Database · 原理介绍 · 数据库的事务与复制
Author: 莫已
前言
本文试图讨论这几个问题:
- MySQL的redo log和binlog为什么要用XA
- MongoDB的oplog是按照什么顺序复制
- Raft真的只能串行Apply吗
- 数据库的复制和事务是完全独立的两回事吗?
- 为什么MySQL不早点做一个Raft插件,直接用Raft实现高可用?
本文旨在阐述Fault-Tolerant Transaction的几种实现模式。虽然它们乍一看可能都是Raft + KVEngine + Concurrency Control,容易被认为是同一类方法,但实际上的差异很大,在讨论时不应该忽视他们之间的差异。
基本概念
- 本文讨论的Fault-Tolerance,指的是通过网络通信的多个计算机节点,在部分节点发生Stop Failure的情况下,仍然尽力保证可用性
- 本文不讨论具体的Fault-Tolerance方法,默认读者对Raft等算法有基本理解
- 本文也不讨论具体的Concurrency Control方法,默认读者对其有基本的理解
- 本文会涉及到Spanner、TiKV、MongoDB等具体的数据库
基于RSM的Fault-Tolerant KV
Replicated State Machine最早应该是在『Implementing fault-tolerant services using the state machine approach』提出。它是一种很简单很实用的实现容错的方法,核心思想是:几个状态机具有相同的初始状态,并且按照同样的顺序执行了同样的命令序列,那么它们的最终状态也是一样的。由于状态一样,那么任意一个状态机宕机,都可以被其他的代替,因此实现了Fault Tolerant。

这里提到了几个概念,命令、执行顺序、状态机,它们都是抽象概念,对应到具体的应用场景才有实际意义。在KVEngine的场景下,命令就是Put/Get等操作,状态机就是KVEngine本身,而执行序列,则由Replication Log决定。
既然提到了RSM和KV,那么基于RSM的KV也就呼之欲出了。把发到KVEngine的操作先用Raft复制一遍,在Apply的时候扔回到KVEngine执行,于是我们就得到了一个Fault-Tolerant的KVEngine。
看起来很简单,但我在这里显然忽略了很多细节:
- 串行还是并行Apply:Raft被人诟病的一点是串行Commit、串行Apply,但这并不是Raft的锅
- 两条Log:Raft复制需要一个Log,KVEngine也会有一个WAL,会带来IO放大,能不能合并成一个呢
- 只读操作需要复制吗
- 命令可以是复合操作吗:单行的CAS操作可以吗,多行的事务操作可以作为一个命令吗
基于RSM的事务
我们来考虑最后一个问题,RSM中的命令,可以直接是一个事务吗?既然Raft都是串行Apply了,那么看起来把事务的所有操作作为一个命令扔到状态机执行并没有什么问题。但问题在于,实际中的事务是交互式的,也就是包含了 if-else等逻辑的,并且逻辑还可能依赖了数据库系统外部的状态,所以不能简单地用WriteBatch + Snapshot来实现一个事务,还是要有Concurrency Control的逻辑。
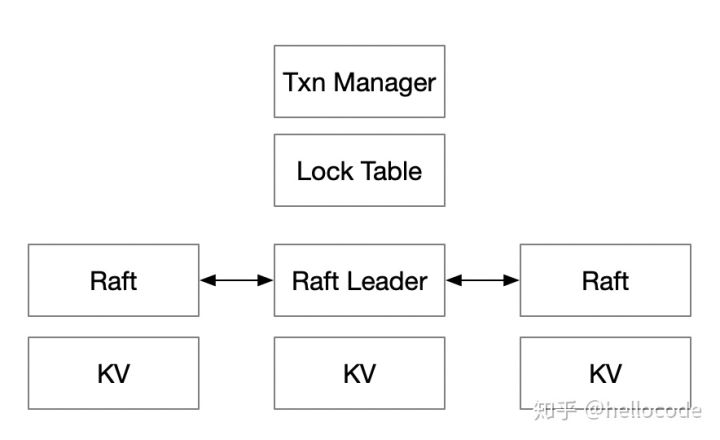
为了解决Concurrency Control的问题,我们在Raft Leader上,实现一个Lock Table和Transaction Manager。拿S2PL方法举例:
- 读数据之前加读锁,写数据之前加写锁;读操作通过Raft读数据,写操作Buffer在本地
- 在用户决定事务提交时,即可释放读锁;通过Raft写一条事务日志,包含所有写操作
- 在Raft Apply事务日志时,把写操作应用到KVEngine,并且释放写锁
这里举的例子是S2PL,但对于其他的并发控制方法也基本通用。例如Snapshot Isolation,事务开始时获得KV的Snapshot,读操作都走Snapshot,写操作获得写锁,数据Buffer在本地,事务提交时检查[begin, end]之间有没有写冲突,没有的话则通过Raft写事务日志,在Apply事务日志之后,把写操作应用到KVEngine,最后释放写锁。
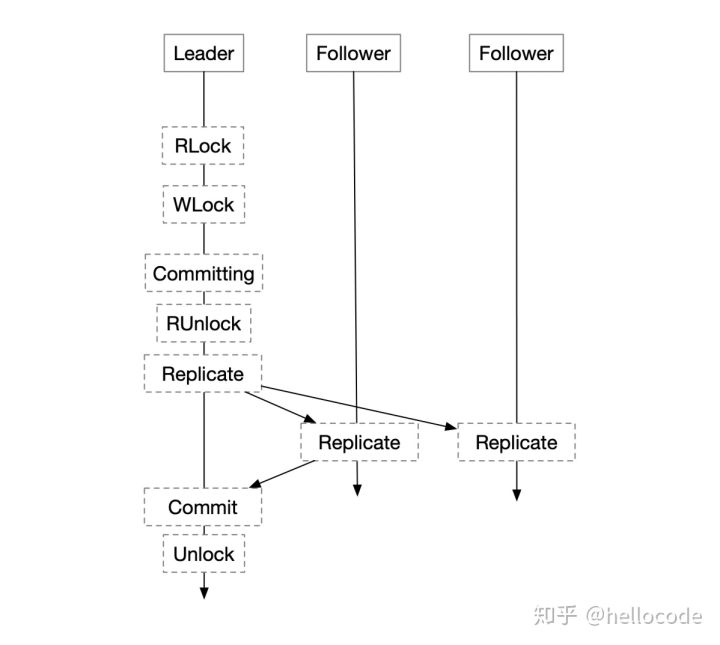
这种方法接近Spanner的做法,它具有几个特点:
- 只有Leader需要维护LockTable、TransactionManager,事务并发控制基本在Leader节点完成
- 从RSM的角度来看,这里的LockTable起到了命令定序的作用,保证所有State Machine按照同样的顺序执行命令
- 写锁会在复制的开始到Commit一直持有:也就意味着,复制协议的Commit即是事务的Commit,在Commit之前发生Failover,事务都会Abort
- 按照S2PL的做法,读锁可以不做复制和持久化,像Spanner仅仅在Leader内存中维护
- Raft所复制的,即是事务的REDO
基于共享存储的事务
重新看一下上面这个模型,复制协议所做的事情非常简单,和其他模块的耦合也很小,仅仅是维护一个有序的Log,因此,我们可以把它从share-nothing推广到share-storage的模型中。
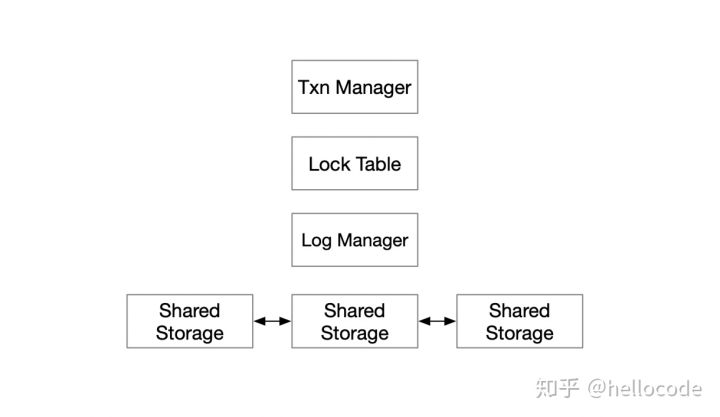
也就是说,我们把普通的单机事务引擎,放到一个高可用的存储上,就得到了基本可用的Fault-Tolerant 事务引擎了,连复制协议也不需要实现的。
不过事情显然不会这么简单:
- 如何实现只读节点,提供读扩展的能力
- 计算节点如何更快地Failover
- 如何把更多的操作下推到存储节点
基于高可用KV的事务
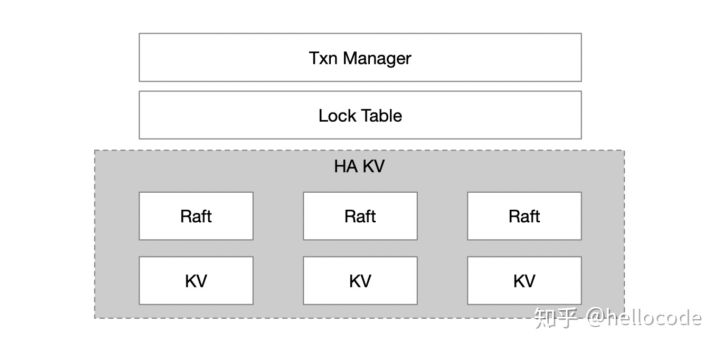
回到一开始的第一种方案,在一个节点实现了KV、Raft、Lock Table、Transaction Manager,看起来耦合度比较大了,我们能不能对其进行分层,进一步简化呢?例如Google的经典做法,基于GFS实现Bigtable,基于Bigtable实现Percolator,分层设计易于迭代、易于开发、易于调试。
因此我们可以考虑把KV层单独抽离出来,基于KV去实现Lock Table、Txn Manager:
- Lock Table:在原本的KV中增加一列,变成
Key => {Value, Lock} - Txn Manager: 从事务修改的所有Key中选出一个Primary Key,用来记录事务状态,因此KV进一步变成
Key => {Value, Lock, TxnStatus} - MVCC:甚至我们不甘心于Single Version,还想用Multi Version的并发控制,那么KV就变成
{Key, Version} => {Value, Lock, TxnStatus}
看过Percolator、TiKV设计的应该会比较熟悉,它们就是基于一个高可用的KV,把事务的状态都下沉到KV中。这种设计很容易拓展到分布式事务的场景,如果KV能够scale,那么上层的事务也能够scale了。
基于单机事务引擎实现高可用事务
上面的方案看起来都比较清晰,不过有一个细节不容忽视:锁基本都是在复制协议提交之后才会释放,换句话说事务持有的锁会从事务开始直到多个节点写完日志,经历多次网络延迟、IO延迟,并且在拥塞情况下会面临排队延迟的风险。而锁意味着互斥,互斥意味着事务吞吐降低。
那么自然会想到:
- 锁一定要在复制协议提交之后才能释放吗?
- RSM的Order一定要和事务的Serialization Order一致吗?
- 提前释放会破坏Order的一致性吗?
暂且不做回答,我们再看最后一种方案,基于单机事务引擎的高可用事务:
- 在正常的单机事务流程中,增加一个复制的环节:本地事务提交之后不是立即返回用户,而是写binlog,等待binlog 复制到其他节点之后再返回用户
这种方式的事务延迟,看起来还是本地事务的延迟,加上复制日志的延迟;但相比于之前的方案,本地事务可以先提交,锁可以提交释放,总体的事务吞吐相比之下会有所提升。
看起来甚至比之前的方案更加简单,事务和复制模块得到了完美的分离,但这里忽略了一个复杂的问题:
- 基于哪个日志来复制,基于数据库的Journal,还是再写一个binlog?
- 基于什么顺序进行复制,如果是基于Journal复制可以用Journal顺序,如果基于binlog,顺序又是什么?
- 如果有两个日志,两个日志其实意味着Transaction Serialization Order和RSM的State Machine Order不一样,会不会产生事务的并发异常,或者导致State Machine不一致?
- 由于直接复制Journal会引起一系列复杂的耦合问题,大部分数据库都选择单独写一个binlog/oplog来实现复制,不过在实现时可以做优化,因为如果真的写两个log会有原子性的问题(一个写成功了另一个没写成功)以及IO放大的问题。
这里的设计空间比较庞大,不做详细讨论,仅仅考虑在简化的模型下复制顺序的问题。
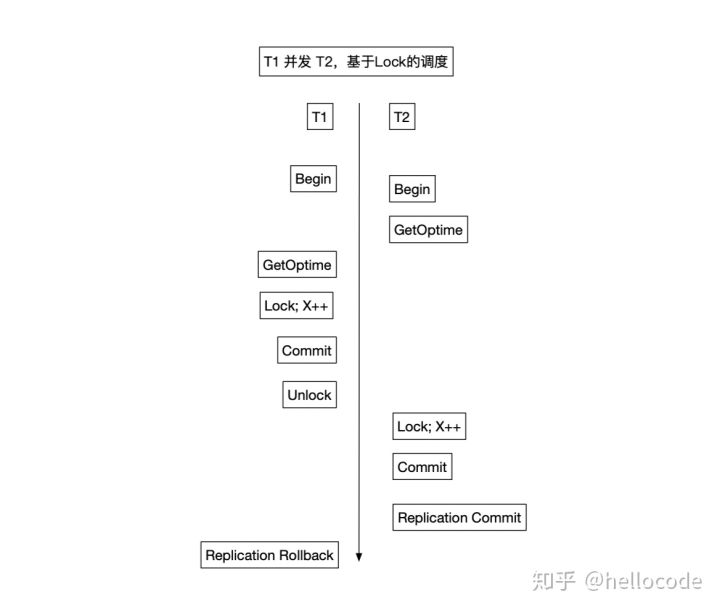
对于并发执行的事务,为了确定复制顺序,这里维护一个称之为OpTime的自增ID。后续的复制会按照OpTime的顺序,OpTime小的先复制。如果OpTime仅仅是在事务的开始和结束之间分配,会带来问题:
- 有冲突且并发的事务T1先Commit,具有较大的OpTime,也就意味会被后复制
- 后Commit的事务T2先Replication Commit,而先Commit的事务T1可能因为复制失败而Rollback
- 对于事务来说,这种场景下出现的异常类似Read-Uncommitted,事务T2读到了未Commit的数据
因此,OpTime的分配需要有更强的限制:对于并发且有冲突的事务,OpTime的顺序要和事务的Serialization Order一样:
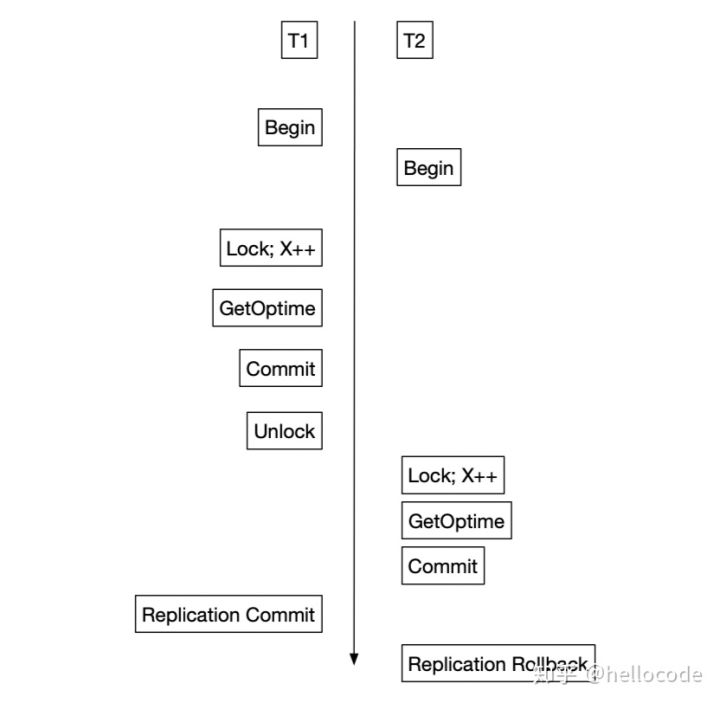
在S2PL的场景中,我们把OpTime分配放到Lock之后Commit之前,即可满足这个要求。因为按照S2PL的调度,事务的Commit-Point就是Lock完成和Unlock之间。对照上面的例子,事务T2的OpTime被推迟到T1之后,复制的顺序也会相应改变,不会发生先前的异常了。
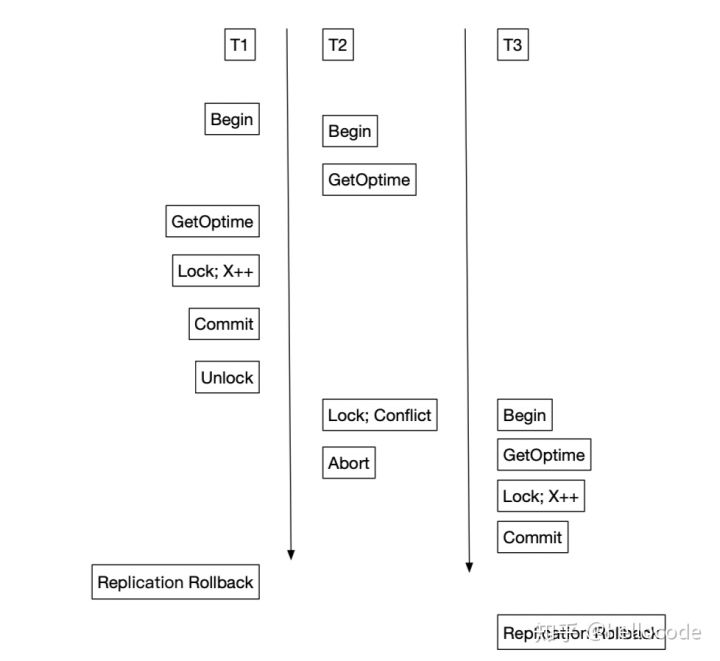
推广到其他的并发控制方法也是类似,例如上面的Snapshot Isolation。提交之前会检查[begin, end]是否有冲突,有冲突直接重启事务。相当于在[begin, end]区间内分配OpTime即可。
这种方法通过OpTime,保留了Transaction Serialization Order和RSM的Order之间的关系:
- 并发且有冲突的事务,其OpTime的顺序和事务Serialization Order一样
- 并发但没有冲突的事务,其OpTime顺序不确定,因为谁先提交都不会影响正确性
- 有先于关系的事务,OpTime也一定满足这个先于关系
这个做法基本是MongoDB的做法:
- 事务流程中先分配一个Optime
- 一次事务写操作包含:数据、索引、oplog,通过WiredTiger存储引擎的Snapshot Isolation事务来保证ACID
- oplog写到一个特殊的表,因此对于存储引擎来说,一次用户的写操作,最后也只是一次存储引擎的事务写入
- 由于事务提交顺序和Optime不一样,所以存储模块需要维护oplog集合的空洞,保证按照Optime的顺序进行复制、Commit
不过这里留下了一个问题,留待读者思考:
- 如何按照OpTime复制,因为有事务Abort的情况,OpTime做不到连续自增,仅仅是单调自增
对比
第一种其实是Spanner以及目前云厂商所Follow的共享存储数据库,第二种是TiKV、Percolator、Omid等基于分布式KV的事务系统,第三种是MySQL、MongoDB等数据库。
它们在复制上的区别:
- 第一种方案是复制了事务的REDO,事务的提交顺序由Raft Log的顺序确定,Failover等机制完全按照RSM的模型来即可
- 第二种方案Raft仅仅用于复制KV,事务的顺序和Raft Log的顺序没有关系,KV层的Failover和事务的Recovery完全独立
- 第三种方案,已经区别于传统的RSM模型,因为它其实是先Apply,再Replication、Commit,可以实现并发Apply
从复杂度来看:
- 第二种最简单清晰,从Raft,到Raft KV,再到Transactional KV,分层良好
- 其次是第一种,在Leader节点会额外实现Lock Table、Transaction Manager,这个和Raft是紧密结合的,但是事务提交的顺序就是Raft Log的提交顺序,不会造成混淆
- 最复杂的是第三种,由于事务提交顺序和Optime顺序不一致,对复制、读写等各种流程都会造成影响,看似简单但实则耦合
从事务并发的角度来看:
- 第三种方案可以完美支持并发,且可以做到持有锁的时间较短,仅仅是写一次本地日志
- 第一二种方案持有锁的时间更长,最后在Apply时理论上可以做到并发,如果没有其他约束
从读写放大的角度来看:
- 第一种最好,Replication Log和Engine Log可以合并,每条事务只要复制一次Raft Log
- 其次是第二种,通常会把binlog和存储引擎的journal独立,需要写两遍;不过oplog可以写到存储引擎里,一次IO即可提交(MongoDB的做法)
- 最后是第二种,在KV中增加了更多的数据,放大较多
不过这仅仅是理论上的分析,实际的复杂度、性能,很大程度上取决于实现而非理论。
总结
如果我们从很粗的粒度来看,会觉得这些系统不过都是几个技术点的组合,而每一个技术点看起来都很简单,进而觉得事务系统不过是如此;但实际上事务系统绝非简单的KV + Raft + Snapshot Isolation,它们之间不同的组合方式,会最终造就不同的系统。
本文留下了很多问题,RSM的Order往往认为是全序的,而Transaction 的Serialization Order是偏序的(偏序关系由事务冲突定义),它们之间如何统一?RSM的Checkpoint和Transaction Checkpoint的统一?RSM 的Recovery和Transaction Recovery的关系?写两条日志的系统(journal和binlog)两条日志之间的关系是什么?留待下回分解。