PgSQL · 引擎介绍 · 向量化执行引擎简介
Author: 雅悯
摘要
本文为大家介绍一下向量化执行引擎的引入原因,前提条件,架构实现以及它能够带来哪些收益。 希望读者能够通过对这篇文章阅读能够对向量化执行引擎的应用特征与架构有一个概要的认识。
关键字
向量化执行引擎, MonetDB,Tuple, 顺序访问,随机访问, OLAP, MPP,火山模型,列存表,编译执行
背景介绍
过去的20-30年计算机硬件能力的持续发展,使得计算机的计算能力飞速提升。然后,我们很多的应用却没有做到足够的调整到与硬件能力配套的程度,因此也就不能够充分的将计算机强大的计算能力转换为软件的生产力。这样的问题在今天的通用数据库系统中也是一个比较突出的问题,因为这些通用数据库系统往往都已经有十数年或者几十年的历史了,它们也存在着不能够充分利用现在硬件能力的情况。
为什么会出现向量化执行引擎
制约数据库系统利用硬件能力的因素
-
查询执行模型 传统的数据库查询执行都是采用一次一tuple的pipleline执行模式。这样CPU的大部分处理时不是用来真正的处理数据,而是在遍历查询操作树,这样CPU的有效利用率不高。同时这也会导致低指令缓存性能和频繁跳转。更加糟糕的是,这种方式的执行,不能够利用到现在新硬件的新的能力来加速查询的执行。 关于执行引擎这块,当前有一另外一个解决方案就是改变一次一tuple 为一次一列的模式。这也是我们向量化执行引擎的一个基础。在本文后面的部分会为大家详细介绍。
-
存储 从存储层面上来看,磁盘读写能力的提升并没有CPU硬件计算能力提升的那么迅速,加上通常数据库在对于随机访问的支持,对于数据的存放位置没有做特殊的要求。目前对于磁盘来说,顺序读取的效率是比随机读取的效率要高的。但是通常数据库很多数据存储都更倾向(或者说在运行了一段时间以后)数据是处于随机存放的状态。 另一方面,目前磁盘读写能力已经远远的跟不上CPU数据执行的速度了。这种状况有一种解决方案就是使用列存储方案。因为列存储能够最大化的利用磁盘的读写能力,来提升IO带宽。
-
列存简介 这里我们也顺便给大家简单介绍一下列存储的一些特点以及优势,方便大家理解为什么向量化执行引擎必须要构架在列存储的表上才能够发挥出最大的优势。近年来,使用列存来实现存储的数据库这一技术成为,大型分析型数据越来越青睐的一种OLAP数据库的存储选型方案。 使用列存技术能够为查询的执行带来下列潜在的优势:
- 压缩能力的提升: 因为列存储技术在数据表的存储上使用数据表的列(记录的一个属性)为单位存储数据,这样类型一致的数据被放在一起,这样类似的数据在进行压缩的时候,能够达到一个比较好的压缩比。
- 减少I/O的读入总量: 因为列存按列为单位,这样,我们在读取数据的时候仅需要读入需要的列,相对于行存将所有数据读取上来再提取对应的属性,减少了I/O总量。
- 减少查询执行过程中的节点函数调用次数: 以Greenplum 为例,如果当前列存的每次以一个数据块(segment,通常一个数据块包含某列1024行值)返回给上层节点的话,会极大的减少函数调用次数,达到提升查询执行性能的效果。
- 向量化执行: 因为列存每列的各行数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作,可以使用SIMD进一步提升计算效率,即便运算的机器上不支持SIMD, 也可以通过一个循环来高效完成对这个数据块各个值的计算。
- 延迟物化: 延迟物化是在整个查询的计算过程中,尽量使用列存储,这样可以进一步减少在各个查询计划树节点之间传递数据的总量。
向量化执行引擎能够发挥效率的前提
那么向量化执行引擎是不是针对所有的数据库场景都能够达到很好的效果呢?答案是否定的。要获得到向量化执行引擎的收益,是需要有一定的条件支持的:首先向量化执行引擎效率的发挥需要数据库能够提供列存表的支持。 对于传统的行存表来说,谈向量化执行是不可能的。通常向量化执行引擎都是用在OLAP数仓类系统,因为通常分析型系统通常都是数据处理密集型负载,基本上都是采用顺序方式来访问表中大部分的数据,然后进行计算,最后将计算结果输出给终端用户。对于典型的OLTP点查询,这种类型的查询执行,使用行存表反而比列存表更好。那么读到这里是不是觉得向量化执行引擎似乎本身限制也挺多的!没有它我是不是一样可以满足数据库用户的需要呢? 如果跟按照现在OLAP数仓系统数据容量动辄T 级别甚至P 级别,一条复杂报表查询的执行可能会用几千秒,如果使用向量化执行引擎能可以比原来的行存提升3-5倍的执行效率的话,也许原来不能被接受的查询时长,现在可以被接受了。 其次,向量化引擎本身应该如何实现呢? 目前主要有两种关于向量化执行引擎的实现方法,
- 仍然使用火山模型,只不过一次返回一组列。这种模型的优势是仍然使用(火山模型),这个优化器于执行器模型已经很成熟,剩下需要的工作量就在于如何将一次一tuple的处理模式,修改为一次向上返回一组列存行值(例如:100-1000行)处理方式,难度相对较小;
- 将整个模型改造成为层次型的执行模式,这种模式需要将优化好的执行计划树,最终转换为编译执行,即,一次调用下来之后,每一层都完成后才向上返回数据,这样能够最大程度的减少各层次节点间的调用次数。提高CPU的有效计算效率。这里我们称这种模型为编译执行模型。 后续会给大家对这两种模型进行更加详细的介绍
向量化执行引擎的架构
接下来我们将就之前讲的两种执行引擎来给大家在架构原理上来深入一些的了解向量化执行引擎。
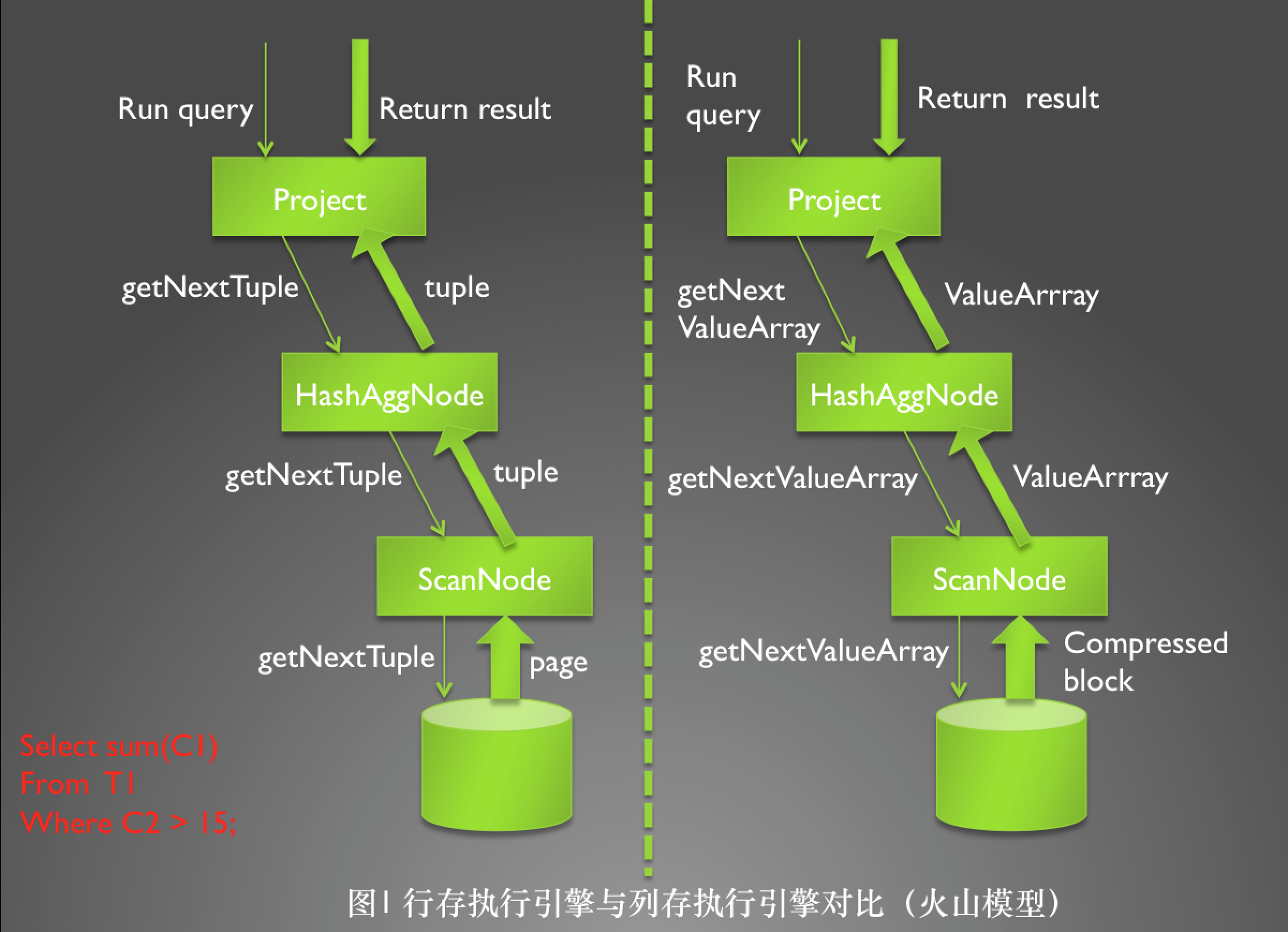
图1中描述的就是火山模型实现的行存执行引擎与列存执行引擎,其中左边代表的是当前比较流行的传统行存火山模型,右边代表的是列存实现的火山模型,从上图我们可以看到火山模式是从执行计划树的根节点开始向叶子节点递归调用,然后有叶子节点,通常是各种的扫描节点返回一条符合过滤条件的tuple 给上层节点处理,每一层节点在处理完该tuple之后继续网上层节点传递记录(Agg节点不是立刻往上层节点返回数据,它需要计算完所有的Tuple,才能继续往上层节点返回,所以这里AGG算子在处理好这个Tuple之后,又会往下调用扫描算子返回下一条符合过滤条件的记录)。这样处理完整个表的记录之后,AGG算子会把数据返回到上一层节点继续处理,在整个过程中需要AGG算子缓存中间结果。 右边列存执行引擎,执行逻辑基本上与左边行存执行引擎一致,但是每次扫描处理的是一组组以col组织的列数据集合,这样我们最为直观的观察就是从上层节点向下层节点的调用次数少了。相应的CPU的利用率得到了提高,另外数据被组织在一起。可以利用硬件发展带来的一些收益;如SIMD, 循环优化,将所有数据加载到CPU的缓存当中去,提高缓存命中率,提升效率。在列存储与向量化执行引擎的双重优化下,查询执行的速度会有一个非常巨大的飞跃大约3-5倍。后续我们会在技术实现的过程中给出更为详细的性能测试对比报告,敬请期待。
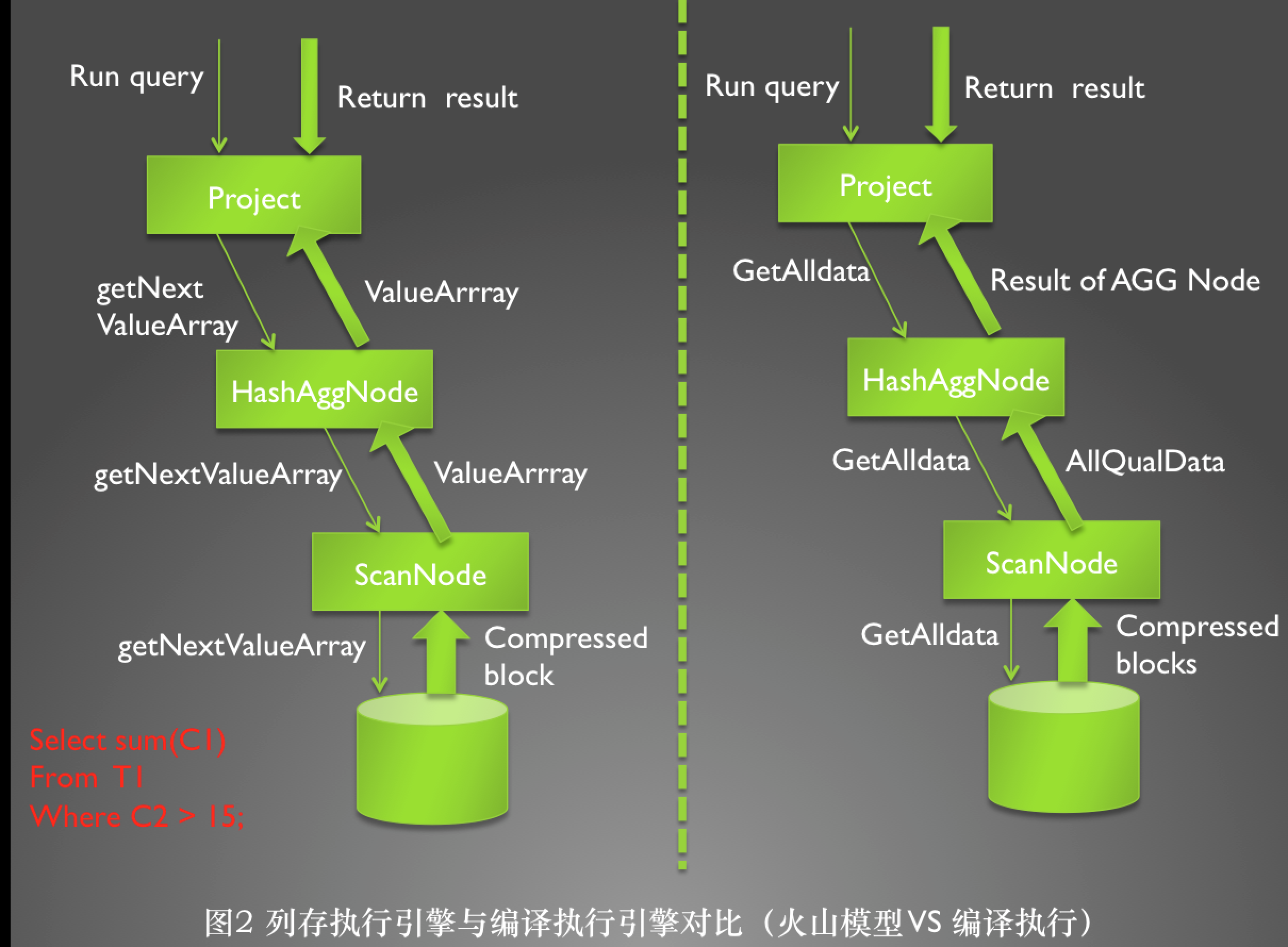
图2 给我们现实的是火山模型的向量化执行引擎与编译执行的向量化执行引擎之间执行方式的对比。鉴于在图1部分已经介绍过了火山模型,在这里我们讲一下编译执行模型,这个模型也是从根节点开始往叶子节点调用,但是只调用一次,从叶子节点开始每一层都是执行完所有的操作之后,才向上返回结果。这样整颗执行计划树从跟节点到叶子节点只需要调用一次,彻底消除了因节点间函数调用而导致的CPU利用率不高的这个问题。 同样列存执行引擎所能够拿到的好处也是可以被编译执行模型使用。 但是这种模型有一个缺点就是每一个节点都需要将数据进行缓存,在数据量比较大的情况下,内存可能放不下这些数据,需要写盘,这样会造成额外的开销。
向量化执行引擎的优势与需要注意的方面
这部分我们主要给大家提一下向量化执行引擎的优势与需要注意的地方。
优势:
- 向量化执行引擎可以减少节点间的调度,提高CPU的利用率。
- 因为列存数据,同一列的数据放在一起,导致向量化执行引擎在执行的时候拥有了更多的机会能够利用的当前硬件与编译的新优化特征。
- 因为列存数据存储将同类型的类似数据放在一起使得压缩比能够达到更高,这样可以拉近一些磁盘IO能力与计算能力的差距。
需要注意的问题:
- 通信库效率问题 当前比较主流的OLAP类型的数据库架构,通常首选是MPP架构的数据库,因为MPP架构上是share nothing架构的,所以它的集群各执行节点是有通信需要的,通信效率的高低也是决定了查询执行效率。另外就是大集群情况下,如果使用tcp方式连接,连接数会受限。
- 数据读写争抢问题 这个问题本身不是向量化执行引擎的,而是列存带来的,因为列存储表每一列单独存储为一个文件,这样在写盘的时候有优化与没有优化的差距还是非常明显的。
- 列存数据过滤效率问题 列存数据过滤率问题,这个问题是源于,列存数据中的一个处理单元是由连续的N个值放在一起组成的一个Col(数组),然后再由多个Col的数组组成了一个处理单元。在进行过率的时候如何能够更加紧凑的放置数据是需要我们考虑列存在过滤掉效率和存放之间如何优化的问题。
- 表达式计算问题(LLVM) LLVM优化可以将表达式计算由遍历树多层调用模式变为,只调用一个函数的扁平式执行方式。这样可以极大的提高表达式的执行性能。值得一提的是LLVM技术的优势也可以应用在执行计划编译执行模型的构建上面。
总结
本文旨在给大家一个向量化执行引擎的概要介绍,给大家有一个初步印象,在我们阿里云自己的向量化执行引擎设计开发的过程中,会在很多方面遇到不少问题, 后续我们也尽量给大家分享这些细节的实现。