MySQL · 特性分析 · 8.0 WriteSet 并行复制
Author: 西加
并行复制的演进
MySQL最早的主备复制只有两个线程,IO 线程负责从主库接收 binlog 日志,并保存在本地的 relaylog 中,SQL线程负责解析和重放 relaylog 中的 event。当主库并行写入压力较大时,备库 IO 线程一般不会产生延迟,因为写 relaylog 是顺序写,但是 SQL 线程重放的速度经常跟不上主库写入的速度,会造成主备延迟。如果延迟过大,relaylog 一直在备库堆积,还可能把磁盘占满。
为了缓解这种问题,很自然的想法是提高 SQL 线程重放的并行度,引入并行复制。
5.6 Schema 级别的并行复制
开启并行复制后,会启动多个 Worker 线程,原有的 SQL 线程变为 Coordinator 线程。
可以并行的事务分发给 Worker 线程执行; 不能并行的事务等待 Worker 线程全部结束后,再由 Coordinator 线程自己执行。
DDL 语句或者是跨 Schema 的语句不能并行执行。
这种并行复制的模式,对于多个 DB 同时更新才能有较高的并行度,但是更常见的情况是更新集中在同个一个 DB。
一个简单的改进,把 Schema 级别的并行复制改成 Table 级别,可以大幅度提高单库多表环境下的并行度。但是对于只有一个热点表的情况依然处理不了。
5.7 基于 Group Commit 的并行复制
Group Commit
引入 Group Commit之前,Binlog 和 InnoDB 日志是内部XA,为了保证 InnoDB 和 Binlog 提交顺序一致,实际是串行提交,执行序列如下:
- InnoDB prepare
- write/sync Binlog
- InnoDB commit
官方的 Group Commit 分为三个阶段,每个阶段有一个线程操作,三个阶段可以并发执行。
- flush stage:binlog 从 cache 写入文件
- sync stage: 对 binlog 做 fsync
- commit stage:引擎层 commit
这样 InnoDB prepare 成功的事务可以进入队列,每个阶段可以对队列事务统一做操作,提高了并行度。
写binlog 和 InnoDB commit 都是按照队列中的顺序,可以保证 binlog 和事务提交顺序一致。
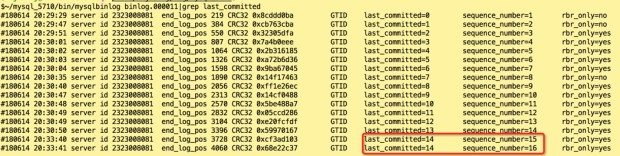
binlog 中记录了 sequence_number 和 last_commited,如上图,mysqlbinlog 解析日志可以看到这两个值。
sequence_number 是自增事务 ID,last_commited 代表上一个提交的事务 ID。
如果两个事务的 last_commited 相同,说明这两个事务是在同一个 Group 内提交的。
LOGICAL_CLOCK 并行复制
5.7 引入了变量 slave_parallel_type,可选值 DATABASE、LOGICAL_CLOCK,DATABASE 就是和 5.6 中相同,Schema 级别的并行复制,而 LOGICAL_CLOCK 是基于 Group Commit 的并行复制,相比 5.6 极大提高了并行度。
Group Commit 实现了主库事务的并行提交。很显然的,主库能同时进入prepare阶段的事务之间不会冲突,那么这些事务在备库回放时也不会冲突。
Group Commit 中,last_commited 相同的事务,可以在备库并行回放。
class MYSQL_BIN_LOG: public TC_LOG
{
...
public:
/* Committed transactions timestamp */
Logical_clock max_committed_transaction;
/* "Prepared" transactions timestamp */
Logical_clock transaction_counter;
MySQL bin log 里面维护了两个变量
Logical_clock max_committed_transaction:记录上次 Group commit 时最大的 sequence_number,即上述 mysqlbinlog 中的 last_committed
Logical_clock transaction_counter:sequence_number 来源,每次分配 sequence_number 时 transaction_counter 进行递增,即当前最大的 sequence_number
5.7 的并行复制还有一点点弊端,如果如果主库并行度低,那么备库回放时也很难并行。
为此,5.7 引入了两个参数:
- binlog_group_commit_sync_delay:等待延迟提交的时间,binlog提交后等待一段时间再 fsync。让每个 group 的事务更多,人为提高并行度。
- binlog_group_commit_sync_no_delay_count:等待提交的最大事务数,如果等待时间没到,而事务数达到了,就立即 fsync。达到期望的并行度后立即提交,尽量缩小等待延迟。
8.0 基于 WriteSet 的并行复制
5.7 为了提高备库回放的速度,需要在主库尽量提高并行度。
8.0解决了这个问题,即使主库在串行提交的事务,只有互相不冲突,在备库就可以并行回放。
8.0 引入了参数 binlog_transaction_dependency_tracking 来控制事务依赖模式,让备库根据 commit timestamps 或者 write sets 并行回放事务,有三个取值:
- COMMIT_ORDERE:使用 5.7 Group commit 的方式决定事务依赖
- WRITESET:使用 WriteSet 的方式决定判定事务直接的冲突,发现冲突则依赖冲突事务,否则按照 COMMIT_ORDERE 方式决定依赖
- WRITESET_SESSION:在 WRITESET 方式的基础上,保证同一个 session 内的事务不可并行
WRITESET 是一个 hash 数组,大小由参数 binlog_transaction_dependency_history_size 决定。
参数 transaction_write_set_extraction 决定 hash 算法,可选值:OFF、MURMUR32、XXHASH64,默认值 XXHASH64,如果
WriteSet 记录了事务的更新行信息,决定 commit_parent时,使用事务自己的 session WriteSet 和 history WriteSet 进行比对,找到最近的冲突行,设为 commit_parent。如果 WriteSet 找不到 commit_parent,则还是使用 COMMIT_ORDERE 决定 commit_parent
WriteSet 源码分析
写入 session write_set 入口在 rpl_write_set_handler.cc:add_pke() (pke 是 primary key equivalent 的缩写)
add_pke() 在 binlog_write_row() 内部调用,每次插入、更新、删除记录,都会更新 session WriteSet
add_pke() 会记录每一条主键、唯一键、外键信息,并且会记录是否更新了无主键表,或者更新了外键关联的列
WriteSet 中每条记录是一个 uint64 hash,hash字符串由更新行的 index,db,table,value 组成
MySQL_BIN_LOG 里定义的 Transaction_dependency_tracker m_dependency_tracker 是决定事务依赖的入口。
MYSQL_BIN_LOG::write_gtid 入口处决定调用 m_dependency_tracker.get_dependency() 获取事务依赖
class MYSQL_BIN_LOG : public TC_LOG {
public:
/** Manage the MTS dependency tracking */
Transaction_dependency_tracker m_dependency_tracker;
...
}
-----------------------------------------------------------------------
bool MYSQL_BIN_LOG::write_gtid(THD *thd, binlog_cache_data *cache_data,
Binlog_event_writer *writer) {
...
int64 sequence_number, last_committed;
/* Generate logical timestamps for MTS */
m_dependency_tracker.get_dependency(thd, sequence_number, last_committed);
...
}
可以看到,对于三种依赖模式,处理流程是依次递增的。
COMMIT_ORDERE 是 5.7 引入的,这里就不再深入分析。
/**
Get the dependencies in a transaction, the main entry point for the
dependency tracking work.
*/
void Transaction_dependency_tracker::get_dependency(THD *thd,
int64 &sequence_number,
int64 &commit_parent) {
sequence_number = commit_parent = 0;
switch (m_opt_tracking_mode) {
case DEPENDENCY_TRACKING_COMMIT_ORDER:
/* COMMIT_ORDERE 只调用 m_commit_order.get_dependency() */
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
/* WRITESET 在 COMMIT_ORDERE 的基础上再调用 m_writeset.get_dependency() */
m_writeset.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET_SESSION:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
m_writeset.get_dependency(thd, sequence_number, commit_parent);
/* WRITESET_SESSION 在 WRITESET 的基础上再调用 m_writeset_session.get_dependency */
m_writeset_session.get_dependency(thd, sequence_number, commit_parent);
break;
default:
DBUG_ASSERT(0); // blow up on debug
/*
Fallback to commit order on production builds.
*/
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
}
}
/*
WRITESET 模式下获取事务依赖,获取到的 commit_parent 和 writeset_history 有关
writeset_history 增长到 binlog_transaction_dependency_history_size 时会立即清空
*/
void Writeset_trx_dependency_tracker::get_dependency(THD *thd,
int64 &sequence_number,
int64 &commit_parent) {
/* 获取当前的 session write_set */
Rpl_transaction_write_set_ctx *write_set_ctx =
thd->get_transaction()->get_transaction_write_set_ctx();
std::vector<uint64> *writeset = write_set_ctx->get_write_set();
/*
判断是否可以使用 write_set
如下几种情况不可以使用 write_set:
* DDL
* session 的 hash 算法和 history 不同
* 事务更新了被外键关联的字段
*/
bool can_use_writesets =
// empty writeset implies DDL or similar, except if there are missing keys
(writeset->size() != 0 || write_set_ctx->get_has_missing_keys() ||
/*
The empty transactions do not need to clear the writeset history, since
they can be executed in parallel.
*/
is_empty_transaction_in_binlog_cache(thd)) &&
// hashing algorithm for the session must be the same as used by other
// rows in history
(global_system_variables.transaction_write_set_extraction ==
thd->variables.transaction_write_set_extraction) &&
// must not use foreign keys
!write_set_ctx->get_has_related_foreign_keys();
/* write_history 长度是否超过最大值 */
bool exceeds_capacity = false;
if (can_use_writesets) {
/*
Check if adding this transaction exceeds the capacity of the writeset
history. If that happens, m_writeset_history will be cleared only after
using its information for current transaction.
*/
/* 判断 write_history 是否超过最大值 */
exceeds_capacity =
m_writeset_history.size() + writeset->size() > m_opt_max_history_size;
/*
Compute the greatest sequence_number among all conflicts and add the
transaction's row hashes to the history.
*/
/*
遍历 session 的 writeset,查找在 writeset_history 中的冲突行
如果冲突,则更新 last_parent(last_parent 是临时变量,并不是 commit parent
如果没冲突,write_history 没找错最大值,则插入 write_history
*/
int64 last_parent = m_writeset_history_start;
for (std::vector<uint64>::iterator it = writeset->begin();
it != writeset->end(); ++it) {
Writeset_history::iterator hst = m_writeset_history.find(*it);
if (hst != m_writeset_history.end()) {
if (hst->second > last_parent && hst->second < sequence_number)
last_parent = hst->second;
hst->second = sequence_number;
} else {
if (!exceeds_capacity)
m_writeset_history.insert(
std::pair<uint64, int64>(*it, sequence_number));
}
}
/*
如果更新了没有主键的表,则不能更新 commit_parent
但是因为要更新 writeset_history 所以不能直接设置 can_use_writesets
*/
if (!write_set_ctx->get_has_missing_keys()) {
commit_parent = std::min(last_parent, commit_parent);
}
}
/* 如果 writeset_history 已满,或者不可以使用 WriteSet,则清空WriteSet */
if (exceeds_capacity || !can_use_writesets) {
m_writeset_history_start = sequence_number;
m_writeset_history.clear();
}
}
/* WRITESET_SESSION 使用 session parent 更新 commit parent 并记录当前的session parent */
void Writeset_session_trx_dependency_tracker::get_dependency(
THD *thd, int64 &sequence_number, int64 &commit_parent) {
int64 session_parent = thd->rpl_thd_ctx.dependency_tracker_ctx()
.get_last_session_sequence_number();
if (session_parent != 0 && session_parent < sequence_number)
commit_parent = std::max(commit_parent, session_parent);
thd->rpl_thd_ctx.dependency_tracker_ctx().set_last_session_sequence_number(
sequence_number);
}
总结
随着 MySQL 版本迭代,备库回放效率越来越高,为了保证主备同步时效性,可以尽量更新版本 MySQL
同时,为了保证备库回放效率,应该根据业务模型适当设置复制相关参数。
比如 5.7 可以适当调大 binlog_group_commit_sync_delay 以提高主库并行度,同时设置 binlog_group_commit_sync_no_delay_count 在已满足并行度要求时主动提交,尽量减小延迟
在 8.0 中根据数据库配置高低设置 binlog_transaction_dependency_history_size,性能有富余的实例可以适当调大该参数,找到更小的 commit parent,提高备库回放并行度。内存和CPU紧张的实例最好避免在 WriteSet上消耗太多资源。binlog_transaction_dependency_history_size 过大,不光消耗内存,还会降低冲突查询的效率。