MongoDB · myrocks · mongorocks 引擎原理解析
Author: linqing
mongorocks 是基于著名的开源KV数据库RocksDB实现的一个MongoDB存储引擎,借助rocksdb的优秀特性,mongorocks能很好的支持一些高并发随机写入、读取的应用场景。
MongoDB 与 mongorocks 的关系

mongodb 支持多种引擎,目前官方已经支持了mmapv1、wiredtiger、in-Memory等,而mongorocks则是第三方实现的存储引擎之一(对应上图红框的位置)。
MongoDB KV存储引擎模型
MongoDB 从 3.0 版本 开始,引入了存储引擎的概念,并开放了 StorageEngine 的API 接口,为了方便KV存储引擎接入作为 MongoDB 的存储引擎,MongoDB 又封装出一个 KVEngine 的API接口,比如官方的 wiredtiger 存储引擎就是实现了 KVEngine 的接口,本文介绍的 mongorocks 也是实现了KVEngine的接口。
KVEngine 主要需要支持如下接口
创建/删除集合
MongoDB 使用 KVEngine 时,将所有集合的元数据会存储到一个特殊的 _mdb_catalog 的集合里,创建、删除集合时,其实就是往这个特殊集合里添加、删除元数据。
_mdb_catalog 特殊的集合不需要支持索引,只需要能遍历读取集合数据即可,MongoDB在启动时,会遍历该集合,来加载所有集合的元数据信息。
数据存储及索引
插入新文档时,MongoDB 会调用底层KV引擎存储文档内容,并生成一个 RecordId 的作为文档的位置信息标识,通过 RecordId 就能在底层KV引擎读取到文档的内容。
如果插入的集合包含索引(MongoDB的集合默认会有_id索引),针对每项索引,还会往底层KV引擎插入一个新的 key-value,key 是索引的字段内容,value 为插入文档时生成的 RecordId,这样就能快速根据索引找到文档的位置信息。
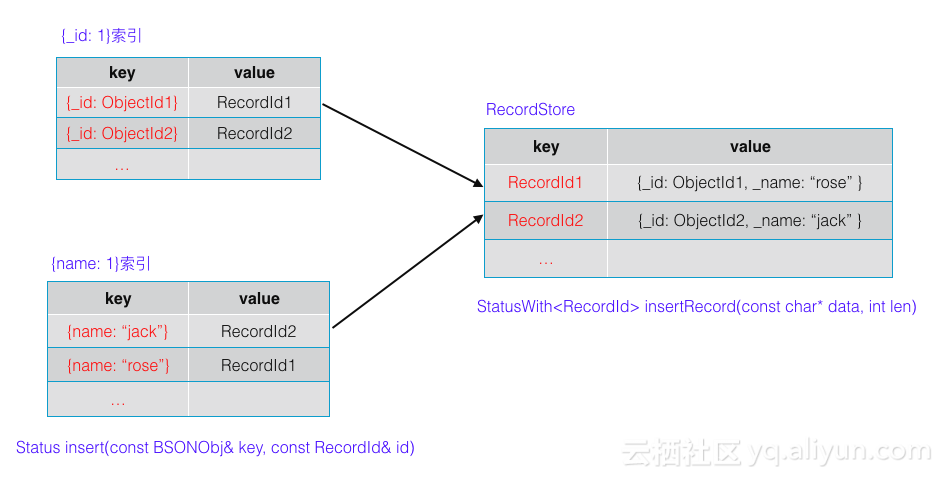
如上图所示,集合包含{_id: 1}, {name: 1} 2个索引
- 用户插入文档时,底层引擎将文档内容存储,返回对应的位置信息,即 RecordId1
- 集合包含2个索引
- 插入 {_id: ObjectId1} ==> RecordId1 的索引
- 插入 {name: “rose”} ==> RecordId1 的索引
有了上述的数据,在根据_id访问时文档时 (根据其他索引字段类似)
- 根据文档的 _id 字段从底层KV引擎读取 RecordId
- 根据 RecordId 从底层KV引擎读取文档内容
mongorock 存储管理
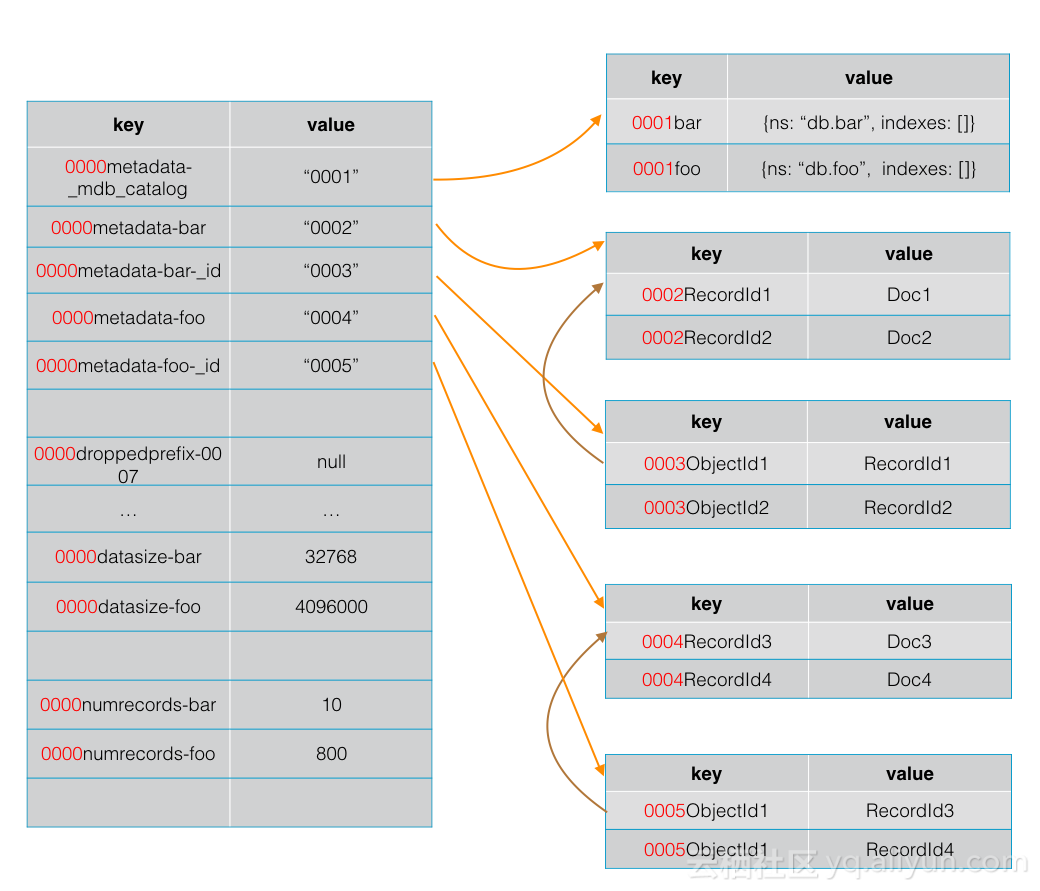
mongorocks 存储数据时,每个key都会包含一个32位整型前缀,实际存储时将整型转换为big endian格式存储。
- 所有的元数据的前缀都是
0000 - 每个集合、以及集合的每个索引都包含不同的前缀,集合及索引与前缀的关系存储在
0000metadata-*为前缀的key里 _mdb_catalog在mongorocks也是一个普通的集合,有单独的前缀
创建集合、写数据
- 创建集合或索引时,mongrocks会为其分配一个前缀,并将对应关系持久化,比如创建集合 bar(默认会创建_id字段的索引),mongorocks 会给集合和索引各分配一个前缀,如上图所示的
0002,0003,并将对应关系持久化。 - 接下来往bar集合里写的所有数据,都会带上
0002前缀; - 往其_id索引里写的数据都会带上前缀
0003;
写索引时,有个比较有意思的设计,重点介绍下 (其他的key-value引擎,如wiredtiger也使用类似的机制)
MongoDB 支持复合索引,比如db.createIndex({a: 1, b, -1, c, 1}),这个索引要先按a字段升序、a相同的按b字段降序.. 依此类推,但KV引擎并没有这么强大的接口,如何实现对这种复合索引的支持呢?
MongoDB针对每个索引,会有一个位图来描述索引各个字段的排序方向,比如插入如下2条索引时 (key的部分会转换为BSON格式插入到底层)
{a: 100, b: 200, c: 300} == > RecordId1
{a: 100, b: 300, c: 400} ==> RecordId2
插入到底层 RocksDB,第1条记录会排在第2条记录前面,但我们建立的索引是 {a: 1, b, -1, c, 1},按这个索引,第2条记录应该排在前面才对,否则索引顺序就是错误的。
mongorocks 在存储索引数据时,会根据索引的排序位图,如果方向是逆序(如b: -1),会把key的内容里将b字段对应的bit全部取反,这样在 RocksDB 里第2条记录就会排在第1条前面。
读取数据
根据_id来查找集合数据时,其他访问方式类似
- 根据集合的名字,在元数据里找到集合的前缀
0002及其_id索引对应的前缀0003 - 根据
0003 + 文档id生成文档_id索引的key,并根据key读取出文档的RecordId - 根据
0002 + RecordId生成存储文档内容的key,并根据key读取出文档的内容
删除集合
- 将集合的元数据从
_mdb_catalog移除 - 将集合及其索引与前缀的对应关系都删除掉
- 将第2步里删除的前缀加入到待删除列表,并通知 RocksDB 把该前缀开头的所有key通过compact来删除掉(通过定制CompactionFilter来实现,这个compact过程是异步做的,所以集合删了,会看到底层的数据量不会立马降下来),同时持久化一条
0000droppedprefix-被删除前缀的记录,这样是防止compact被删除前缀的过程中宕机,重启后被删除前缀的key不会被会收掉,直到待删除前缀所有的key都被回收时,最终会把0000droppedprefix-被删除前缀的记录删除掉。
文档原子性
MongoDB 写入文档时,包含如下步骤
- 插入文档到集合
- 更新集合所有的索引
- 记录oplog(如果是复制集模式运行)
MongoDB 保证单文档的原子性,上述3个步骤必须全部成功应用或者全部不应用,mongorocks 借助 RocksDB 的 WriteBatch 接口来保证,将上述3个操作放到一个WriteBatch中,最后一次提交,RocksDB 层面会保证 WriteBatch 操作的原子性。
特殊的oplog
在MongoDB里,oplog是一个特殊的 capped collection(可以理解为环形存储区域),超过配置的大小后,会将最老的数据删除掉,如下是2个oplog的例子,mongorocks在存储oplog时,会以oplog集合前缀 + oplog的ts字段作为key来存储,这样在RocksDB,oplog的数据都是按ts字段的顺序来排序的。
0008:ts_to_uint64 ==> { "ts" : Timestamp(1481860966, 1), "t" : NumberLong(71), "h" : NumberLong("-6964295105894894386"), "v" : 2, "op" : "i", "ns" : "test.tt", "o" : { "_id" : ObjectId("58536766d38c0573d2ff5b90"), "x" : 2000 } }
0008:ts_to_uint64 ==> { "ts" : Timestamp(1481860960, 1), "t" : NumberLong(71), "h" : NumberLong("3883981042971627762"), "v" : 2, "op" : "i", "ns" : "test.tt", "o" : { "_id" : ObjectId("58536760d38c0573d2ff5b8f"), "x" : 1000 } }
capped collection 当集合超出capped集合最大值时,就会逐个遍历最先写入的数据来删除,直到空间降到阈值以下。
mongorocks 为了提升回收oplog的效率,做了一个小的优化。
针对oplog集合,插入的每一个文档,除了插入数据本身,还会往一个特殊的集合(该集合的前缀为oplog集合的前缀加1)里插入一个相同的key,value为文档大小。比如
0008:ts_to_uint64 ==> { "ts" : Timestamp(1481860966, 1), "t" : NumberLong(71), "h" : NumberLong("-6964295105894894386"), "v" : 2, "op" : "i", "ns" : "test.tt", "o" : { "_id" : ObjectId("58536766d38c0573d2ff5b90"), "x" : 2000 } }
0009:ts_to_uint64 ==> 88 (假设88为上面这个文档的大小)
有了这个信息,在删除oplog最老的数据时,就可以先遍历包含oplog文档大小信息的集合,获取被删除文档的大小,而不用把整个oplog的key-value都读取出来,然后统计大小。个人觉得这个优化当oplog文档大小比较大效果会比较好,文档小的时候并不一定能有效。
集合大小元数据管理
MongoDB 针对collection的count()接口,如果是全量的count,默认是O(1)的时间复杂度,但结果不保证准确。mongorocks 为了兼容该特性,也将每个集合的『大小及文档数』也单独的存储起来。
比如集合foo的大小、文档数分别对应2个key
0000datasize-foo ==> 14000 (0000是metadata的前缀)
0000numrecords-foo ==> 100
上面2个key,当集合里有增删改查时,默认并不是每次都更新,而是累计到一定的次数或大小时更新,后台也会周期性的去更新所有集合对应的这2个key。
mongorocks 也支持每次操作都将 datasize、numrecords 的更新进行持久化存储,配置storage.rocksdb.crashSafeCounters参数为true即可,但这样会对写入的性能有影响。
数据备份
借助 RocksDB 本身的特性,mongorocks能很方便的支持对数据进行物理备份,执行下面的命令,就会将产生一份快照数据,并将对应的数据集都软链接到/var/lib/mongodb/backup/1下,直接拷贝该目录备份即可。
db.adminCommand({setParameter:1, rocksdbBackup: "/var/lib/mongodb/backup/1"})
总结
总体来说,MongoDB 存储引擎需要的功能,mongorocks 都实现了,但因为 RocksDB 本身的机制,还有一些缺陷,比如
- 集合的数据删除后,存储空间并不是立即回收,RocksDB 要通过后台压缩来逐步回收空间
- mongorcks 对 oplog 空间的删除机制是在用户请求路径里进行的,这样可能导致写入的延迟上升,应像 wiredtiger 这样当 oplog 空间超出时,后台线程来回收。
- RocksDB 缺乏批量日志提交的机制,无法将多次并发的写log进行合并,来提升效率。