Influxdb · 源码分析 · Influxdb cluster实现探究
Author: fengyu
背景
Influxdb cluster在0.12版本的release notes中声明,将cluster代码闭源,并且将cluster版本作为商业版售卖。
虽然cluster版本毕源已经一年多的时间,从目前官网中release notes来看,总体的设计没有发生变化。
本文主要探讨influxdb cluster 0.11版本的实现细节,学习参考。本文将参考官方博客中的一篇设计文稿,同时参考Influxdb最后的一个cluster开源版本的源代码,分析influxdb cluster实现,水平有限,欢迎指正。
参考博文 :
https://www.influxdata.com/blog/influxdb-clustering-design-neither-strictly-cp-or-ap/
https://www.influxdata.com/blog/influxdb-clustering/
https://docs.influxdata.com/enterprise_influxdb/v1.3/concepts/clustering/
https://docs.influxdata.com/enterprise_influxdb/v1.3/guides/anti-entropy/
InfluxDB Clustering Design – neither strictly CP or AP
cluster设计约定
下述为官方的influxdb cluster设计约定。
- 时间序列数据总是新数据,且数据写入后是不会发生变化的。
- 如果同一时间点写入了多次同样的数据,数据肯定是重复写入的
- 基本不会出现删除数据的情况, 删除数据基本上都是对过期数据的一个大批量的过期删除。
- 基本不会存在更新存量数据的情况,并发的修改不会出现
- 绝大对数的写入都是最近时间的数据
- 数据的规模会非常大,很多场景下数据量大小会在TB和PB量级。
- 能够写入和查询数据会比强一致性更加重要
- 很多time series非常短暂的存在,所以time series 数量比较大。
需求
- Horizontally scalable - 设计需要能够支持数百个节点,并且可以扩展到数千个节点。 读写能力需要按照节点数量线性增长。
- Available - 对于读写能力,我们需要AP design,既可用性优先。Time series不断写入增长,对大多数最近的写入数据不需要强一致性。
- 需要支持十亿级别的 time series, 一个独立的series由 measurement name + tag set 组成。 这个量级的需求原因是我们会存在短暂的 time series的假设。
- Elastic - 架构设计上集群中节点可以删除和增加。
cluster design
系统架构图
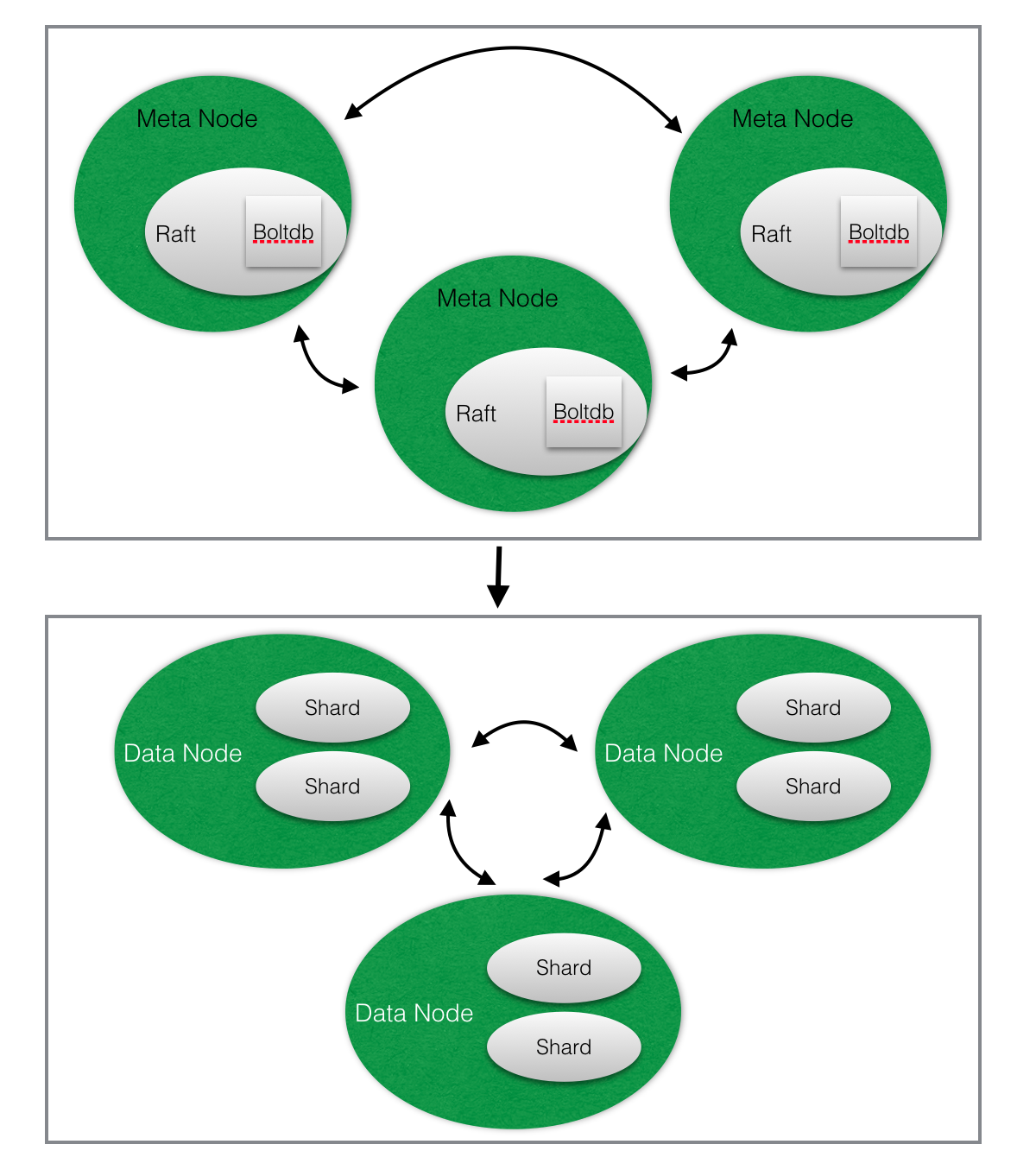
Cluster Metadata – CP
首先解释这个CP的含义是CAP理论中的CP,C: consistence一致性 , P表示PARTITION TOLERANCE,CP表示cluster 元数据的服务,更加着重保障系统的一致性。
图中上半部分是metadata node, 存储元数据包括:
- 集群中主机信息,包括meta node和data node.
- databases, retention policies, continuous queries
- users and permissions
- Shard groups - 每个shards的开始和结束时间
- Shars - shard id 落在哪个server上的元信息
每个metadata 节点会通过一个简单的http 对外提供服务,其中raft的实现是: https://github.com/hashicorp/raft,raft底层数据存储使用Boltdb。
每个server (datanode)会保持一份cluster metadata的数据拷贝,会定时调用http接口获取存量元数据感知元数据的变化。当request请求到该data node时,如果cache miss, 此时调用metadata获取对应的元数据。
Cluster Data Write – AP
AP的含义是CAP理论中的AP,表示系统系统设计着重保障系统的可用性,舍弃一致性。下述介绍一个write请求的访问流程。
Shard Group
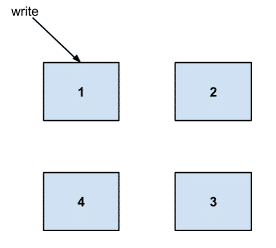
前提:
- 如果一个集群中存在server 1,2,3,4 , client的写入请求可以随意访问server1,2,3,4的任何一台上,然后由data node路由到其他的server上,如本例子中请求落在了1中。
Shard Group是什么?
- influxdb中将数据根据时间进行分区写入到不同的shard中。如influxdb会划分24 hours为一个时间分区,根据写入point的时间归属写入到不同的shard中。
- 由于influxdb cluster为了能够写入能力随机器数量横向扩展,所以虽然还按照24 hours作为一个shard,但是会将写入数据进行hash到不同的后端server中存储。例如有10台机器,那么写入会打散在10台机器上。写入性能提高了10倍,Shard Group就是指这10台机器组成的shard。
- 当然由于有数据冗余的存在,如设置用户数据需要写入2份,那么实际上10台机器写入性能提高5倍。
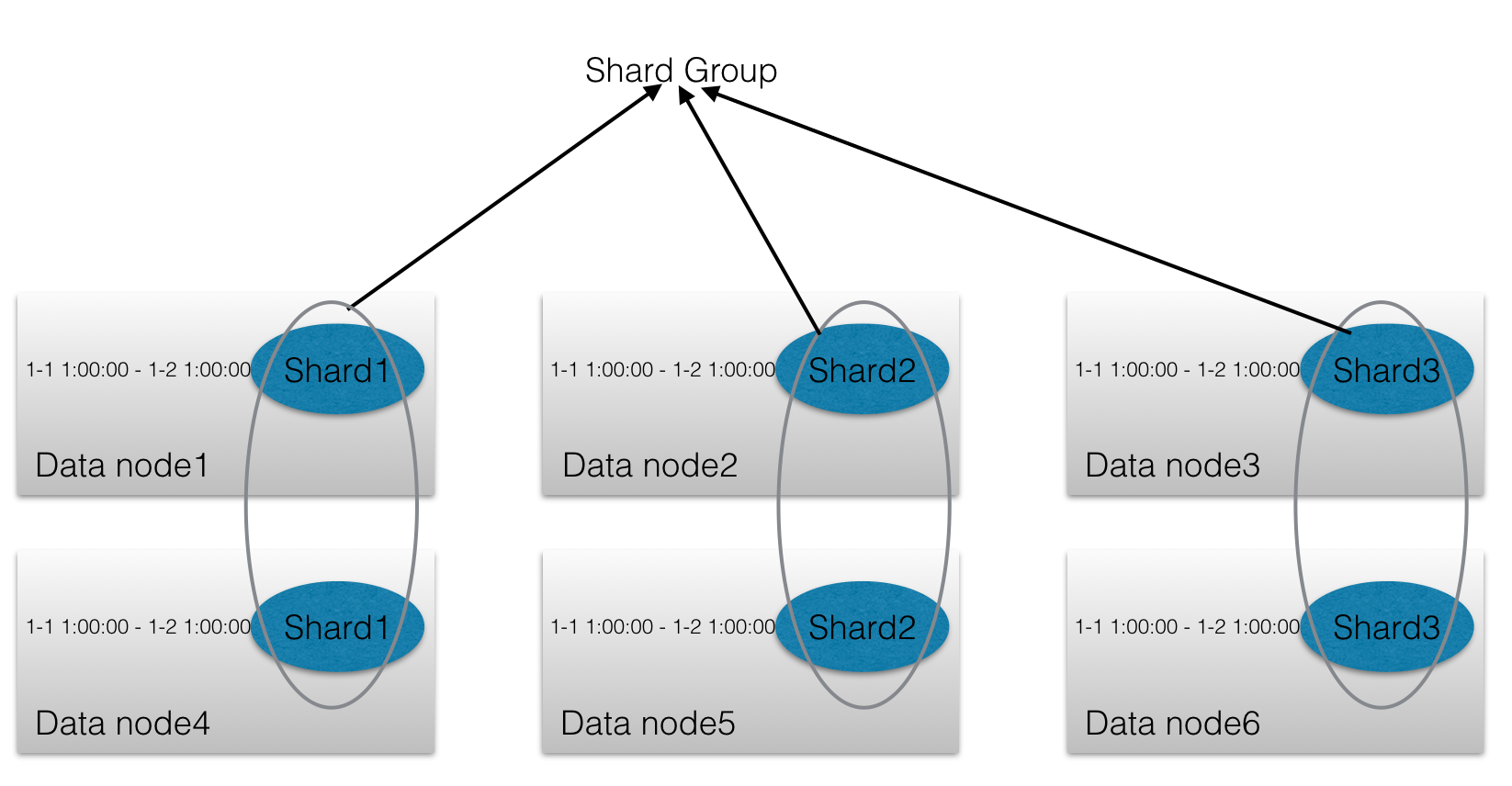
type ShardGroupInfo struct {
ID uint64
StartTime time.Time
EndTime time.Time
DeletedAt time.Time
Shards []ShardInfo
}
一个Shard Group映射多个ShardInfo。并且Shard Group有StartTime, EndTime等属性。
type ShardInfo struct {
ID uint64
Owners []ShardOwner
}
每个ShardInfo属于多个ShardOwner,如用户设置数据需要写入2份,那么每个ShardInfo既对应存在两个ShardOwner (data nodes)。
Steps:
- 根据写入point的timestamp, 获取写入的数据属于哪个shard group。如果shard group信息在data node中不存在,调用metadata service获取。
- cluster metadata service会负责规划这些数据分配到哪些节点上。shard groups一般会在写入请求到来之前提前创建,防止批量请求的数据量过大冲击到cluster metadata service。
- measurement name和tagset相加进行hash并且根据shard group中ShardInfo的数量进行取余,那么最近的一些时序数据就会平均写入到每一台服务器上,分散写入压力。注意此时的hash算法不是一致性hash, 原因是
- 写入:集群规模resize后我们并不需要考虑将老的shard group重新hash, 因为此时老的shard group已经没有了写入,这样就不需要再对写入请求重新负载均衡。
- 对于老的数据读能力的横向扩展比较简单,仅仅需要将写入shards拷贝到集群中其他的data node上。
Write Points to Shard
write定位到对应server的shard后,开始写入到shard流程,如下图所示
- 根据shard group流程计算出requests写入3副本,且对应的shard存储的机器为2,3,4
- Http write request 发送到了server 1,server 1会将请求路由到2,3,4,并且根据下述的写入级别判断是否应该返回给client此次写入成功。
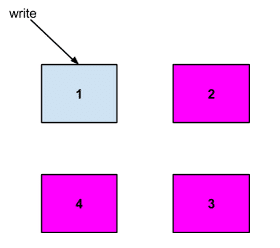
每个写入需要设置一致性级别 (consistency level)
- Any - 任何一台 server 接收到了写入请求,虽然写入失败,但是只要写入到 hinted handoff,此时就算成功。hinted handoff模块后续会详做介绍,这里可以理解为写入失败,但是写入到了一个失败队列文件中,这个失败队列会不断的重试这个请求,但是实际上也并不保证这个写入一定成功。
- one - 任何一台server写入成功
- quorun - 多数派写入成功
- all - 所有写入成功
值得注意的是:
- 按照这种写入设计,不能保证一个shard对应的server 2,3,4,其中任何一台server上的数据是全量最新的。不过本文最开头也描述了influxdb cluster设计哲学,时序数据的场景,成功写入和查询数据比强一致性更加重要。
- 如果client写入失败,实际上部分主机上的写入可能是成功的,由于hinted handoff的存在,理论上写入最终是会成功写入的。这种行为也是符合本文开头的设计:时序数据的场景数据一旦生成是不会变化,既如果client发现写入失败重试对于server中存储的数据仅仅也是出现两份同样的数据,后续做一次compaction就可以了。
Hinted Handoff
下面我们详细描述下Hinted Handoff的工作机制。
Hinted handoff 帮忙我们快速恢复这些短时间内的写入失败,如server 重启或者由于gc 中断, 高查询导致系统负载过高而导致server的临时不可用。
在我们先前示例中,当写入到达server 1后, 会尝试写入到server 2, 3, 4. 当写入4失败时,server 1的hinted handoff会不断尝试将失败的数据写入到server 4中。
hinted handoff的实现机制:
- hinted handoff实际后端存储为 cluster中所有其他的data node分别存储很多的queue files.
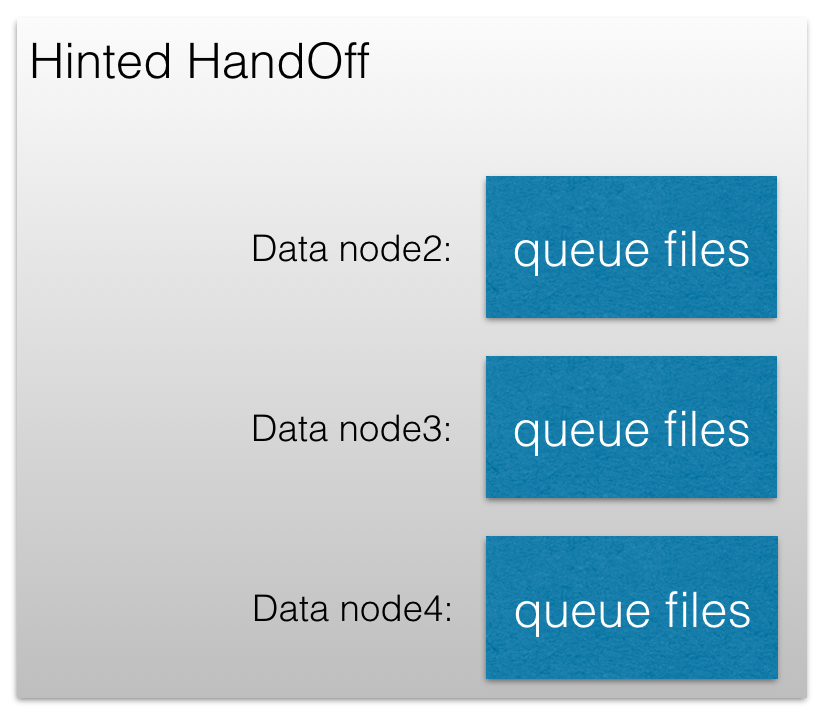
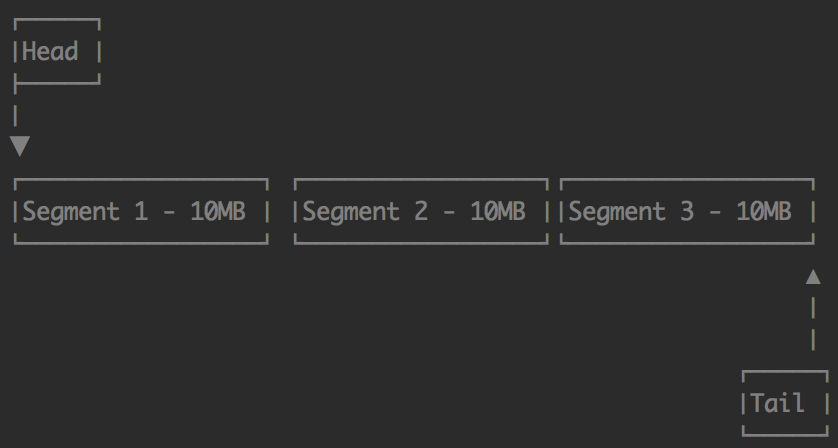
- Queue files默认10MB一个,分成很多的Segment,方便清理过期数据。
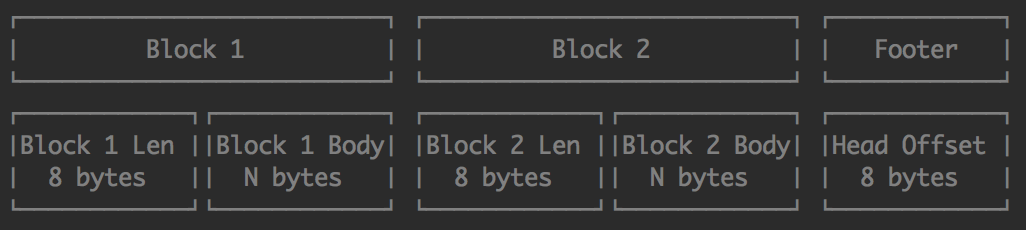
- 每个queue file格式如下,每个Block对应写入失败的points,Footer存储当前读取的offset point,所以每次写入时会重新写这个offset, 且读写文件不能同时进行。
- 看看hinted handoff提供的配置项功能,默认hinted handoff是有最大大小和最大存活时间的限制,所以理论上还是会存在数据丢失的可能。Blog中声称会提供anti-entropy的一个模块来保证数据的最终一致性,但是在0.11版本开源的cluster代码并没有看到这个模块。
type Config struct {
Dir string `toml:"dir"`
MaxSize int64 `toml:"max-size"` // 默认一个队列最大大小为1G
MaxAge toml.Duration `toml:"max-age"` // 默认Age为7天
RetryRateLimit int64 `toml:"retry-rate-limit"` // 重试的频率,单位为bytes per second. 默认不限制
RetryInterval toml.Duration `toml:"retry-interval"` // 重试失败的时间间隔,按照指数级增长直到达到最大重试间隔。默认1秒
RetryMaxInterval toml.Duration `toml:"retry-max-interval"` // 重试最大间隔,默认1分钟
PurgeInterval toml.Duration `toml:"purge-interval"` // 清理间隔,既将由于过期,或者不活跃的节点的数据做清理,默认1小时
}
Anti-Entropy Repair
Anti-entropy repaire确保我们能够达到我们数据的最终一致性。集群中的servers 会定期的交换信息确保他们拥有同样的数据。
- Anti-entropy repaire使用Merkil Tree来对每个shard中数据进行比较,并取两个比较数据之间差异的并集。
- Anti-entropy还能够将shard数据迁移到目标的data node中。
这么设计的原因,如官方在开头中对时序数据使用场景的假设:
- 所有的数据写入都是针对最近的时间。所以老的shard不应该会有频繁的数据的变更。
非常遗憾的是,0.11版本的cluster源代码并没有实现Anti-Entropy Repair的功能。具体实现细节不做介绍。
Conflict Resolution
当存在update同一条数据的场景时,就会出现冲突的情况。influxdb cluster解决冲突的办法非常简单:the greater value wins。这种方案使得解决冲突的代价非常低,但是实际上也带来了一些问题。
如:
- 当一条update请求到server 1,需要更新server 1, 2, 3三副本中的数据。此时update 在server 3上执行失败了,那么数据在server 3上实际上仍然为老数据。
- 后续当对同一条记录执行update操作时,此时三副本的server执行全部成功,此时server1, 2, 3上面 的数据全部被update成功。
- 第一条update记录在server 3上通过hinted handoff模块写入成功。此时server 1,2,3上面的数据将会不一致。最终通过Anti-Entropy Repair模块将数据做最终校验,按照文中描述可能会取两次update更大的值。实际上update操作的结果是不可预期的。
influxdb cluster的设计基本不过多考虑这种时序数据中少见的delete和update操作。但是将update/deletec操作的一致性级别设置为ALL保证delete和update成功是减少上述问题发生概率的方法(即使设置成ALL,如果一旦delete失败也是有不符合预期的情况存在),但是设置为ALL后服务的高可用性会有一定的影响。
Design Conclusion
官方对influxdb cluster的设计概述:
influxdb cluster的设计既不是纯粹的CP或存粹的AP系统,cluster一部分是CP系统,但是数据保证了最终一致性。一部分是AP系统,如果出现较长时间meta nodes和data nodes之间的分区,可用性是不能保证的。上述设计历经influxDB cluster的三次迭代,根据实际的需求做了很多的trade-offs,设计更多的倾向cluster需要实现的最重要的目标: 数据可以水平扩展和写入更低的开销。
总结
虽然非常遗憾cluster后续版本没有开源,但是influxdb cluster总体设计已经非常完善,并且开源出来的0.11版本也是非常具有参考价值。
目前开源的Influxdb cluster 0.11 版本缺乏能力包括:
- 宕机迁移功能,如果data nodes存在主机宕机且无法恢复,那么这台主机上存量的shards需要迁移到其他的机器上。
- 运维管理功能,比如meta nodes主机如何替换上线另外一台meta nodes等。 如官方收费版提供的功能: https://docs.influxdata.com/enterprise_influxdb/v1.3/features/cluster-commands/
如果能够补齐以下两块能力,你觉得使用influxdb cluster符合你的业务场景么?你会用么?