PgSQL · 引擎特性 · PostgreSQL 并行查询概述
Author: lingce
背景
大数据时代,人们使用数据库系统处理的数据量越来越大,请求越来越复杂,对数据库系统的大数据处理能力和混合负载能力提出更高的要求。PostgreSQL 作为世界上最先进的开源数据库,在大数据处理方面做了很多工作,如并行和分区。
PostgreSQL 从 2016 年发布的 9.6 开始支持并行,在此之前,PostgreSQL 仅能使用一个进程处理用户的请求,无法充分利用资源,亦无法很好地满足大数据量、复杂查询下的性能需求。2018 年 10 月发布的 PostgreSQL 11,在并行方面做了大量工作,支持了并行哈希连接,并行 Append 以及并行创建索引等特性,对于分区表,支持了 Partition-wise JOIN。
本文从以下三方面介绍 PostgreSQL 的并行查询特性:
- 并行查询基础组件,包括后台工作进程(Background Work Process),动态共享内存(Dynamic Shared Memory)以及后台工作进程间的通信机制和消息传递机制
- 并行执行算子的实现,包括并行顺序扫描、并行索引扫描等并行扫描算子,三种连接方式的并行执行以及并行
Append - 并行查询优化,介绍并行查询引入的两种计划节点,基于规则计算后台工作进程数量以及代价估算
举个例子
首先,通过一个例子,让我们对 PostgreSQL 的并行查询以及并行计划有一个较宏观的认识。如下查询:统计人员表 people 中参加 2018 PostgreSQL 大会的人数:
SELECT COUNT(*) FROM people WHERE inpgconn2018 = 'Y';
没有开并行的情况下(max_parallel_workers_per_gather=0),查询计划如下:
Aggregate (cost=169324.73..169324.74 rows=1 width=8) (actual time=983.729..983.730 rows=1 loops=1)
-> Seq Scan on people (cost=0.00..169307.23 rows=7001 width=0) (actual time=981.723..983.051 rows=9999 loops=1)
Filter: (atpgconn2018 = 'Y'::bpchar)
Rows Removed by Filter: 9990001
Planning Time: 0.066 ms
Execution Time: 983.760 ms
开启并行的情况下(max_parallel_workers_per_gather=2),查询计划如下:
Finalize Aggregate (cost=97389.77..97389.78 rows=1 width=8) (actual time=384.848..384.848 rows=1 loops=1)
-> Gather (cost=97389.55..97389.76 rows=2 width=8) (actual time=384.708..386.486 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=96389.55..96389.56 rows=1 width=8) (actual time=379.597..379.597 rows=1 loops=3)
-> Parallel Seq Scan on people (cost=0.00..96382.26 rows=2917 width=0)
(actual time=378.831..379.341 rows=3333 loops=3)
Filter: (atpgconn2018 = 'Y'::bpchar)
Rows Removed by Filter: 3330000
Planning Time: 0.063 ms
Execution Time: 386.532 ms
max_parallel_workers_per_gather 参数控制执行节点的最大并行进程数,通过以上并行计划可知,开启并行后,会启动两个 worker 进程(即 Workers Launched: 2)并行执行,且执行时间(Execution Time)仅为不并行的40%。该并行计划可用下图表示:
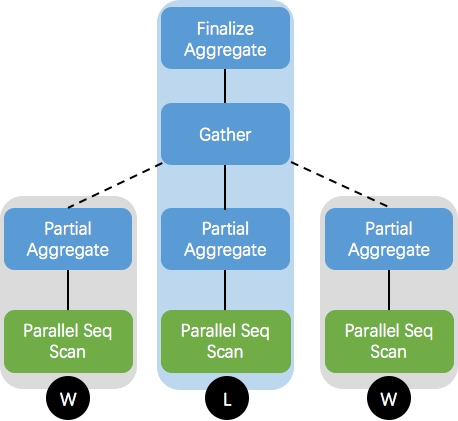
并行查询计划中,我们将处理用户请求的 backend 进程称之为主进程(leader),将执行时动态生成的进程称之为工作进程(worker)。每个 worker 执行 Gather 节点以下计划的一个副本,leader 节点主要负责处理 Gather 及其以上节点的操作,根据 worker 数不同,leader 也可能会执行 Gather 以下计划的副本。
并行基础组件
PostgreSQL 从 9.4 和 9.5 已经开始逐步支持并行查询的一些基础组件,如后台工作进程,动态共享内存和工作进程间的通信机制,本节对这些基础组件做简要介绍。
后台工作进程(Background Worker Process)
PostgreSQL 是多进程架构,主要包括以下几类进程:
- 守护进程,通常称之为
postmaster进程,接收用户的连接并 fork 一个子进程处理用户的请求 backend进程,即postmaster创建的用于处理用户请求的进程,每个连接对应一个backend进程- 辅助进程,用于执行
checkpoint,后台刷脏等操作的进程 - 后台工作进程,用于执行特定任务而动态启动的进程,如上文提到的 worker 进程
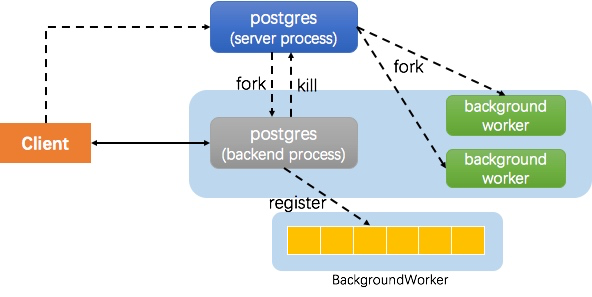
上图中 server process 即 postmaster 进程,在内核中,postmaster 与 backend 进程都是 postgres 进程,只是角色不同。对于一个并行查询,其创建 worker 进程的大致流程如下:
- client 创建连接,
postmaster为其 fork 一个backend进程处理请求 backend接收用户请求,并生成并行查询计划- 执行器向
backgroudworker注册 worker 进程(并没有启动) - 执行器通知(kill)
postmaster启动 worker 进程 - worker 进程与 leader 进程协调执行,将结果返回 client
动态共享内存(Dynamic Shared Memory)与 IPC
PostgreSQL 是多进程架构,进程间通信往往通过共享内存和信号量来实现。对于并行查询而言,执行时创建的 worker 进程与 leader 进程同样通过共享内存实现数据交互。但这部分内存无法像普通的共享内存那样在系统启动时预先分配,毕竟直到真正执行时才知道有多少 worker 进程,以及需要分配多少内存。
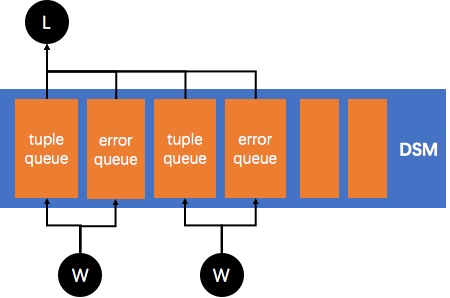
PostgreSQL 实现了动态共享内存,即在执行时动态创建,用于 leader 与 worker 间通信,执行完成后释放。基于动态共享内存的队列用于进程间传递元组和错误消息。
如下图,每个 worker 在动态共享内存中都有对应的元组队列和错误队列,worker 将执行结果放入队列中,leader 会从对应队列获取元组返回给上层算子。动态共享内存的具体实现原理和细节在此不做展开。
并行执行
以上简单介绍了并行查询依赖的两个重要基础组件:后台工作进程和动态共享内存。前者用于动态创建 worker,以并行执行子查询计划;后者用于 leader 和 worker 间通信和数据交互。本节介绍 PostgreSQL 目前支持并行执行的算子的实现原理,包括:
- 并行扫描,如并行顺序扫描,并行索引扫描等
- 并行连接,如并行哈希连接,并行
NestLoop连接等 - 并行
Append
并行扫描
并行扫描的理念很朴素,即启动多个 worker 并行扫描表中的数据。以前一个进程做所有的事情,无人争抢,也无需配合,如今多个 worker 并行扫描,首先需要解决如何分工的问题。
PostgreSQL 中的并行扫描分配策略也很直观,即 block-by-block。多个进程间(leader 和 worker)维护一个全局指针 next,指向下一个需要扫描的 block,一旦某个进程需要获取一个 block,则访问该指针,获取 block 并将指针向前移动。
目前支持并行的常用扫描算子有:SeqScan,IndexScan,BitmapHeapScan 以及 IndexOnlyScan。
下图分别是并行 SeqScan(左)和 并行 IndexScan(右)的原理示意图,可见两者均维护一个 next 指针,不同的是 SeqScan 指向下一个需要扫描的 block,而 IndexScan 指向下一个索引叶子节点。
注意,目前并行 IndexScan 仅支持 B-tree 索引。
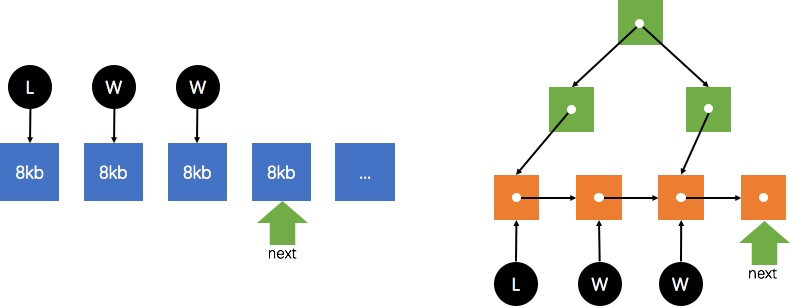
并行 IndexOnlyScan 的原理类似,只是无需根据索引页去查询数据页,从索引页中即可获取到需要的数据;并行 BitmapHeapScan 同样维护一个 next 指针,从下层 BitmapIndexScan 节点构成的位图中依次分配需要扫描的 block。
并行连接
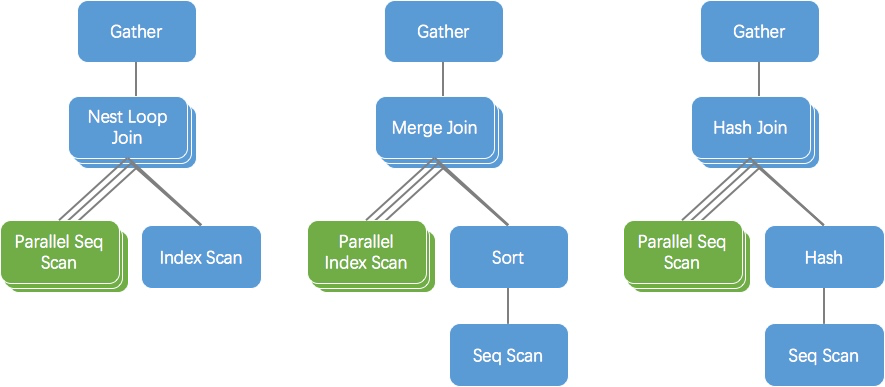
PostgreSQL 支持三种连接算法:NestLoop,MergeJoin 以及 HashJoin。其中 NestLoop 和 MergeJoin 仅支持左表并行扫描,右表无法使用并行;PostgreSQL 11 之前 HashJoin 也仅支持左表并行,PostgreSQL 11 支持了真正的并行 HashJoin,即左右表均可以并行扫描。
以下图左侧的 NestLoop 查询计划为例,NestLoop 左表是并行 Seq Scan,右表是普通的 Index Scan,三个进程(1 个 leader,2 个 worker)分别从左表中并行获取部分数据与右表全量数据做 JOIN。Gather 算子则将子计划的结果向上层算子输出。图中右表是索引扫描,其效率可能还不错,如果右表是全表扫描,则每个进程均需要全表扫描右表。
同理,MergeJoin 也是类似的,左表可以并行扫描,右表不能并行。由于 MergeJoin 要求输入有序,如果右侧计划需要显式排序,则每个进程都需要执行 sort 操作,代价较高,效率较低。
PostgreSQL 10 中的并行 HashJoin 如下图所示,每个子进程都需要扫描右表并构建各自的 HashTable 用于做 HashJoin。
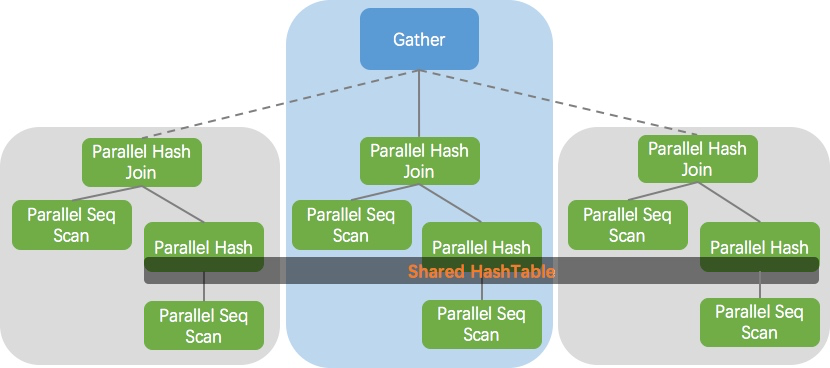
PostgreSQL 11 实现了真正的并行 HashJoin,所有进程并行扫描右表并构建共享的 HashTable,然后各进程并行扫描左表并执行 HashJoin,避免了 PostgreSQL 10 中各自构建一个私有 HashTable 的开销。
关于三种 HashJoin 的执行效率以及性能提升,读者可以参考 THOMAS MUNRO 的这篇文章。
并行 Append
PostgreSQL 中用 Append 算子表示将多个输入汇聚成一个的操作,往往对应 SQL 语法中的 UNION ALL。在 PostgreSQL 11 中实现了 partition-wise join,如果多个分区表的查询满足特定连接条件(如拆分键上的等值连接),则可将其转换为多个子分区的局部 JOIN,然后再将局部 JOIN 的结果 UNION ALL 起来。具体转换细节以及实现在此不展开,读者可以参考 Ashutosh Bapat (आशुतोष बापट) 的这篇文章。以下给出一个转换后的示例图:
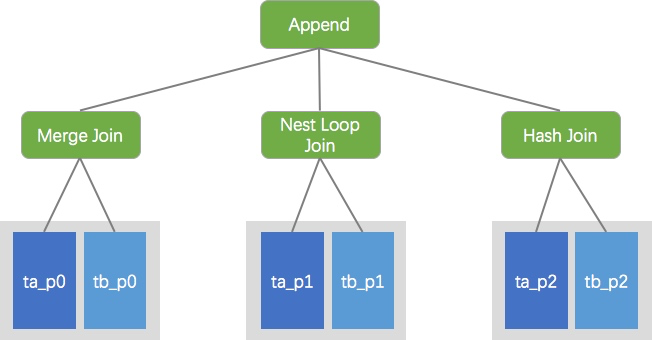
在实现并行 Append 之前,Append 算子下的多个孩子节点均只能通过一个进程依次执行,并行 Append 则分配多个 worker 进程,并发执行多个孩子节点,其孩子节点可以是以上介绍的并行执行算子,也可以是普通的算子。
并行查询优化
PostgreSQL 实现了基于代价的优化器,大致流程如下:
- 考虑执行查询的可能路径(Path)
- 估算代价,并选择代价最小的路径
- 将路径转换为计划供执行器执行
在并行查询优化中,将路径节点分为两类:
parallel-aware节点,即节点本身可以感知自己在并行执行的节点,如Parallel Seq Scanparallel-oblivious节点,即节点本身意识不到自己在并行执行,但也可能出现在并行执行的子计划中(Gather以下),如以上提到的并行NestLoop计划中的NestLoop节点
并行查询引入了两个新的节点:Gather 和 GatherMerge,前者将并行执行子计划的结果向上层节点输出,不保证有序,后者能够保证输出的顺序。
并行查询优化在生成路径时,会生成部分路径(Partial Paths),所谓 partial,即说明该路径仅处理部分数据,而非全部数据。Partial Paths 从最底层的扫描节点开始,比如 Parallel Seq Scan,就是一个 partial path;包含 partial path 的路径(Gather/GatherMerge 以下)同样也是 partial path,比如我们在 Partial Seq Scan 节点上做聚合操作(Aggregate),此时的聚合操作是对局部数据的聚合,即 Partial Aggregate。随后,优化器会在 partial path 之上添加对应的 Gather/GatherMerge 节点,Gather/GatherMerge 相当于把 partial path 封装成一个整体,对上屏蔽并行的细节。
并行度
既然要并行执行,就需要解决并行度的问题,即评估需要几个 worker。目前,PostgreSQL 仅实现了基于规则的并行度计算,大体包括两部分:
- 通过 GUC 参数获取并行度
- 基于表大小评估并行度
并行度相关的 GUC 参数如下:
max_parallel_workers_per_gather每个Gather/GatherMerge最大的并行 worker 数(不包含 leader)force_parallel_mode是否强制使用并行min_parallel_table_scan_size使用并行扫描的最小表大小,默认 8MBmin_parallel_index_scan_size使用并行扫描的最小索引大小,默认 512KB
根据表大小计算并行度的公式如下:
log(x / min_parallel_table_scan_size) / log(3) + 1 workers
以 min_parallel_table_scan_size 为默认值 8MB 来计算,表大小在 [8MB, 24MB) 区间时为 1 个 worker,在 [24MB, 72MB) 区间时为 2 个 worker,以此类推。
需要注意的是,尽管在查询优化阶段已经计算了并行度,但最终执行的时候是否会启动对应数量的进程还取决于其他的因素,如最大允许的后台工作进程数(max_worker_processes),最大允许的并行进程数(max_parallel_workers),以及事务隔离级别是否为 serializable(事务隔离级别可能在查询优化以后,真正执行之前发生改变)。一旦无法启动后台工作进程,则由 leader 进程负责运行,即退化为单进程模式。
代价估算
并行查询优化需要估算 Partial Path 的代价以及新加节点 Gather/GatherMerge 的代价。
Partial Path
对于 Partial Path 中的 parallel-aware 节点,比如 Partial Seq Scan,由于多个 worker 并行扫描,每个 worker 处理的数据量减少,CPU 消耗也减少,通过如下方法评估 parallel-aware 的 CPU 代价和处理行数。
- 计算并行除数(parallel_divisor)
double parallel_divisor = path->parallel_workers;
if (parallel_leader_participation)
{
double leader_contribution;
leader_contribution = 1.0 - (0.3 * path->parallel_workers);
if (leader_contribution > 0)
parallel_divisor += leader_contribution;
}
以上算法说明,worker 越多,leader 就越少参与执行 Gather/GatherMerge 以下的子计划,一旦 worker 数超过 3 个,则 leader 就完全不执行子计划。其中 parallel_leader_participation 是一个 GUC 参数,用户可以显式控制是否需要 leader 参与子计划的执行。
- 估算 CPU 代价,即
cpu_run_cost /= parallel_divisor - 估算行数,
path->rows / parallel_divisor
对于 Partial Path 中的 parallel-oblivious 节点,则无需额外处理,由于其并不感知自身是否并行,其代价只需要根据下层节点的输入评估即可。
Gather/GatherMerge
并行查询中引入了两个新的代价值:parallel_tuple_cost 和 parallel_setup_cost。
parallel_tuple_cost每个 Tuple 从 worker 传递给 master 的代价,即 worker 将一个 tuple 放入共享内存队列,然后 master 从中读取的代价,默认值为 0.1parallel_setup_cost启动并行查询 worker 进程的代价,默认值为 1000
在此不具体介绍这两个节点的代价计算方式,感兴趣的读者可以参考 cost_gather 和 cost_gather_merge 的实现。
并行限制
PostgreSQL 并行查询功能日趋完善,但仍然有很多情况不支持使用并行,这也是未来社区需要解决的问题,主要包括以下场景:
- 任何写数据或者锁行的查询均不支持并行,
CREATE TABLE ... AS,SELECT INTO,和CREATE MATERIALIZED VIEW等创建新表的命令可以并行 - 包含 CTE(with…)语句的查询不支持并行
DECLARE CURSOR不支持并行- 包含
PARALLEL UNSAFE函数的查询不支持并行 - 事务隔离级别为
serializable时不支持并行
更多的并行限制,读者可以参考官网。
总结
本文从并行基础组件、并行执行以及并行查询优化三方面介绍了 PostgreSQL 的并行查询特性,每个模块的介绍都较为宏观,不涉及太多实现细节。希望读者可以借此了解 PostgreSQL 并行查询的全貌,对实现细节感兴趣的读者亦可以此为指引,深入解读源码,加深理解。
当然,PostgreSQL 并行特性涉及模块众多,实现复杂,笔者对其理解也还有很多不到位的地方,还望大家多多指正。
参考文献
- https://www.postgresql.org/docs/11/parallel-query.html
- https://speakerdeck.com/macdice/parallelism-in-postgresql-11
- https://www.postgresql.org/docs/11/parallel-plans.html#PARALLEL-JOINS
- http://rhaas.blogspot.com/2013/10/parallelism-progress.html
- https://www.enterprisedb.com/blog/parallel-hash-postgresql
- https://write-skew.blogspot.com/2018/01/parallel-hash-for-postgresql.html
- http://amitkapila16.blogspot.com/2015/11/parallel-sequential-scans-in-play.html
- https://blog.2ndquadrant.com/parallel-aggregate/
- https://www.pgcon.org/2017/schedule/attachments/445_Next-Generation%20Parallel%20Query%20-%20PGCon.pdf
- https://www.enterprisedb.com/blog/parallelism-and-partitioning-improvements-postgres-11