MySQL · 引擎特性 · 主库 binlog 概览
Author: zhuyan
前言
接触过 MySQL 的同学对于 binlog 必然不会陌生,为了有一种统一格式的日志来记录 MySQL 中不同存储引擎的数据,在数据库之间实时同步或备份,binlog 便诞生了。本文根据源码梳理一下主库从启动,事务组提交,到 binlog 发送等流程,最后介绍一下在 POLARDB 共享存储的情况下,支持 Binlog 功能需要做哪些事情。
启动
重要参数
打开 binlog 的参数是 log-bin ,log-bin 后面跟的是保存 binlog 的路径,如果不指定就会生成默认值,参数生效需要重启实例。这个启动参数实际上对应了两个全局变量,布尔类型的 log_bin 表示 binlog 是否打开 ,log_bin_basename 表示路径。首先在 my_long_options 定义了 log-bin, value 关联到全局变量 opt_bin_logname 中。
{"log-bin", OPT_BIN_LOG,
"Log update queries in binary format. Optional (but strongly recommended "
"to avoid replication problems if server's hostname changes) argument "
"should be the chosen location for the binary log files.",
&opt_bin_logname, &opt_bin_logname, 0, GET_STR_ALLOC,
OPT_ARG, 0, 0, 0, 0, 0, 0},
其中第二个参数 OPT_BIN_LOG 在函数 mysqld_get_one_option 中处理,关联变量 log_bin:
...
case (int) OPT_BIN_LOG:
opt_bin_log= MY_TEST(argument != disabled_my_option);
break;
启动参数中另外一个重要的参数是 log-bin-index ,表示 binlog index 文件的路径, index 文件是 binlog 文件的索引,关于如何保证 crash-safe,请参考 MySQL purge log简单吗? 和月报 MySQL · 源码分析 · binlog crash recovery 。
初始化
初始化工作大部分在函数 init_server_components 中完成,首先是打开 index 文件,对应函数 MYSQL_BIN_LOG::open_index_file,包括下面几步:
- set_crash_safe_index_file 是 binlog index 文件 crash safe 的辅助文件
- 判断 index 文件是否可以访问,如果不可以,就把 crash_safe_index 文件重命名为 index 文件。
- 打开 index 文件,sync 文件,初始化 IO_CACHE。 IO_CACHE 是内部的文件流缓冲,后面会详细介绍。
- 根据 purge_index_file,删除 index 文件中不存在的 binlog 文件。
MySQL 是多存储引擎的架构,假如一个事务跨多个存储引擎,那么就需要内部两阶段提交来保证事务的 ACID,如果 binlog 打开,那么它将作为协调者和各个引擎交互。在启动阶段要负责处理引擎内状态为 prepare 的事务,决定它们是提交还是回滚。关于 MySQL 的整体崩溃恢复可以参考 MySQL · 引擎特性 · InnoDB 崩溃恢复过程。
初始化的时候把 tc_log 设为 mysql_bin_log, binlog 崩溃恢复部分的处理在函数 MYSQL_BIN_LOG::open_binlog(opt_name) 中进行。主要分为几步:
- 以只读模式打开 index 文件中最后一个 binlog 文件,因为在 binlog rotate 的时候会确保事务都已经提交,prepare 事务必然在最后一个 binlog 文件中。
- 读取文件中的 FORMAT_DESCRIPTION_EVENT ,根据 LOG_EVENT_BINLOG_IN_USE_F 判断 binlog 是否安全关闭,如果没有安全关闭,则进入崩溃恢复逻辑。
- 在函数 MYSQL_BIN_LOG::recover 中,循环读取每一个 EVENT,碰到 XID EVENT 就把 xid 插入 hash 表中。把 hash 表传给函数 ha_recover。
- 在 ha_recover 中循环对每个存储引擎调用 xarecover_handlerton 函数,其中会调 handlerton->recover 获取存储引擎中的 prepare 事务集合,再取出每个prepare事务的 xid,去 hash 表中查找,如果找到说明 binlog 中对应的事务已经提交,那么就提交该事务,否则就回滚。
- 剪裁不合法的 event。
除了上面正常的崩溃恢复逻辑,还有一种“启发式”的崩溃恢复,假如数据库奔溃之后 binlog 文件损坏无法担任协调者的角色,对于 prepare 的事务可以人为的选择是提交还是回滚. 参数是 –tc-heuristic-recover。这个参数认为如果超过一个支持事务的引擎,回滚是不安全的,会拒绝回滚,而只有一个事务引擎则会强制回滚,无论参数设置的是什么。
接下来就是打开 binlog 文件,在数据库启动阶段会重新 rotate 一个新的 binlog 文件,调用函数 MYSQL_BIN_LOG::open_binlog
- 调用 init_and_set_log_file_name 顺序获得一个新的文件路径。
- 打开 purge_index 文件,把新的文件名先保存下来,落盘。
- 打开文件
- 写入一些初始化信息,比如 Format_description_log_event。
- 这一步比较有意思,写入 Previous_gtid_set:
if (current_thd) ... prev_gtid_set.write(&log_file) ...数据库启动的时候 current_thd 还没有初始化,所以此时不会写入 Previous_gtid_set,因为 open_binlog 在 rotate 的时候也会调用,此时会维护 Previous_gtid_set 的信息在内存中,发起 rotate 的线程负责创建新的文件并且初始化。启动时候的初始化放在了 main 函数中.
- 更新 index 文件。
打开文件后会清理过期的 binlog 文件,具体在 MYSQL_BIN_LOG::purge_logs_before_date 中。完成之后会跳出 init_server_components。
最后一步是初始化 Previous_gtid_set, 在 MYSQL_BIN_LOG::init_gtid_sets 中从后往前遍历 binlog 文件,读出的第一个 Previou_gtid_set 初始化为 gtid_purged,从前往后遍历 binlog 文件,读出的第一个 Previous_gtid_set 加上当前文件的 gtid 集合,初始化为 gtid_executed。
Group Commit
当 binlog 作为协调者,如果其中记录的事务顺序和存储引擎层记录的顺序不一样的话,备份工具(Innodb Hot Backup)拿到备份集的位点可能会存在空洞。因为备份工具会拷贝 redo 日志,在 redo 的头部会记录最后一个提交的事务对应的 binlog 位点,备份集建立之后就会根据这个位点继续从主库 dump binlog。如下图所示,假如有三个事务 T1,T2,T3 已经 fsync 到 binlog 文件中,三个事务的在文件中的位点分别是 100,200,300,但是在引擎层的只有 T1 和 T3 完成了 commit 并记录到 redo 中,最后一个 commit 的事务 T3 位点是 300。此时通过备份工具拿到的数据就是这样的状态,备份集启动的时候会走崩溃恢复的流程,prepare 事务被回滚(备份集没有 binlog 文件,对应上个小节 xid 集合为空),从位点 300 继续从主库同步数据,那么 T2 在备库就丢失了。
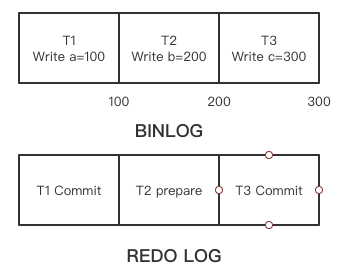
为了解决这个问题,最开始引入了 prepare_commit_mutex ,在两阶段提交引擎层 prepare 的时候加锁,在引擎层 commit 之后释放锁,
innobase_xa_prepare()
write() and fsync() binary log
innobase_commit()
这样确实可以保证 binlog 和 innodb 的事务顺序一致,但是这把锁会导致所有的事务顺序执行,每次执行都会至少调用 3 次 fsync 操作,非常低效。
后面 MariaDB 提出了一个解决方案,也是现在代码中的实现方式,把写 binlog 和引擎 commit 分为三个阶段,每个阶段有不同的 mutex 保护,Flush 阶段只负责调用文件系统的写接口,不保证落盘,Sync 阶段调用 fsync 操作写磁盘,Commit 阶段调用存储引擎接口提交事务。fsync 是比较耗时的操作,希望能够有尽可能多的事务一起执行一次 fsync,所以多个线程到达 Flush 阶段,第一个到达的线程就作为 Leader 线程,后续到达的线程作为 Follower,形成链表,每隔一段时间允许 Leader 线程进入 Sync 阶段,Follower 阻塞等待 Leader 线程唤醒。这样就可以积累多个事务执行一次 fsync。Commit 阶段也是按照链表顺序提交,可以保证 binlog 和引擎层提交顺序一致。

这部分内容非常丰富,介绍的比较粗略,有兴趣可以参考更加详细的文章
- Binary Log Group Commit in MySQL 5.6
- Fixing MySQL group commit part1 | part2 | part3 | part4
- MariaDB & Percona XtraDB Group Commit实现简要分析
- MySQL/InnoDB和Group Commit part1 | part2
代码分析
了解思路之后看看代码,更加复杂有趣一点,主要逻辑在 MYSQL_BIN_LOG::ordered_commit 中,此时引擎层事务已经 prepare,并发情况下线程将不断涌入这个函数中。进入一个阶段的基本函数是:
bool
MYSQL_BIN_LOG::change_stage(THD *thd,
Stage_manager::StageID stage, THD *queue,
mysql_mutex_t *leave_mutex,
mysql_mutex_t *enter_mutex)
{
/*
enroll_for will release the leave_mutex once the sessions are
queued.
*/
if (!stage_manager.enroll_for(stage, queue, leave_mutex))
{
DBUG_RETURN(true);
}
mysql_mutex_lock(enter_mutex);
DBUG_RETURN(false);
}
- thd: 当前线程
- stage: 要进入的阶段
- queue: 需要入队的线程集合,一般为上一个阶段处理完的集合,递送到下一个阶段继续处理。
- leave_mutex: 进入这个阶段会释放的锁
- enter_mutex: 进入这个阶段要持有的锁
一般使用方式
if (change_stage(thd, stage, queue, leave_mutex, enter_mutex))
{
DBUG_RETURN(finish_commit(thd));
}
这个函数只有 Leader 线程才会返回 false,Follower 线程会等待直到被 Leader 线程唤醒,然后返回 true, 调用 finish_commit 退出函数 MYSQL_BIN_LOG::ordered_commit,表示提交完成。具体入队操作在函数 enroll_for 中
bool
Stage_manager::enroll_for(StageID stage, THD *thd, mysql_mutex_t *stage_mutex)
{
int slot= UNDEF_COND_SLOT;
bool leader= m_queue[stage].append(thd, &slot);
if (stage_mutex)
mysql_mutex_unlock(stage_mutex);
if (leader)
thd->stage_leader= true;
if (!leader)
{
/* Follower 线程在这里等待被唤醒 */
mutex_enter_slot(slot);
while (thd->get_transaction()->m_flags.pending)
enter_cond_slot(slot);
mutex_exit_slot(slot);
/* 这个阶段的 Follower 可能是其他阶段的 Leader,要唤醒自己的 Follower */
if (thd->stage_leader)
{
mutex_enter_slot(thd->stage_cond_id);
cond_signal_slot(thd->stage_cond_id);
mutex_exit_slot(thd->stage_cond_id);
}
}
return leader;
}
m_queue 对于每个阶段都维护一个链表,首先就是入队,如果这个阶段链表为空,那么传入队列的 Leader 线程就变成当前阶段的 Leader 线程,如果不为空就说明当前的传入的队列在这个阶段变为 Follower。append 函数会为每个 Leader 线程分配一个 slot 位置,指向一个 cond,保存在 thd->stage_cond_id 中,所有的 Follower 在 append 函数中获得的 slot 都是 leader 线程的 slot。cond 在初始化的时候会分配一个大小为 128 的数组, 新的 Leader 不断递增 index,循环使用其中的 cond,所以最大的活跃的队列个数不能超过 128。
接下来看下每个阶段具体都做了什么,change_stage 到 Flush 阶段,其中一个线程抢占称为 Leader 线程,此时后面到来的线程都会不断追加到链表尾部称为 Follower,Leader 线程获得 LOCK_log 锁,完成 change_stage, 然后执行代码:
THD *wait_queue= NULL;
flush_error= process_flush_stage_queue(&total_bytes, &do_rotate, &wait_queue);
my_off_t flush_end_pos= 0;
if (flush_error == 0 && total_bytes > 0)
flush_error= flush_cache_to_file(&flush_end_pos);
process_flush_stage_queue 中首先要获得 Leader 线程的指针,
stage_manager.fetch_queue_for(Stage_manager::FLUSH_STAGE);
|
------ m_queue[stage].fetch_and_empty
这一步很重要,取出 Leader 线程的同时,把对应 stage 的链表也清空了,这样后面的线程又可以重新竞争成为 Flush 阶段的 Leader,但是新的 Leader 会阻塞在获得 LOCK_log 这一步。接着在 process_flush_stage_queue 中遍历每个 thd 的 binlog cache 写到全局的 cache 中,flush_cache_to_file 对全局的 cache 调用文件系统写操作。
change_stage 到 Sync 阶段,释放 LOCK_log, 等待 LOCK_log 的线程可以进入 Flush 阶段,同样有一个 Leader 线程从 change_stage 中返回继续执行,
/* wait some time or a certain count to aggregate more threads into sync queue.*/
stage_manager.wait_count_or_timeout();
THD *final_queue= stage_manager.fetch_queue_for(Stage_manager::SYNC_STAGE);
if (flush_error == 0 && total_bytes > 0)
{
std::pair<bool, bool> result= sync_binlog_file(false);
}
为了积累更多的数据执行一次 fsync,会等待一定数量或者时间,此时等待的话,Sync 阶段有一个 Leader 线程持有 LOCK_sync 锁,Flush 阶段的 Leader 线程都加入到 Sync 阶段的 Follower 队列中。直到 sync 阶段调用 stage_manager.fetch_queue_for(Stage_manager::SYNC_STAGE) ,才会产生新的 Sync 阶段 Leader 线程。 后面的操作比较简单,调用一次 fsync 操作即可。
Commit 阶段是否执行由参数 binlog_order_commits 决定,如果为 true,那么同样的 change_stage 到 Commit 阶段,释放 LOCK_sync 锁,Leader 线程拿到 LOCK_commit 锁,调用 process_commit_stage_queue 遍历链表,调用存储引擎的 ha_commit_low 提交。
三个阶段都完成后有一个最终的 Leader 线程调用 stage_manager.signal_done,自下而上的唤醒 Follower 线程,Follower 线程调用 finish_commit,如果发现事务在引擎中没有提交,会调用 ha_commit_low, 此时就不能保证 commit 的顺序了。
Dump 线程
每一个用户连接过来在 MySQL 中都有一个线程处理其请求,把结果返回,Dump 线程是处理备库连接的线程,根据备库发送过来的位点读取本地的 binlog 文件,发送 Event 到备库去。备库 change master 就是记录备库要从哪个位点去读,具体可以看这篇月报,而 start slave 之后会和主库有多次交互,具体如下:
- SELECT UNIX_TIMESTAMP()
- SHOW VARIABLES LIKE ‘SERVER_ID’
- SET @master_heartbeat_period= 1799999979520
- SET @master_binlog_checksum= @@global.binlog_checksum
- SELECT @master_binlog_checksum
- SELECT @@GLOBAL.GTID_MODE
- SHOW VARIABLES LIKE ‘SERVER_UUID’
- SET @slave_uuid= ‘’
- command=COM_REGISTER_SLAVE
- command=COM_BINLOG_DUMP
最后一步就是启动 Dump 线程,不论是否看起 Gtid 模式,最终处理的函数都是 mysql_binlog_send,看下大概逻辑:
if (pos > BIN_LOG_HEADER_SIZE)
read Format_description_log_event at the beginning of binlog file.
while (!net->error && net->vio != 0 && !thd->killed)
{
while (true)
{
error = Log_event::read_log_event(,,,,&is_active_binlog);
if (error)
break;
send event to slave;
}
if (!is_active_binlog)
goto_next_binlog= true;
if (!goto_next_binlog)
{
switch (error = Log_event::read_log_event)
{
..
case 0:
read_packet = 1;
break;
case LOG_READ_BINLOG_LAST_VALID_POS:
{
do
{
mysql_bin_log.wait_for_update_bin_log(thd, hearbeat_ts);
}while(signal_cnt == mysql_bin_log.signal_cnt && !thd->killed)
}
break;
}
if(read_packet)
send event to slave;
}
if (goto_next_binlog)
{
find next logfile in index file;
close current file;
open next file;
}
}
第一个循环会不断的从备库发送的位点去读 event,然后发送 event,直到 error 不为 0,正常情况是读到了文件末尾,而 is_active_binlog 可以判断当前读到的是不是正在写入的活跃 binlog 文件,如果不是活跃的,那么就到下一个 binlog 文件继续读。如果是活跃的就可能读到了写入端的末尾,需要等待文件有新的数据。进入 if (!goto_next_binlog) 后尝试读一个 Event,如果返回 0,说明从在 while(true) 读到文件末尾到再次读文件这个区间又产生的新的 Event,发送之后继续进入 while(true) 循环读,如果发现读到了末尾(LOG_READ_BINLOG_LAST_VALID_POS),进入循环 wait_for_update_bin_log 去等待。在主库的写入线程调用 MYSQL_BIN_LOG::ordered_commit 中,flush 或者 sync 阶段写入 Event 后会调用 update_binlog_end_pos() 通过 update_cond 唤醒所有 dump 线程。
binlog for POLARDB
POLARDB 实例之间是通过 redo 物理复制同步的,相比于 binlog 逻辑复制更加高效,而且考虑到打开 binlog 之后对性能影响比较大,起初并不支持 binlog 复制。随着用户不断增长,使用 binlog 同步数据到 RDS 的诉求越来越多,POLARDB 也即将支持原生的 binlog 复制。
在共享存储的架构下,假如主节点宕机,Replica 提升为主库需要走崩溃恢复的逻辑,前面提到 binlog 开启之后将作为事务的协调者,决定 prepare 事务提交还是回滚,因此需要在 Replica 角色切换的时候读取binlog 文件进行崩溃恢复,初始化 gtid等,处理逻辑类似于启动阶段。
对于 binlog 相关的请求,都要求必须发送到主库,即使是类似 show binary logs 这样的查询语句,因为主备实际上还是两个进程,没有共享的 mutex,假如主库在 purge,那么读操作也是不安全的。
在可用性方面也做了一些改进,开放 binlog 的 purge 操作,用户可以手动去删除不需要的文件,也可以配置 expire_logs_hours, 以小时级别的粒度自动处理过期的 binlog 文件。
欢迎使用 POLARDB