MySQL · 捉虫动态 · UK 包含 NULL 值备库延迟分析
Author: fungo
前言
在之前的月报 RDS 只读实例延迟分析 中,我们介绍了一些常见的备库延迟的场景,今天给大家分享一个比较少见的特殊场景。
简单的来说,就是在 UK 索引中存在大量 NULL 值情况下,如果备库选用这个 UK 来同步更新,会导致非常大的延迟。
背景知识
UK 中有大量 NULL 值,第一次看到这个可能会觉得有点奇怪,但是这确实是允许的,官方文档写的非常清楚:
A UNIQUE index creates a constraint such that all values in the index must be distinct. An error occurs if you try to add a new row with a key value that matches an existing row. For all engines, a UNIQUE index permits multiple NULL values for columns that can contain NULL.
同时这个也是SQL92标准定义的:
A unique constraint is satisfied if and only if no two rows in a table have the same non-null values in the unique columns. In addition, if the unique constraint was defined with PRIMARY KEY, then it requires that none of the values in the specified column or columns be the null value.
关于这个问题,官方bug list 也有激烈的讨论: Bug #8173 unique index allows duplicates with null values,有的人认为是 feature,有的人认为是 bug。
NULL 和 NULL 是不一样的,我们可以将 NULL 理解为未知,虽然现在不知道,但它未来有很多可能性,只是我们现在还不知道而已。
MySQL 对于 NULL 也有专门的处理,例如比较运算符,以及一些函数在 NULL 上是失效的,结果可能出乎意料,详细情况可以参考官方文档 Working with NULL Values 和 Problems with NULL Values。
问题描述
介绍完背景知识,我们来看下具体问题吧。问题来源于真实用户 case,下面的表结结构和数据是为了说明方便特殊构造的。
表结构如下:
ds_logs_uk
Create Table: CREATE TABLE `rds_logs_uk` (
`id` bigint(20) NOT NULL,
`ins_name` varchar(32) NOT NULL DEFAULT 'ins',
`ins_uuid` varchar(36) DEFAULT NULL,
UNIQUE KEY `idx_uuid` (`ins_uuid`),
KEY `idx_name` (`ins_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
可以看到 UK 的 column 是允许 NULL的,我们看下数据分布情况:
mysql> select count(*) from rds_logs_uk where ins_uuid is NULL;
+----------+
| count(*) |
+----------+
| 24549655 |
+----------+
mysql> select count(ins_uuid) from rds_logs_uk where ins_uuid is not NULL;
+-----------------+
| count(ins_uuid) |
+-----------------+
| 20505406 |
+-----------------+
可以看到 NULL 基本占了一半多。
我们用脚本在主库上,每隔 1s 执行下面的 SQL:
delete from rds_logs_uk where ins_name >= '888' and ins_name <= '899' and ins_uuid is NULL limit 1;
然后监控主备的 InnoDB rows 统计信息:
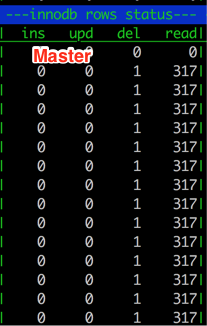
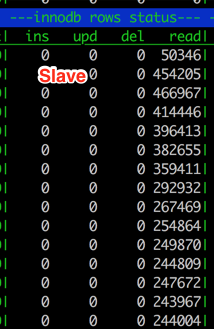
可以看到备库在做大量的查询,还没有删到一条记录,这就导致了备库延迟。
问题分析
为什么会差别这么大呢,我们在主库只删除一条记录,扫了317行,但是到了备库后,扫了很多行,连一条匹配的记录都没找到,一个比较可能的解释是走的索引不一样了。主库上 explain 的结果如下:

主库用了 idx_name 这个普通二级索引,而没有用UK,因为主库优化器算出来,走 UK 的代价更大。
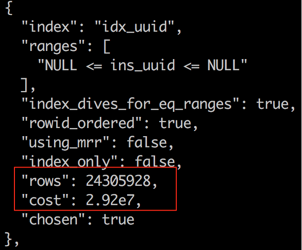
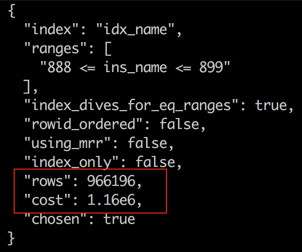
从上面的现象,我们可以大致推出,备库跑的更慢,是因为备库在同步更新时,用错了索引,用 UK 来更新。
为什么会选错索引呢,在 ROW 格式下,备库在同步更新时,索引的选择是基于简单规则的,没有走优化器的代价模型,规则如下:
- PK
- UK without NULL
- other keys(include UK with NULL)
- table_scan
从1到4,优先级依次递减,在选择时,只要有索引满足规则,就选择这个索引,并不再往下找了。具体的逻辑在 sql/log_event.cc:search_key_in_table() 中,大家可以自己看下代码,这里就不在贴了。
按照我们的表结构,是会用第3条规则来选出索引的,按索引的先后顺序,遍历一遍,找到第一个可用的。什么样的索引是可用呢,只要索引对应的字段,在 event row 中存在,就是可用的,而我们的 binlog_row_image = FULL,这样每一个索引都是用到的,而 UK 是排在普通二级索引前面的,所以就选了 UK。做删除时,需要先查到和 delete image 匹配的记录,然后再删除。用NULL值在UK上扫描,虽然 NULL 和 NULL 值是不一样的,但是在实现表示上都是一样的,也就是说所有的 NULL 在索引在是排列在一起的,这样通过在 UK 查找很多 NULL 然后回表拿到全字段记录,发现和 delete image 中记录不匹配,最终导致在找到匹配记录前,扫描了大量的NULL。
为什么这里没用优化器的代码计算呢,小编认为有正面的原因,也有反面的原因:
正面来看,因为在 row 格式 full image 下,相当于 where 条件所有字段都有的,PK/UK 这种索引如果有是肯定能用上的,而通常都会有PK的。
反面来看,因为每个 row 都做一次代价评估,太不划算了。。。主库上一条 SQL 可能更新了 n 条记录,只需要做一次代价计算,而备库在同步row binlog 时,每个 row 都要做一次代价计算,这样代价计算的成本,就会非常高。
问题解决
如果遇到这种情况,怎么解呢?解法有多种,目的都是一样,让备库不选择 UK 来做同步。
- 加法:在备库加一个比当前 UK 更好的索引,需要更好的UK和PK,不能是普通二级索引,因为普通二级索引,是排在UK后面的,不会被选择。
- 减法:直接 drop 掉 UK,在做读写分离的备库上,不建议这么做,因为可能影响业务的查询。
- 比 2 轻量一点,用 Invisible Index 特性。MySQL 官方 8.0 和 AliSQL 都支持 Invisible Index,我们可以在备库上把 UK 临时改成 Invisible,等备库同步完后,再改回 Visible。不过我们在实际测试中,发现这个方法不起作用,因为备库应用 row 时,根本不认 invisible 属性,这个已经跟官方提 bug#88847,AliSQL 在即将发布的新版本中,会 fix 掉这个问题,欢迎大家使用。