HybridDB · 稳定性 · HybridDB如何优雅的处理Out Of Memery问题
Author: 明虚
前言
你是否遇到过数据库服务器的Out Of Memory(OOM)现象?就是数据库的进程把操作系统内存耗尽,触发操作系统对数据库进程执行Kill -9操作。操作系统对某个数据库进程的Kill,会导致整个数据库实例所有实例重启,所有连接会断开,造成一定时间的数据库不可用。OOM对数据库服务影响较大,应该尽量避免。
在我们的HybridDB for PG 云服务中,也可能遇到用户实例耗尽所有可用内存的情况。一般情况下,我们会采用CGROUP机制来限制用户的内存使用,同一实例在同一主机上的所有进程会放入一个CGROUP。当数据库实例使用的内存总量超出限制时,会触发操作系统从CGROUP中找出耗内存较多的进程,执行Kill -9,这会导致我们上面说的数据库服务暂时不可用。这里操作系统的Kill操作我们称为OOM Kill。
发生OOM的因素一般是应用的并发连接数过多、大对象的存取操作、查询用到过多的临时内存,实例内存过小等。从云服务提供者的角度看,我们无法提前预知或限制用户的使用行为。通常是发生OOM Kill后,监控程序检测到操作系统错误日志,我们才会进行处理,而此时往往已经对用户业务造成了影响。就是说,我们无法避免OOM的发生。但能不能更好的处理OOM,避免OOM Kill这种严重后果呢?本文将对此进行讨论。
Greenplum的处理方式
HybridDB for PG 是基于Greenplum开发的。为尽量避免OOM Kill,Greenplum提供了Resource Manager内存限制功能。通过设置Resource Manager参数,可以限制整个实例可以申请的内存。其背后的机制是,在每次数据库内核执行Malloc系统调用,申请操作系统内存时,用一个全局变量累加记录申请的内存量,并它记录的实例内存申请总量是否已经超限,如果超限则报错。
Greenplum这种方法看似可行,但在我们的云服务中却不宜采用。这是因为,操作系统并不是在Malloc被调用的时候,把实际的物理内存返回给调用者,而是等到调用者实际使用(例如做内存拷贝操作)时,才分配物理内存给它。也就是说。记录的Malloc内存总量,是虚拟内存使用量(可以从top命令输出中VIRT字段,查看一个进程的虚拟内存),并不能反映数据库实际使用的内存(实际使用内存量可以从top命令输出中的RSS字段得到)。如果按这种方法做限制,用户实际可用内存会比他购买的规格内存内存少的多。在我们的一个测试中发现,Malloc记录的内存有时是实例实际使用内存的两倍以上!
既然使用Resource Manager记录和限制内存使用的方法不可行,有没有更优雅的方式尽量避免OOM Kill呢?使用HybridDB的用户,如果线下使用过Greenplum,可能会发现,在大量使用内存时,线下会触发OOM Kill的场景在HybridDB可能并未触发(虽然还是会有SQL报错,但并没有触发实例重启)。另一方面,用户可以实际使用到HybridDB规格标称的内存。实际上HybridDB使用了独特的的方式处理OOM,较大程度上避免了OOM Kill被触发。下面我们介绍一下HybridDB的方法。
HybridDB如何处理OOM
下图是个HybridDB实例的例子。主节点、两个子节点分布位于不同的Linux主机上。每个节点都使用CGROUP限制了内存,例如,每个节点限制使用8G内存。
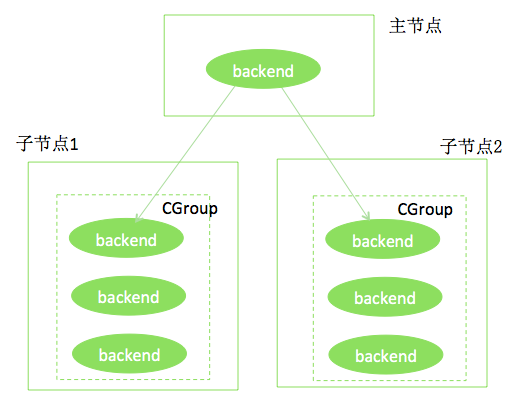
我们假设上述实例的某个节点使用了超过8G的内存,如果按原有机制,此节点所在主机的操作系统,会找出此实例对应CGROUP中使用内存较多的进程,执行Kill -9,此节点的所有进程重启,暂时不可用。更严重的是,这可能使整个HybridDB集群不可用!为避免这种情况,HybridDB使用了如下方法:
a. 创建一个独立的CGROUP,限制例如10G的内存,如下图所示。
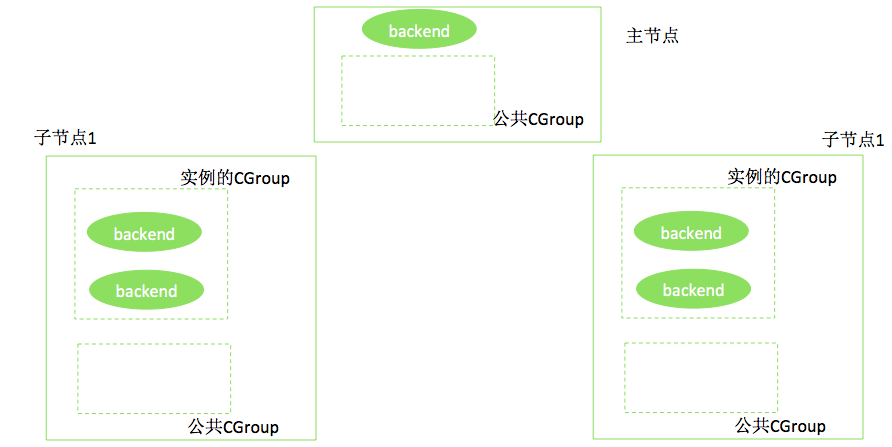
b. 将实例的CGROUP内存限制提升20%,即如果用户实例的节点规格是8G的内存,则在CGROUP中,提升为9.6G。这样做的目的是为下面的操作留存空间。
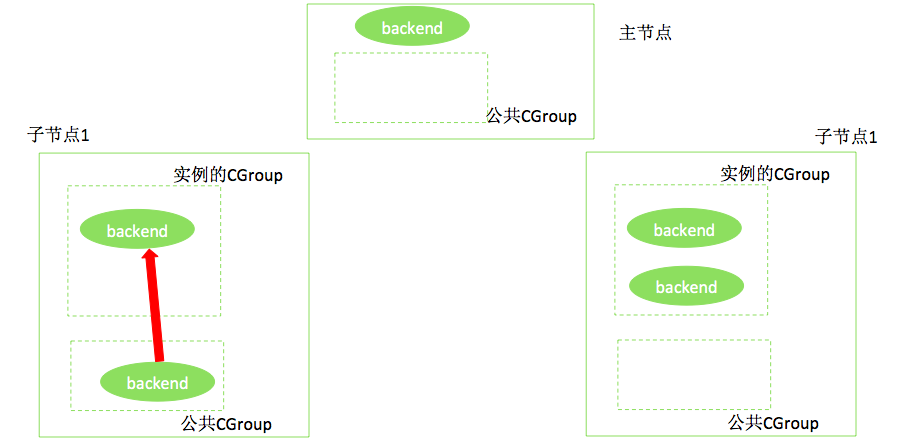
c. 启动一个脚本,实时监控(例如每秒钟扫描一次)主机所有CGROUP的内存水位。操作系统提供了机制,在CGOUP状态信息中可以查到内存的水位信息。当发现某个CGROUP的水位过高(例如超过了100%的规格可用内存,如8G)时,将内存使用最高的进程移入公用CGROUP。如果内存水位未降低到指定水位,如规格内存的80%,则继续在此CGROUP中取出内存占用高的进程,放入公用CGROUP。如下图所示。
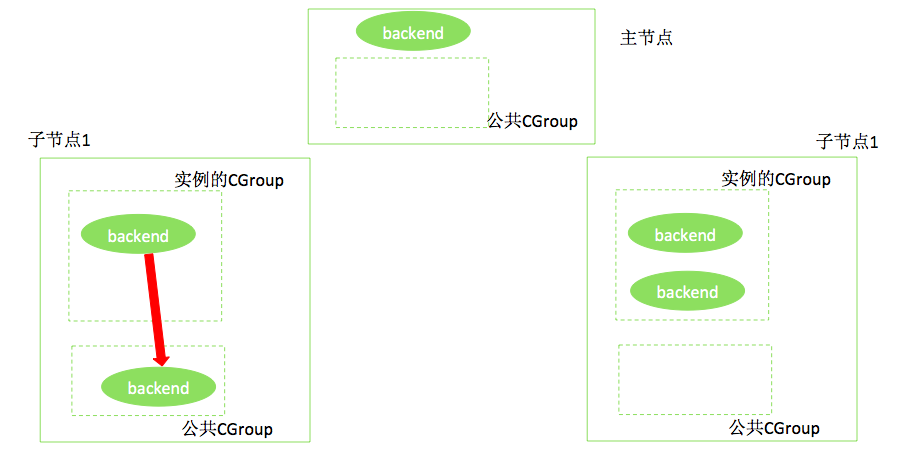
d. 启动另一个独立的脚本,不断获取公用CGROUP中的进程,对这些进程发送特殊的信号;HybridDB进程收到这些信号,将执行类似Cancel Query一样的操作,撤销当前正在进行的查询,同时返回给用户如下的提示:
ERROR: out of memory, no enough instance memory available to run this query.
这个步骤如下图所示。
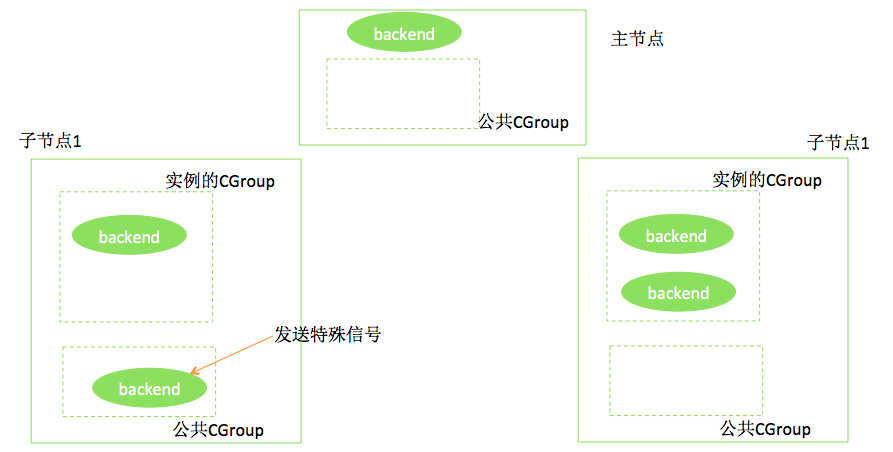
e. b中提到的内存监控脚本在内存降低到指定水位(如规格内存的80%)后,则进入到另一状态,即开始将进程从公用CGROUP移动回原CGROUP,直到水位上升到预设水位(如100%规格内存)。如下图所示。
上述方法的优势有:
1)由于在实例内存不断增长的过程中,实时的监控内存使用,在内存超限时,触发查询的撤销操作,保护了实例,避免的实例的整体不可用。
2)用户可以通过出错信息获知内存不足导致查询失败,进而做进一步处理。如果触发了OOM Kill,用户只能看到连接断开、实例重启,但无法获知发生现象的原因,所以通常会误以为是网络连接问题。
3)由于一台机器的所有实例都共享一个公用CGROUP,而这个CGROUP一般10G左右就满足使用了,所以它并不会增加多少成本。另外虽然为用户提升了20%的内存,但由于超出规格内存时就开始做查询撤销操作了,所以实际上实例并不会长时间多用内存。
4)这种方法实现简单。仅需要编写两个监控脚本,并在HybridDB内核中增加对特殊信号的支持。
需要注意的是,如果公用CGROUP的内存也耗尽了,是会触发OOM Kill的。也就是说这种方法并不会完全避免OOM Kill,但从实践看,大大降低了OOM Kill的发生几率。
总结
HybridDB对OOM的处理方式,虽然没能避免OOM,但大大减少了OOM Kill的发生,避免了整个HybridDB集群不可用的危险后果。可以说这是一种更优雅的OOM处理方式。当然,作为HybridDB的用户,仍然要从应用层做工作,提前降低OOM发生的几率,例如,降低并发度、调优大量使用临时内存的查询、升级实例规格等。