MongoDB · 特性分析 · 网络性能优化
Author: jiangling
从 C10K 说起
对于高性能即时通讯技术(或者说互联网编程)比较关注的开发者,对C10K问题(即单机1万个并发连接问题)应该都有所了解。『C10K』概念最早由 Dan Kegel 发布于其个人站点,即出自其经典的《The C10K problem》一文[1]。
于是FreeBSD推出了kqueue,Linux推出了epoll,Windows推出了IOCP。这些操作系统提供的功能就是为了解决C10K问题。
常用网络模型
| 方案 | 名称 | 接受连接 | 网络 IO | 计算任务 |
| 1 | thread-per-connection | 1个线程 | N个线程 | 在网络线程执行 |
| 2 | 单线程 Reactor | 1个线程 | 在连接线程执行 | 在连接线程执行 |
| 3 | Reactor + 线程池 | 1个线程 | 在连接线程执行 | C2线程 |
| 4 | one loop per thread | 1个线程 | C1线程 | 在网络线程执行 |
| 5 | one loop per thread + 线程池 | 1个线程 | C1线程 | C2线程 |
注:N 表示并发连接数,C1和 C2 与连接数无关,与 CPU 数组相关的常数。
当然,还有一些用户态的解决方案,例如Intel DPDK。来自KVM核心的研发团队推出了一款数据库叫做ScyllaDB[2],其使用了SeaStar网络框架[3],SeaStar是目前可用性最好的用户态网络编程框架,在基于DPDK实现了socket语义之后,进一步提供了线程乃至协程的语义封装,便于上层应用使用。
看看利用Seastar加速的http和memcached并发可以达到多少级别,并且随着cpu核数增加线性增长,就能感受用户态网络的巨大威力了。


各个方案中各有优缺点,要根据不同的业务场景因地制宜,包括但不限于:CPU 密集型,IO 密集型,长连接,短连接,同步,异步,硬件特性。
官方 IO 模型分析
MongoDB 现在使用的同步 IO 模型,如图:
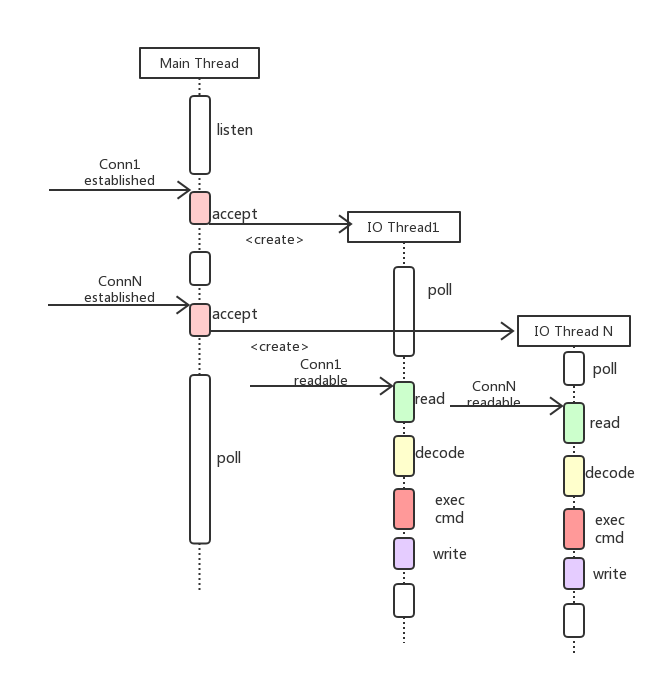
由主线程进行 accept 连接,然后针对每一个连接创建一个线程进行处理,「thread per connection」这种模型
- 其一,不适合短连接服务,创建/删除线程的开销是巨大的,体现在创建线程时间和至少1MB 内存的使用。
- 其二,伸缩性受到线程数的限制,200+线程数的调度对 OS 也是不小的负担。另外随着线程数的增加, 由于 mongo 本身业务的特性,对数据处理的并发度并不高,DB锁和全局的原子操作造成的 context-switch 也是急剧上升,性能反而下降,频繁的线程切换对于 cache 也不友好。
下面一张图可以看出各级缓存之间的响应时间差距,以及内存访问到底有多慢!
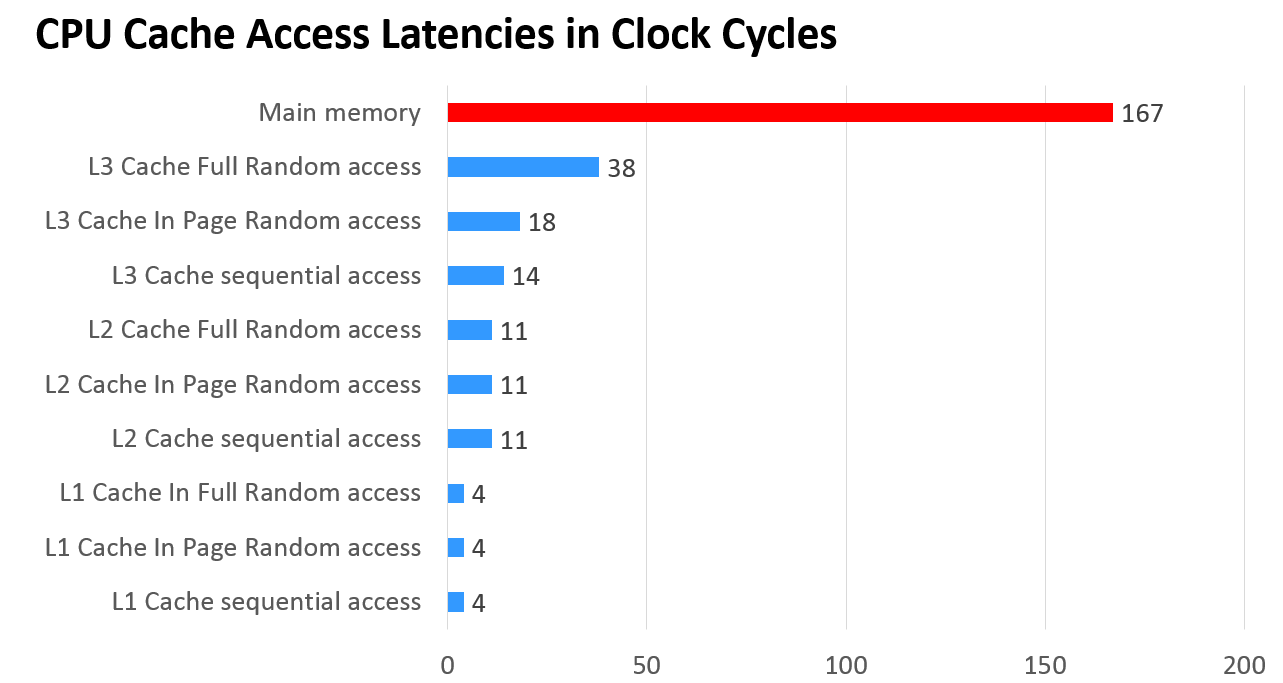
改进方案
基于上述思考和 MongoDB 的业务特性:
- 部分命令可能阻塞
- 长连接
- 高并发需求
- 通用性
我们选型方案5,「one loop per thread」加上线程池,利用分而治之的思想。 有一个 main reactor 负责 accept 连接,然后把连接挂载某个sub reactor(采用round-robin的方式来选择sub reactor),这样该连接的所用操作都在那个sub reactor所处的线程池中完成。如图:
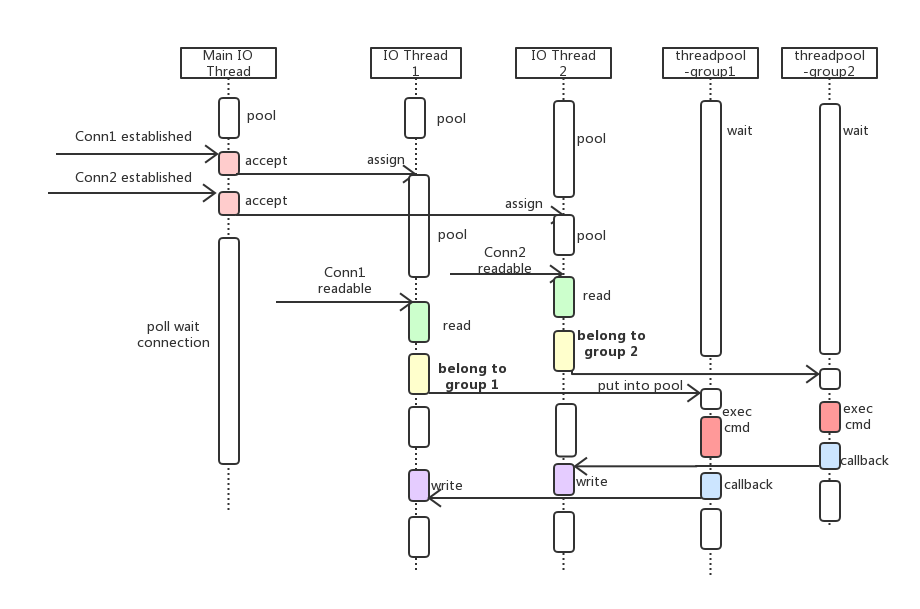
同步模型到异步模型的转变,也引入了一些问题需要我们解决:
- 非 pingpong 模型,乱序问题;
- 请求优先级反转;
- 线程池忙等;
- cache miss 是否减少。
以上问题我们将在下文中一一展开。
网络框架对比
libevent: libevent 就如名字所言,是一个异步事件框架。从 OS 那里获得事件, 然后派发。派发机制就是“回调函数”。异步异步,归根结底就是处理从操作系统获得的事件。
libev: 就设计哲学来说,libev的诞生,是为了修复libevent设计上的一些错误决策。例如,全局变量的使用。
libuv: 开发node的过程中需要一个跨平台的事件库,他们首选了libev,但又要支持Windows,故重新封装了一套,*nix下用libev实现,Windows下用IOCP实现。
boost.asio: 跨平台的 Proactor 模型实现,目前已经进入 C++17 的标准提案
libco: libco是微信后台大规模使用的c/c++网络协程库。
调研与验证
asio 在 MongoDB 上使用越来越多[4],而且满足我们跨平台的需求。如下在调研了性能后,我们还是选择了 asio 。
使用 boost.asio 编写 echo 客户端,服务端, 验证 asio 网络框架的极限性能,指导我们对 MongoDB 的性能优化。
echo 客户端的代码: https://gist.github.com/yjhjstz/ee1820efe0ff0c1ed83a6eb4649c7985
模型1- echo service 端: https://gist.github.com/yjhjstz/4eceba80ecd328a87784a0fe0b602d6c
// 省略 ....
echo_server();
boost::thread_group tg;
for (int i = 0; i < thread_count; ++i)
tg.create_thread([]{ ios.run(); });
tg.join_all();
return 0;
一个 IO 线程 + 线程池的模型,但锁的竞争被放大,QPS 在35W左右。
模型2 —- echo service 端 : https://gist.github.com/yjhjstz/a9eb964fd20d6e5c186d7a2ba3921c8f#file-server-cpp 多个 IO 线程的模型,基本没有锁竞争,QPS 在90W+。
代码实现
修改原则:
- 尽量增加接口,尽量不改动原有接口
- 利用重载,实现自己的类,做到代码开关可控。
实现略,开源 patch 准备中,请期待。
回答四个问题
同步模型到异步模型的转变,一些问题需要我们解决:
问题1的解决得益于 asio 提供的 Preactor 编程模型,async_* 的驱动在每个 IO 线程(或者线程池),但单个命令不返回客户端,下个数据包就不会被触发响应。
请求优先级反转的问题具体场景可以是心跳包或者其他。我们隔离了单独的IO 线程去处理和管理此类连接。
针对问题3,线程池忙等,我们实现了动态可伸缩的线程池,通过配置线程池中线程的最小值和最大值实现动态申请和回收线程。
问题4,我们使用 perf stat 来验证:
// 未优化前
[jianghua.yjh@r101072xxx.sqa.zmf /home/jianghua.yjh]
$sudo perf stat -e cache-references,cache-misses -p 21782
Performance counter stats for process id '21782':
31,807,891,996 cache-references
1,515,770,600 cache-misses # 4.765 % of all cache refs
126.836238857 seconds time elapsed
// 优化后
[jianghua.yjh@r101072xxx.sqa.zmf /home/jianghua.yjh]
$sudo perf stat -e cache-references,cache-misses -p 20047
Performance counter stats for process id '20047':
35,495,507,358 cache-references
1,344,188,577 cache-misses # 3.787 % of all cache refs
99.501870882 seconds time elapsed
cache-miss 在优化后降了1个百分点。进一步的,我们发现 update_curr 相比占比上升,也就是花在线程调度上的工作导致了部分的 cache-miss, 锁的 lock, unlock 排在了前面(如图),

锁这块我们还在努力研究优化中~~
性能测试报告
测试环境 (standalone)
- Linux, Intel(R) Xeon(R) CPU E5-2630 0 @ 2.30GHz, SSD
- 136 部署修改过的 YCSB 测试工具, 137 部署 mongod, 针对大量不同的连接数进行测试,场景 workloada。
- 随着连接数的增加,刚开始qps会不断成倍增长,当server资源已经达到上限时,继续增加连接数,qps会降低,同时平均的延时也在增加; 因测试存在一定的偶然性,测试结果里个别数据项可能跟总的趋势不匹配,但经多次测试验证,总的趋势是类似。
- 请求延时分布统计了平均延时、95%的请求延时(95%的请求延时小于该值)、99%请求延时。
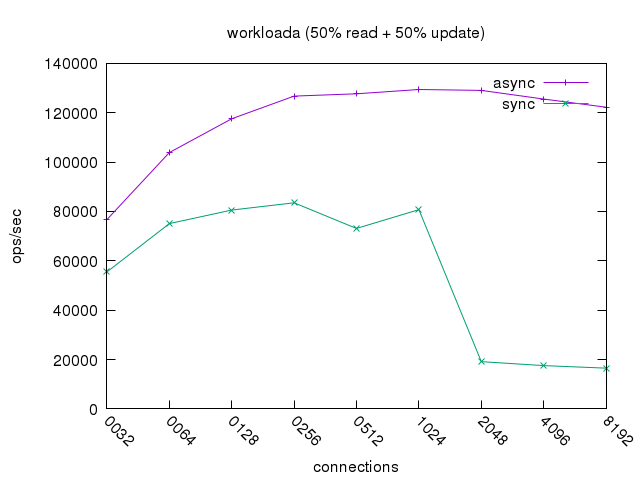
workloada QPS(50% read + 50% update )
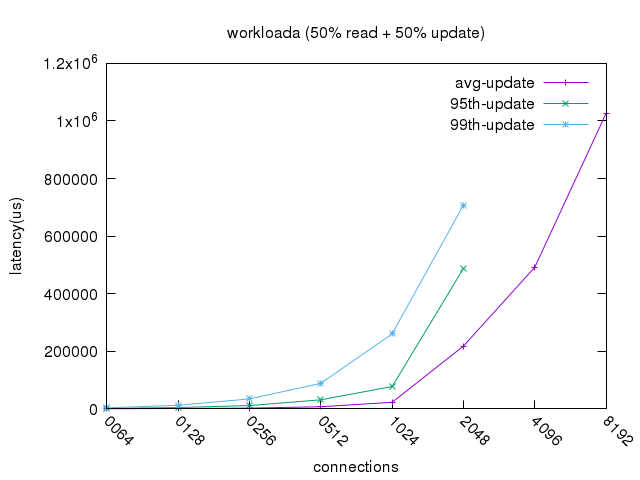
Latency update (同步模型)
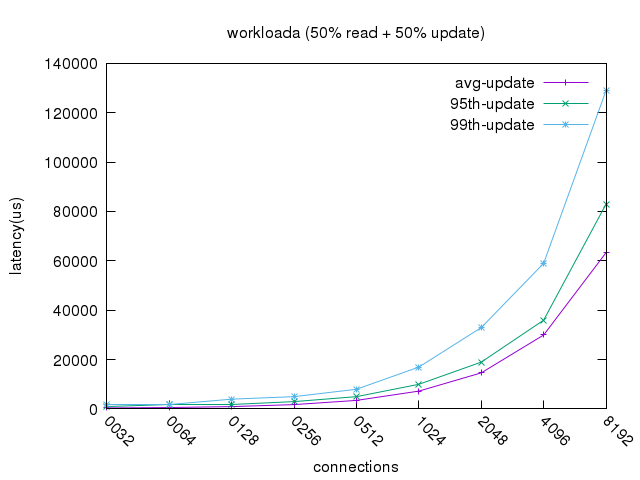
Latency update (异步模型)
总结
- 在高并发场景下,排队控制导致同步模型平均
update延时超过1S,降级到不可用的状态。 - 异步模型性能保持稳定,优化后我们获得了60%+的 QPS 收益。
- 调优过程中使用到了很多性能剖析利器 ,可以参考博文:Linux常用性能调优工具索引