PgSQL · 最佳实践 · 双十一数据运营平台订单Feed数据洪流实时分析方案
Author: 窦贤明
摘要
2017年的双十一又一次刷新了记录,交易创建峰值32.5万笔/秒、支付峰值25.6万笔/秒。而这样的交易和支付等记录,都会形成实时订单Feed数据流,汇入数据运营平台的主动服务系统中去。
数据运营平台的主动服务,根据这些合并后的数据,实时的进行分析,进行实时的舆情展示,实时的找出需要主动服务的对象等,实现一个智能化的服务运营平台。
通过阿里云RDS PostgreSQL和HybridDB for PGSQL实时分析方案:
- 承受住了几十万笔/s的写入吞吐并做数据清洗,是交易的数倍
- 实现分钟级延迟的实时分析,5张十亿级表关联秒级响应
- 实时发现交易异常,提升淘宝的用户体验。
业务背景
一个电商业务通常会涉及 商家、门店、物流、用户、支付渠道、贷款渠道、商品、平台、小二、广告商、厂家、分销商、店主、店员、监管员、税务、质检等等角色,这些对象的活动会产生大量的 浏览、订单、投诉、退款、纠纷等业务数据。
而任何一笔业务,都会涉及很多不同的业务系统。在这些业务系统中,为了定位问题、运营需要、分析需要或者其他需求,会在系统中设置埋点,记录用户的行为在业务系统中产生的日志,也叫FEED日志。比如订单系统、在业务系统中环环相扣,从购物车、下单、付款、发货,收货(还有纠纷、退款等等),一笔订单通常会产生若干相关联的记录。
每个环节产生的属性可能是不一样的,有可能有新的属性产生,也有可能变更已有的属性值。为了便于分析,通常有必要将订单在整个过程中产生的若干记录(若干属性),合并成一条记录(订单大宽表)。
数据运营平台的主动服务,根据这些合并后的数据,实时的进行分析,进行实时的舆情展示,实时的找出需要主动服务的对象等,实现一个智能化的服务运营平台。
难点
该项目不止业务逻辑复杂,实时性和性能要求都极高。具体的有:
- 复杂查询的极限性能,比如5张过十亿的表关联
- 实时性,要求分钟级以内的延迟
- 高并发写入
- 吞吐压力高达每秒几十万笔/s
- 每个SQL分析的数据总是在TB级
- 响应时间要求秒级、毫秒级
除了实时性的要求以外,在写入的过程中,还有数据的切换、合并和清理等动作。做过数据库或数据分析的会知道:单独要做到每秒80万/s吞吐的写入、切换、合并和清理并不算特别困难;单独要做到TB级数据的毫秒级分析也不算困难。
但要做到实时写入的同时提供分钟级延迟的秒级实时分析,并做合理的调度就没那么容易了。
方案
为支撑这样的业务需求,采用的方案图示如下:
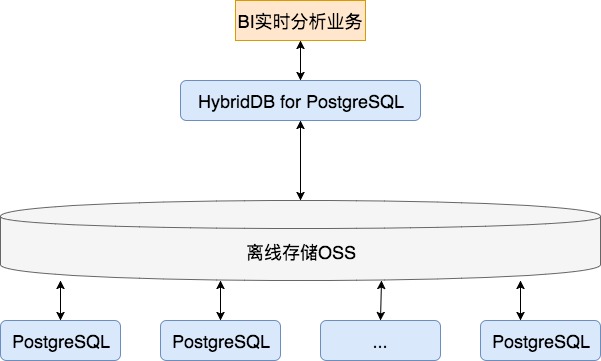
其中:
- RDS PostgreSQL 是阿里云基于开源关系型数据库PostgreSQL开发的云上版本
- HybridDB for PostgreSQL是MPP架构的分布式分析型数据库,在多表关联、复杂查询、实时统计、圈人等诸多方面性能卓越,并支持JSON、GIS、HLL估值等多种独特的功能特性
- OSS,是阿里云推出的海量、安全、低成本、高可靠的云存储服务,此处用作数据的离线存储
- 最关键的,是实现RDS PostgreSQL和HybridDB for PostgreSQL 对离线存储OSS的透明化访问能力
在该方案中,多个PostgreSQL接受业务的写入,在每个RDS PostgreSQL中完成数据的清洗,然后以操作外部表(类似堆表)的方式,将清洗完的数据写入弹性存储OSS;而在写入完成后,HybridDB for PostgreSQL 也以操作外部表(类似堆表)的方式,从OSS中将数据并行加载到HybridDB中。在HybridDB中,实现几十、几百TB级数据的毫秒级查询。
在PostgreSQL中,创建一个外部表:
# 创建插件,每个库执行一次
create extension oss_fdw;
# 创建 server,每个OSS bucket创建一个
CREATE SERVER ossserver FOREIGN DATA WRAPPER oss_fdw OPTIONS
(host 'oss-cn-hangzhou-zmf.aliyuncs.com' , id 'xxx', key 'xxx',bucket 'mybucket');
# 创建 oss 外部表,每个需要操作的OSS对象对应一张表
CREATE FOREIGN TABLE ossexample
(date text, time text, volume int)
SERVER ossserver
OPTIONS ( filepath 'osstest/example.csv', delimiter ',' ,
format 'csv', encoding 'utf8', PARSE_ERRORS '100');
这样即创建了映射到OSS对象的表,通过对ossexample的读写即是对OSS的读写。在数据写入”local_tbl”中后,执行以下SQL:
# 数据写入OSS
insert into ossexample
select date, time, volume) from local_tbl where date > '2017-09-20';
表”local_tbl”中满足过滤条件的数据,即会写入OSS对应的对象”osstest/example.csv”中。
在HybridDB for PostgreSQL也用与此类似的方式读写OSS。整个过程,用户看到的只是一条条SQL。如下:
# 创建外部表,用于导出数据到OSS
create WRITABLE external table ossexample_exp
(date text, time text, volume int)
location('oss://oss-cn-hangzhou.aliyuncs.com
prefix=osstest/exp/outfromhdb id=XXX
key=XXX bucket=testbucket') FORMAT 'csv'
DISTRIBUTED BY (date);
# 创建堆表,数据就装载到这张表中
create table example
(date text, time text, volume int)
DISTRIBUTED BY (date);
# 数据并行的从 ossexample 装载到 example 中
insert into example select * from ossexample;
该INSERT语句的执行,即会将”osstest/exp/outfromhdb” 文件中的数据,并行写入到表”example”中。其原理如下:
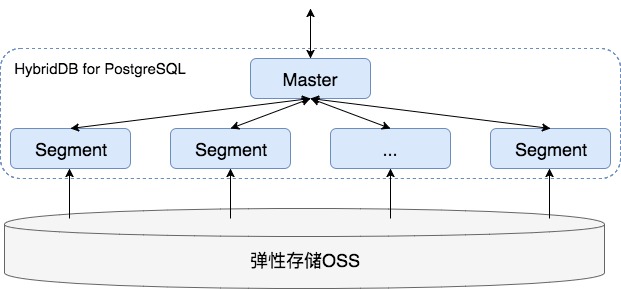
HybridDB 是分布式数据库,一个HybridDB for PostgreSQL集群中,有一个Master和多个Segment,Segment的个数可以横向扩充。Segment负责存储、分析数据,Master则是主入口接受查询请求并分发。
通过每个Segment并行从OSS上读取数据,整个集群可以达到相当高的吞吐能力,且这个能力随Segment个数而线性增加。
方案优势
上面的方案初看起来并不复杂,却解决了下面几个问题:
1.性能
融合了PostgreSQL超强的并发写入性能与HybridDB卓越的分析性能。
单个RDS PostgreSQL甚至可以支撑到百万级的写入; 而写入PostgreSQL后批量加载到HybridDB,使得PostgreSQL与HybridDB无缝衔接,利用MPP卓越的分析性能做到实时的毫秒级查询。
2.数据的搬运与清洗
在传统的分析领域,数据的搬运往往是比较重、且性能较差的一环,导致TP和AP距离较远,只能采用截然不同的方式和节奏。而如果是异构数据库的搬运,则痛苦指数再上台阶。
如果这些,都可以通过SQL来操作,数据的清洗和搬运最终都只是SQL的定义与执行,岂不美哉?
在上图中,RDS PostgreSQL 和 HybridDB for PostgreSQL都有直接读写OSS的能力,可以很容易地的串联起来。假以合理的调度和封装,可以以较低的成本实现原本需要很多工作量的功能。
3.冷热数据的统一
而借操作离线存储的能力,可以将冷数据放在OSS,热数据放在PostgreSQL或者HybridDB for PostgreSQL,可以通过SQL以相同的处理方式实现对冷热数据的统一处理。
4.动态调整资源
云生态的好处之一就是动态与弹性。RDS PostgreSQL的资源可以随时动态调整,而不影响任何的可用性,相当于给飞机在空中加油;而对HybridDB的扩容与缩容,则是秒级切换即可完成。OSS本身的弹性,也允许客户放多少的数据都可以。
因此,带来了如下几点优势:
- 相比于传统的数据分析方案,以SQL为统一的方式进行数据的管理,减少异构;
- 资源动态调度,降低成本
- 冷热数据界限模糊,直接互相访问
- TP、AP一体化
- RDS PostgreSQL的个数没有限制;HybridDB集群的数量没有限制
阿里云云数据库PostgreSQL
阿里云云数据库 PostgreSQL,基于号称“Most Advanced”的开源关系型数据库。在StackOverflow 2017开发者调查中,PostgreSQL可以说是“年度统计中开发者最爱和最想要的关系型数据库”。
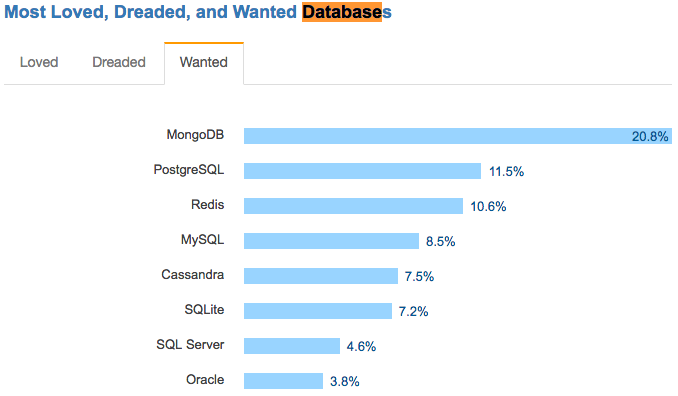
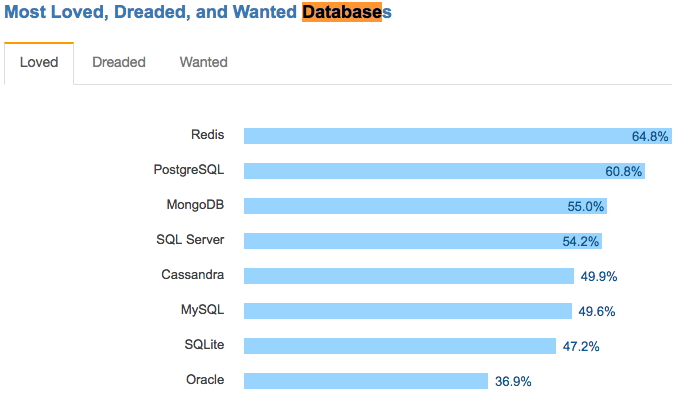
PostgreSQL的优势有以下几点:
-
稳定
PostgreSQL的代码质量是被很多人认可的,经常会有人笑称PG的开发者都是处女座。基本上,PG的一个大版本发布,经过三两个小版本就可以上生产,这是值得为人称道的一个地方。从PostgreSQL漂亮的commit log就可见一斑。
而得益于PostgreSQL的多进程架构,一个连接的异常并不影响主进程和其他连接,从而带来不错的稳定性。
-
性能
我们内部有些性能上的数据,TPCC的性能测试显示PostgreSQL的性能与商业数据库基本在同一个层面上。
-
丰富
PostgreSQL的丰富性是最值得诉说的地方。因为太丰富了,以至于不知道该如何突出重点。这里只列举几个认为比较有意思的几点(查询、类型、功能):
-
查询的丰富
且不说HASH\Merge\NestLoop JOIN,还有递归、树形(connect by)、窗口、rollup\cube\grouping sets、物化视图、SQL标准等,还有各种全文检索、规则表达式、模糊查询、相似度等。在这些之外,最重要的是PostgreSQL强大的基于成本的优化器,结合并行执行(并行扫瞄、并行JOIN等)和多种成本因子,带来各种各样丰富灵活高效的查询支持。
-
类型的丰富
如高精度numeric, 浮点, 自增序列,货币,字节流,时间,日期,时间戳,布尔, 枚举,平面几何,立体几何,多维几何,地球,PostGIS,网络,比特流,全 文检索,UUID,XML,JSON,数组,复合类型,域类型,范围,树类型,化 学类型,基因序列,FDW, 大对象, 图像等。
[PS: 这里的数组,可以让用户像操作JAVA中的数组一样操作数据库中的数据,如 item[0][1]即表示二维数组中的一个元素,而item可以作为表的一个字段。]
或者,如果以上不够满足,你可以自定义自己的类型(create type),并且可以针对这些类型进行运算符重载,比如实现IP类型的加减乘除(其操作定义依赖于具体实现,意思是:你想让IP的加法是什么样子就是什么样子)。
另外还有各种索引的类型,如btree, hash, gist, sp-gist, gin, brin , bloom , rum 索引等。你甚至可以为自己定义的类型定制特定的索引和索引扫瞄。
-
功能的丰富
PostgreSQL有一个无与伦比的特性——插件。其利用内核代码中的Hook,可以让你在不修改数据库内核代码的情况下,自主添加任意功能,如PostGIS、JSON、基因等,都是在插件中做了很多的自定义而又不影响任何内核代码从而满足丰富多样的需求。而PostgreSQL的插件,不计其数。
FDW机制更让你可以在同一个PostgreSQL中像操作本地表一样访问其他数据源,如Hadoop、MySQL、Oracle、Mongo等,且不会占用PG的过多资源。比如我们团队开发的OSS_FDW就用于实现对OSS的读写。
-
至于其他的,举个简单的例子,PostgreSQL的DDL(如加减字段)是可以在事务中完成的 [PS: PostgreSQL是Catalog-Driven的,DDL的修改基本可以理解为一条记录的修改]。这一点,相信做业务的同学会有体会。
而在开源版本的基础上,阿里云云数据库PostgreSQL增加了HA、无缝扩缩容、自动备份、恢复与无感知切换、离线存储透明访问、诊断与优化等诸多功能,解除使用上的后顾之忧。更多的建议访问阿里云官网产品页(见文下参考)。
阿里云HybridDB for PostgreSQL
HybridDB for PostgreSQL是MPP架构的分布式分析型数据库,基于开源Greenplum,在多表关联、复杂查询、实时统计、圈人等诸多方面性能卓越。在此基础上,阿里云HybridDB for PostgreSQL提供JSON、GIS、HLL估值、备份恢复、异常自动化修复等多种独特的功能特性;并在METASCAN等方面做了诸多性能优化,相比开源版本有质的提升。
阿里云HybridDB for PostgreSQL有以下特点:
-
实时分析
支持SQL语法进行分布式GIS地理信息数据类型实时分析,协助物联网、互联网实现LBS位置服务统计;支持SQL语法进行分布式JSON、XML、模糊字符串等数据实时分析,助金融、政企行业实现报文数据处理及模糊文本统计。
-
稳定可靠
支持分布式ACID数据一致性,实现跨节点事务一致,所有数据双节点同步冗余,SLA保障99.9%可用性;分布式部署,计算单元、服务器、机柜三重防护,提高重要数据基础设施保障。
-
简单易用
丰富的OLAP SQL语法及函数支持,众多Oracle函数支持,业界流行的BI软件可直接联机使用;可与云数据库RDS(PostgreSQL/PPAS)实现数据通讯,实现OLTP+OLAP(HTAP)混合事务分析解决方案。
支持分布式的SQL OLAP统计及窗口函数,支持分布式PL/pgSQL存储过程、触发器,实现数据库端分布式计算过程开发。
符合国际OpenGIS标准的地理数据混合分析,通过单条SQL即可从海量数据中进行地理信息的分析,如:人流量、面积统计、行踪等分析。
-
性能卓越
支持行列混合存储,列存性能在OLAP分析时相比行存储可达100倍性能提升;支持高性能OSS并行数据导入,避免单通道导入的性能瓶颈。
基于分布式大规模并行处理,随计算单元的添加线性扩展存储及计算能力,充分发挥每个计算单元的OLAP计算效能。
-
灵活扩展
按需进行计算单元,CPU、内存、存储空间的等比扩展,OLAP性能平滑上升致数百TB;支持透明的OSS数据操作,非在线分析的冷数据可灵活转存到OSS对象存储,数据存储容量无限扩展。
通过MySQL数据库可以通过mysql2pgsql进行高性能数据导入,同时业界流行的ETL工具均可支持以HybridDB为目标的ETL数据导入。
可将存储于OSS中的格式化文件作为数据源,通过外部表模式进行实时操作,使用标准SQL语法实现数据查询。
支持数据从PostgreSQL/PPAS透明流入,持续增量无需编程处理,简化维护工作,数据入库后可再进行高性能内部数据建模及数据清洗。
-
安全
IP白名单配置,最多支持配置1000个允许连接RDS实例的服务器IP地址,从访问源进行直接的风险控制。
DDOS防护, 在网络入口实时监测,当发现超大流量攻击时,对源IP进行清洗,清洗无效情况下可以直接拉进黑洞。
总结
利用阿里云的云生态,RDS PostgreSQL、HybridDB for PostgreSQL等一系列云服务,帮助企业打造智能的企业数据BI平台,HybridDB for PostgreSQL也企业大数据实时分析运算和存储的核心引擎。实现企业在云端从在线业务、到数据实时分析的业务数据闭环。