PgSQL · 内核优化 · Hybrid DB for PG 赋能向量化执行和查询子树封装
Author: 雅悯
背景
Hybrid DB for postgresql简介:
随着大数据时代的不断演进, 用户对于数据的分析能力的需要提出了越来越高的要求。 Hybrid DB for postgres(本文后续将会使用HDBP来代表)是一款基于Greenplum开源项目的分析型数据库。 为阿里云用户提供数据分析计算服务,HDBP数据库继承开源Greenplum的处理复杂SQL查询的支持能力,同时HDBP又是一款由阿里云技术团队支持的分析类型数据库产品,阿里云技术团队会不断的在HDBP的各个方面进行持续维护与增强。
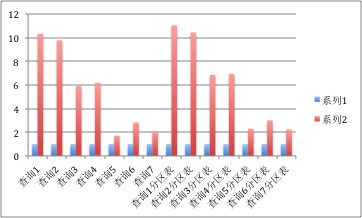
本文将主要介绍HDBP在查询性能提升方面对数据库内核的赋能,使得HDBP查询执行引擎能够比开源Greenplum执行效率高出2-10+倍。 并且HDBP还在持续提升执行引擎的效率。 下图为我们本次性能优化的测试结果:蓝色柱代表优化前的查询执行时间这里用1作为一个比较基线, 红色柱代表优化后查询性能提升的倍数。后续测试部分会详细测试说明。
本项目优化理论依据:
首先我们将会介绍一下本次性能优化项目的理论依据,HDBP性能优化项目主要是基于以下两个主要的研究结论展开:
向量化执行能力
通过研究我们发现Greenplum虽然提供了列存储的能力,但是实现没有向量化执行引擎提供向量化处理能力,在处理列存表的时候,是分别读取一条Tuple的各个字段内容,拼装完成后返回,后续的执行过程还是行存执行引擎完成。向量化执行能够带来的性能上面的提升就无法获得了。 在本次HDBP数据库内核优化项目中我们引入了一种灵活的向量化处理模型,使得HDBP执行引擎可以在一条查询中灵活的在行存处理模式和向量化处理模式两种执行方式中切换。 后续我们将会给大家介绍这块的设计与实现。
查询子树的封装执行
通过分析发现查询计划树中某些部分,是需要执行完成以后然后才能够继续后续的执行,在分析型数据库当中,往往这部分查询子树往往也是整个查询中耗时比较多的部分,由于这部分查询子树的执行相对独立,给我们提供了封装这部分子树的可能性,进过优化处理,最终获得这部分子树最大的执行效率。
我们的设计目标:
- 用户无感知(即用户查询无需做任何修改);
- 性能提升收益最大化;
- 架构灵活;
- 能够快速上线。 基于上述目标我们在设计的性能优化框架的时候就首先致力于一个灵活且能够满足互联网快速迭代的执行引擎框架的设计与实现。
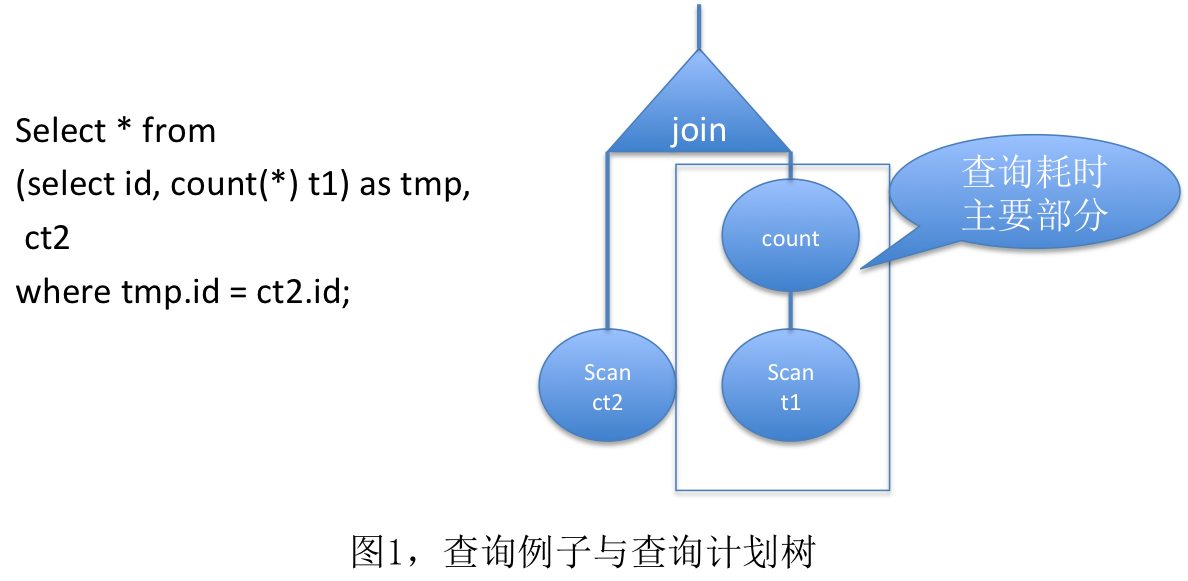
如图1,给我们展示的是一查询和它对应的查询计划树, 其中方框所包含的部分就是查询子树部分。 我们首先将这部分时间减少到最低,理论上就能够提升整个查询执行效率的效果。
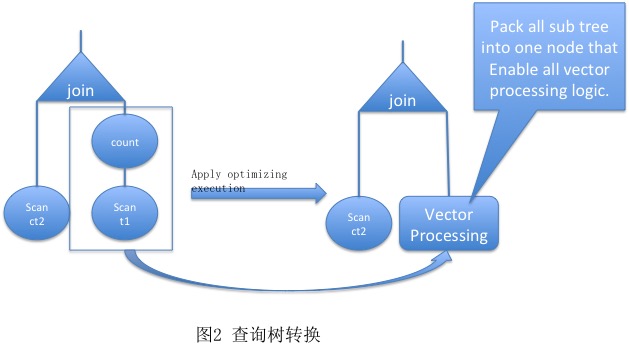
通过图2,所示,我们将查询子树封装到我们性能优化处理框架当中,并且在性能优化处理框架中我们实现了向量化处理能力。这样我们就能够达到对用户无感知的性能加速的效果。并且这样的实现使得我们后续的查询执行优化及功能快速上线这两个方面都有了非常大的灵活度。 通过前面的描述,HDBP性能优化项目会主要会构建一个新的向量化执行引擎框架,在这个框架中我们会将查询子树封装进去,在框架中对这个查询子树的执行过程进行优化处理,最终达到查询子树执行性能的提升。
当前项目状况:
- 当前阿里云已经架构起来了优化执行引擎的框架代码基础框架建设。 为后续直接在这个框架上进行快速迭代开发,实现更多的优化能力提供了架构基础。
- 向量化执行能力的提供,使得向量化处理的收益可以不断的收获。
- 聚合函数优化执行的代码,这部分功能已经上线,并且已经在客户那边进行了实际场景的测试, 经过验证能够达到实验室测试同样的提升效果。
测试效果:
我们在用tpch10G数据结果集,在一台机器上部署了一个3节点测试环境测试进行如下查询的测试:
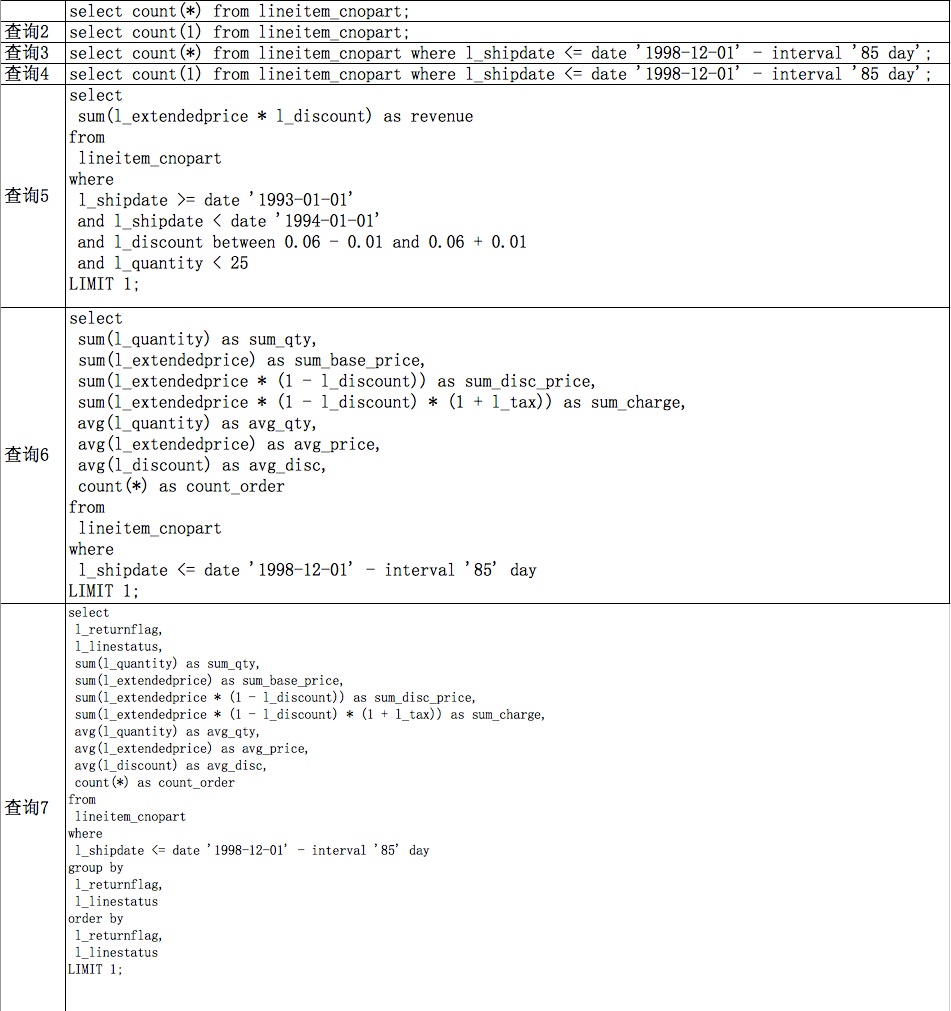

从测试结果来看,我们的优化项目框架还是起到了很好的性能加速效果。通过性能测试我们还发现了几个性能优化点:
- 列存扫描效率,向量化数据准备过程,这部分还有很大的提升空间;
- 表达式计算效率提升,查询5由于过滤算子比较多, 表达式目前向量化计算效率还有优化空间;
- hash Agg计算Hash值效率,计算Hash值部分可以继续优化;
结语:
上述性能优化框架是突破了开源Greenplum局限,虽然目前它只实现了聚集函数的加速,但是对它的成功探索过程中,也让我们看到了执行引擎优化的更多可以尝试的方面,更加广阔的优化空间。后续我们会不断突破局限,让HDBP给用户带来更多的计算价值。