MySQL · 源码分析 · InnoDB Repeatable Read隔离级别之大不同
Author: 令猴
开始介绍之前,先让我们了解一些基本概念。ANSI SQL STANDARD定义了4类隔离级别(READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE),包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级别一般支持更高的并发处理,并拥有更低的系统开销。
- Read Uncommitted(读未提交) 在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
- Read Committed(读已提交) 一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
- Repeatable Read(可重读) 这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
- Serializable(可串行化) 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。 这四种隔离级别采取不同的锁类型来实现。并发控制中读取同一个表的数据,可能出现如下问题:
脏读(Drity Read):事务T1修改了一行数据,事务T2在事务T1提交之前读到了该行数据。
不可重复读(Non-repeatable read): 事务T1读取了一行数据。 事务T2接着修改或者删除了改行数据,当T1再次读取同一行数据的时候,读到的数据时修改之后的或者发现已经被删除。
幻读(Phantom Read): 事务T1读取了满足某条件的一个数据集,事务T2插入了一行或者多行数据满足了T1的选择条件,导致事务T1再次使用同样的选择条件读取的时候,得到了比第一次读取更多的数据集。
MySQL/INNODB支持ANSI SQL STANDARD规定的四种隔离级别(READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE).本篇文章重点关注一下MySQL REPEATABLE READ隔离级别与其他数据实现方式上的不同之处。
下面看一下MySQL在REPEATABLE READ 隔离级别下的工作方式:
开启两个session。

接下来看一下另外一个开源数据库PostgreSQL在REPEATABLE READ 隔离级别下的工作方式:

同样测试了SQL SERVER,得到的结果与PostgreSQL是一致的。
从上面的执行情况我们可以看到MySQL与PostgreSQL两者工作方式上有所不同。MySQL在执行UPDATE语句的时候对于session2的INSERT语句是可以看到的,也就是说发生了幻读。那么MySQL在隔离级别为REPEATABLE READ的情况下,表现出来的幻读现象是否属于一个BUG呢?曾经有人在2013年给官方提过一个关于该现象的BUG,请参考https://bugs.mysql.com/bug.php?id=63870。 从BUG页面的注释可以了解到,该现象是与MySQL对REPATABLE READ隔离级别的实现方式有关。而这种幻读现象对于REPATABLE READ隔离级别也是正确的方式。请看wikipedia上对于REPEATABLE READ的描述:
Repeatable reads
In this isolation level, a lock-based concurrency control DBMS implementation keeps read and
write locks (acquired on selected data) until the end of the transaction. However, range-locks are not managed, so phantom reads can occur.
另外我们接着看一下ANSI SQL STANDARD对于各种隔离级别发生幻读的规定:
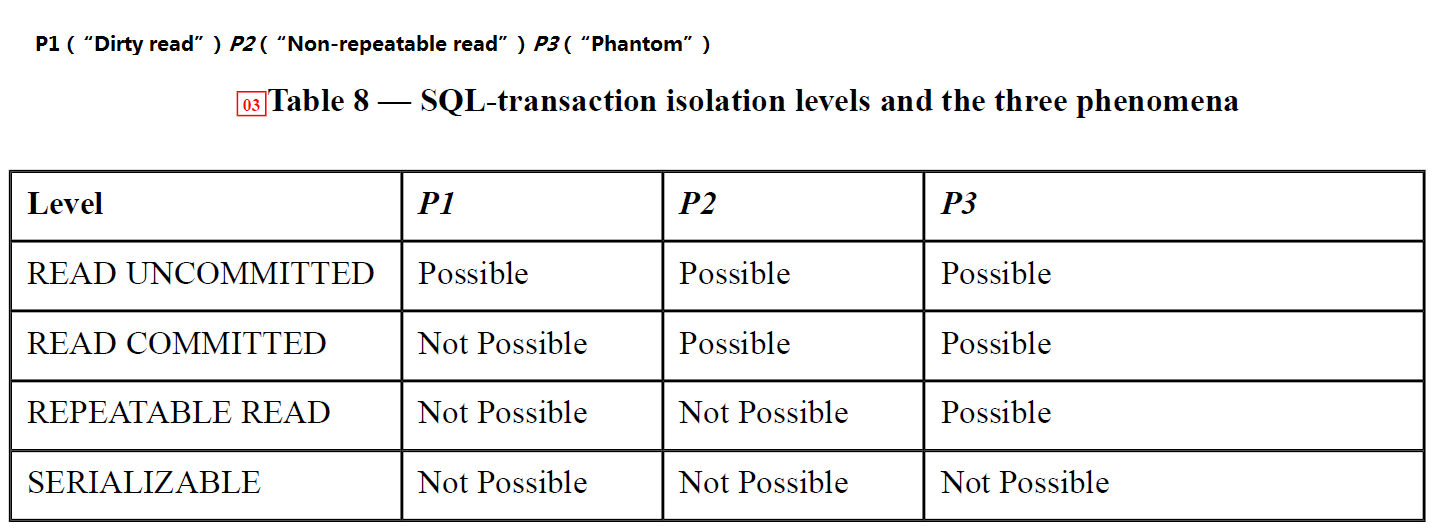
我们从wikipedia以及ANSI SQL STANDARD可以看到对于REPEATABLE READ隔离级别下是允许出现幻读现象的。
接下来我们从源码的角度分析一下Innodb对于REPEATABLE READ隔离级别的执行过程(代码只覆盖重要执行部分)。 以上面的例子为依据进行剖析: 对于第一条SELECT语句,InnoDB将调用row_search_for_mysql函数来返回扫描行。函数row_search_for_mysql调用相关代码如下:
UNIV_INTERN
dberr_t
row_search_for_mysql(
/*=================*/
byte* buf, /* 用来存放记录的空间地址 */
ulint mode, /* InnoDB页扫描顺序 */
row_prebuilt_t* prebuilt, /* InnoDB扫描需要的所有信息都包含在这个结构体,比如表以及Index等信息 */
ulint match_mode, /* 对于Index的匹配模式,是精确匹配还是前缀索引匹配 */
ulint direction) /* 指定扫描顺序,正序还是倒叙扫描 */
{
...
/* 从这里我们看出开始一个新事务,并非是从执行BEGIN语句位置开始,而是从其后开始执行的第一条语句开始分配事务ID */
trx_start_if_not_started(trx, ((trx->mysql_thd
&& thd_is_select(trx->mysql_thd)
) || srv_read_only_mode) ? FALSE : TRUE);
...
// 如果是SQL语句第一次开始执行,需要考虑对TABLE增加意向所
if (!prebuilt->sql_stat_start) {
// 这里标记SQL语句已经开始执行,处理一条SQL语句循环扫描记录的过程
/* No need to set an intention lock or assign a read view */
if (UNIV_UNLIKELY
(trx->read_view == NULL
&& prebuilt->select_lock_type == LOCK_NONE)) {
fputs("InnoDB: Error: MySQL is trying to" " perform a consistent read\n" "InnoDB: but the read view is not assigned!\n", stderr);
trx_print(stderr, trx, 600);
fputc('\n', stderr);
ut_error;
}
} else if (prebuilt->select_lock_type == LOCK_NONE) {
/* This is a consistent read */
/* Assign a read view for the query */
// 如果是第一次执行SELECT语句,构建READ_VIEW. 该READ_VIEW 用来判断记录的可见性
trx_assign_read_view(trx);
prebuilt->sql_stat_start = FALSE;
} else {
...
}
...
/* We are ready to look at a possible new index entry in the result
set: the cursor is now placed on a user record */
/* 从这里我们看一下InnoDB如何获取一条新纪录。由于上面例子中SESSION1的第一条语句是SELECT语句,InnoDB在REPEATABLE READ 隔离级别下,不对SELECT 语句加锁,所以这里执行SELECT语句的时候prebuilt->select_lock_type为LOCK_NONE。下面我们直接看一下prebuilt->select_lock_type为LOCK_NONE的情况下,InnoDB如何扫描行? */
if (prebuilt->select_lock_type != LOCK_NONE) {
... //稍后会对prebuilt->select_lock_type != LOCK_NONE的情况进行分析
}
else
{
/* This is a non-locking consistent read: if necessary, fetch
a previous version of the record */
if (trx->isolation_level == TRX_ISO_READ_UNCOMMITTED) {
/* 对于READ UNCOMMITTED隔离级别,我们什么都不需要,只要让他读取最新的记录版本即可 */
} else if (index == clust_index) {
/* Fetch a previous version of the row if the current
one is not visible in the snapshot; if we have a very
high force recovery level set, we try to avoid crashes
by skipping this lookup */
// 如果是全表扫描或主键扫描,这里需要看看当前记录是否对当前事务可见
if (UNIV_LIKELY(srv_force_recovery < 5)
&& !lock_clust_rec_cons_read_sees(
rec, index, offsets, trx->read_view)) {
// 如果不可见,这里需要查找历史版本
rec_t* old_vers;
/* The following call returns 'offsets'
associated with 'old_vers' */
err = row_sel_build_prev_vers_for_mysql(
trx->read_view, clust_index,
prebuilt, rec, &offsets, &heap,
&old_vers, &mtr);
if (err != DB_SUCCESS) {
goto lock_wait_or_error;
}
if (old_vers == NULL) {
/* The row did not exist yet in
the read view */
// 如果当前记录对当前事务不可见,也没有历史版本,直接查找下一条记录
goto next_rec;
}
rec = old_vers;
} else {
/* We are looking into a non-clustered index,
and to get the right version of the record we
have to look also into the clustered index: this
is necessary, because we can only get the undo
information via the clustered index record. */
ut_ad(!dict_index_is_clust(index));
// 这里处理是Secondary index扫描的情况
if (!lock_sec_rec_cons_read_sees(
rec, trx->read_view)) {
/* We should look at the clustered index.
However, as this is a non-locking read,
we can skip the clustered index lookup if
the condition does not match the secondary
index entry. */
// 这里InnoDB做了一下优化,如果当前记录不满足ICP,直接查找下一条记录;如果满足ICP则需要继续根据聚集索引寻找历史版本
switch (row_search_idx_cond_check(
buf, prebuilt, rec, offsets)) {
case ICP_NO_MATCH:
goto next_rec;
case ICP_OUT_OF_RANGE:
err = DB_RECORD_NOT_FOUND;
goto idx_cond_failed;
case ICP_MATCH:
goto requires_clust_rec;
}
ut_error;
}
}
}
...
}
}
接下来我们看一下UPDATE的执行过程。对于UPDATE操作执行流程的简单描述如下:
根据WHERE条件扫描一条记录(row_search_for_mysql)
更新当前获取的记录(ha_innobase::update_row)
重新将更新后的记录写入InnoDB存储引擎(row_upd_step)
那么我们按照上面的这个流程看一下源码方面的执行过程:
UNIV_INTERN
dberr_t
row_search_for_mysql(
/*=================*/
byte* buf, /* 用来存放记录的空间地址 */
ulint mode, /* InnoDB页扫描顺序 */
row_prebuilt_t* prebuilt, /* InnoDB扫描需要的所有信息都包含在这个结构体,比如表以及Index等信息 */
ulint match_mode, /* 对于Index的匹配模式,是精确匹配还是前缀索引匹配 */
ulint direction) /* 指定扫描顺序,正序还是倒叙扫描 */
{
...
/* 从这里我们看出开始一个新事务,并非是从执行BEGIN语句位置开始,而是从其后开始执行的第一条语句开始分配事务ID */
trx_start_if_not_started(trx, ((trx->mysql_thd
&& thd_is_select(trx->mysql_thd)
) || srv_read_only_mode) ? FALSE : TRUE);
...
// 如果是SQL语句第一次开始执行,需要考虑对TABLE增加意向所
if (!prebuilt->sql_stat_start) {
// 这里标记SQL语句已经开始执行,处理一条SQL语句循环扫描记录的过程
/* No need to set an intention lock or assign a read view */
if (UNIV_UNLIKELY
(trx->read_view == NULL
&& prebuilt->select_lock_type == LOCK_NONE)) {
...
}
} else if (prebuilt->select_lock_type == LOCK_NONE) {
...
} else {
// 这里开始非INSERT的DML操作,因为DML会对记录增加记录排他锁。具体需要增加什么类型的锁,可以参考https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html
wait_table_again:
// 这里要对TABLE加意向锁
err = lock_table(0, index->table,
prebuilt->select_lock_type == LOCK_S
? LOCK_IS : LOCK_IX, thr);
if (err != DB_SUCCESS) {
table_lock_waited = TRUE;
goto lock_table_wait;
}
prebuilt->sql_stat_start = FALSE;
}
...
if (prebuilt->select_lock_type != LOCK_NONE) {
ulint lock_type;
if (!set_also_gap_locks
|| srv_locks_unsafe_for_binlog
|| trx->isolation_level <= TRX_ISO_READ_COMMITTED
|| (unique_search && !rec_get_deleted_flag(rec, comp))) {
// 这里对于READ_UNCOMMITTED以及READ_COMMITTED,或者唯一键扫描不需要使用gap锁
goto no_gap_lock;
} else {
lock_type = LOCK_ORDINARY;
}
/* If we are doing a 'greater or equal than a primary key
value' search from a clustered index, and we find a record
that has that exact primary key value, then there is no need
to lock the gap before the record, because no insert in the
gap can be in our search range. That is, no phantom row can
appear that way.
An example: if col1 is the primary key, the search is WHERE
col1 >= 100, and we find a record where col1 = 100, then no
need to lock the gap before that record. */
if (index == clust_index
&& mode == PAGE_CUR_GE
&& direction == 0
&& dtuple_get_n_fields_cmp(search_tuple)
== dict_index_get_n_unique(index)
&& 0 == cmp_dtuple_rec(search_tuple, rec, offsets)) {
no_gap_lock:
lock_type = LOCK_REC_NOT_GAP;
}
err = sel_set_rec_lock(btr_pcur_get_block(pcur),
rec, index, offsets,
prebuilt->select_lock_type,
lock_type, thr);
switch (err) {
const rec_t* old_vers;
case DB_SUCCESS_LOCKED_REC:
if (srv_locks_unsafe_for_binlog
|| trx->isolation_level
<= TRX_ISO_READ_COMMITTED) {
/* Note that a record of
prebuilt->index was locked. */
prebuilt->new_rec_locks = 1;
}
err = DB_SUCCESS;
case DB_SUCCESS:
// 加锁成功后就认为记录可见了,并未像SELECT语句一样根据事务开始的READ_VIEW进行可见性判断。所以对于DML来说,所有提交的事务都是可见的。
break;
case DB_LOCK_WAIT:
/* Never unlock rows that were part of a conflict. */
// 如果存在锁冲突,也就是其他事务正在更新同一行
prebuilt->new_rec_locks = 0;
if (UNIV_LIKELY(prebuilt->row_read_type
!= ROW_READ_TRY_SEMI_CONSISTENT)
|| unique_search
|| index != clust_index) {
goto lock_wait_or_error;
}
/* The following call returns 'offsets'
associated with 'old_vers' */
// 这里需要查看是否有别的事务提交了,以便获取最新版本的记录
row_sel_build_committed_vers_for_mysql(
clust_index, prebuilt, rec,
&offsets, &heap, &old_vers, &mtr);
/* Check whether it was a deadlock or not, if not
a deadlock and the transaction had to wait then
release the lock it is waiting on. */
err = lock_trx_handle_wait(trx);
switch (err) {
case DB_SUCCESS:
/* The lock was granted while we were
searching for the last committed version.
Do a normal locking read. */
offsets = rec_get_offsets(
rec, index, offsets, ULINT_UNDEFINED,
&heap);
goto locks_ok;
case DB_DEADLOCK:
goto lock_wait_or_error;
case DB_LOCK_WAIT:
err = DB_SUCCESS;
break;
default:
ut_error;
}
if (old_vers == NULL) {
/* The row was not yet committed */
goto next_rec;
}
did_semi_consistent_read = TRUE;
rec = old_vers;
break;
default:
goto lock_wait_or_error;
}
}
从上面的代码我们可以看到,对于UPDATE操作更新的记录包含幻读读取到的已提交事务的最新记录。那么接下来看为什么UPDATE之后的SELECT语句对于UPDATE之后的所有语句都可见了? 原因是前面的UPDATE语句执行之后,会将当前记录上存储的事务信息更新为当前的事务,而当前事务所做的任何更新,对本事务所有SELECT查询都变的可见,因此最后输出的结果是UPDATE执行后更新的所有记录。
当前各种数据库对于隔离级别的支持不尽相同,比如ORACLE,它只实现了READ COMMITTED和SERIALIZABLE两种ANSI SQL STANDARD规定的隔离级别(这里ORACLE还实现了一种自定义的READ ONLY隔离级别,具体请参考https://docs.oracle.com/cd/B28359_01/server.111/b28318/consist.htm#CNCPT621) , 而没有实现REPEATABLE READ。对于相同的隔离级别,不同的数据库有着自己不同的实现方式。所以我们在理解隔离级别的时候需要针对具体的数据库。综上所述,我们看到了MySQL InnoDB引擎对于REPEATABLE READ隔离级别有着不同于其他数据库的实现方式。而该实现方式符合ANSI SQL STANDARD,并非属于实现上的BUG。