MySQL · 最佳实践 · 难以置信,MySQL也可以无损自由切换
Author: zhilin
MySQL通常在人们眼中就是一个低端、开源、大众化的数据库产品,它的稳定性和可用性一直被人们所置疑,被认为难登大雅之堂,只适用于互联网应用,难于应用到可用性高的场景中,比如金融、证券等行业。然而时代的变化太快,MySQL也不能再以过去的眼光来看,从MySQL金融版的诞生开始,它已经不再是那个扶不起的阿斗,它已经脱胎换骨,以一个崭新的形象出现在数据库的高端产品中。
这一切真的难以置信,在开源数据库产品中,MySQL从来都是一枝独秀,但在表面风光的同时,却是DBA和资深用户的满心苦涩。由于硬件、网络的可用性还难以达到理想的要求,无论出现任何故障,数据库系统都必须保证其可用性。对于MySQL来说,大家所熟知的主备集群是最常见的解决方案。由于MySQL的架构设计原因,主备集群的解决方案虽然不完美,但也是其最好的解决方案了。但其中存在的可用性隐患,却是DBA和资深用户的内心无奈。
MySQL的主备集群方案,对于大多数应用系统可以满足基本的可用性要求了,如果要求更高的话,只能去选择商业数据库,而商业数据库的成本却又难以承受。到底存在什么问题呢?
熟悉MySQL的都知道,MySQL是采用binlog来搭建主备集群的,主机上的事务提交时,通过两阶段事务将binlog写入到磁盘,然后再将其发送给备机,备机收到后重放日志,以完成事务与主机的同步。如下图所示

显而易见,主备之间会存在一些延迟,当主机已经将事务提交后,备机也许还没有收到这条事务的binlog,此时在备机上这条事务其实的缺失的。为了尽可能降低主备延迟,后来MySQL又设计了Semi-Sync,如下图所示:
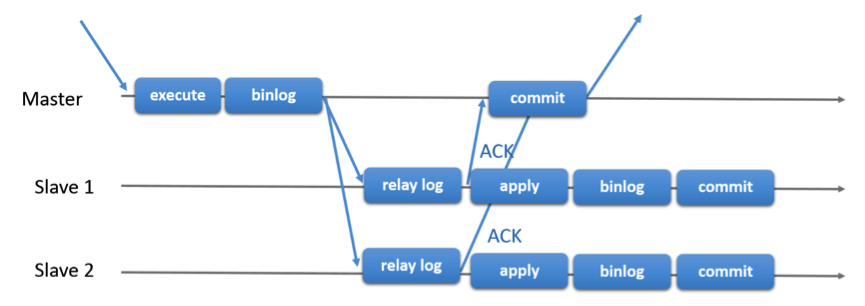
在Master提交之前,必须保证备机已经收到binlog,并记录到本机的relay log中。这样在主机上提交的事务就一定会在备机上提交,只是可能会有些许延迟,如果应用容忍这些延迟的话,那么一切就很完美了。
但这个看起来很完美的解决方案,在真正故障发生时,却不一定那么完美,只是隐藏的很深。
即使使用semi-sync的同步解决方案,当主机发生故障后,系统需要切换到备机,将备机变成主机来继续提供数据库服务。如果原来的主机故障可以修复,可以做为备机,这一切看起来没有什么问题。但如果对MySQL有更深入研究的话,就会发现其实还有隐藏的更深的隐患。
MySQL的事务处理采用两阶段提交机制,以保证事务的可靠性。当事务准备提交时,首先将事务写入binlog,然后再在存储引擎层提交事务,比如InnoDB存储引擎。正常情况下一切都没有问题,但当系统意外down机,重新启动时,MySQL首先会进入故障恢复阶段,读取redo日志,做事务恢复,但可能会发现部分事务并没有提交,那么这部分事务是应该回滚吗?MySQL的实现方法是先将这部分事务挂起,暂时既不提交也不回滚,然后读取binlog日志,如果在binlog中发现有此事务的记录,就将事务提交,若未发现此事务的记录,就将事务回滚。
现在我们再回过头来看之前的故障切换问题。若主机上有事务准备提交,然后事务记入binlog,但在传送给备机之前主机崩溃了,那么备机是没有这些事务的,然后备机就切换成了主机。当原主机重新启动后,通过之前所述的故障恢复过程,这些事务已经记录到binlog,那么应该提交。问题出现了,新的主机和即将成为备机的原主机数据不一致了。有些事务在新主机上没有,但在原主机上已经提交。
举个例子,用户在原主机上插入10条数据,但在新主机上没有发现,因此重新插入,但在原主机成为备机后,却又接收到从主机传来的插入10条数据的binlog,此时何去何从?该不该插入呢?
从理论上来讲,原主机上的事务虽然已经记录到binlog,但其实尚未在存储引擎层提交,也没有返回给应用系统事务提交成功的信息,用户是不知道此条事务成功还是失败,当然多数情况下可能认为此条事务是执行失败的。如果要确切的知道这条事务的状态,必须在数据库中查询一下,是否已执行成功。这在任何数据库系统中都是这样的。比如你执行一个事务,数据库已经执行成功,日志也已经记录,但在返回数据时,网络出现故障,应用系统是无法得知此事务是成功还是失败,但数据库系统中其实是已经提交成功的。
为了解决MySQL更高可用性的问题,我们重新设计了MySQL的复制解决方案,汲取最新分布式理论成果,采用多副本投票选主及分布式故障恢复的机制来提高MySQL的可用性,从而达到RPO为0的目标,重磅发布了MySQL金融版。同时3节点可以容忍1个节点故障,5节点可以容忍2个节点故障。相比传统的主备集群为什么会有这么神奇的改变呢,下面我们对新的架构做详细的阐述,尤其在改进可用性方面做的创新。
新的金融版架构要求至少有3个节点,可以由3个及3个以上节点组成高可用集群。为简单起见,我们以3个节点为例,下图是一个简单的3节点金融版架构示意图:
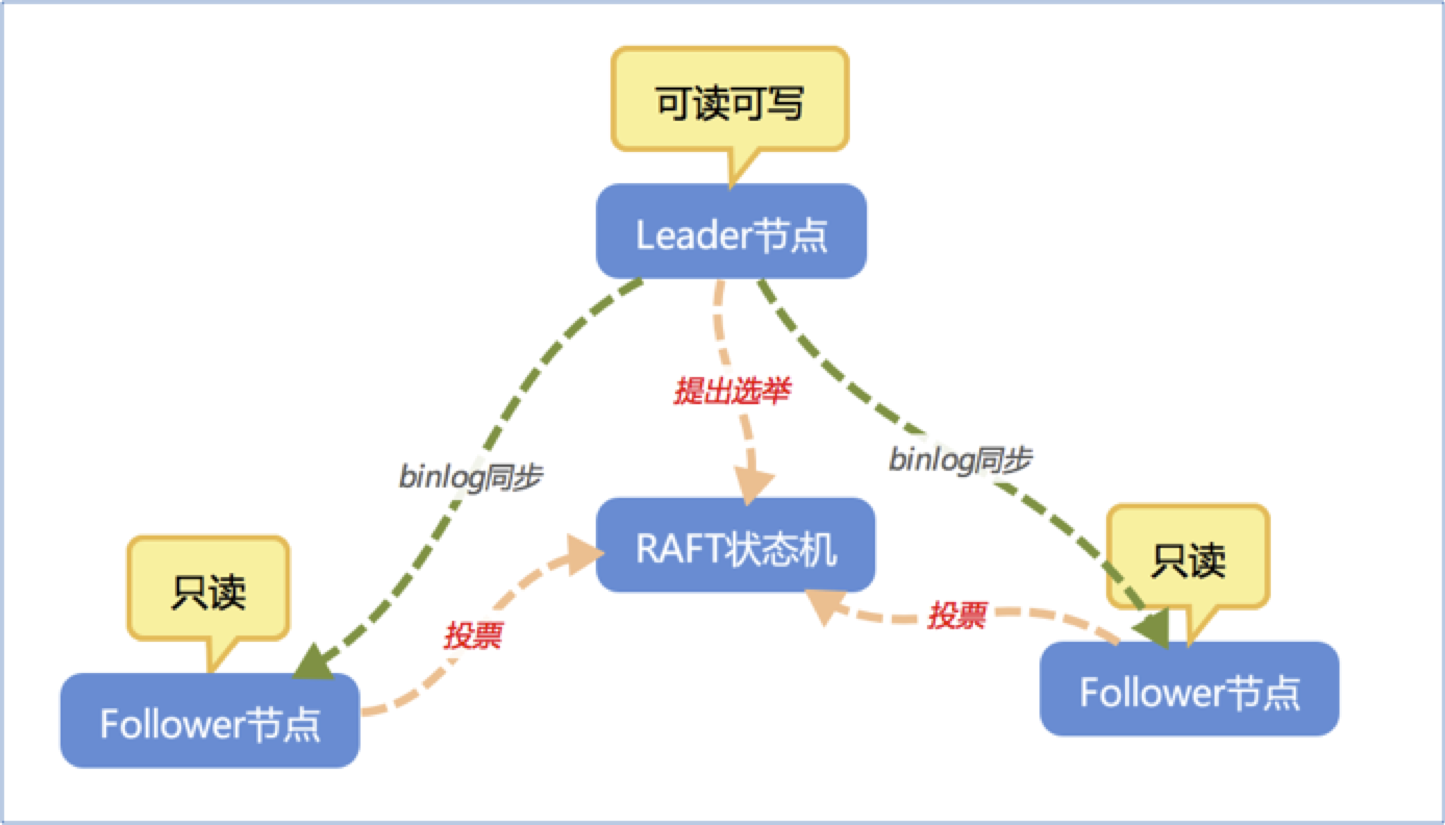
其中Leader节点等同于传统主备集群中的master节点,而follower节点等同于slave节点。在MySQL金融版集群架构中,系统会自动选举一个节点做为主节点,而其它2个节点自动成为备节点。主节点可以接受客户的读写事务,而备节点只能接受客户的读事务,读写事务的分离可以通过proxy来自动完成。
当事务在主节点即leader节点上准备提交时,必须先写到本机的binlog中,并且传送给2个follower节点,当至少一个follower节点回复收到后,leader节点方可在存储引擎层提交事务,然后返回给用户事务执行成功。这样就保证当事务提交后,肯定在其中一个follower上已经接收到此事务的binlog,可以重放binlog,实现与leader的事务同步。
从这里来看,貌似和主备集群没有什么太大区别,其实区别主要在故障发生后的处理过程中。前文已经分析过主备集群在故障切换时可能存在的问题,那么对于MySQL金融版来说,首先就要解决故障切换后可能存在的数据不一致问题。
当3节点集群中有1个节点故障后,这里与2节点的主备集群也有很大区别,2节点集群是不可能自己检测出来某些故障的,比如主备间的网络中断,它无法正确识别出是网络中断,还是主机down机,自然也无法做出正确的决择。因此2节点主备集群的切换都依赖于第3方管理监控软件来识别故障和发起主备切换。与此不同,3节点是可以自己正确识别故障,并进行主动切换,原因在于,故障需要多数派确认,然后再进行相应的切换操作。
当leader发生故障后,其它2个节点很快就能发现leader失去联系,然后会自发的进入选举leader阶段,与常规主备切换不同的是,3节点的主备切换多了一个leader选举过程,因为有2个备库,所以必须就哪个备库切为主库达成一致,防止多主的出现。
新主选择的最重要的条件之一就是其拥有更多的binlog,系统总是选择拥有更多binlog的备库做为新的主库,这也防止新的主库上会有缺失的事务。
如果原主上有更多的binlog该怎么办?这也是之前分析的主备集群难以解决的问题。其实在3节点集群中,这个问题也同样可能发生,只是3节点很好的解决了这个问题。如前所述,当主库准备提交事务之后,先将事务写入本机binlog,然后在将其传送给备库之前,此时主库故障或网络故障,主库上就会有更多的binlog。
我们注意到,此时这些事务并未在存储引擎层提交,也尚未返回给客户事务成功或失败的消息。那么当新leader,即新主选举出来之后,新主上没有这些事务也是正常的,客户可以重做或取消这个事务,但原主库的故障恢复后必须保证和新主库相同的状态,即事务一致性,以保证主备的数据一致性。因此在原主库/网络的故障消除后,重新加入集群时,首先就要防止事务的不一致。
我们在新架构的故障处理中引入分布式故障处理机制,在原主库加入集群对外服务之前,回滚那些未传送到其它节点的事务,从而确保其恢复到与新主库被选举出来的那个时刻。新主库被选举出来的时刻就是一个同步点,每个节点都将恢复或同步到那个同步点。新主从同步点开始之后就可以接收客户的事务,并将其同步给新的备库,当然也包括重新加入集群的原主库,只是其角色变成了备库。
如下图所示:

另外,若是为了提升数据库的吞吐能力,用户通常会增加只读节点,那么同样的场景,若主库的部分事务写入本机的binlog,但尚未同步到备库,更糟糕的是,这些事务已经同步到只读节点,此时若发生了主库down机,备库切换为主库,悲剧发生了。一是只读库可能会读到脏数据,二是只读库无法建立与新主库的复制关系,因为他们之间的事务不一致。幸运的是,MySQL金融版也完美的解决了这个问题,保证只读节点只能复制并读取被确认提交的事务。
传统的主备集群架构还存在了另一个隐患,通常我们会对主库做备份,在异常情况下或业务扩展迁移时,可能需要恢复到指定时间点,而当主备库切换后,可能会存在无法恢复到正确的时间点。
除此之外,基于新架构的高可用集群还有更高的故障容忍性,并且可以将其中的备机开放出来,提供只读服务,提升系统整体的事务吞吐量。
这样,MySQL以草根的数据库形象,提供了企业级数据库的可用性、可靠性和性能,为各类更高可用性要求的用户提供了一个新的选择,MySQL 金融版,你值的拥有。