HybridDB · 最佳实践 · HybridDB 数据合并的方法与原理
Author: mingxu
引言
刚开始使用HybridDB的用户,有个问的比较多的问题:如何快速做数据“合并”(Merge)?所谓“合并”,就是把数据新版本更新到HybridDB中。如果数据已经存在,则将它们替换为新版本;如果不存在,将它们插入数据库中。一般是离线的做这种数据合并,例如每天一次批量把数据更新到HybridDB中。也有客户需要实时的更新,即做到分钟级甚至秒级延迟。这里我们介绍一下HybridDB中数据合并的方法和背后原理。
简单更新过程
无论怎么做数据合并,都是对数据的修改,即Update、Delete、Insert、Copy等操作。我们先要了解一下HybridDB中的数据更新过程。我们以用户发起一次Update操作为例(对列存表单行记录的更新),整个流程如下图所示。
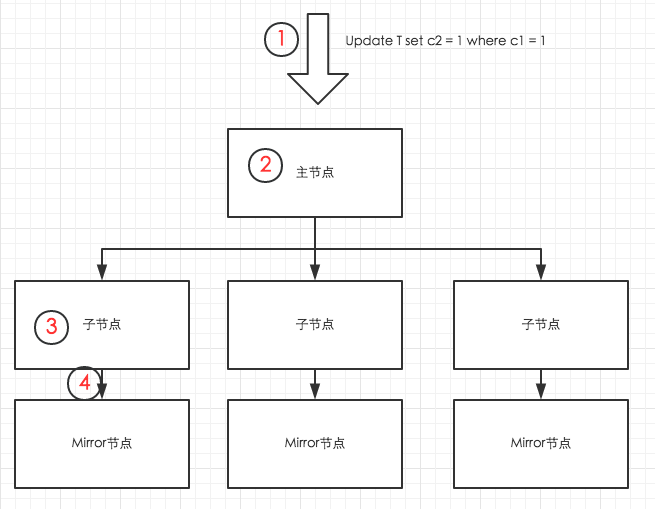
其中的步骤说明如下:
-
用户把Update的SQL请求发送到主节点;
-
主节点发起分布式事务,并对被Update的表加锁(HybridDB不允许并行的Update同一张表),然后把更新请求分发到对应的子节点。
-
子节点通过索引扫描,定位到要更新的数据,并更新数据。对于列存表,更新逻辑其实就是删除旧的数据行,并在表的尾端写入新的数据行。(列存表)被更新的数据页面会写入内存缓存区,对应的表文件长度的变化(因为尾端写入了数据,所以数据表对应的文件长度增大了)会写入日志(xlog文件)。
-
在Update命令结束前,内存中的被更新的数据页面和xlog日志,都要同步到Mirror节点。同步完成后,主节点结束分布式事务,返回用户执行成功的消息。
可以看出,整个过程的链条很长,SQL语句解析、分布式事务、锁,主节点子节点之间的连接建立、子节点与Mirror数据和日志同步等操作,都会耗费CPU或IO资源,同时拖慢整个请求的响应时间。因此,对于HybridDB来说,应该尽量避免单行数据的更新,而是尽量批量的更新数据,也就是尽量做到:
-
尽量把更新放到一个SQL语句,减少语句解析、节点通信、数据同步等开销;
-
尽量把更新放到一个事务,避免不必要的事务开销。
简而言之,就是数据的合并和更新,尽量以”成批“的形式进行。下面我们看看,如何批量的做数据更新。
批量Update
假如我们要Update很多独立数据行,怎么才能用一个SQL来实现呢?
我们假设有张表target_table需要做更新(称为目标表),这张表的定义如下。一般目标表都非常大,这里我们往target_table里面插入1千万数据。为了能快速更新,target_table上要有索引。这里我们定义了primary key,会隐含的创建一个唯一值索引(unique index)。
create table target_table(c1 int, c2 int, primary key (c1));
insert into target_table select generate_series(1, 10000000);
为了做批量的Update,需要用到中间表(Stage Table),其实就是为了更新数据临时创建的表。为了更新target_table的数据,可以先把新数据插入到中间表source_table中。然后,把新数据通过COPY命令、OSS外部表等方式导入到source_table。这里为简单起见,我们直接插入一些数据。
create table source_table(c1 int, c2 int);
insert into source_table select generate_series(1, 100), generate_series(1,100);
source_table数据准备好后,执行下面的update set … from … where ..语句,即可实现批量的Update。注意,为了最大限度的使用到索引,在执行Update前,要使用set opitimzer=on启用ORCA优化器(如果不启用ORCA优化器,则需要执行set enable_nestloop = on才能使用到索引)。
set optimizer=on;
update target_table set c2 = source_table.c2 from source_table where target_table.c1= source_table.c1;
这种Update的执行计划如下:
=> explain update target_table set c2 = source_table.c2 from source_table where target_table.c1= source_table.c1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Update (cost=0.00..586.10 rows=25 width=1)
-> Result (cost=0.00..581.02 rows=50 width=26)
-> Redistribute Motion 4:4 (slice1; segments: 4) (cost=0.00..581.02 rows=50 width=22)
Hash Key: public.target_table.c1
-> Assert (cost=0.00..581.01 rows=50 width=22)
Assert Cond: NOT public.target_table.c1 IS NULL
-> Split (cost=0.00..581.01 rows=50 width=22)
-> Nested Loop (cost=0.00..581.01 rows=25 width=18)
Join Filter: true
-> Table Scan on source_table (cost=0.00..431.00 rows=25 width=8)
-> Index Scan using target_table_pkey on target_table (cost=0.00..150.01 rows=1 width=14)
Index Cond: public.target_table.c1 = source_table.c1
可以看到,HybridDB“聪明”的选择了索引。但是,如果往source_table里面加入更多数据,优化器会认为使用Nest Loop关联方法+索引扫描,不如不使用索引高效,而是会选取Hash关联方法+表扫描方式执行。例如:
postgres=> insert into source_table select generate_series(1, 1000), generate_series(1,1000);
INSERT 0 1000
postgres=> analyze source_table;
ANALYZE
postgres=> explain update target_table set c2 = source_table.c2 from source_table where target_table.c1= source_table.c1;
QUERY PLAN
------------------------------------------------------------------------------------------------------
Update (cost=0.00..1485.82 rows=275 width=1)
-> Result (cost=0.00..1429.96 rows=550 width=26)
-> Assert (cost=0.00..1429.94 rows=550 width=22)
Assert Cond: NOT public.target_table.c1 IS NULL
-> Split (cost=0.00..1429.93 rows=550 width=22)
-> Hash Join (cost=0.00..1429.92 rows=275 width=18)
Hash Cond: public.target_table.c1 = source_table.c1
-> Table Scan on target_table (cost=0.00..477.76 rows=2500659 width=14)
-> Hash (cost=431.01..431.01 rows=275 width=8)
-> Table Scan on source_table (cost=0.00..431.01 rows=275 width=8)
上述批量的Update方式,减少了SQL编译、节点间通信、事务等开销,可以大大提升数据更新性能并减少对资源的消耗。
批量Delete
对于Delete操作,采用和上述批量Update类似的中间表,然后使用下面的带有“Using”子句的Delete来实现批量删除:
delete from target_table using source_table where target_table.c1 = source_table.c1;
可以看到,这种批量的Delete同样使用了索引。
explain delete from target_table using source_table where target_table.c1 = source_table.c1;
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Delete (slice0; segments: 4) (rows=50 width=10)
-> Nested Loop (cost=0.00..41124.40 rows=50 width=10)
-> Seq Scan on source_table (cost=0.00..6.00 rows=50 width=4)
-> Index Scan using target_table_pkey on target_table (cost=0.00..205.58 rows=1 width=14)
Index Cond: target_table.c1 = source_table.c1
利用Delete + Insert做数据合并
回到本文刚开始的问题,如何实现批量的数据合并?做数据合并时,我们先把待合入的数据放入中间表中。如果我们预先知道待合入的数据,在目标表中都已经有对应的数据行,即我们通过Update语句即可实现数据合入。但多数情况下,待合入的数据中,一部分是在目标表中已存在记录的数据,还有一部分是新增的,目标表中没有对应记录。这时候,使用一次批量的Delete + 一次批量的Insert即可:
set optimizer=on;
delete from target_table using source_table where target_table.c1 = source_table.c1;
insert into target_table select * from source_table;
利用Values()表达式做实时更新
使用中间表,需要维护中间表生命周期。有的用户想实时的批量更新数据到HybridDB,即持续性的同步数据或合并数据到HybridDB。如果采用上面的方法,需要反复的创建、删除(或Truncate)中间表。其实,可以利用Values表达式,达到类似中间表的效果,但不用维护表。方法是先将待更新的数据拼成一个Values表达式,然后按如下方式执行Update或Delete:
update target_table set c2 = t.c2 from (values(1,1),(2,2),(3,3),…(2000,2000)) as t(c1,c2) where target_table.c1=t.c1
delete from target_table using (values(1,1),(2,2),(3,3),…(2000,2000)) as t(c1,c2) where target_table.c1 = t.c1
注意,使用set optimizer=on;或set enable_nestloop=on;都可以生成使用索引的查询计划。比较复杂的情形,比如索引字段有多个、涉及分区表等,必须要使用ORCA优化器才能匹配上索引。
总结
上面我们简单介绍了HybridDB的批量数据合并和更新的最佳实践。利用这些方法,无论是在每天一次或多次的ETL操作,还是实时更新数据的场景,都可以把HybridDB的数据更新效率充分发挥出来。