MySQL · 实现分析 · HybridDB for MySQL 数据压缩
Author: 田汉
概述
数据压缩是一个把输入数据集按照一定的算法变换成更小的数据集的过程,解压是压缩的逆过程。如果算法对数据本身的语义了解得越多,则越可能利用语义信息进行针对性的处理,获得更好的压缩效果。数据库系统中用得比较多的压缩算法可以分为两大类:基于块的压缩、基于值的压缩。前者更为常见一些,在 OLTP 以及 OLAP 系统中都会用到,例如 InnoDB、TokuDB、HybridDB 中的块压缩;后者更多的用在 OLAP 的列存引擎内,例如 HybridDB for MySQL 中的列压缩。为了区别它们,这里把块压缩简称为压缩(Compression)、而把基于值的压缩称为编码(Encoding)。此外,在存储系统中比较常见的重复数据删除功能也可以被视为一种特殊形式的压缩。不过它不属于本文要考虑的范围。
通常来说,列存格式对压缩要更友好。大概而言,行存的数据压缩率一般为3:1(采用通用压缩算法);列存的数据压缩率为10:1(采用编码以及通用的压缩算法)。
无论是哪种形式的压缩,衡量算法本身是否适用的指标主要有:
- 压缩率,也就是压缩前后数据大小的比率。
- 吞吐量,也就是压缩和解压的速度。典型单位为 GB/s。
- 资源消耗,压缩解压一般是计算密集型的算法,因此主要考虑的是 CPU 消耗。
压缩
压缩算法可以说是无处不在。常见的例子如各种文件压缩工具背后的压缩算法,包括 zip、rar 等等;各种图片格式对应的压缩算法,包括 png、jpeg 等等。数据库系统中用的都是无损压缩,图片压缩则可以采用有损压缩。很多算法都属于 lz 系列,例如:lz、lzo、quicklz 等等。多年以前 Google 推出的 Snappy ,虽然压缩率不是特别出众,但是吞吐量比较大、资源消耗比较小,因此获得了广泛的应用。最近几年 Facebook 推出的 zstd 算法具有类似的特征,也获得了很多应用。zstd 的主页上有一些测试的数据,可以作为参考:
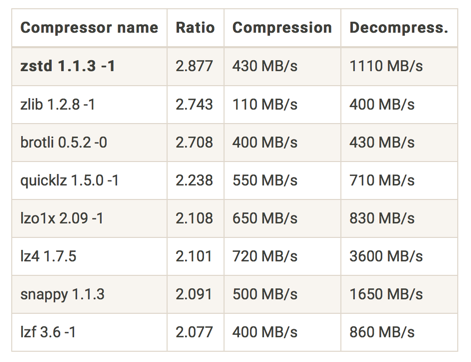
编码
编码则是利用数据的语义信息进行更加有针对性的压缩。当然,很多算法也在通用的压缩算法中被采用了。常见的编码算法有:行程编码(Run Length Encoding)、字典编码(Dictionary)、差值编码(Delta)、变长整数编码(Varint)、位变换(Bit Shuffle)、前缀编码(Prefix)、异或(XOR)等等。甚至可以说有多少种数据的规律就可以发明出多少种编码算法。例如:InfoBright 就可以对一系列的数字除以最大公约数,获得更小的数字,从而达到数据压缩的目的。
产品
下面让我们来看一看典型的几个 OLAP 产品对压缩算法的支持。
Apache Kudu
Apache Kudu 是一个比较有意思的项目,它支持多副本、列存,试图解决实时分析的需求。下图是它支持的编码/压缩方法:
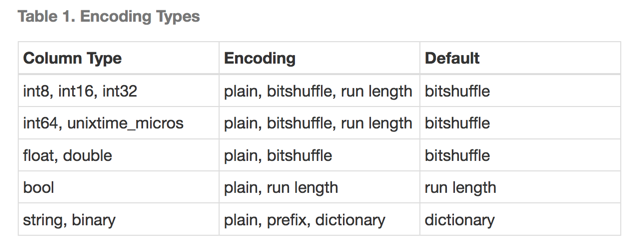
相对其他系统而言,Kudu 编码中比较特殊的一种是 BitShuffle 编码。假设输入的是类型 T 的一个数组,该编码的算法是:先保存每个值的 MSB 位(最高位),然后下一个 bit 位,一直到最后的 LSB(最低位);然后对数据进行 LZ4 压缩。该编码适合与重复值较多的列或者列值变化不大的情况。除了上述的编码之外,Kudu 也支持通用压缩算法,例如:lz4、snappy、zlib。默认情况下,列是不压缩的。而且 Bitshuffle 编码后的列总是自动采用 lz4 压缩。
Amazon RedShift
Amazon RedShift 支持的编码/压缩算法如下:

从图中可以看出,RedShift 支持 Delta、字典、RLE、Mostly、Text255 等编码。比较特别的是 Text255 和 text32k,它们适合与单词重复出现的 VARCHAR 列。实际上,它就是对每个 1MB 块中的单词创建了一个字典。字典容纳 245 个唯一的单词,数据实际存储的时候用一个字节的索引代替对应的单词。
Pivotal GPDB
Pivotal GPDB 的 Append Only Table 也支持压缩算法 。

相对而言,GPDB 支持的编码和压缩种类要稍少一些。但是它允许设置算法的压缩级别以及块的大小。
总结
不同的通用压缩算法在压缩率和速度以及资源消耗之间做了不同程度的权衡,有些算法(例如 zlib)还提供了一些压缩级别的参数可供调整。针对不同的数据集合,压缩率也存在较大的区别。例如:在采用某个特定数据集的测试中,snappy 的压缩率接近 3,而 zlib 和 zstd 的压缩率大约为 4。编码算法的压缩率对数据集的类型和取值更为敏感,例如 delta 算法对整数类型,并且相邻数据之间差别较小的情况下(例如自增列),压缩比就很好。对于浮点数而言,提高要缩率更为困难,Facebook 等曾经做过一些针对性的优化。
如果想要了解数据压缩的基本背景,请参考:Data compression tutorial 。如果想要获得对列存系统的更多知识(包括列存对数据压缩的优化),则建议移步:Column store tutorial 。
参考资料
1.Snappy 2.Zstd 3.Apache Kudu 4.Amazon RedShift 5.GreenPlum Database 6.Gorilla 7.Data compression tutorial 8.Column store tutorial