MySQL · 社区动态 · Online DDL 工具 gh-ost 支持阿里云 RDS
Author: zhuyan
背景
Online DDL 一直都是 DBA 运维时比较头疼的事,一般都会选择在业务低峰期谨慎的操作,比较常用的几个工具比如 percona pt-online-schema-change , Facebook OSC, 本质上它们都是基于触发器的,简单来讲就是通过数据库的触发器把作用在源表的操作在一个事务内同步到修改后的表中,这在业务高峰期时会极大的加重主库的负载。gh-ost 是由 Github 开发的 Online DDL 工具,使用 binlog 代替触发器来做增量数据同步,这样可以降低主库的负载,异步的执行。为了表彰 Github 在 gh-ost 上的贡献,MySQL 社区把 2017 年的社区贡献奖颁发给了 Github(值得一提的是 2018 年的 MySQl 社区贡献奖颁发给了阿里云数据库团队)。前段时间有用户反映无法在阿里云 RDS 上使用 gh-ost,经过排查和沟通解决方案,最终官方接受了我们提交的代码,增加 --aliyun-rds 参数,用户下载最新的主干代码就可以使用。
gh-ost
基于触发器的 Online DDL 工具
介绍 gh-ost 之前,先来简单了解一下在这之前基于触发器的工具原理。考虑一下 Online DDL 实际上可以粗糙的分成几步:
- 根据原来的表结构执行 alter 语句,新建一个更新表结构之后的表,通常称为幽灵表。对用户不可见。
- 把原来表的已有数据 copy 到幽灵表。
- 在 copy 的过程中,会有新的数据过来,这些数据要同步到幽灵表,也就是 “Online” 的精髓。
- copy 和同步完成后,锁住源表,交换表名,幽灵表替换源表。
- 删除源表(可选),完成 online DDL。
这其中比较重要的第三步,如何同步增量的数据。最开始办法就是使用触发器,在源表上增加几个触发器,例如当源表执行 INSERT,UPDATE,DELETE 语句,就把这些操作通过触发器同步到幽灵表上,这样在幽灵表上执行的语句和源表的语句就属于同一个事务,显然这样会影响主库的性能。
后面出现了异步的模式,使用触发器把对源表的操作保存到一个 Changelog 表中,不真正的去执行,专门有一个后台的线程从 Changelog 表读取数据应用到幽灵表上。这种方式一定程度上缓解了主库的压力,但是保存到 Changelog 表也同样是属于同一个事务中,对性能也有不小的影响。
在 gh-ost 的文档 中细数了触发器的不足之处,大致有以下几点:
- Triggers, overhead: 触发器是用存储过程的实现的,就无法避免存储过程本身需要的开销。
- Triggers, locks: 增大了同一个事务的执行步骤,更多的锁争抢。
- Trigger based migration, no pause: 整个过程无法暂停,假如发现影响主库性能,停止 Online DDL,那么下次就需要从头来过。
- Triggers, multiple migrations: 他们认为多个并行的操作是不安全的。
- Trigger based migration, no reliable production test: 无法在生产环境做测试。
- Trigger based migration, bound to server: 触发器和源操作还是在同一个事务空间。
Triggerless
从上面的描述可以看出,触发器的作用是源表和幽灵表之间的增量数据同步,gh-ost 放弃了触发器,使用 binlog 来同步。gh-ost 作为一个伪装的备库,可以从主库/备库上拉取 binlog,过滤之后重新应用到主库上去,相当于主库上的增量操作通过 binlog 又应用回主库本身,不过是应用在幽灵表上。引用一下官网的图:
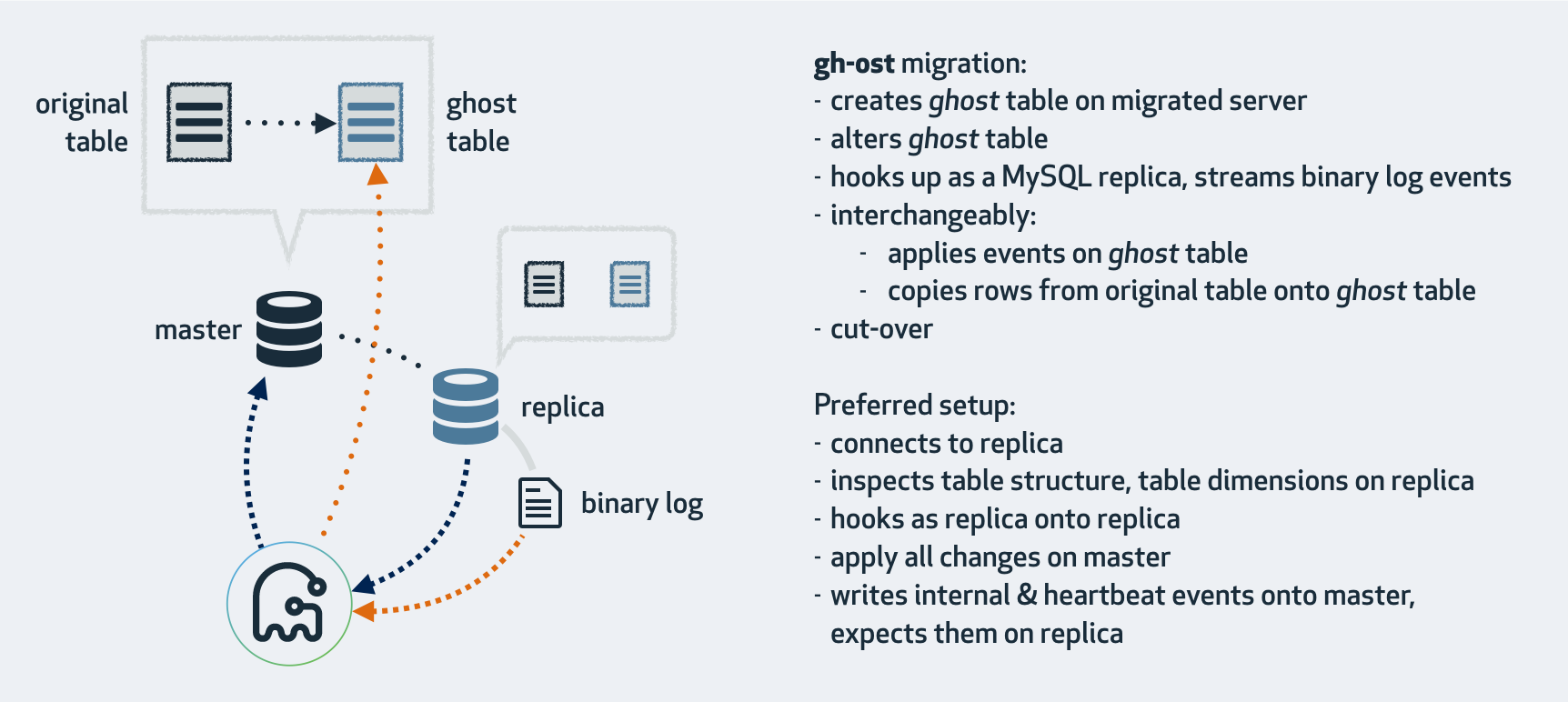
gh-ost 首先连接到主库上,根据 alter 语句创建幽灵表,然后作为一个”备库“连接到其中一个真正的备库上,一边在主库上拷贝已有的数据到幽灵表,一边从备库上拉取增量数据的 binlog,然后不断的把 binlog 应用回主库。图中 cut-over 是最后一步,锁住主库的源表,等待 binlog 应用完毕,然后替换 gh-ost 表为源表。gh-ost 在执行中,会在原本的 binlog event 里面增加以下 hint 和心跳包,用来控制整个流程的进度,检测状态等。这种架构带来诸多好处,例如:
- 整个流程异步执行,对于源表的增量数据操作没有额外的开销,高峰期变更业务对性能影响小。
- 降低写压力,触发器操作都在一个事务内,gh-ost 应用 binlog 是另外一个连接在做。
- 可停止,binlog 有位点记录,如果变更过程发现主库性能受影响,可以立刻停止拉binlog,停止应用 binlog,稳定之后继续应用。
- 可测试,gh-ost 提供了测试功能,可以连接到一个备库上直接做 Online DDL,在备库上观察变更结果是否正确,再对主库操作,心里更有底。
- 并行操作,对于 gh-ost 来说就是多个对主库的连接。
需求和限制
官方文档 对于需求和限制解释的比较全面了,这里主要根据云数据库场景简单介绍下。
- 用户没有 Super 权限,因此使用过程中要加上 –assume-rbr, gh-ost 会认为 binlog 本身就是 row 模式,不会再去修改。阿里云 RDS 上的 binlog 默认也是 row 模式,所以不存在问题。
- 其它权限,主要是 REPLICATION SLAVE,REPLICATION CLIENT 可以拉取 binlog ,也可以获得。
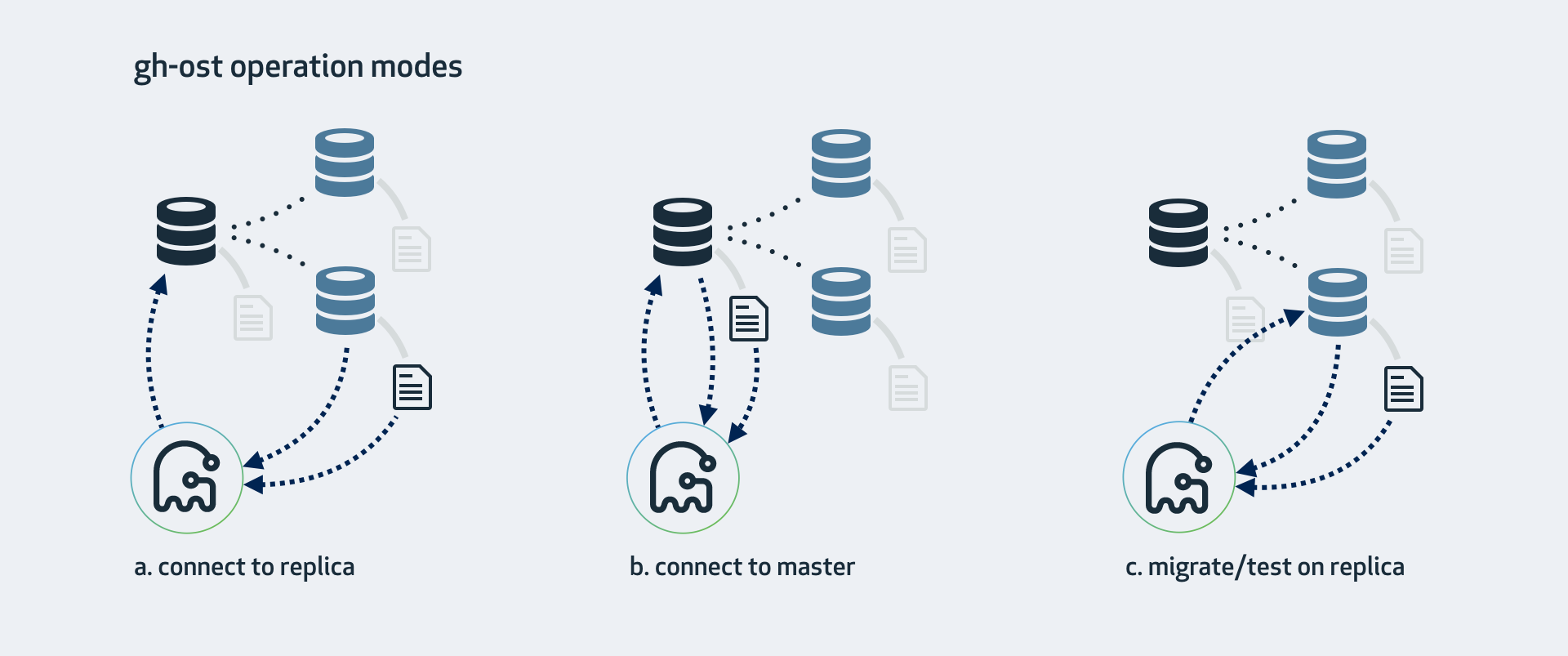
- 无法连接到备库拉取 binlog。备库通常对用户来说是透明的,所以 gh-ost 需要直接连接到主库上去,这可能会增大对主库的负载。使用的时候需要增加 –allow-on-master, –assume-master-host。官方推荐的方式也是连接到其中一个备库,因为会有一些压力较大的 SELECT 操作,放在备库是最好的。几种连接模式如下图所示:
aliyun-rds 参数
当有用户反馈无法在阿里云 RDS 上使用 gh-ost 的时候,我们着手进行了排查,发现在 Github 上已经有热心的用户 dikang123, exherb 在 issue #470 中进行了讨论,原因是在校验阶段隐藏了两个参数,@@port 和 @@hostname,导致 gh-ost 获得了非法的字符。隐藏的原因是系统架构和安全的考虑,避免用户的端口和主机被恶意攻击。返回非法字符也是出于用户体验,例如 port 本应该是整型,如果返回 0,那么可能会有用户认为自己的数据库端口是 0,但是返回 ‘NULL’,用户就可以接收到明确的隐藏信号。
我们随后向官方提交了 Pull Request 从工具本身解决,经过多次交流和代码 review,决定增加一个参数 –aliyun-rds,这样就可以绕开非法字符的校验。具体的过程可以看下 Pull Request 541 。
目前用户使用的话,记得加上以下几个参数:
- –allow-on-master
- –assume-rbr
- –assume-master-host
- –aliyun-rds
总结
gh-ost 在 Online DDL 上确实做出了很大的创新,是一款优秀的工具,并且在很多地方的都有巧妙的设计,例如最后一步 cut-over, cut-over-example,本文并未详细描述。对于在云数据库上的使用,还有一些额外的限制,未来根据用户的需求,可以和数据库层面做更多的融合。