AliSQL · 特性介绍 · 动态加字段
Author: lengxiang
背景
加字段作为业务需求变更中最常见的需求,InnoDB引擎表的加字段功能一直以来被运维人员所诟病, 虽然支持了online方式,但随着表空间越来越大,copy整张表的代价也越来越大。 AliSQL版本在InnoDB的compact记录格式的基础上,设计了新的记录格式comfort,支持动态加字段。
使用方法
使用的实例如下:
CREATE TABLE test(
id int primary key,
name varchar(100),
key(name)
)ENGINE=InnoDB ROW_FORMAT=comfort;
ALTER TABLE test ADD col1 INT;
这里没有增加新的语法,只是增加了新的InnoDB的记录格式,alter语句保持一致。 可以通过SHOW CREATE TABLE或者查询information_schema.tables查看ROW_FORMAT。
mysql> show create table test\G;
*************************** 1. row ***************************
Table: test
Create Table: CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`col1` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMFORT
1 row in set (0.00 sec)
实现方法
AliSQL设计了一种新的记录格式,命名为comfort,其格式从compact演化而来:
Compact行记录的格式:

- 变长字段长度列表:如果列的长度小于255字节,用1字节表示;如果大于255个字节,用2字节表示。
- NULL标志位:表明该行数据是否有NULL值。占一个字节。
- 记录头信息:固定占用5字节,每位的含义见下表:
| 名称 | 大小(bit) | 描述 |
|---|---|---|
| () | 1 | 未知 |
| () | 1 | 未知 |
| delete_flag | 1 | 该行是否已被删除 |
| min_rec_flag | 1 | 为1,如果该记录是预先被定义为最小的记录 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该记录的排序记录 |
| record_type | 3 | 记录类型,000表示普通,001表示B+树节点指针,010表示infimum,011表示supermum,1xx表示保留 |
| next_record | 16 | 页中下一条记录的相对位置 |
新的Comfort记录格式如下:
[Lens | N_nulls | N_fields | Extra_bytes | columns...]
其中:
- Extra_bytes中info_bits占用一个bit来标识comfort记录,即记录头中未使用的2个bit中的其中一个。
- 新增N_fields占用1或者2个Bytes来标识当前记录的column数量: 当记录数小于128个时,占用1个Bytes 当大于等于128时,使用2个Bytes。
实现逻辑
假设变更的case如下:
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 ROW_FORMAT=COMFORT;
alter table test add col1 int;
1. alter变更
1. 变更数据字典SYS_TABLES中的n_cols字段,即更新column数量
InnoDB的变更语句如下:
trx->op_info = "Updating column in SYS_TABLES";
/* N_COLS include compact format bit.*/
error = que_eval_sql(
info,
"PROCEDURE UPDATE_SYS_TABLES_PROC () IS\n"
"BEGIN\n"
"UPDATE SYS_TABLES SET N_COLS=N_COLS+1\n"
"WHERE ID=:table_id;\n"
"END;\n",
FALSE, trx);
2.变更数据字典SYS_COLUMNS,新增一条记录,即新增的column
InnoDB的变更语句如下:
trx->op_info = "inserting column in SYS_COLUMNS";
error = que_eval_sql(
info,
"PROCEDURE INSERT_SYS_COLUMNS_PROC () IS\n"
"BEGIN\n"
"INSERT INTO SYS_COLUMNS VALUES\n"
"(:table_id, :pos, :name, :mtype, :prtype, :len, :prec);\n"
"END;\n",
FALSE, trx);
3. 变更dictionary cache中的dict_table_t对象 新的column需要追加到dict_table_t定义的column数组中,
变更前: table->columns: (id, name, row_id, trx_id, undo_ptr)
变更后: table->columns: (id, name, col1, row_id, trx_id, undo_ptr)
其代码如下:
/* The new column will be added into after user_def cols,
before SYS_COLS(ROW_ID, TRX_ID, ROLL_PTR) in dict_table_t */
for (ulint i= 0; i < n_cols; i++) {
col = (dict_col_t*)save_cols + i;
if (i == n_cols - DATA_N_SYS_COLS) {
dict_mem_table_add_col(user_table, user_table->heap,
field->field_name,
mtype, prtype, len);
}
dict_mem_table_add_col(user_table, user_table->heap,
col_name,
col->mtype, col->prtype, col->len);
new_col = dict_table_get_nth_col(user_table, user_table->n_def - 1);
dict_col_copy_ord_prefix(new_col, col);
}
4. 变更Dictionary Cache中的dict_index_t对象(Cluster index)
变更前: Primary key的field数组如下: (id, trx_id, undo_ptr, name)
变更后: Primary key的field数组如下: (id, trx_id, undo_ptr, name, col1)
其代码如下:
/*The new column will added into after last field in dict_index_t */
for (ulint i = 0; i < n_fields; i++) {
dfield = (dict_field_t*)(save_fields) + i;
if (dfield->col->ind < n_cols - DATA_N_SYS_COLS) {
col = dict_table_get_nth_col(user_table, dfield->col->ind);
} else {
col = dict_table_get_nth_col(user_table, dfield->col->ind + 1);
}
dict_index_add_col(clust_index, user_table, col, dfield->prefix_len);
}
col = dict_table_get_nth_col(user_table, n_cols - DATA_N_SYS_COLS);
5. 变更Dictionary Cache中的dict_index_t对象(Secondary index)
变更前: secondary index的field数组:(name, id)
变更后: secondary index的field数组:(name, id)
在变更前后,二级索引所对应的fields没有发生变化,fields所对应的column的位置也没有变更,只是因为dict_table_t对象的columns对象重建了,所以需要变更一下field做引用的culumn,这里需要reload一下即可。
对比Online和Dynamic方式
InnoDB原生的Online方式的步骤大致是:
- 持有exclusive MDL lock,
- 根据变更后的表结构新建临时表,
- 新建log表,记录原表的变更
- MDL降级为shared 锁,原表允许DML,
- copy数据到新的临时表,并持续copy log表中的记录
- MDL升级为exclusive
- apply完log表中所有的记录,并rename表
- 删除老表,完成变更
InnoDB新的Dynamic方式的步骤大致是:
- 持有exclusive MDL lock,
- 降级为shared的锁,允许DML
- 升级为exclusive锁
- 变更数据字典(SYS_TABLES, SYS_COLUMNS)
- 变更数据字典缓存(dict_table_t, dict_index_t)
- 释放MDL锁
测试情况:
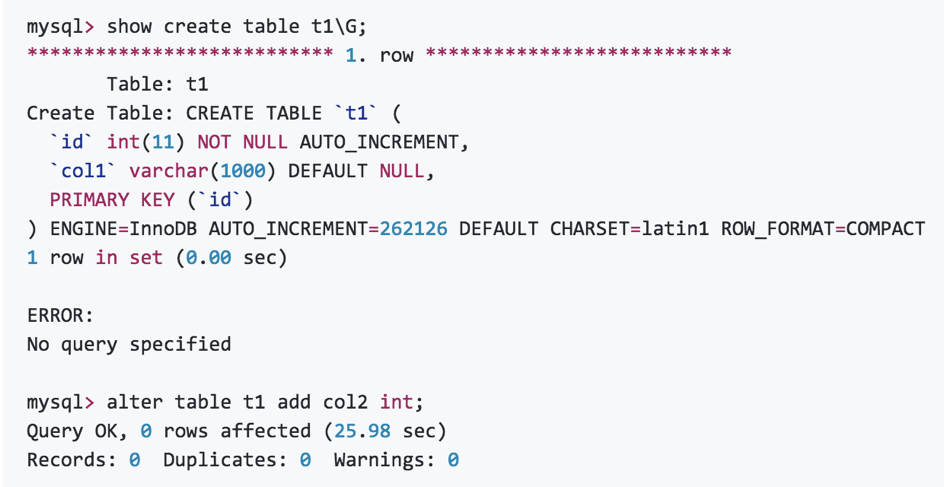
Compact格式的表加字段,共计20W多条记录的情况下,耗时25.98s。
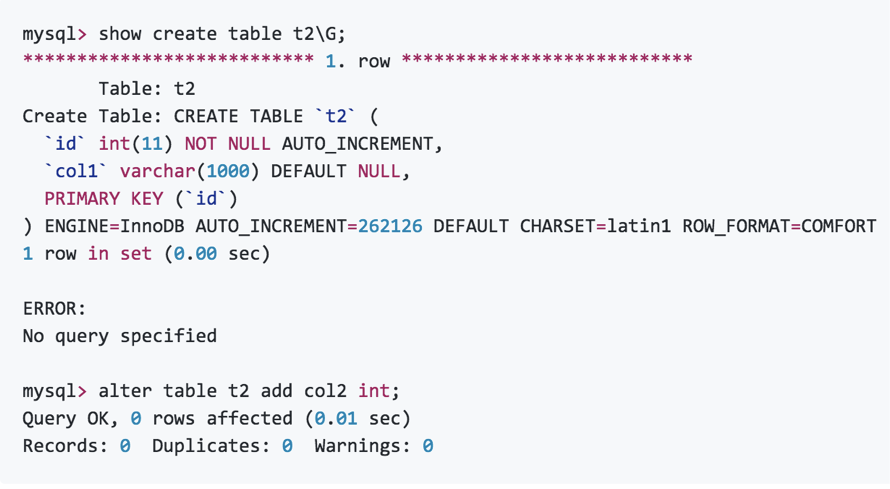
Comfort格式的表加字段,共计20W多条记录的情况下,耗时0.01s。
总结
动态加字段能够在不copy记录的情况下,秒级完成结构的变更,大大方便了运维DBA人员的日常变更,这个功能patch已经开源在AliSQL版本。 如果有兴趣,可以关注AliSQL的开源项目:https://github.com/alibaba/AliSQL