract(bl));
if (r != 0) {
error_codes[i] = r;
inc_error_count();
break;
}
}
int r = add_row(rows, dest_key, dest_val);
if (r != 0) {
break;
}
}
}
}
toku_dbt_array_destroy(&dest_keys);
toku_dbt_array_destroy(&dest_vals);
destroy_rowset(primary_rowset);
toku_free(primary_rowset);
int r = 0;
if (error_count > 0) {
}
toku_free(error_codes);
return r;
}
排序结束,就把索引在当前rowset里面的<key,value>二元组写入到临时文件中,每个临时文件里的数据都是按照key有序的。为了尽量合并这些部分排序的中间结果,loader为每个临时文件维护了prev_key,里面存储了当前打开临时文件的最大key。
如果当前rowset的所有key都比prev_key大,那么就可以把当前结果合并到正在打开的临时文件中,不必另起一个新文件,此时需要更新prev_key。
如果不能合并,就需要关闭当前临时文件,另起一个新的临时文件写入,并重新维护prev_key。
每个索引都为临时文件配置了16M的缓冲区。开启一个新的临时文件是在函数extend_fileset里面实现的,把一个预先分配好的16M缓冲区attach到那个文件。
int sort_and_write_rows (struct rowset rows, struct merge_fileset *fs, FTLOADER bl, int which_db, DB *dest_db, ft_compare_func compare)
{
int result;
if (rows.n_rows == 0) {
result = 0;
} else {
result = sort_rows(&rows, which_db, dest_db, compare, bl);
if (result == 0) {
DBT min_rowset_key = make_dbt(rows.data+rows.rows[0].off, rows.rows[0].klen);
if (fs->have_sorted_output && compare(dest_db, &fs->prev_key, &min_rowset_key) < 0) {
// write everything to the same output if the max key in the temp file (prev_key) is < min of the sorted rowset
result = write_rowset_to_file(bl, fs->sorted_output, rows);
if (result == 0) {
// set the max key in the temp file to the max key in the sorted rowset
result = toku_dbt_set(rows.rows[rows.n_rows-1].klen, rows.data + rows.rows[rows.n_rows-1].off, &fs->prev_key, NULL);
}
} else {
// write the sorted rowset into a new temp file
if (fs->have_sorted_output) {
fs->have_sorted_output = false;
result = ft_loader_fi_close(&bl->file_infos, fs->sorted_output, true);
}
if (result == 0) {
FIDX sfile = FIDX_NULL;
result = extend_fileset(bl, fs, &sfile);
if (result == 0) {
result = write_rowset_to_file(bl, sfile, rows);
if (result == 0) {
fs->have_sorted_output = true;
fs->sorted_output = sfile;
// set the max key in the temp file to the max key in the sorted rowset
result = toku_dbt_set(rows.rows[rows.n_rows-1].klen, rows.data + rows.rows[rows.n_rows-1].off, &fs->prev_key, NULL);
}
}
}
}
}
}
destroy_rowset(&rows);
return result;
}
呵呵,数据插入结束,loader会调用toku_queue_eof往primary_rowset_queue挂一个EOF通知evictor线程结束。
loader->close
我们一起回顾一下批量数据导入的应用场景,数据插入结束后,load的使用者调用loader->close()。
函数toku_loader_close是toku_ft_loader_internal_init注册的loader->close方法。
如果loader->put阶段处理出错,toku_loader_close会根据LOADER_DISALLOW_PUTS标记是否被设置做不同的处理;如果LOADER_DISALLOW_PUTS没有被设置,它会直接调用redirect_loader_to_empty_dictionaries做隐式abort,把每个索引redirect到空的FT上。如果LOADER_DISALLOW_PUTS被设置直接返回错误。
如果loader->put阶段处理成功,但是toku_loader_close内部执行出错,它会直接调用函数redirect_loader_to_empty_dictionaries做隐式abort,把每个索引redirect到空的FT上。
如果之前的处理都正常,toku_loader_close只处理LOADER_DISALLOW_PUTS没有被设置的情况,它会调用ft_loader_close_and_redirect进入merge阶段的处理。
int toku_loader_close(DB_LOADER *loader)
{
if ( loader->i->err_errno != 0 ) {
if ( loader->i->error_callback != NULL ) {
loader->i->error_callback(loader->i->dbs[loader->i->err_i], loader->i->err_i, loader->i->err_errno, &loader->i->err_key, &loader->i->err_val, loader->i->error_extra);
}
if (!(loader->i->loader_flags & LOADER_DISALLOW_PUTS ) ) {
r = toku_ft_loader_abort(loader->i->ft_loader, true);
redirect_loader_to_empty_dictionaries(loader);
}
else {
r = loader->i->err_errno;
}
}
else { // no error outstanding
if (!(loader->i->loader_flags & LOADER_DISALLOW_PUTS ) ) {
r = ft_loader_close_and_redirect(loader);
if (r) {
redirect_loader_to_empty_dictionaries(loader);
}
}
}
free_loader(loader);
return r;
}
函数ft_loader_close_and_redirect调用toku_ft_loader_close把每个索引的<key,value>二元组按照key升序的顺序排序并生成FT文件。然后,调用toku_dictionary_redirect把每个索引redirect到刚刚生成的FT上。
static int ft_loader_close_and_redirect(DB_LOADER *loader) {
int r;
// use the bulk loader
// in case you've been looking - here is where the real work is done!
r = toku_ft_loader_close(loader->i->ft_loader, loader->i->error_callback,
loader->i->error_extra, loader->i->poll_func, loader->i->poll_extra);
if ( r==0 ) {
for (int i=0; i<loader->i->N; i++) {
toku_multi_operation_client_lock(); //Must hold MO lock for dictionary_redirect.
r = toku_dictionary_redirect(loader->i->inames_in_env[i],
loader->i->dbs[i]->i->ft_handle,
db_txn_struct_i(loader->i->txn)->tokutxn);
toku_multi_operation_client_unlock();
if ( r!=0 ) break;
}
}
return r;
}
函数toku_ft_loader_close负责结束loader的extractor阶段,把之前缓存的rowset挂到primary_rowset_queue,并在最后往primary_rowset_queue挂一个EOF,通知extractor线程停止。
如果设置了LOADER_DISALLOW_PUTS,这个loader不接收任何数据输入,一般是用作特殊作用,即把每个索引redirect到空的FT上。
bl->extractor_live为FALSE表示extractor线程没有被启动,回顾一下函数toku_ft_loader_open的处理,只有在toku_ft_loader_internal_init返回成功并且没有设置LOADER_DISALLOW_PUTS的情况下,才会启动extractor线程,并把extractor_live设置为TRUE。
所以,bl->extractor_live为FALSE的条件在大部分情况下都是不成立的,笔者猜测这是为了防止loader的使用者在创建loader出错的情况下错误地使用loader->close方式释放loader。
处理merge的重头戏在函数toku_ft_loader_close_internal里,为每个索引创建fractal线程和相应的queue。
int toku_ft_loader_close (FTLOADER bl, ft_loader_error_func error_function, void *error_extra,
ft_loader_poll_func poll_function, void *poll_extra)
{
int result = 0;
int r;
ft_loader_set_error_function(&bl->error_callback, error_function, error_extra);
ft_loader_set_poll_function(&bl->poll_callback, poll_function, poll_extra);
if (bl->extractor_live) {
r = finish_extractor(bl);
if (r)
result = r;
invariant(!bl->extractor_live);
} else {
r = finish_primary_rows(bl);
if (r)
result = r;
}
// check for an error during extraction
if (result == 0) {
r = ft_loader_call_error_function(&bl->error_callback);
if (r)
result = r;
}
if (result == 0) {
r = toku_ft_loader_close_internal(bl);
if (r && result == 0)
result = r;
} else
toku_ft_loader_internal_destroy(bl, true);
return result;
}
toku_ft_loader_close_internal为每个索引调用loader_do_i进行处理。这个函数还为每个索引创建fractal_queues[which_db]接收排好序的索引<key,value>二元组序列。
在extractor阶段部分排序的结果存储在临时文件中,bl->fs[which_db]中记录临时文件的数据结构。
Extractor阶段结束后,所有索引的<key,value>二元组应该都被处理过了,bl->rows[which_db].rows一定是NULL。
函数loader_do_i会根据dest_db原有的设置来配置新的FT,包括:node size,basement size,compression method和fanout。
一般情况下都没有设置LOADER_DISALLOW_PUTS标记,loader会为当前索引创建fractal线程,并调用merge_files函数把所有部分排序的结果进行归并产生按照索引key有序的<key,value>序列并转发到对应的fractal_queues[which_db]上,fractal线程根据这些<key,value>二元组产生新的FT文件。
若设置LOADER_DISALLOW_PUTS,loader会调用toku_loader_write_ft_from_q产生一个空的FT。
如果fractal线程在生成新FT过程中出错,fractal线程退出后bl->rows[which_db]可能还有未被处理过的索引<key,value>二元组。所以,loader_do_i在退出前需要释放rows->data和rows->rows。
在merge阶段中:
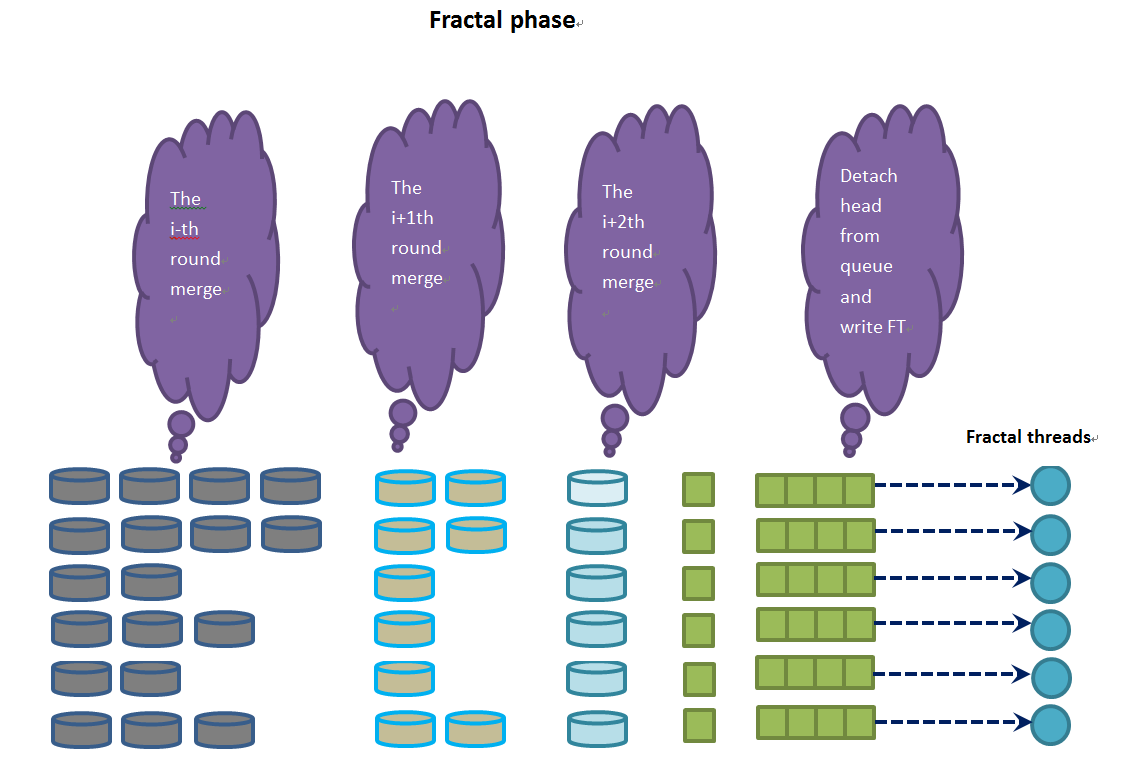
- 前景线程:等待extractor线程把部分排序并转储临时文件的工作结束。循环处理每个索引,对这个索引的所有临时文件(部分排序结果)进行归并,生成一个全局按key有序的<key,value>二元组序列。并把这个<key,value>二元组序列转发给fractal_queues[which_db]
- 背景线程(fractal):fractal[which_db]不断从fractal_queues[which_db]去拉排好序的<key,value>二元组序列,根据这个序列生成最终的FT文件。
在merge阶段有个N个背景线程,连接前景线程(创建loader的上下文)和背景线程 fractal[which_db]的是fractal_queues[which_db]。
static int loader_do_i (FTLOADER bl,
int which_db,
DB *dest_db,
ft_compare_func compare,
const DESCRIPTOR descriptor,
const char *new_fname,
int progress_allocation // how much progress do I need to add into bl->progress by the end..
)
/* Effect: Handle the file creating for one particular DB in the bulk loader. */
/* Requires: The data is fully extracted, so we can do merges out of files and write the ft file. */
{
struct merge_fileset *fs = &(bl->fs[which_db]);
struct rowset *rows = &(bl->rows[which_db]);
invariant(rows->data==NULL); // the rows should be all cleaned up already
int r = toku_queue_create(&bl->fractal_queues[which_db], FRACTAL_WRITER_QUEUE_DEPTH);
if (r) goto error;
{
mode_t mode = S_IRUSR+S_IWUSR + S_IRGRP+S_IWGRP;
int fd = toku_os_open(new_fname, O_RDWR| O_CREAT | O_BINARY, mode); // #2621
if (fd < 0) {
r = get_error_errno(); goto error;
}
uint32_t target_nodesize, target_basementnodesize, target_fanout;
enum toku_compression_method target_compression_method;
r = dest_db->get_pagesize(dest_db, &target_nodesize);
invariant_zero(r);
r = dest_db->get_readpagesize(dest_db, &target_basementnodesize);
invariant_zero(r);
r = dest_db->get_compression_method(dest_db, &target_compression_method);
invariant_zero(r);
r = dest_db->get_fanout(dest_db, &target_fanout);
invariant_zero(r);
if (bl->allow_puts) {
// a better allocation would be to figure out roughly how many merge passes we'll need.
int allocation_for_merge = (2*progress_allocation)/3;
progress_allocation -= allocation_for_merge;
// This structure must stay live until the join below.
struct fractal_thread_args fta = {
bl,
descriptor,
fd,
progress_allocation,
bl->fractal_queues[which_db],
bl->extracted_datasizes[which_db],
0,
which_db,
target_nodesize,
target_basementnodesize,
target_compression_method,
target_fanout
};
r = toku_pthread_create(bl->fractal_threads+which_db, NULL, fractal_thread, (void*)&fta);
if (r) {
int r2 __attribute__((__unused__)) = toku_queue_destroy(bl->fractal_queues[which_db]);
// ignore r2, since we already have an error
bl->fractal_queues[which_db] = nullptr;
goto error;
}
invariant(bl->fractal_threads_live[which_db]==false);
bl->fractal_threads_live[which_db] = true;
r = merge_files(fs, bl, which_db, dest_db, compare, allocation_for_merge, bl->fractal_queues[which_db]);
{
void *toku_pthread_retval;
int r2 = toku_pthread_join(bl->fractal_threads[which_db], &toku_pthread_retval);
invariant(fta.bl==bl); // this is a gratuitous assertion to make sure that the fta struct is still live here. A previous bug put that struct into a C block statement.
resource_assert_zero(r2);
invariant(toku_pthread_retval==NULL);
invariant(bl->fractal_threads_live[which_db]);
bl->fractal_threads_live[which_db] = false;
if (r == 0) r = fta.errno_result;
}
} else {
toku_queue_eof(bl->fractal_queues[which_db]);
r = toku_loader_write_ft_from_q(bl, descriptor, fd, progress_allocation,
bl->fractal_queues[which_db], bl->extracted_datasizes[which_db], which_db,
target_nodesize, target_basementnodesize, target_compression_method, target_fanout);
}
}
error: // this is the cleanup code. Even if r==0 (no error) we fall through to here.
if (bl->fractal_queues[which_db]) {
int r2 = toku_queue_destroy(bl->fractal_queues[which_db]);
invariant(r2==0);
bl->fractal_queues[which_db] = nullptr;
}
// if we get here we need to free up the merge_fileset and the rowset, as well as the keys
toku_free(rows->data); rows->data = NULL;
toku_free(rows->rows); rows->rows = NULL;
toku_free(fs->data_fidxs); fs->data_fidxs = NULL;
return r;
}
函数merge_files进行多轮归并,每轮把前一轮的临时文件集合归并成数目更少的临时文件集合。每次归并时,顺序选择几个临时文件(输入集)进行归并,生成新的临时文件(输出文件)。每轮的所有输出文件构成输出集,被下一轮作为输入集使用。
新产生的临时文件(输出文件)包含所有输入集的<key,value>二元组,文件中的二元组是按照key有序排列的。每轮归并旨在对输入集中的<key,value>二元组按照key进行排序并减少下一轮的输入集的文件个数,直到输出集只包含一个输出文件。
最后一轮产生的索引<key,value>二元组序列,是按照key有序的全序序列。
loader把他们分成几批存储到rows[which_db]的rowset里面,并以rows[which_db]作为媒介转发给fractal线程。
函数merge_files在读取临时文件中部分排序的结果时,使用dbufio来异步读取临时文件中的key和value。dbufio是double buffering io的意思,维护两个buffer和一个异步I/O线程,前景线程永远从buf[0]读取数据,异步的I/O线程负责把buf[1]填满。
当buf[0]的数据被消耗掉后,会交换buf[0]和buf[1],并且告诉I/O线程把后面的数据读到buf[1](老的buf[0])里面。如果前景线程消耗数据太快,异步I/O线程的读操作还没有完成,前景线程会阻塞在dbufio内部的条件变量上。这是个典型的生产者消费者模型。
Merge阶段,需要使用内存的buffer主要包含三部分:
- 多轮归并时的dbufio:每轮输入集大小 * DBUFIO_DEPTH(2)
- fractol线程使用的内存:fractal_queue深度 + 每次挂到fractal_queue时分配的rowset + attach到pivot_file的buffer
- fractal线程把node写入磁盘时存放序列化后数据的buffer(压缩和未压缩的)
// To compute a merge, we have a certain amount of memory to work with.
// We perform only one fanin at a time.
// If the fanout is F then we are using
// F merges. Each merge uses
// DBUFIO_DEPTH buffers for double buffering. Each buffer is of size at least MERGE_BUF_SIZE
// so the memory is
// F*MERGE_BUF_SIZE*DBUFIO_DEPTH storage.
// We use some additional space to buffer the outputs.
// That's FILE_BUFFER_SIZE for writing to a merge file if we are writing to a mergefile.
// And we have FRACTAL_WRITER_ROWSETS*MERGE_BUF_SIZE per queue
// And if we are doing a fractal, each worker could have have a fractal tree that it's working on.
//
// DBUFIO_DEPTH*F*MERGE_BUF_SIZE + FRACTAL_WRITER_ROWSETS*MERGE_BUF_SIZE + WORKERS*NODESIZE*2 <= RESERVED_MEMORY
static int64_t memory_avail_during_merge(FTLOADER bl, bool is_fractal_node) {
// avail memory = reserved memory - WORKERS*NODESIZE*2 for the last merge stage only
int64_t avail_memory = bl->reserved_memory;
if (is_fractal_node) {
// reserve space for the fractal writer thread buffers
avail_memory -= (int64_t)ft_loader_get_fractal_workers_count(bl) * (int64_t)default_loader_nodesize * 2; // compressed and uncompressed buffers
}
return avail_memory;
}
static uint64_t memory_per_rowset_during_merge (FTLOADER bl, int merge_factor, bool is_fractal_node // if it is being sent to a q
) {
int64_t memory_avail = memory_avail_during_merge(bl, is_fractal_node);
int64_t nbuffers = DBUFIO_DEPTH * merge_factor;
if (is_fractal_node)
nbuffers += FRACTAL_WRITER_ROWSETS;
return MAX(memory_avail / nbuffers, (int64_t)MIN_MERGE_BUF_SIZE);
}
以上是归并的过程。
生成新FT的过程是在函数toku_loader_write_ft_from_q处理的。这个函数太长,就不在这贴代码了。
大致过程是这样的:
- 从fractal_queues[which_db]依次读取<key,value>二元组并建立leaf node,每个leaf上存储的数据量一定小于7/8 nodesize,后续数据保存在下一个leaf上。
- 为了建立internal subtree,在创建leaf node的过程中,维护了一个pivot文件保存每个leaf node中存储的最大key,pivot文件中最后一个key是没有用的,后面的处理会丢弃掉最后一个key;除了pivot文件,loader还为internal node维护一个subtree_info数组记录每个leaf node的blocknum。
- 建立internal subtree过程分多轮进行,每轮建立某一高度的internal node,从高度1开始。
- 写descriptor
- 写BTT
- 写FT header
internal node的处理过程,每轮处理: 依次读取上一轮产生的pivot文件中key,每次读取15个pivot key,最后一个key用作建立下一轮的pivot文件。用剩下的14个pivot key和上一轮得到的subtree_info数组中的blocknum建立本轮的internal node,并把新创建internal node的blocknum存储到另一个subtree_info数组,提供给下轮处理使用。
每轮处理完成时,会生成下轮处理需要的pivot文件和subtree_info数组。height 1时读取的是创建leaf node时生成的pivot文件和subtree_info数组。
如果一切顺利,在这之后就调用toku_dictionary_redirect把原来db[which_db]上打开的txn和ft_handle重定向到新的FT上。
loader->abort
异常退出的时候,loader首先释放ft_loader中的内部数据结构,然后调用redirect_loader_to_empty_dictionaries创建带有LOADER_DISALLOW_PUTS标记的temporary loader。
这个temporary loader首先在tokudb.directory里,把原来的loader处理的那些映射关系<index, newFT>改成<index,emptyFT>。然后在创建ft_loader之后,直接调用ft_loader_close_and_redirect把db[which_db]上打开的txn和ft_handle重定向到空的FT上。
static void redirect_loader_to_empty_dictionaries(DB_LOADER *loader) {
DB_LOADER* tmp_loader = NULL;
int r = toku_loader_create_loader(
loader->i->env,
loader->i->txn,
&tmp_loader,
loader->i->src_db,
loader->i->N,
loader->i->dbs,
loader->i->db_flags,
loader->i->dbt_flags,
LOADER_DISALLOW_PUTS,
false
);
lazy_assert_zero(r);
r = toku_loader_close(tmp_loader);
}
int
toku_loader_create_loader(DB_ENV *env,
DB_TXN *txn,
DB_LOADER **blp,
DB *src_db,
int N,
DB *dbs[],
uint32_t db_flags[/*N*/],
uint32_t dbt_flags[/*N*/],
uint32_t loader_flags,
bool check_empty) {
rval = locked_load_inames(env, loader_txn, N, dbs, new_inames_in_env, &load_lsn, puts_allowed);
if ( rval!=0 ) {
free_inames(new_inames_in_env, N);
toku_free(fts);
goto create_exit;
}
TOKUTXN ttxn = loader_txn ? db_txn_struct_i(loader_txn)->tokutxn : NULL;
rval = toku_ft_loader_open(&loader->i->ft_loader,
env->i->cachetable,
env->i->generate_row_for_put,
src_db,
N,
fts, dbs,
(const char **)new_inames_in_env,
compare_functions,
loader->i->temp_file_template,
load_lsn,
ttxn,
puts_allowed,
env->get_loader_memory_size(env),
compress_intermediates,
puts_allowed);
if ( rval!=0 ) {
free_inames(new_inames_in_env, N);
toku_free(fts);
goto create_exit;
}
loader->i->inames_in_env = new_inames_in_env;
toku_free(fts);
if (!puts_allowed) {
rval = ft_loader_close_and_redirect(loader);
assert_zero(rval);
loader->i->ft_loader = NULL;
// close the ft_loader and skip to the redirection
rval = 0;
}
酱,loader的处理过程大致就是这样~