SQL Server · 特性分析 · 2012列存储索引技术
Author: 风移
摘要
MS SQL Server 2012首次引入了列存储索引(Columnstore Index)来加速数据分析(OLAP)和数据仓库(Data Warehouse)场景的查询,它主要是通过将数据按列压缩存储的方式来减少查询对磁盘IOPS开销和CPU开销,最终达到提升查询效率,降低响应时间的目的。当然,列存储索引也不是一把万能的钥匙,在SQL Server 2012版本中它有诸多非常严苛限制条件。 这篇文章会从以下几个方面来介绍列存储索引:
-
列存储索引所涉及到的基本概念
-
列存储索引的结构
-
列存储索引对查询性能的影响
-
MS SQL Server 2012上列存储索引的限制
-
解决列存储索引表只读问题
概念
首先让我们来看看列存储索引涉及到的几个关键的概念。
列存储技术
列存储技术背后的核心思想并不是微软首创的,早在上20世纪70年代,基于列的存储系统就与传统的行存储数据库管理系统一同出现了。微软数据库产品首次尝试从传统的行存储结构转变为面向列的存储方案是在SQL Server2012这个产品,以期望这种方案能够以最低限度的额外工作量换取更高的性能。
列存储索引
MS SQL Server列存储索引是使用列式数据格式(称为列存储)压缩存储、检索和管理数据的技术。它主要目标是将尽量多的数据加载至内存中,在进行数据处理时,使用访问内存的方式来替换从磁盘中读取数据。这种处理方式有两大优点,一是速度更快,二是硬盘的IOPS(每秒读写次数)消耗更低。
列存储索引压缩
数据压缩对于MS SQL Server来说已经不是什么新鲜玩意儿了,SQL Server支持数据库备份压缩,数据行压缩和数据页压缩,当然列存储索引压缩默认是开启的并且不允许禁用。相对于传统按行存储的结构来说,列存储索引这种按列来存储的特殊结构来说,压缩更加有效。这是因为表中的相同列数据属性相同,存储的数据也非常相近,有可能还有非常多的重复值,因此数据压缩比例更高,压缩效率更快,更少的磁盘I/O开销,数据读取需要更少的内存,相同内存中可以存储更多的数据。
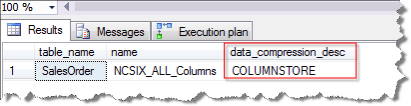
使用下面语句,我们可以发现本文的测试表dbo.SalesOrder的列存储索引NCSIX_ALL_Columns压缩算法是COLUMNSTORE。
USE ColumnStoreDB
GO
SELECT DISTINCT
table_name = object_name(part.object_id)
,ix.name
,part.data_compression_desc
FROM sys.partitions as part
INNER JOIN sys.indexes as ix
ON part.object_id = ix.object_id
AND part.index_id = ix.index_id
WHERE part.object_id = object_id('dbo.SalesOrder','U')
AND ix.name = 'NCSIX_ALL_Columns'
结果如下:
Column Segment and Row Group
在列存储索引中,SQL Server引入了两个全新的概念:Column Segment和Row Group。
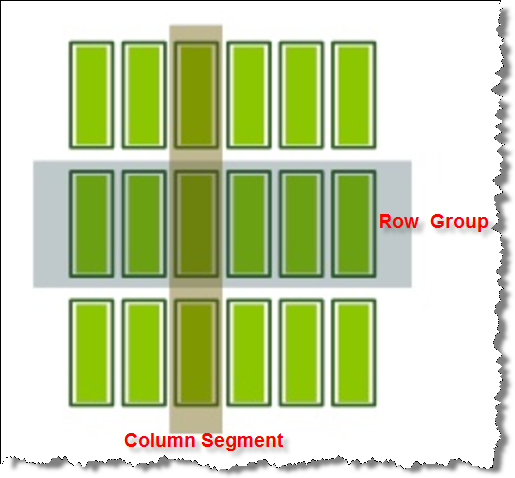
Column Segment:是SQL Server列存储索引最基本的存储单元,列存储索引的每一列数据会被划分为一个或者多个Column Segment。它是一组经过压缩后物理存储在相同存储介质的列值。
Row Group:是一组同时被压缩成列存储格式的行,每一个Row Group中包含了每个列的一个Column Segment。Row Group定义了每一个Column Segment的列值。 以上的解释还是非常抽象和难于理解,做一个图,我们就很好理解什么Column Segment和Row GROUP了。
Batch Mode Processing
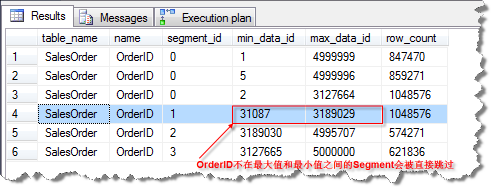
在SQL Server OLAP的场景中,做BI类分析型查询语句往往需要扫描非常大量的数据记录数。Batch Mode Processing 是SQL Server新的查询处理算法,专门设计来高效地处理大量数据的批处理算法,以加快统计分析类查询的效率。其实这个算法的原理实现非常简单,SQL Server有一个专门的系统视图sys.column_store_segments来存放列存储索引的每个列的每个Segments的最小值和最大值,当SQL Server执行Batch Mode Processing查询时,只需要和查询筛选条件对比,就可以知道对应的Segment是否包含满足条件的数据,从而可以实现快速的跳过哪些不满足条件的Segment。由于每个Segment中包含成千上万条记录,所以SQL Server筛选出满足条件的效率非常高,因此大大节约了磁盘I/O和因此带来的CPU开销。这种跳过不满足条件Segment的算法专业术语叫Segment Elimination。
USE ColumnStoreDB
GO
SELECT
table_name = object_name(part.object_id)
,col.name
,seg.segment_id
,seg.min_data_id
,seg.max_data_id
,seg.row_count
FROM sys.partitions as part
INNER JOIN sys.column_store_segments as seg
ON part.partition_id = seg.partition_id
INNER JOIN sys.columns as col
ON part.object_id = col.object_id
AND seg.column_id = col.column_id
WHERE part.object_id = object_id('dbo.SalesOrder','U')
AND seg.column_id = 1
ORDER BY seg.segment_id
结果如下:
行列存储结构对比
其实在列存储索引引入SQL Server之前,SQL Server的索引我们通常不叫行存储索引,而是叫B-Tree索引,因为SQL Server的行存储索引是按照B-Tree结构来组织的。这一节我们来对比基于行存储和基于列存储的结构差异。
行存储结构
在传统的基于行存储的结构中,表中每一行数据会存储在一起。如果用户需要其中的某个或者某几个字段的数据,SQL Server系统必须先将满足条件的记录所有字段的值载入内存中,然后再从中筛选出用户需要的列。换句话说,用户的查询语句横向筛选是通过索引(传统的B-Tree索引)来快速完成,而纵向列的筛选由于基于行存储的设计而浪费了许多的系统性能,这些性能浪费包括载入过多列数据导致的内存浪费,磁盘I/O资源的浪费开销,和因此而带来的CPU开销。那就让我们看看基于行存储的结构图:

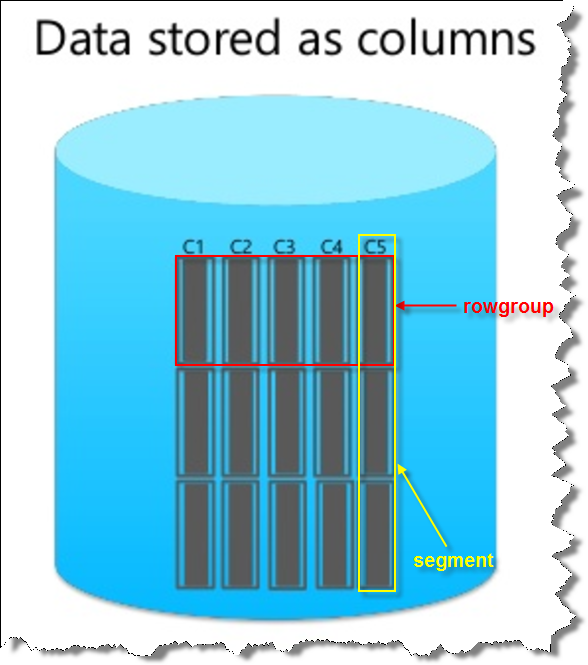
列存储结构
为了解决行存储结构导致资源浪费和多余开销,从MS SQL Server 2012开始,微软引入了基于列存储的新结构,具体使用在列存储索引这个方面。列存储结构是将数据按列来存储,每一列的数据存放在一起。这样当用户在执行查询的时候,可以快速拿到这一列的所有数据,而不会浪费多余的IO资源和相应的CPU开销。除了存储结构的变化外,微软还对列存储索引默认启用了数据压缩功能,进一步减少了IO开销。列存储索引的结构如下:
行列存储结构对比
以上是比较理论的认知,稍显抽象,让我们来看一个典型的例子,从具体的例子详细分析基于行存储和基于列存储的数据获取方式上的差异。 首先,让我们来创建测试环境数据库ColumnStoreDB,所需要使用到的表dbo.AutoType和dbo.SalesOrder,以及相应的数据初始化。为了照顾到后面《解决列存储索引表只读问题》章节,我将dbo.SalesOrder创建为分区表。
-- Create testing database
IF DB_ID('ColumnStoreDB') IS NULL
CREATE DATABASE ColumnStoreDB;
GO
USE ColumnStoreDB
GO
IF OBJECT_ID('dbo.AutoType', 'U') IS NOT NULL
BEGIN
DROP TABLE dbo.AutoType
END
GO
-- create demo table autoType
CREATE TABLE dbo.AutoType
(
AutoID INT IDENTITY(101,1) NOT NULL PRIMARY KEY,
Make VARCHAR(20) NOT NULL,
Model VARCHAR(20) NOT NULL,
Color VARCHAR(15) NOT NULL,
ModelYear SMALLINT NOT NULL
);
-- data init
INSERT INTO dbo.AutoType
SELECT 'Ford', 'Explorer', 'white', 2003 UNION ALL
SELECT 'Satum', 'Lon', 'blue', 2003 UNION ALL
SELECT 'Lexus', 'GX460', 'gray', 2010 UNION ALL
SELECT 'Honda', 'CRV', 'blue', 2007 UNION ALL
SELECT 'Subaru', 'Legacy', 'green', 2008 UNION ALL
SELECT 'Honda', 'Civic', 'red', 1996 UNION ALL
SELECT 'Nissan', 'Sentra', 'silver', 2012 UNION ALL
SELECT 'Chevrolet', 'Tahoe', 'green', 1995 UNION ALL
SELECT 'Toyota', 'Celica', 'red', 1992 UNION ALL
SELECT 'BMW', 'X5', 'gray', 2002 UNION ALL
SELECT 'Subaru', 'Impreze', 'silver', 2011 UNION ALL
SELECT 'Volkswagen', 'Jetta', 'black', 1995 UNION ALL
SELECT 'Chevrolet', 'Impala', 'red', 2008 UNION ALL
SELECT 'Jeep', 'Liberty', 'gray', 2012 UNION ALL
SELECT 'Dodge', 'Dakota', 'blue', 2000
;
-- Create PARTITION FUNCTION & SCHEMA
CREATE PARTITION FUNCTION pf_SalesYear (datetime)
AS RANGE LEFT FOR VALUES
('2013-01-01 00:00', '2014-01-01 00:00', '2015-01-01 00:00', '2016-01-01 00:00', '2017-01-01 00:00', '2018-01-01 00:00')
;
GO
CREATE PARTITION scheme ps_SalesYear
AS PARTITION pf_SalesYear
ALL TO ([PRIMARY])
;
GO
-- create demo table SalesOrder
IF OBJECT_ID('dbo.SalesOrder', 'U') IS NOT NULL
BEGIN
DROP TABLE dbo.SalesOrder
END
GO
CREATE TABLE dbo.SalesOrder
(
OrderID INT NOT NULL
,AutoID INT NOT NULL
,UserID INT NOT NULL
,OrderQty INT NOT NULL
,Price DECIMAL(8,2) NOT NULL
,UnitPrice AS Price * OrderQty
,OrderDate DATETIME NOT NULL
) ON ps_SalesYear(OrderDate);
-- data init for 5 M records.
;WITH a
AS (
SELECT *
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9),(10)) AS a(a)
), RoundData
AS(
SELECT TOP(5000000)
OrderID = ROW_NUMBER() OVER (ORDER BY a.a)
,AutoIDRound = abs(checksum(newid()))
,Price = a.a * b.a * 10000
,OrderQty = a.a + b.a + c.a + d.a + e.a + f.a + g.a + h.a
FROM a, a AS b, a AS c, a AS d, a AS e, a AS f, a AS g, a AS h
)
INSERT INTO dbo.SalesOrder(OrderID, AutoID, UserID, OrderQty, Price, OrderDate)
SELECT
OrderID
,AutoID = cast(ROUND((13 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 101), 0) as int)
,UserID = cast(ROUND((500 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 10000), 0) as int)
,OrderQty
,Price = cast(Price AS DECIMAL(8,2))
,OrderDate = dateadd(day, -cast(ROUND((1099 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 1), 0) as int) ,'2017-01-10')
FROM RoundData;
GO
假如目前用户需要获取所有汽车的制造商和相应的制造年份,即查询语句如下:
SELECT Make, ModelYear FROM dbo.AutoType;
那么,对于传统的基于行存储的结构,SQL Server会首先将AutoType这个表所有的数据页(这里假设占用了3 页)载入SQL Server内存缓存中,然后筛选出两个必须的列返回给用户。换句话来说,在返回用户必须的两个字段之前,用户必须等待3个Pages的数据全部加载进入内存(这3个页中包含了无用的其他三个字段),如此势必导致磁盘I/O,内存使用量和CPU开销的浪费,最终必然导致用户的执行时间会被拉长。
相反的,对于列存储结构而言,列中数据是按列式存储的(一个Column Segment只包含某一个列的数据),当用户提交查询以后,系统可以很快的拿到这两个列的值,而无需去获取其他三个多余字段的值。
以上文字描述,可以形象为如下的结构图,图的左上角为行存储结构,图的右上角为列存储结构,图的左下角是行存储结构载入内存的过程,图的右下角是用户需要的最终结果。
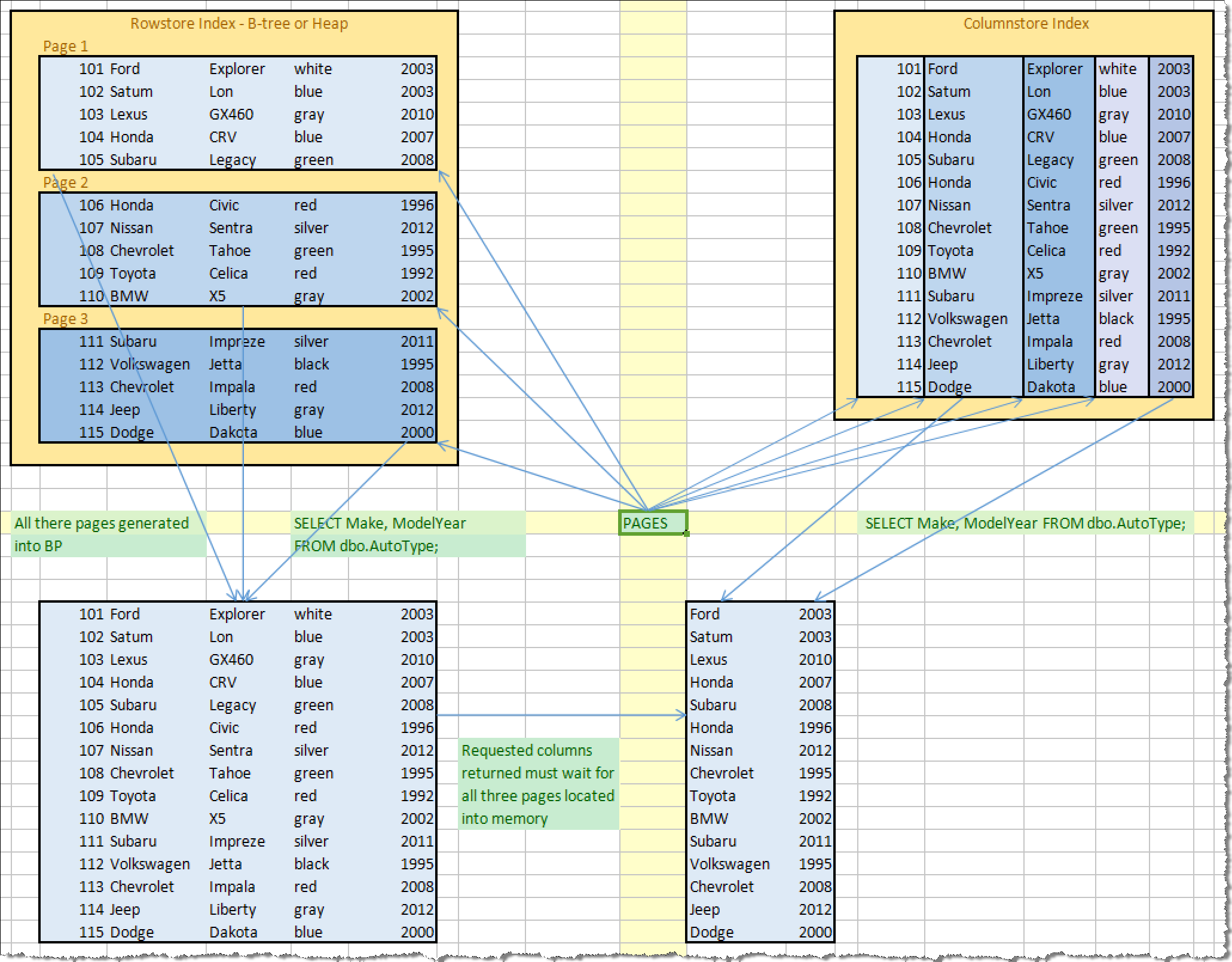
基于以上的分析,我们清楚的知道了基于列存储的结构和数据压缩功能为SQL Server执行查询语句大大节约了I/O消耗和因此而产生的CPU开销。
查询性能影响
基于上一节对列存储索引的特殊存储结构的分析,我们很清楚的知道列存储索引在执行查询过程中节约IOPS的同时,对数据仓库类统计查询语句性能有了非常大的性能提升,当然这里面也避免不了有非常多的坑。这一节让我们来看看列存储索引相对于行存储索引性能到底有多大的提升,在提升性能的同时,我们又需要踩过哪些坑,迈过哪些坎。
创建列存储索引
为了便于接下来的性能对比,我们同时创建了传统的B-Tree索引和列存储索引,代码如下:
-- create regular B-Tree Clustered Index
CREATE UNIQUE CLUSTERED INDEX CIX_OrderID
ON dbo.SalesOrder(OrderID, OrderDate)
WITH (ONLINE = ON)
ON ps_SalesYear(OrderDate);
--create nonclustered columnstore index
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_ALL_Columns
ON dbo.SalesOrder(OrderID, AutoID, UserID, OrderQty, Price, OrderDate)
GO
性能提升
首先让我们来分析下列存储索引为什么会提升查询性能:
-
列存储索引可以提供非常高压缩比,官方数据是可以节约10X的存储开销和成本。因为用户表中每列存储的数据属性相同,数据内容相似,有的甚至有非常多的重复值。
-
高数据压缩比为高性能查询提供了基础。因为在查询过程中压缩后的数据将使用更少磁盘IOPS来读取,相同内存大小可以存放更多的数据,高效的磁盘I/O带来CPU使用率的下降。
-
Batch Mode Processing提高查询性能,官方数据可以提高2-4X的性能。因为SQL Server可以一次性处理多行数据。
-
用户查询经常使用某一列或者某几个列字段数据。列存储索引可以大大减少物理磁盘的I/O开销。
按照官方的数据统计列存储索引查询性能有10X到100X的性能提升,当然也取决于表结构的设计和具体的查询语句。接下来让我们用实际例子看看列存储索引相较于B-Tree索引对查询性能的提升。
/*--=====================================================
MS SQL Server 2012 columnstore index query performance compare
--=====================================================*/
USE ColumnStoreDB
GO
DBCC DROPCLEANBUFFERS
GO
SET STATISTICS TIME ON
SET STATISTICS IO ON
-- Columnstore index query
SELECT
AutoID
,SalesQty = SUM(OrderQty)
,SalesAmount = SUM(UnitPrice)
FROM dbo.SalesOrder WITH(INDEX=NCSIX_ALL_Columns)
GROUP BY AutoID
-- B-Tree Index query
SELECT
AutoID
,SalesQty = SUM(OrderQty)
,SalesAmount = SUM(UnitPrice)
FROM dbo.SalesOrder WITH (INDEX = CIX_OrderID)
GROUP BY AutoID
I/O、CPU和执行时间的对比:
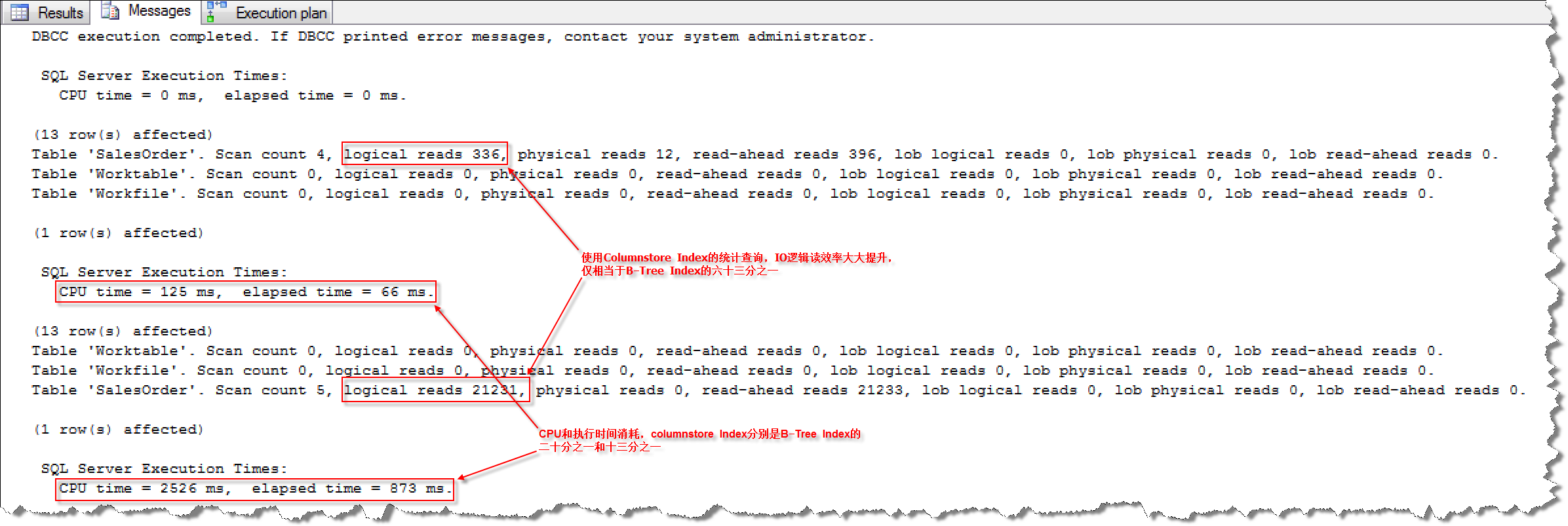 列存储索引的I/O逻辑读消耗为336,B-Tree索引I/O逻辑读为21231,是前者的63倍;列存储索引CPU消耗为125;B-Tree索引CPU消耗为2526,是前者的20倍;列存储索引执行时间消耗为66,B-Tree索引执行时间消耗为873,是前者的13倍。
列存储索引的I/O逻辑读消耗为336,B-Tree索引I/O逻辑读为21231,是前者的63倍;列存储索引CPU消耗为125;B-Tree索引CPU消耗为2526,是前者的20倍;列存储索引执行时间消耗为66,B-Tree索引执行时间消耗为873,是前者的13倍。
执行计划中的性能消耗对比:
 列存储索引占5%,而B-Tree 索引占95%,也就是B-Tee储索引性能消耗是列存储索引的19倍。
列存储索引占5%,而B-Tree 索引占95%,也就是B-Tee储索引性能消耗是列存储索引的19倍。
执行计划对比:
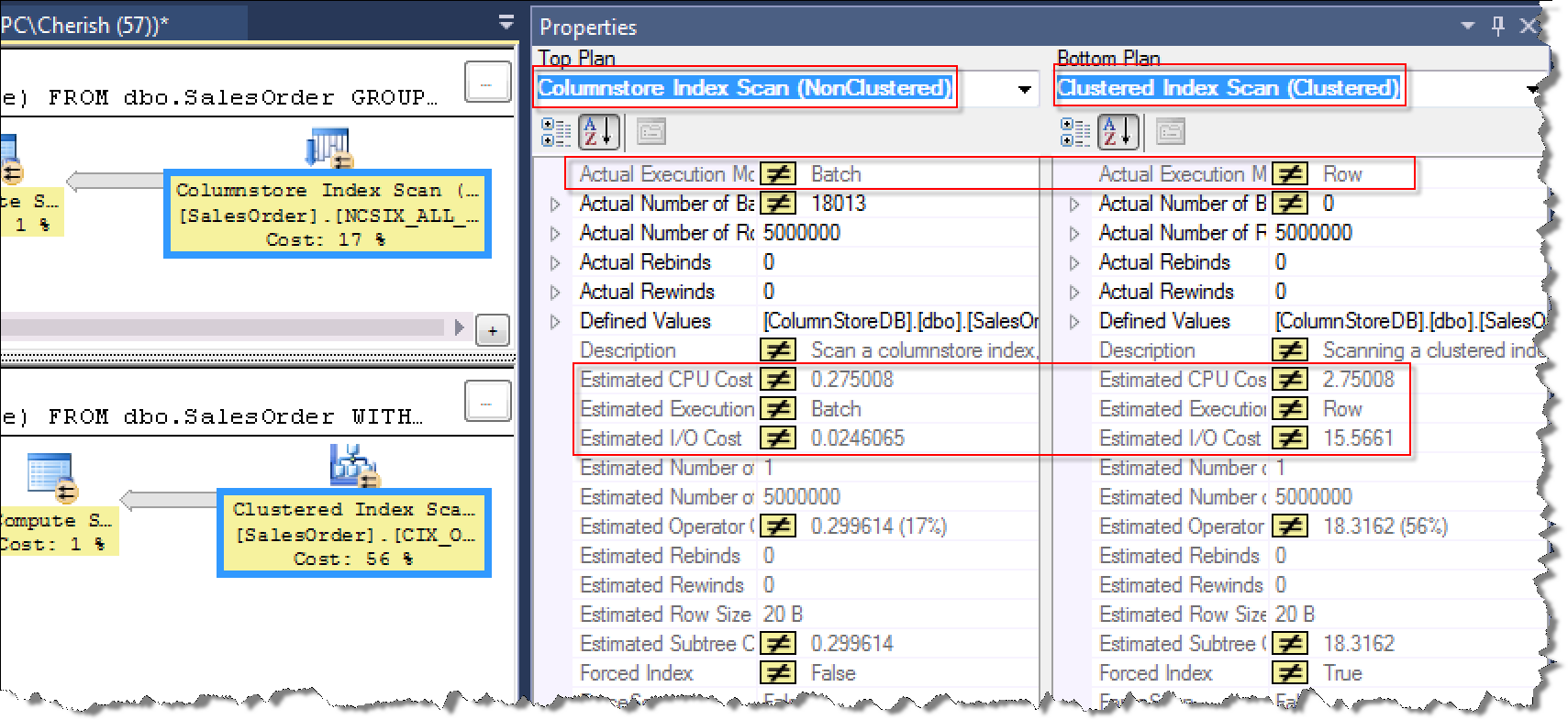 列存储索引走的Batch Mode Processing,B-Tree索引走的是Row Mode Processing;列存储索引的CPU预估消耗为0.275008,B-Tree索引的CPU预估消耗为2.75008,是前者的10倍;列存储索引预估I/O消耗为0.0246065,B-Tee索引预估的I/O消耗为15.5661,是前者的632倍。
列存储索引走的Batch Mode Processing,B-Tree索引走的是Row Mode Processing;列存储索引的CPU预估消耗为0.275008,B-Tree索引的CPU预估消耗为2.75008,是前者的10倍;列存储索引预估I/O消耗为0.0246065,B-Tee索引预估的I/O消耗为15.5661,是前者的632倍。
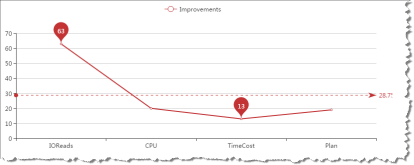
总结一下列存储索引在IO读、CPU消耗、时间消耗和执行计划展示中的性能有13到63倍的性能提升,平均有28.75倍提升,总结如下图所示:
踩坑场景
相较于B-Tree索引,列存储索引在IO,CPU,时间消耗方面,列存储索引的效率都有非常明显的提升。但是,请不要高兴得太早,如果不注意查询语句的写法,列存储索引可能不会走高效的Batch Mode Processing,而走低效的Row Mode Processing,进而达不到你想要的效果。以下几个小节是教大家如何升级打怪,踩坑迈坎。
INNER JOIN使用Batch Mode而OUTER JOIN使用Row Mode
在OLAP场景中,创建了列存储索引的表,使用Batch Mode处理查询效率要远远高于Row Mode处理。其中一种典型的情况是使用等值连接(INNER JOIN)SQL Server会采用Batch Mode来处理查询,而使用外链接(OUTER JOIN)的情况,SQL Server会采取Row Mode处理查询,效率天壤之别。让我们来看看如何改写OUTER JOIN查询,使查询计划能够走到Batch Mode,从而大大提高查询性能。
INNER JOIN使用Batch Mode:显示所有存在销售记录的汽车销售收入和销量
-- Batch mode processing will be used when INNER JOIN
SELECT
at.Model
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.AutoType AS at
INNER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY at.Model
实际的执行计划Actual Execution Mode为Batch
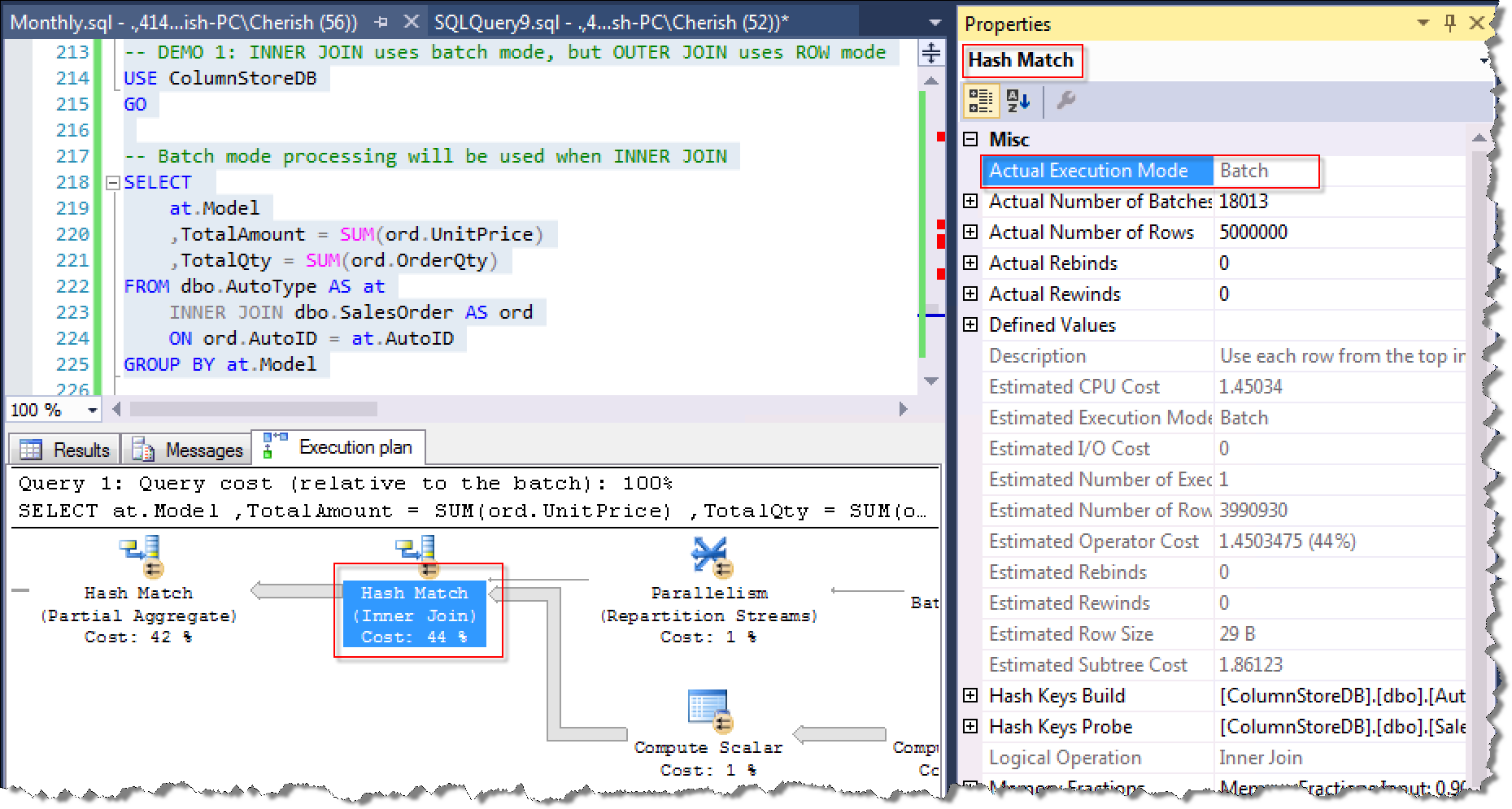
OUTER JOIN使用Row Mode:显示所有汽车的销售收入和销量
-- BUT row mode processing will be used when OUTER JOIN
SELECT
at.Model
,TotalAmount = ISNULL(SUM(ord.UnitPrice), 0)
,TotalQty = ISNULL(SUM(ord.OrderQty), 0)
FROM dbo.AutoType AS at
LEFT OUTER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY at.Model
ORDER BY ISNULL(SUM(ord.UnitPrice), 0) DESC
实际的执行计划Actual Execution Mode为Row
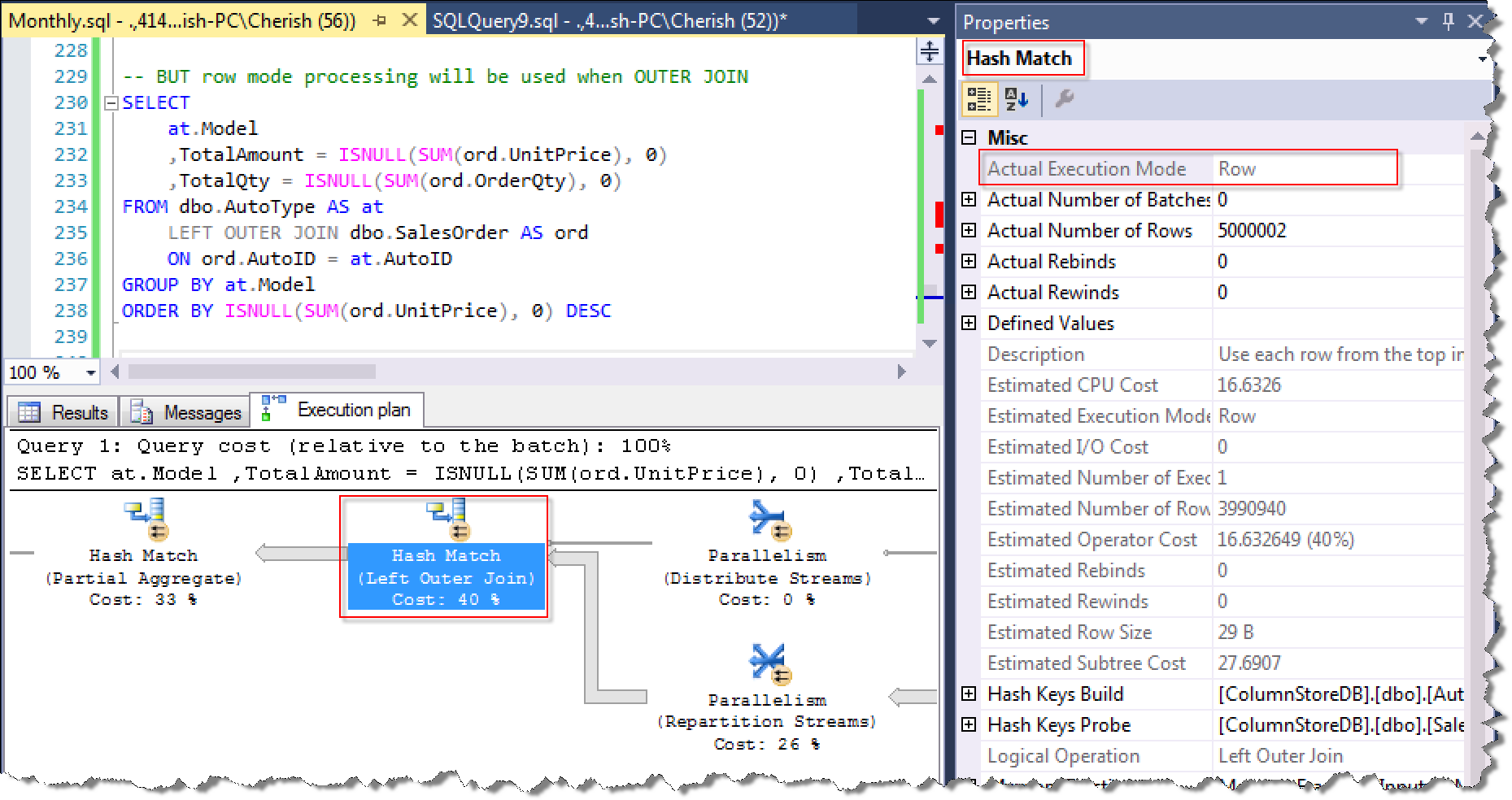 如何踩过OUTER JOIN使用Row Mode的坑呢?思路其实很简单,因为从第一部分我们知道,使用INNER JOIN执行计划是可以走到Batch Mode的,那么我们可以先找出有销售记录的所有汽车的销售额和销量结果集(这个结果集应该已经非常小了),然后再使用AutoType表来OUTER JOIN第一步的结果集,就得到我们想要的结果。
如何踩过OUTER JOIN使用Row Mode的坑呢?思路其实很简单,因为从第一部分我们知道,使用INNER JOIN执行计划是可以走到Batch Mode的,那么我们可以先找出有销售记录的所有汽车的销售额和销量结果集(这个结果集应该已经非常小了),然后再使用AutoType表来OUTER JOIN第一步的结果集,就得到我们想要的结果。
-- OUTER JOIN workaround
;WITH intermediateData
AS
(
SELECT
at.AutoID
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.AutoType AS at
INNER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY at.AutoID
)
SELECT
at.Model
,TotalAmount = ISNULL(itm.TotalAmount, 0)
,TotalQty = ISNULL(itm.TotalQty, 0)
FROM dbo.AutoType AS at
LEFT OUTER JOIN intermediateData AS itm
ON itm.AutoID = at.AutoID
ORDER BY itm.TotalAmount DESC
在处理掉数据量最大的这一步,实际的执行计划Actual Execution Mode为Batch
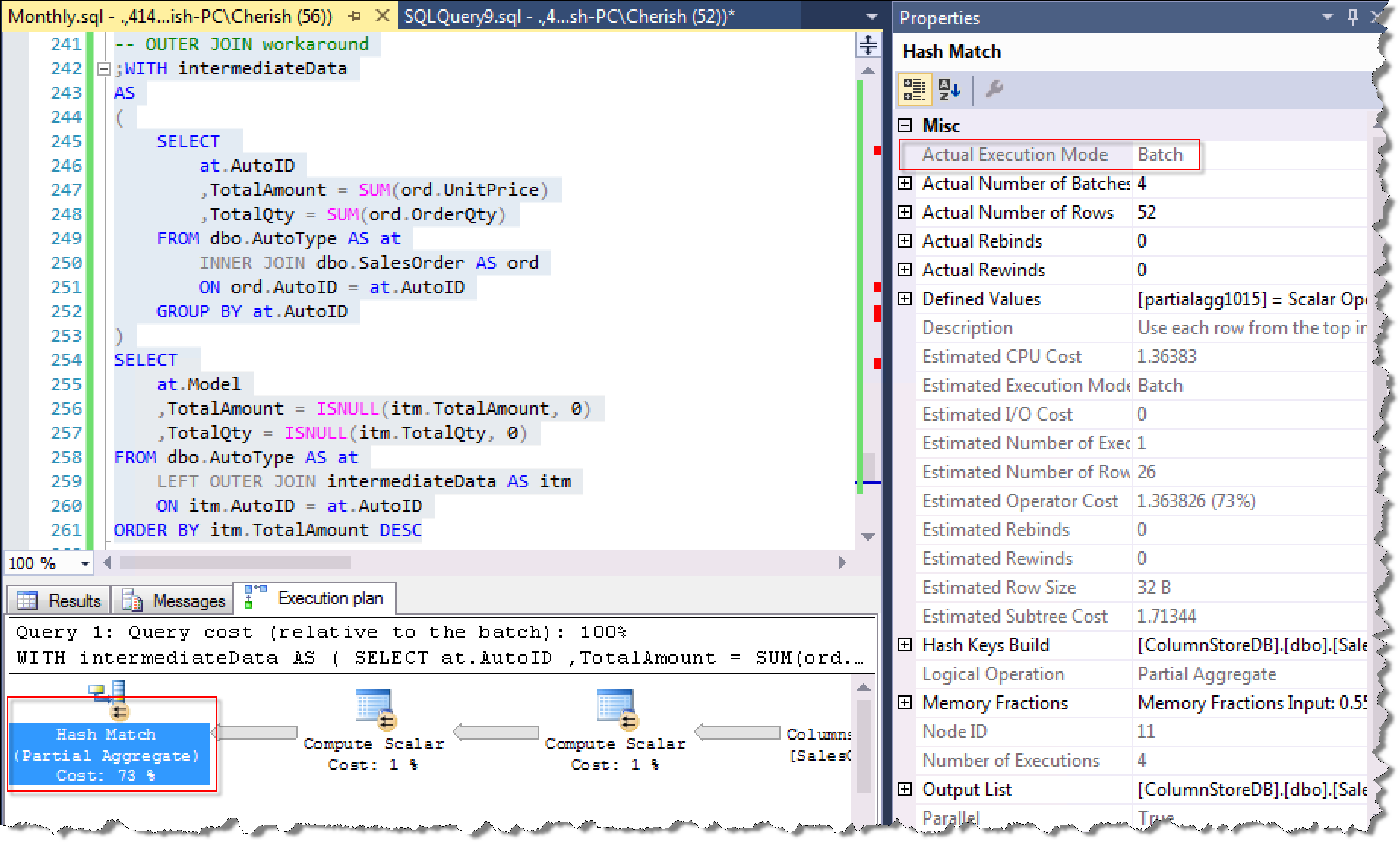
OUTER JOIN踩坑前后写法执行的CPU和时间消耗对比:
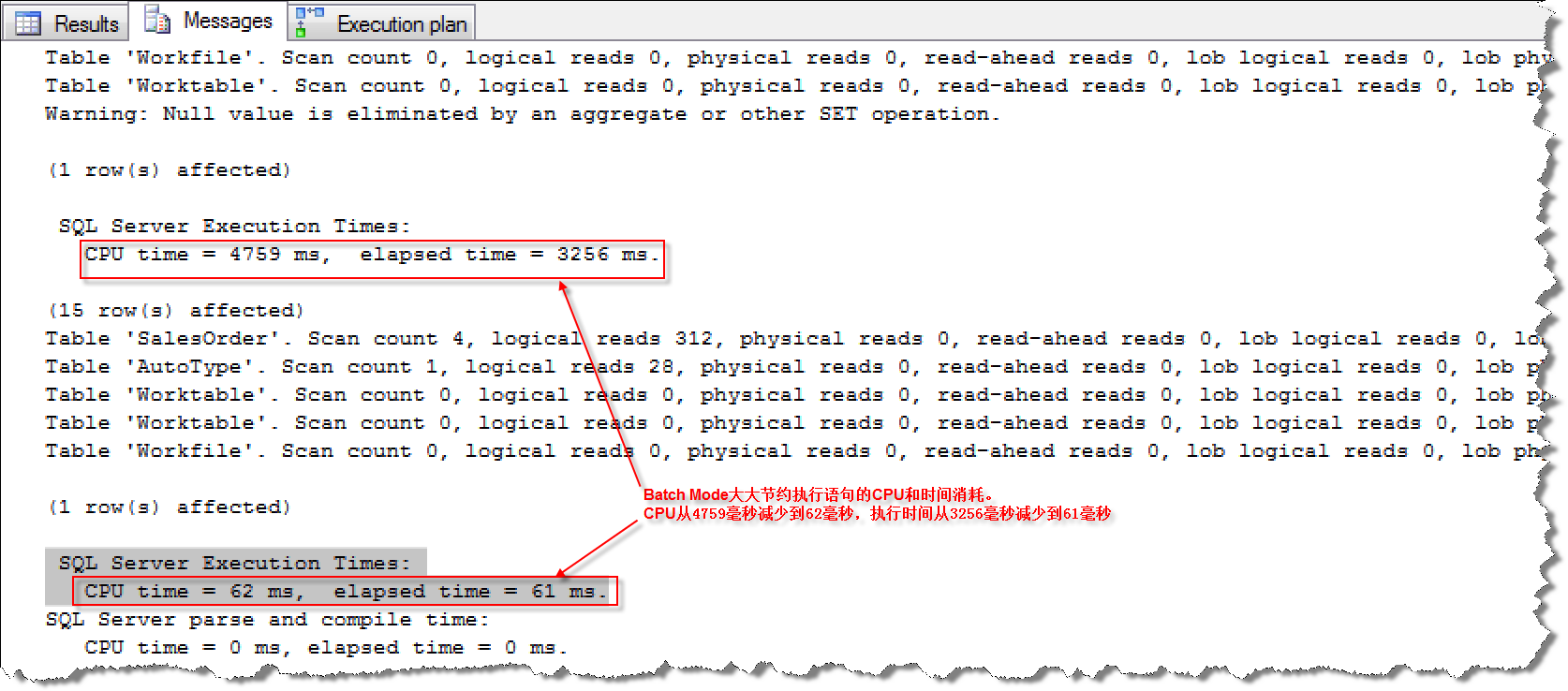
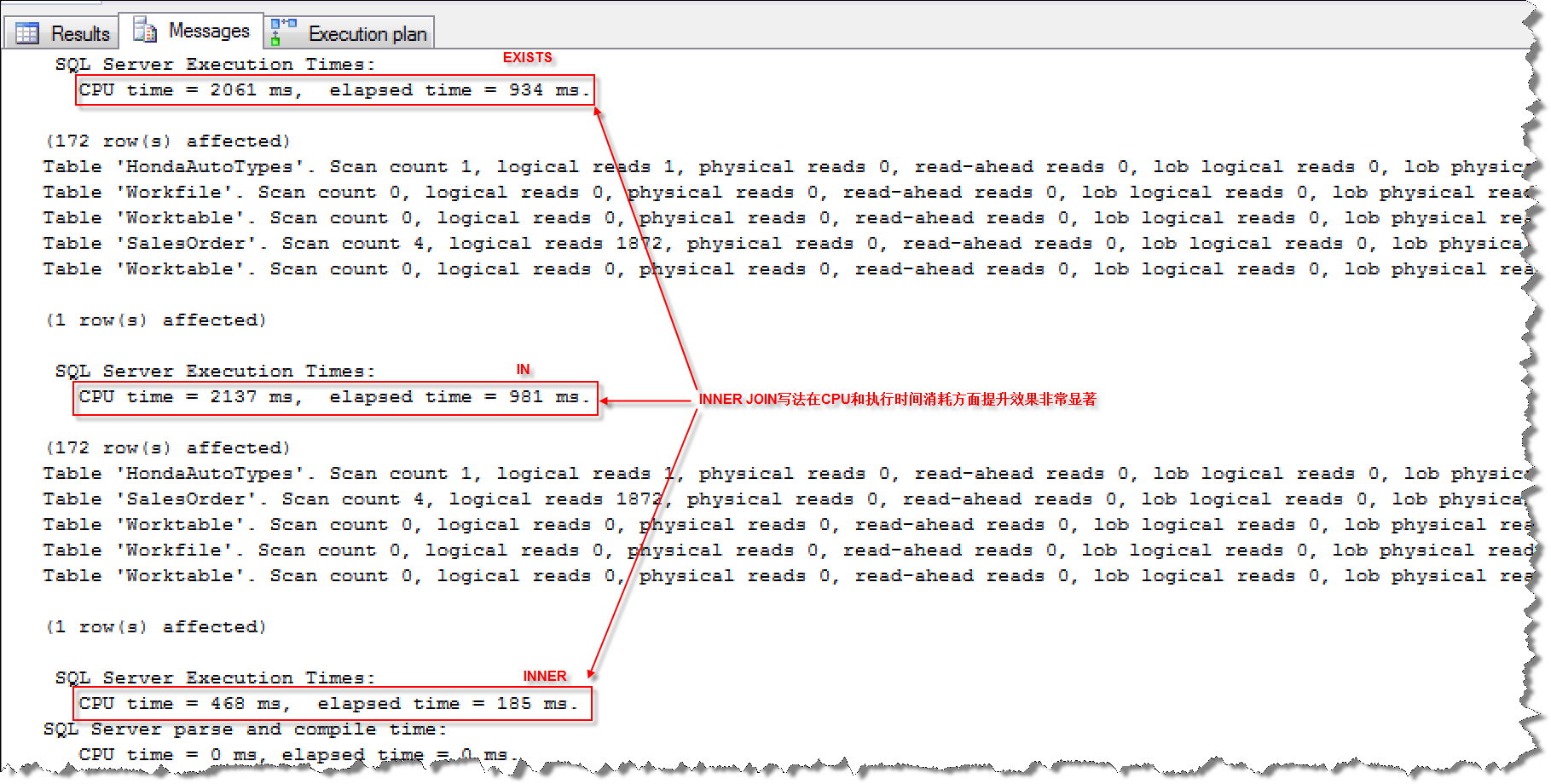
IN & EXISTS使用Row Mode
IN和EXISTS写法在查询列存储表时,也是使用Row Mode,所以我们需要改写为使用Batch Mode执行方式。方法是使用INNER JOIN方式或者是在IN字句里面使用常量。
-- DEMO 2: IN & EXISTS both use row mode processing
IF OBJECT_ID('dbo.HondaAutoTypes', 'U') IS NOT NULL
BEGIN
TRUNCATE TABLE dbo.HondaAutoTypes
DROP TABLE dbo.HondaAutoTypes
END
SELECT *
INTO dbo.HondaAutoTypes
FROM dbo.AutoType
WHERE make = 'Honda'
-- IN use row mode
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.SalesOrder AS ord
WHERE ord.AutoID IN(SELECT AutoID FROM dbo.HondaAutoTypes)
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
ORDER BY 1 DESC
-- EXISTS use row mode too.
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.SalesOrder AS ord
WHERE EXISTS(SELECT TOP 1 * FROM dbo.HondaAutoTypes WHERE AutoID = ord.AutoID)
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
ORDER BY 1 DESC
-- IN & EXISTS workaround using INNER JOIN
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.SalesOrder AS ord
INNER JOIN dbo.HondaAutoTypes AS hat
ON ord.AutoID = hat.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
ORDER BY 1 DESC
-- or we also can use IN(<list of constants>) to make it use batch mode.
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.SalesOrder AS ord
WHERE ord.AutoID IN(104,106)
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
ORDER BY 1 DESC
执行计划对比:
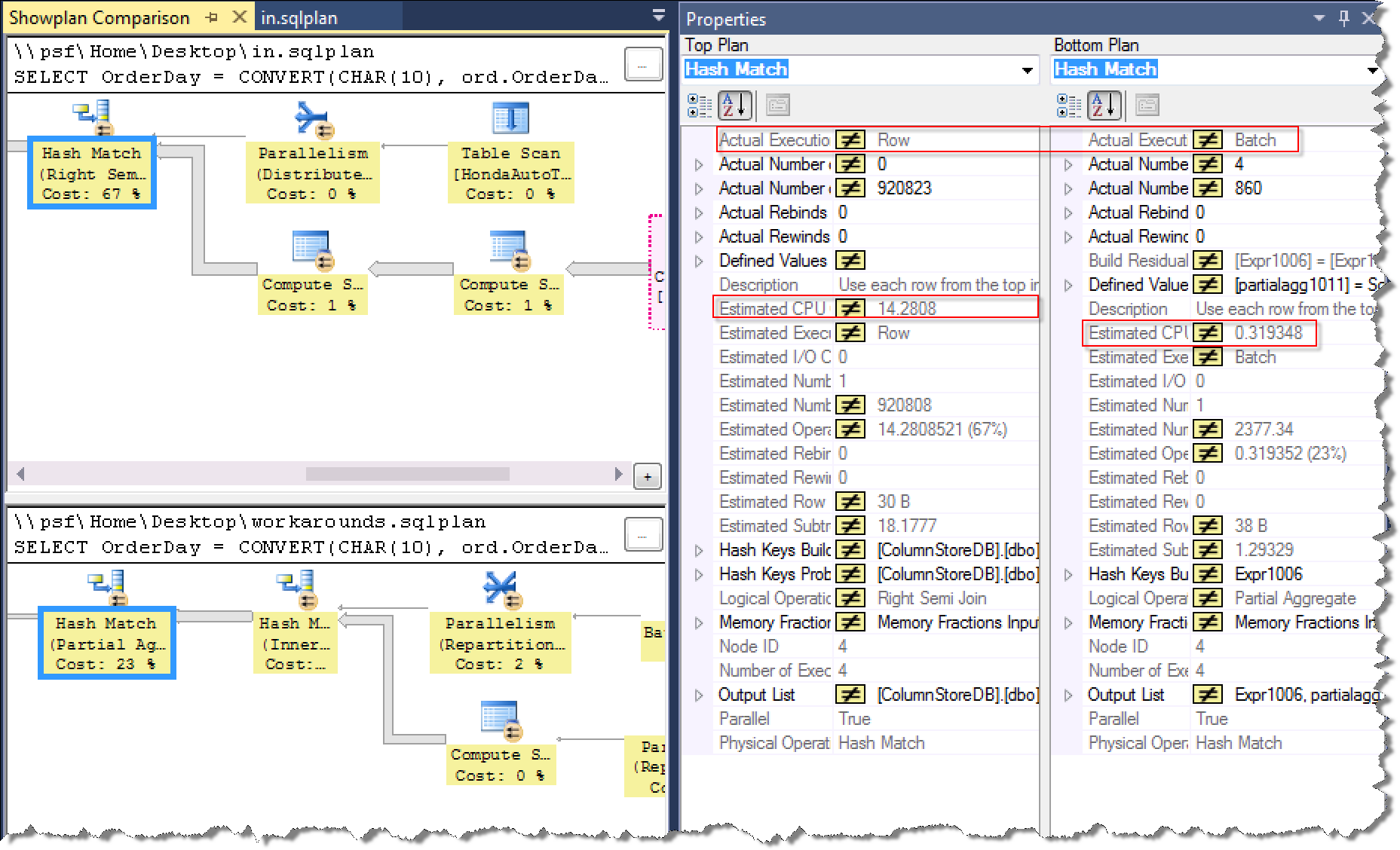 执行CPU和时间消耗对比:
执行CPU和时间消耗对比:
UNION ALL
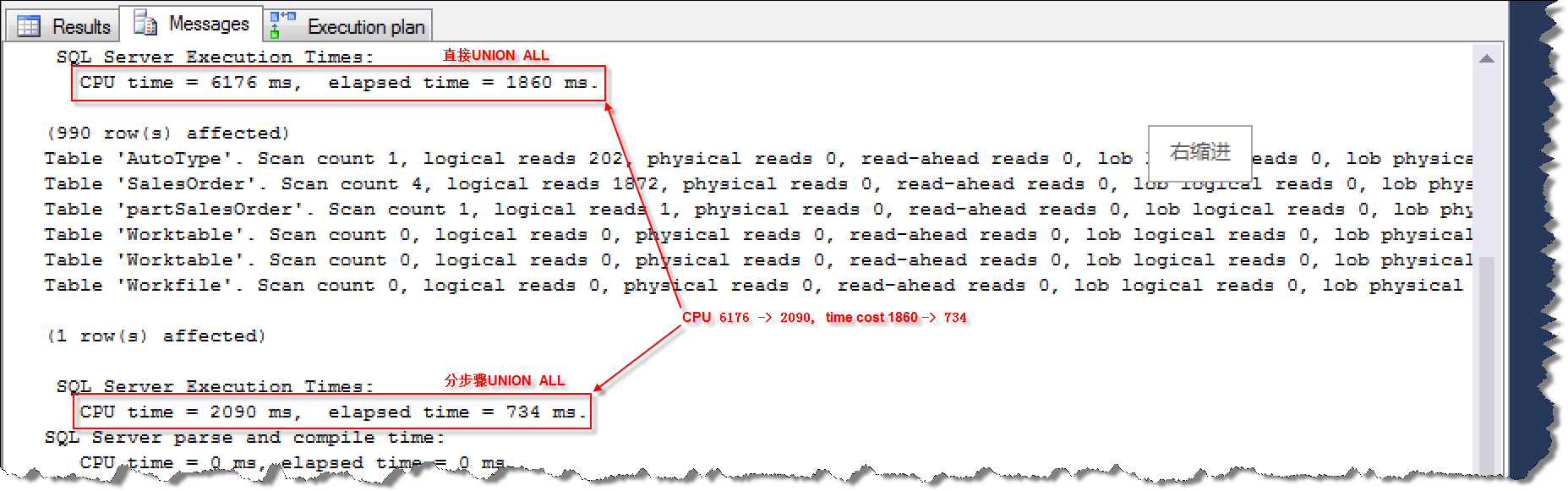
在大多数情况下UNION ALL操作会导致列存储表走Row Mode执行方式,这种方式相对于Batch Mode执行性能低很多。改写UNION ALL方式非常有技巧,具体的思路是:
先将UNION ALL的各个查询分之汇总出来,然后将各分支的汇总数据再UNION ALL起来,最后再做一次统计汇总,就是我们想要的结果集了。
-- DEMO 3: UNION ALL usually use row mode
IF OBJECT_ID('dbo.partSalesOrder', 'U') IS NOT NULL
BEGIN
TRUNCATE TABLE dbo.partSalesOrder
DROP TABLE dbo.partSalesOrder
END
SELECT TOP 100 *
INTO dbo.partSalesOrder
FROM dbo.SalesOrder
WHERE OrderID < 2500000;
-- UNION ALL mostly use row mode
;WITH unionSalesOrder
AS
(
SELECT *
FROM dbo.SalesOrder AS ord
UNION ALL
SELECT *
FROM dbo.partSalesOrder AS pord
)
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.AutoType AS at
INNER JOIN unionSalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
ORDER BY 1 DESC
-- UNION ALL workaround
;WITH unionSaleOrders
AS(
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.AutoType AS at
INNER JOIN SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
), unionPartSaleOrders
AS
(
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,TotalAmount = SUM(ord.UnitPrice)
,TotalQty = SUM(ord.OrderQty)
FROM dbo.AutoType AS at
INNER JOIN dbo.partSalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
), unionAllData
AS
(
SELECT *
FROM unionSaleOrders
UNION ALL
SELECT *
FROM unionPartSaleOrders
)
SELECT
OrderDay
,TotalAmount = SUM(TotalAmount)
,TotalQty = SUM(TotalQty)
FROM unionAllData
GROUP BY OrderDay
ORDER BY OrderDay DESC
执行计划的对比
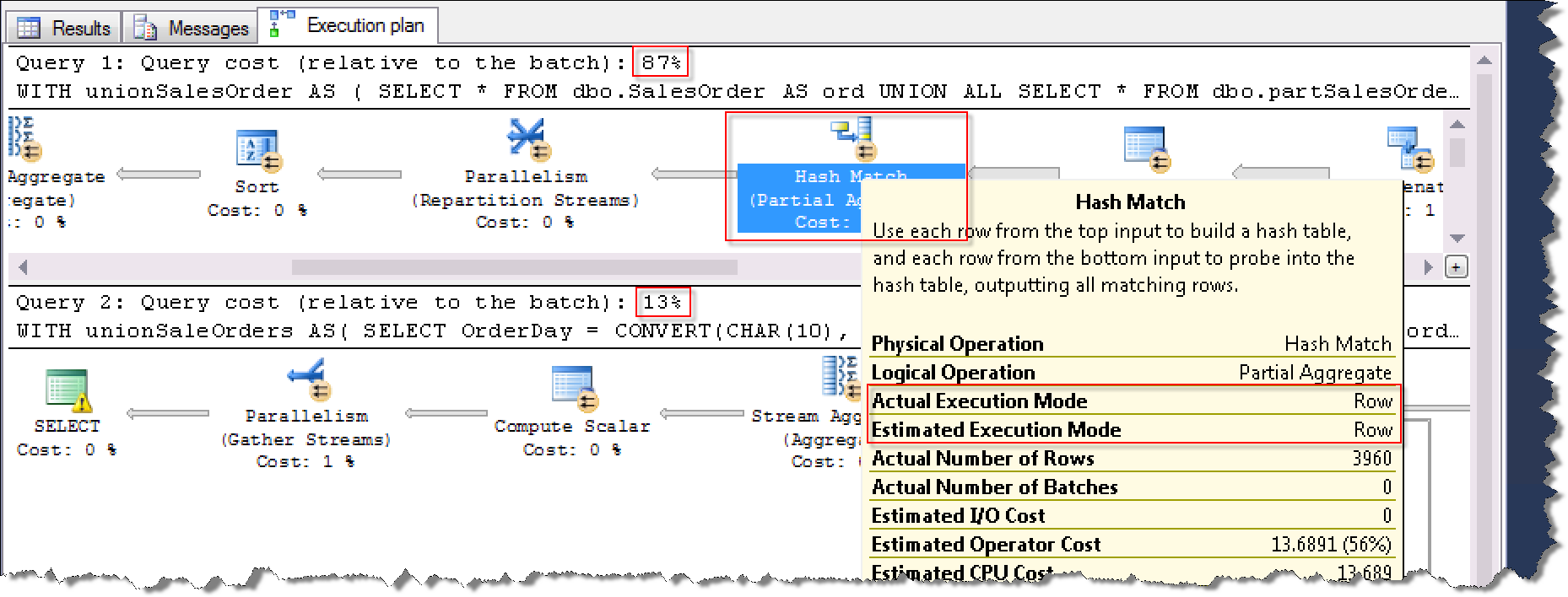 执行过程CPU和时间消耗对比:
执行过程CPU和时间消耗对比:
Scalar Aggregates
有时候,我们一个简单的统计查询记录总数的操作在列存储表中也可以有优化的写法,思想是将一个一次性的统计汇总化简为繁,使用分级汇总的方式获取一个较小的结果集,最后再求总和。这种优化方法的思想是利用了第一次统计汇总可以使用Batch Mode操作方式,从而大大提高查询效率。
-- DEMO 4: Scalar Aggregates
SELECT COUNT(*)
FROM dbo.SalesOrder
-- workaround
;WITH salesOrderByAutoId([AutoID], cnt)
AS(
SELECT [AutoID], count(*)
FROM dbo.SalesOrder
GROUP BY [AutoID]
)
SELECT SUM(cnt)
FROM salesOrderByAutoId
-- END DEMO 4
执行计划对比:
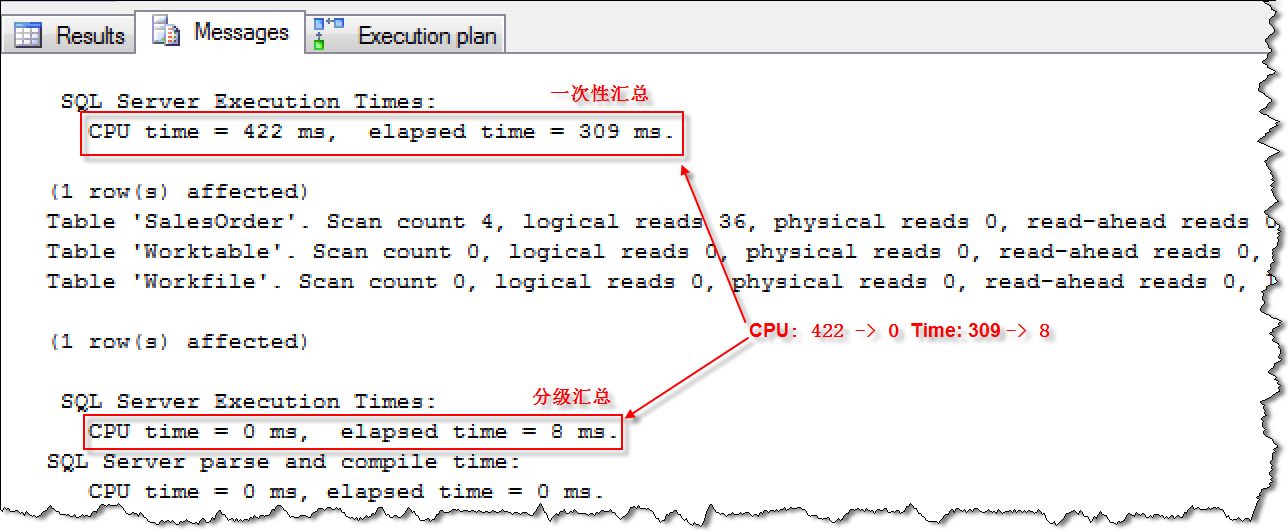
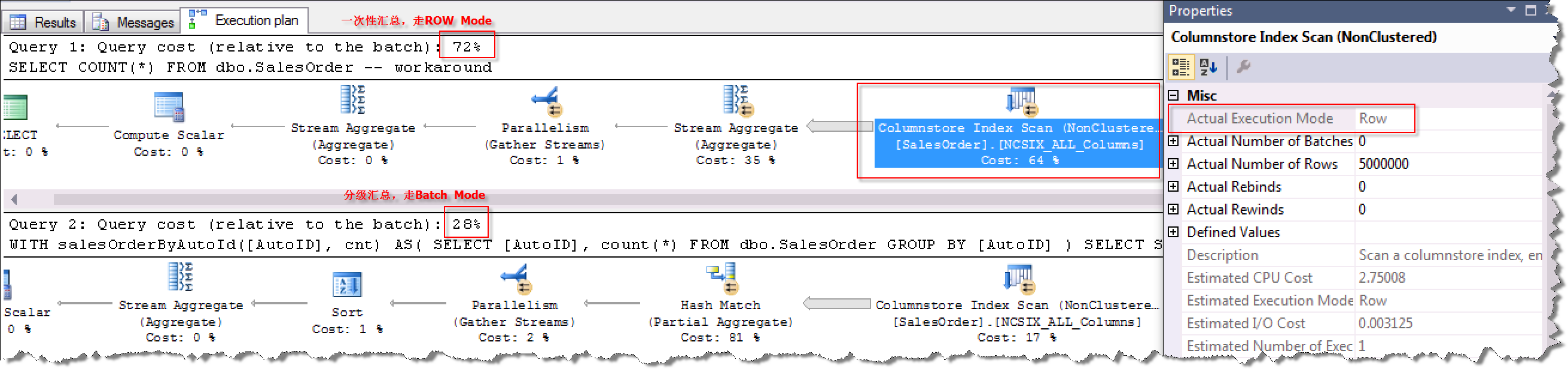 执行CPU和时间消耗对比:
执行CPU和时间消耗对比:
Multiple DISTINCT Aggregates
当SQL Server有两个或者两个以上的DISTINCT聚合操作的时候,会产生Table Spool操作,这个动作的产生当然会伴随着Table Spool的读写操作,更要命的是SQL Server对Table Spool读写操作是单线程的并且采用Row Mode方式执行,所以执行效率非常低下。改写的方式是采用将多个DISTINCT操作分开汇总,最后再INNER JOIN在一起,以此来避免Table Spool操作。
-- DEMO 5: Multiple DISTINCT Aggregates
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,AutoIdCount = COUNT(DISTINCT ord.[AutoID])
,UserIdCount = COUNT(DISTINCT ord.[UserID])
FROM dbo.AutoType AS at
INNER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
-- workaround
;WITH autoIdsCount(orderDay, AutoIdCount)
AS(
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,AutoIdCount = COUNT(DISTINCT ord.[AutoID])
FROM dbo.AutoType AS at
INNER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
), userIdsCount(orderDay, UserIdCount)
AS(
SELECT
OrderDay = CONVERT(CHAR(10), ord.OrderDate, 120)
,UserIdCount = COUNT(DISTINCT ord.[UserID])
FROM dbo.AutoType AS at
INNER JOIN dbo.SalesOrder AS ord
ON ord.AutoID = at.AutoID
GROUP BY CONVERT(CHAR(10), ord.OrderDate, 120)
)
SELECT
auto.orderDay
,auto.AutoIdCount
,ur.UserIdCount
FROM autoIdsCount AS auto
INNER JOIN userIdsCount AS ur
ON auto.orderDay = ur.orderDay
-- END DEMO 5
执行计划对比:
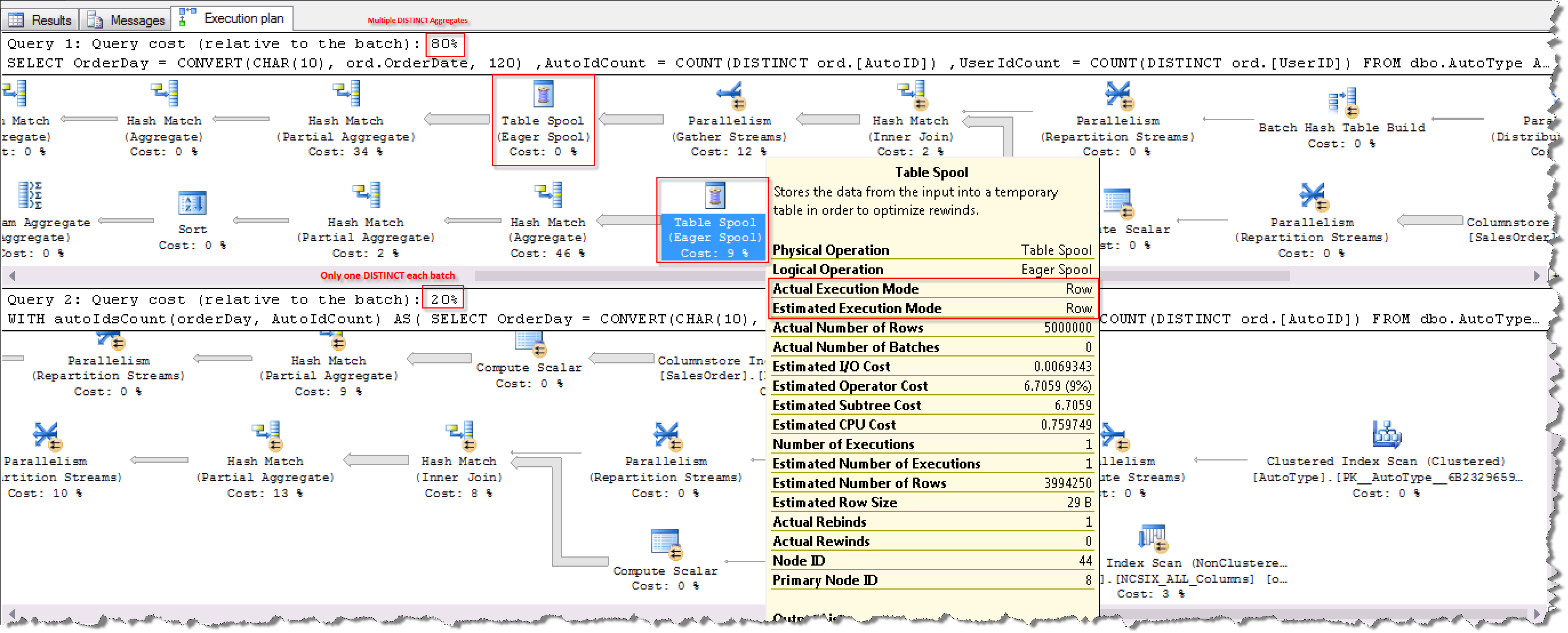
执行CPU和时间消耗对比:

限制条件
我们看到列存储索引对统计查询(数据分析OLAP或者数据仓库Data Warehouse场景)性能有非常显著的提升,按照微软SQL Server的一向“恶习”,新特性的推出都附带有很多的限制条件,当然列存储索引也不例外。而这些限制条件在不同的SQL Server 版本中又各不相同,这一小节,让我们来看看列存储索引在SQL Server 2012版本中的诸多限制。
SQL Server 2012列存储索引表的限制
-
每张表只允许创建一个列存储索引
-
不支持创建Clustered列存储索引,仅支持Nonclustered格式(注:从SQL Server 2014及以后的产品已经支持创建Clustered列存储索引)
-
不支持创建Unique和Filtered列存储索引
-
不支持对列存储索引的排序ASC或者DESC功能
-
计算列不允许包含在列存储索引中
-
列存储索引不支持在线创建(ONLINE选项)
-
列存储索引不支持Include字句
-
不允许重组列存储索引
-
不支持在视图上创建列存储索引
-
创建了列存储索引的表会成为只读表,不允许UPDATE、DELETE和INSERT(注:从SQL Server 2014及以后开始已经提供可更新列存储索引)
-
列存储索引包含的列不能超过1024
-
列存储索引不能包含稀疏列
-
列存储索引不能包含Filestream列
-
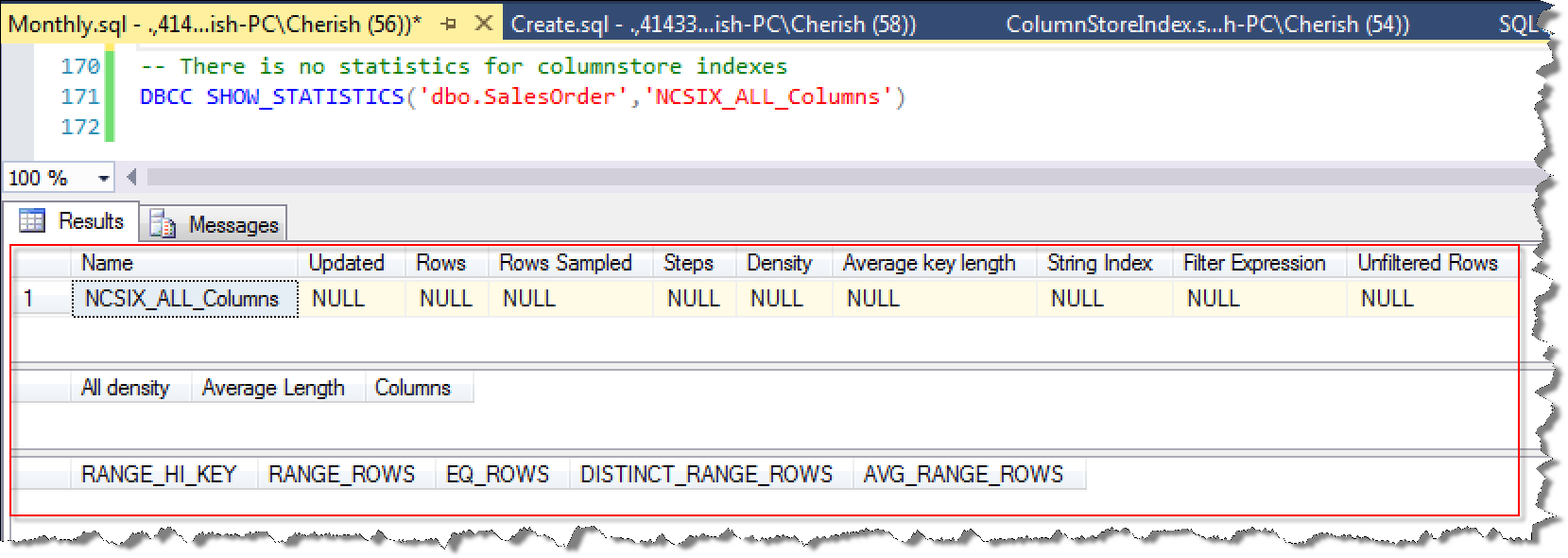
列存储索引不关心行记录数和行数据库分布,所以不使用统计信息
- 列存储索引不能与以下功能共同使用
- 数据库复制技术(Replication)
- 更改跟踪(Change Tracking)
- 变更数据库捕获(Data Change Capture)
- 文件流(Filestream)
- 行、列压缩功能(Data Compression)
- 列存储索引包含列字段数据类型不允许:
- 二进制数据类型:Binary、varbinary
- BLOB数据类型:ntext、text、image、varchar(max) 、nvarchar(max)、xml
- Uniqueidentifier
- Rowversion和timestamp
- sql_variant
- 精度大于18位的decimal和numeric
- 标量大于2的datetimeoffset
- CLR 类型
限制测试
以下是SQL Server 2012诸多限制的一个简单测试。
/*--=====================================================
MS SQL Server 2012 Columnstore index limitations
--=====================================================*/
-- Just accept only one columnstore index
-- create another one
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder
ON dbo.SalesOrder(OrderID,AutoID,OrderQty,Price,OrderDate);
GO
-- Does not support CLUSTERED columnstore index
CREATE CLUSTERED COLUMNSTORE INDEX CCSIX_SalesOrder
ON dbo.SalesOrder(OrderID,AutoID,OrderQty,Price,OrderDate);
GO
-- Does not support UNIQUE columnstore index
CREATE UNIQUE COLUMNSTORE INDEX UCSIX_SalesOrder
ON dbo.SalesOrder(OrderID,AutoID,OrderQty,Price,OrderDate);
GO
-- Does not accept ASC/DESC
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder_OrderDate
ON dbo.SalesOrder(OrderDate ASC);
GO
-- Does not accept computed column
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder_OrderDate
ON dbo.SalesOrder(OrderDate);
GO
-- Does not support online build index
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder_OrderDate
ON dbo.SalesOrder(OrderDate)
WITH (ONLINE = ON);
GO
-- Does not support include action
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder_OrderDate_@OrderID
ON dbo.SalesOrder(OrderDate)
INCLUDE(OrderID);
GO
-- Does not accept data length more than 18 numeric
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_SalesOrder_UnitPrice
ON dbo.SalesOrder(UnitPrice);
GO
-- Doesn't allow ALTER INDEX REORGANIZE
ALTER INDEX NCSIX_ALL_Columns
ON dbo.SalesOrder REORGANIZE;
-- Doesn't support create base on view
IF OBJECT_ID('dbo.V_SalesOrder', 'V') IS NOT NULL
DROP TABLE dbo.V_SalesOrder
GO
CREATE VIEW dbo.V_SalesOrder
AS
SELECT TOP 100 *
FROM dbo.SalesOrder
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_V_SalesOrder_ALL_Columns
ON dbo.V_SalesOrder(OrderID,AutoID,OrderQty,Price,OrderDate);
GO
-- columnstore index table will be read only
UPDATE TOP (1) A
SET OrderQty = 100
FROM dbo.SalesOrder AS A
DELETE TOP(1) A
FROM dbo.SalesOrder AS A
INSERT INTO dbo.SalesOrder(OrderID, AutoID, OrderQty, Price, OrderDate)
SELECT TOP 1 OrderID = OrderID + 1, AutoID, OrderQty, Price, OrderDate
FROM dbo.SalesOrder
GO
-- There is no statistics for columnstore indexes
DBCC SHOW_STATISTICS('dbo.SalesOrder','NCSIX_ALL_Columns')
错误信息如下:
Msg 35339, Level 16, State 1, Line 97
Multiple nonclustered columnstore indexes are not supported.
Msg 35338, Level 15, State 1, Line 103
Clustered columnstore index is not supported.
Msg 35301, Level 15, State 1, Line 107
CREATE INDEX statement failed because a columnstore index cannot be unique. Create the columnstore index without the UNIQUE keyword or create a unique index without the COLUMNSTORE keyword.
Msg 35302, Level 15, State 1, Line 112
CREATE INDEX statement failed because specifying sort order (ASC or DESC) is not allowed when creating a columnstore index. Create the columnstore index without specifying a sort order.
Msg 35339, Level 16, State 1, Line 117
Multiple nonclustered columnstore indexes are not supported.
Msg 35318, Level 15, State 1, Line 124
CREATE INDEX statement failed because the ONLINE option is not allowed when creating a columnstore index. Create the columnstore index without specifying the ONLINE option.
Msg 35311, Level 15, State 1, Line 128
CREATE INDEX statement failed because a columnstore index cannot have included columns. Create the columnstore index on the desired columns without specifying any included columns.
Msg 35341, Level 16, State 1, Line 134
CREATE INDEX statement failed. A columnstore index cannot include a decimal or numeric data type with a precision greater than 18. Reduce the precision of column 'UnitPrice' to 18 or omit column 'UnitPrice'.
Msg 35326, Level 16, State 1, Line 139
ALTER INDEX statement failed because a columnstore index cannot be reorganized. Reorganization of a columnstore index is not necessary.
Msg 2714, Level 16, State 3, Procedure V_SalesOrder, Line 1 [Batch Start Line 145]
There is already an object named 'V_SalesOrder' in the database.
Msg 35305, Level 16, State 1, Line 152
CREATE INDEX statement failed because a columnstore index cannot be created on a view. Consider creating a columnstore index on the base table or creating an index without the COLUMNSTORE keyword on the view.
Msg 35330, Level 15, State 1, Line 157
UPDATE statement failed because data cannot be updated in a table with a columnstore index. Consider disabling the columnstore index before issuing the UPDATE statement, then rebuilding the columnstore index after UPDATE is complete.
这里特别把列存储索引不存在统计信息截图如下:
如何解决列存储索引表只读的问题
从限制条件章节,我们知道SQL Server 2012的列存储索引表不允许进行DML操作,因为建立了列存储索引的表会自动变成只读表,那么我们如何解决这个问题呢?
升级到SQL Server 2014或更高版本
将SQL Server 2012数据库整个大版本升级到SQL Server 2014或者2016。因为从SQL Server 2014开始,列存储索引表已经支持更新操作。当然升级动作非常复杂,只是为了解决列存储表只读问题而升级版本,有点本末倒置,因此这个方法不是本文的讨论范畴。
禁用列存储索引
在SQL Server 2012中解决列存储索引表只读问题的方法是,在执行DML语句之前,先禁用列存储索引,完成DML以后,再重建列存储索引。这个过程相当于先删除列存储索引,DML操作后重新创建列存储索引。
-- DEMO: columnstore index table read_only fixing
USE ColumnStoreDB
GO
ALTER INDEX NCSIX_ALL_Columns
ON dbo.SalesOrder DISABLE;
GO
UPDATE TOP (1) A
SET OrderQty = OrderQty + 1
FROM dbo.SalesOrder AS A
GO
ALTER INDEX NCSIX_ALL_Columns
ON dbo.SalesOrder REBUILD;
GO
-- END DEMO
分区交换
分区交换方法的实现步骤如下:
-
新建一个中间步骤表,表结构保持和列存储表结构一致,包括字段,数据类型,索引等
-
初始化一部分数据,注意OrderID不能与列存储表OrderID有交集
-
做中间步骤表的SWITCH动作到列存储表的一个空的分区上
-- DEMO: columnstore index table read_only fixing using partion switch
IF OBJECT_ID('dbo.SalesOrder_staging', 'U') IS NOT NULL
BEGIN
DROP TABLE dbo.SalesOrder_staging
END
GO
CREATE TABLE dbo.SalesOrder_staging
(
OrderID INT NOT NULL
,AutoID INT NOT NULL
,UserID INT NOT NULL
,OrderQty INT NOT NULL
,Price DECIMAL(8,2) NOT NULL
,UnitPrice AS Price * OrderQty
,OrderDate DATETIME NOT NULL,
CONSTRAINT check_OrderDate CHECK ([OrderDate] > '2018-01-01 00:00' and [OrderDate]<='2019-01-01 00:00')
) ON [PRIMARY];
-- data init for 5 M records.
DECLARE
@OrderID INT
;
SELECT @OrderID = max(OrderID)
FROM dbo.SalesOrder;
;WITH a
AS (
SELECT *
FROM (VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9),(10)) AS a(a)
), RoundData
AS(
SELECT TOP(500000)
OrderID = @OrderID + ROW_NUMBER() OVER (ORDER BY a.a)
,AutoIDRound = abs(checksum(newid()))
,Price = a.a * b.a * 10000
,OrderQty = a.a + b.a + c.a + d.a + e.a + f.a + g.a + h.a
FROM a, a AS b, a AS c, a AS d, a AS e, a AS f, a AS g, a AS h
)
INSERT INTO dbo.SalesOrder_staging(OrderID, AutoID, UserID, OrderQty, Price, OrderDate)
SELECT
OrderID
,AutoID = cast(ROUND((13 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 101), 0) as int)
,UserID = cast(ROUND((500 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 10000), 0) as int)
,OrderQty
,Price = cast(Price AS DECIMAL(8,2))
,OrderDate = dateadd(day, cast(ROUND((330 * (AutoIDRound*1./cast(replace(AutoIDRound, AutoIDRound, '1' + replicate('0', len(AutoIDRound))) as bigint)) + 1), 0) as int) ,'2018-01-01')
FROM RoundData;
GO
-- create regular B-Tree Clustered Index
CREATE UNIQUE CLUSTERED INDEX CIX_OrderID
ON dbo.SalesOrder_staging(OrderID, OrderDate)
WITH (ONLINE = ON)
ON [PRIMARY];
GO
--create nonclustered columnstore index
CREATE NONCLUSTERED COLUMNSTORE INDEX NCSIX_ALL_Columns
ON dbo.SalesOrder_staging(OrderID, AutoID, UserID, OrderQty, Price, OrderDate)
GO
ALTER PARTITION scheme ps_SalesYear NEXT used [PRIMARY];
--alter partition function pf_SalesYear() split range ('2019-01-01 00:00');
--go
ALTER TABLE dbo.SalesOrder_staging switch TO dbo.SalesOrder
PARTITION $PARTITION.pf_SalesYear('2018-01-01 01:00');
GO
注意:
-
SalesOrder_staging表的OrderID初始值比表SalesOrder表中的OrderID最大值要大
-
SalesOrder_staging表的Check约束必须要满足Partition函数的限制,比如LEFT操作是左开右闭
-
SalesOrder_staging表的索引结构必须和SalesOrder表索引结构保持一致,否则Switch会报错
-
如果SalesOrder表初始分区数不够用,请使用ALTER PARTITION FUNCTION SPLIT方式分割出新的分区
-
由于Partition函数是LEFT,左开右闭,所以最后的Switch传入日期不能是小于等于’2018-01-01 00:00’(我在这里踩了坑,花了很长时间才走出来),必须比这个时间点稍微大些,否则系统会认为数据属于前一个分区而导致Switch失败。
最后总结
这篇文章从列存储索引的几个基本概念引入,谈到了列存储索引的结构以及列存储索引对查询性能的提升,然后谈到了需要踩过的几个坑,再接着聊到了列存储索引在SQL Server 2012中的限制,最后讲我们如何破解列存储表只读的问题。由于篇幅原因,关于SQL Server 2014和2016中的列存储索引没有过多涉及。预知后事如何,且听下月分解。