POLARDB · 性能优化 · 敢问路在何方 — 论B+树索引的演进方向(中)
Author: zhiyi
前言
在前文《POLARDB · 性能优化 · 敢问路在何方 — 论B+树索引的演进方向(上)》一文中,笔者以多核处理器+闪存为背景,详细分析了Bw树的索引设计、存储层设计和在数据库中的实际应用,并分析了它的优势劣势。本文以多核处理器+非易失内存(Persistent Memory,PM)为背景,分析新型非易失内存场景下B+树的设计与优化[1-5]。
如下图[7]所示,在传统的存储体系结构中,存储系统借助易失性内存提供高性能的数据访问,利用性能较差但价格低廉的闪存/硬盘保证数据的持久性。传统内存是基于动态随机访问存储器(Dynamic Random Access Memory,DRAM)构建的。每个DRAM cell中包含一个电容,它限制了DRAM器件的扩展性。当DRAM cell的尺寸低于某个阈值时,电容存在被电荷击穿的可能,因此难以依赖DRAM在内存层次提供TB乃至更大存储容量的能力[8,9,10]。当然,目前也有一些研究尝试基于3D堆叠技术,提高DRAM的存储密度,但这也存在一些工艺等方面的其它问题。
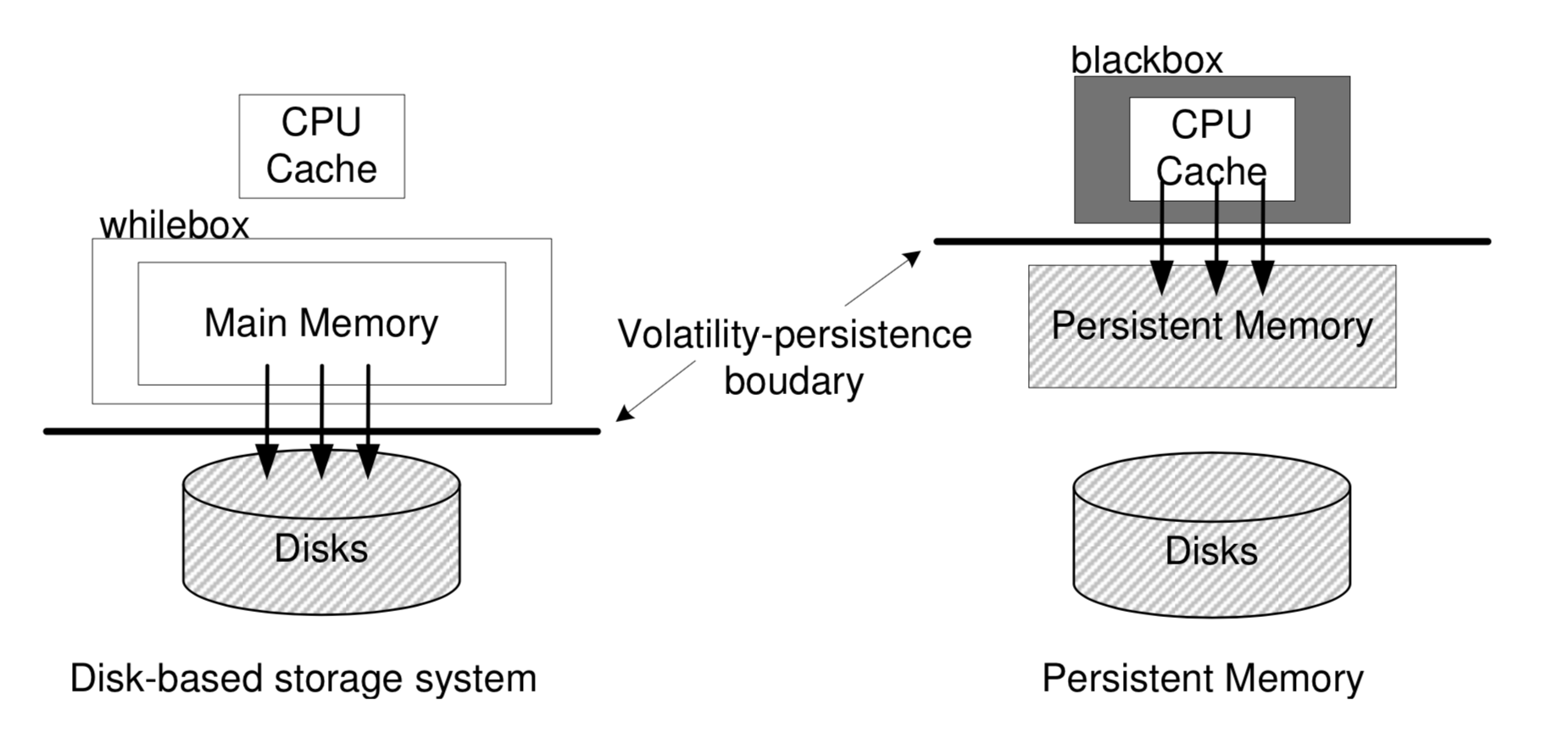
另外,DRAM中的电荷会随着时间慢慢流失,当电荷流失超过一定程度时,DRAM cell中的数据就会丢失。为了解决这个问题,传统内存依赖周期性的刷新操作避免数据丢失,这也产生了较高的静态能耗,在大的数据中心中这部分能耗也会产生较为昂贵的电力成本。此外,传统内存是易失性的,数据会随着内存断电而丢失。因此,存储系统需要在合适的时机,将内存中的数据持久化到外存中。然而,不管是磁盘(毫秒级的访问延迟)还是闪存(数十微妙级别的访问延迟),持久化延迟都会显著影响请求的响应延迟,降低整个系统的性能。
为了解决这些问题,学术界以及工业界一直在寻找传统内存和外存的替代材料。非易失内存(PM)是一种在内存层次提供数据持久性的新介质,比如相变存储器(Phase Change Memory,PCM),自旋力矩存储器(Spin-Transfer Torque RAM,STT-RAM)和阻变存储器(Resistive RAM,RRAM)。目前,非易失内存离实用场景越来越近,比如Intel公司开发的基于3DxPoint的DIMM接口内存条即将投入使用(内部实现机制和原理尚未公开)。非易失内存不仅拥有传统磁盘/闪存的持久性,并且具有接近内存的高性能(百纳秒级的访问延迟)及字节寻址的特性。
为了榨干非易失内存的性能红利,降低软件栈开销,研究人员往往会把非易失内存作为内存+外存的单层存储,挂载在内存总线上,直接通过内存接口进行访问。如上图所示,非易失内存将易失性-持久性的边界移动到处理器缓存与持久性内存之间,这将打破传统易失性内存与非易失外存的边界,对上层软件系统的设计产生颠覆性的改变。正因如此,相比于多核处理器+闪存场景,多核处理器+非易失内存场景下B+树的演进方向更加复杂。
首先,非易失内存在内存层次保证了数据持久性,这同样要求存储系统在内存层次保证数据的崩溃一致性,能从系统崩溃中将数据恢复到一致性的状态。如下图所示,访问非易失内存中的数据需要经历多个易失性的存储器件,包括片上的store buffer,处理器缓存和内存控制器缓存。只有确保已经将数据从这些易失性存储写回到非易失内存中,才能保证这些数据的持久性。
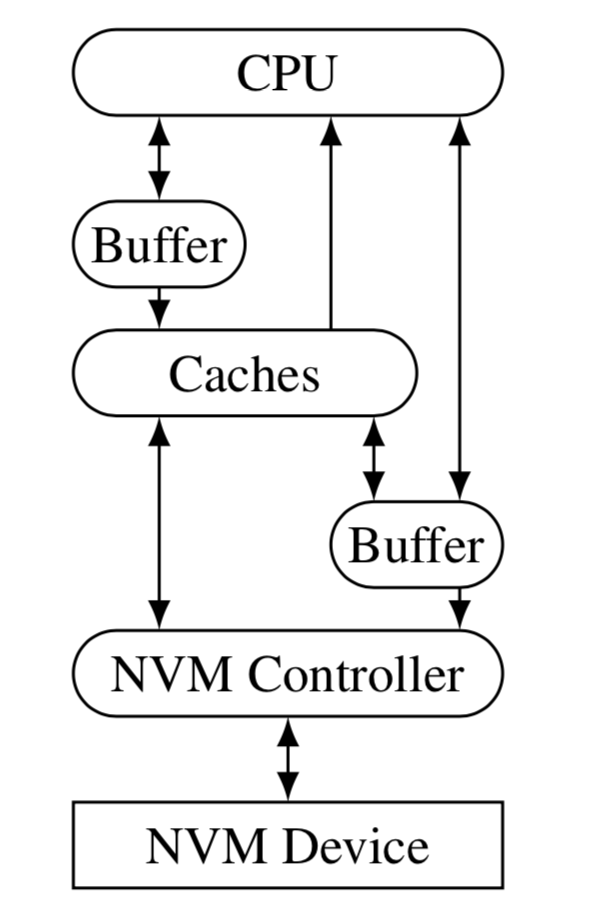
然而,当PM挂载在内存总线上时,64位计算机只能保证8字节数据(地址对齐)的原子性和持久性,任何大于8字节的写操作都可能因为系统崩溃处于一个不一致的中间状态。传统存储系统往往依赖日志机制来保证一致性,即在修改某个数据时先将新/旧数据写入日志并持久化,然后再写回到原数据区。因此,为了保证一致性,系统需要按照正确的顺序将脏数据从易失性缓存持久化到非易失内存,比如先写日志,再写原数据区。对于传统存储架构,内存中的数据是一个白盒,存储系统知道每个页的持久化状态,它可以借助文件系统/操作系统中类似fsync的操作,保证数据从内存(page cache)持久化到外存中。然而,处理器缓存往往是硬件控制的,对软件系统而言像是一个黑盒,它根据缓存替换策略(例如LRU等)自动将某些缓存行写回到非易失内存中,这会打乱数据持久化到内存中的顺序。当系统突然崩溃时,非易失内存中的持久性数据可能处于一个不一致的状态。软件系统难以追踪每个缓存行的持久化状态,即使可以,也会带来过于昂贵的追踪开销。
为了解决这个问题,硬件厂商提供一些新的指令用于刷新缓存行,保证某个数据已经持久化到内存中,例如clflush指令,它将包含某个数据的缓存行刷回内存。然而,clflush指令之间有顺序的限制,会产生百纳秒级的延迟。对于访问延迟仅为百纳秒级的非易失内存,clflush会产生严重的性能影响[2]。此外,clflush指令会将对应缓存行置为无效,影响后续相同缓存行的访问,频繁的clflush调用会带来频繁的处理器缓存缺失[11]。另外,clflush指令只能保证缓存行数据写到内存控制器的row buffer中,然后row buffer无法保证数据的持久性,所以它还需要调用pcommit指令将row buffer中的所有数据持久化到介质上,这同样产生了比较高的等待延迟。因此,研究者们开始研究扩展CPU硬件,减少clflush和pcommit指令带来的性能影响。例如Intel公司开始提供clflushopt和clwb指令,前者消除了clflush指令之间的顺序限制,后者进一步避免了对应缓存行的失效。因为clflushopt/clwb无法保证相互之间的顺序,所以它们依赖mfence指令保证顺序要求。此外,Intel公司还为row buffer加上了小型电容,它能保证系统突然崩溃时row buffer中的数据持久化到介质上,所以就消除了pcmmit的开销。学术界还研究了很多硬件方法去提高性能,例如设计非易失缓存[12],放松事务之间持久性的限制[13]等等。这部分方法往往需要修改硬件,与本文关系不大。以后有机会,笔者会从体系结构角度,详细分析如何减少非易失内存上的一致性开销。
虽然上述指令级别的优化在一定程度上提高了性能,但是基于日志的一致性保障机制对于非易失内存而言过于厚重,重复写操作+多次持久化指令的调用所带来的延迟,在很大程度上掩盖了非易失内存百纳秒级的性能优势。正因如此,学术界开始针对索引结构的特点,设计更加灵活和轻量级的一致性机制。
其次,非易失内存往往存在读写不对称的特性,写操作的延迟显著高于读延迟,并且具有有限的写寿命问题。以较为成熟的PCM为例,它通过加热操作改变器件阻值,通过不同的阻值范围表示0和1这两个值。然而,这种基于加热修改阻值的写操作需要较长的时间/能量,写延迟往往在200纳秒到1微妙的范围内。并且,写操作会产生较高的动态能耗,每个PCM cell在经过一定的写操作后无法继续写入(寿命大约是10^8次),永久性停留在某个阻值上。相比于写操作,它的读操作只需要通过小的电流测算出阻值范围,就可以得出存储的数值,仅需要数十纳秒的延迟。因此非易失内存往往存在读写不对称的问题,应该尽可能减少写操作。
因此,基于非易失内存的索引需要保证索引结构在系统崩溃后可以恢复到一致性的状态,并且需要降低一致性成本和写成本。为此,研究者针对非易失内存提出了很多B+树的优化,包括例如采用多版本机制的CDDS-Tree[8],采用无序树节点的NVTree[9]/wB+Tree[10],采用混合内存架构的NVTree/FPTree[11],控制缓存行刷出顺序的FAST+FAIR[12]等等。
此外,随着非易失内存的出现,持久性数据离处理器更近。因此,对于基于非易失内存的索引结构,它需要更高的多线程扩展性。在多线程场景下,B+树的优化方向主要分为两类:1. 采用硬件事务内存等新的硬件红利,优化B+树的多线程扩展性,例如FPTree;2. 利用内存字节寻址的特性,设计latch-free的B+树,例如BzTree[6]。由于篇幅和时间限制,本文着力于讨论单核处理器+非易失内存场景下B+树的演进方向,而将多核处理器+非易失内存场景下B+树的演进方向放在下一篇文章中分析。本文的部分观点可能尚不完善,读者可根据文章末尾的引用论文,深入阅读相关工作。
基于多版本机制保证崩溃一致性的CDDS B-Tree
在2011年存储领域顶会FAST上,HP实验室的研究人员发表了第一篇在NVM上保证崩溃一致性的B+树:CDDS B-Tree。CDDS B-Tree采用版本号的机制,在不需要日志的情况下从一个一致性状态更新到下一个一致性状态。版本号机制支持原子性的更新,当事务失败支持将索引结构回滚到最新的一致性状态。与基于内存的Berkeley DB B-Tree相比,CDDS B-Tree 将带宽提高了74%和138%。与基于传统内存+闪存架构的Cassandra相比,基于CDDS B-Tree的KV系统将系统带宽提高了250%-286%。下面,笔者分析CDDS B-Tree的实现原理。如果读者对它的具体操作实现感兴趣,可以详细阅读原文的伪代码。
如下图所示,CDDS具有以下的特性:1. 每个记录都有个版本号区间[a,b),a表示这个记录的起始时间戳,b表示这个记录的失效时间戳。每个存活的记录都有一个版本[a, -),这表示这个记录是最新的,还没有失效,可以被其它线程所访问;2. 每个写操作都会创建一个新版本的记录;3. 每个写操作不会修改记录的旧版本,而是将新版本记录通过原子操作或者写时复制的方式加入到CDDS B-Tree中;4. 所有的写操作都会被持久化,然后全局版本号计数器会被原子性更新。通过以上的四点特性,对于每一个写操作,CDDS B-Tree都会产生对应记录的新版本,而不破坏旧版本。当操作执行过程中系统突然崩溃时,这种多版本机制支持根据完整的旧记录回滚到一致性的状态。
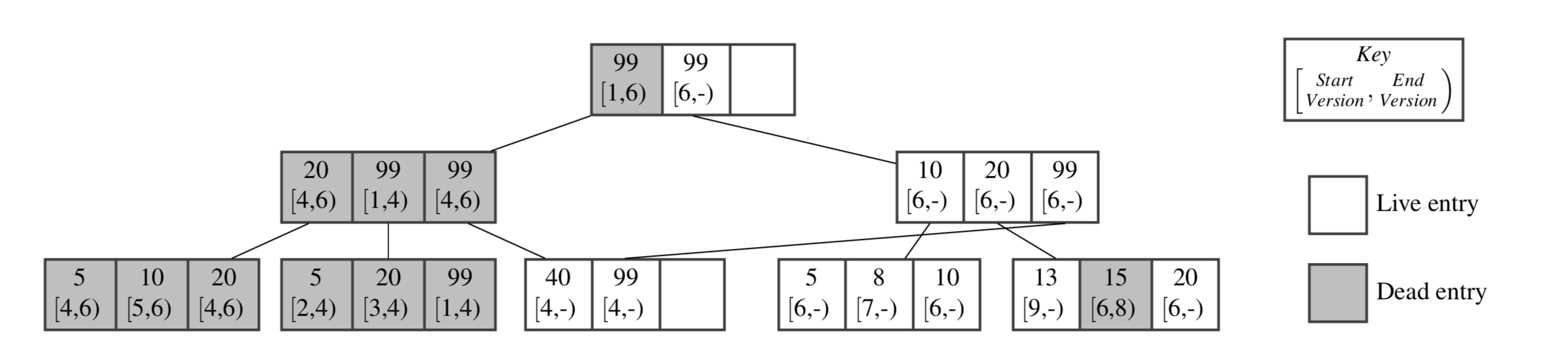
看到这里,读者们很容易联系到MySQL中的undo日志:每个更新操作不会修改原记录,而是生成一个新的记录项,形成一个不同版本的记录项链表。以RR隔离级别为例,事务可以根据事务开始时的活跃事务列表,选择可以读取最新版本的记录。MySQL依赖多版本的undo日志提供MVCC能力,很大程度上提高了读操作的并行能力。CDDS B-Tree就是使用类似的原理,在非易失内存上提供了崩溃一致性的保证。
因为CDDS B-Tree有多个版本的旧数据,所以它需要在合适的时机回收那些不再被访问的旧版本数据,减少空间开销。首先,在插入新的数据时,它可以复用那些不再被访问的记录项。其次,它使用后台运行的垃圾回收线程(例如传统的mark-and-sweep垃圾回收器)回收旧数据:根据目前所有线程访问的最旧版本号,确定可以回收的最大版本号,然后从B-Tree的根结点开始遍历删除旧数据。
基于混合内存架构的NV-Tree
笔者曾完整实现过本文提到的所有B-Tree。对于CDDS B-Tree,它的主要问题在于为了维护多版本的存在,引入了大量写操作和持久化操作。尤其是排序操作,它需要移动现有的记录,为新记录提供插入位置,这需要将相关记录置为非法,并创建新版本,这带来了大量持久化开销。同样,在发生树节点分裂等复杂操作的情况下,它也需要将发生分裂/合并的树节点中所有记录置为非法,并创建相关所有记录的新版本。文献[2]中说明,当树节点大小为4KB时,往CDDS B-Tree中插入一百万条记录,它的持久化版本(存在clflush操作)比易失性版本要慢20倍,原因是clflush操作会带来很高的延迟和大量的缓存缺失。此外,CDDS B-Tree的旧版本回收操作,也会带来不可忽视的开销。
为了解决上述问题,南洋理工大学的研究人员在FAST'15上提出了NV-Tree,基于主要三点设计:1. 选择性的数据一致性保障机制。因为B+树将真实数据存储在叶节点,而内部节点作为叶节点的索引,只用于加速真实数据的查找,所以NV-Tree将叶节点视作为关键节点,内部节点视作为可重建数据。CDDS B-Tree需要保证整棵树的一致性,而NV-Tree只保证叶节点的一致性,从而消除了内部节点的一致性开销。当系统崩溃时,只需要叶节点的数据一直处于一致性的状态,内部节点就可以根据叶节点数据进行重建。2. 保持叶节点的记录是无序的,从而消除排序操作的一致性开销。同时,NV-Tree保证内部节点的记录依然是有序的,这可以加速键值对的查找过程。3. 使用一种处理器缓存友好的格式存储内部节点。NV-Tree将所有内部节点存储在一个连续的内存空间,任何一个内部节点都可以直接通过它的父节点计算出它的偏移位置,从而避免了指针开销,提高了处理器缓存的命中率。
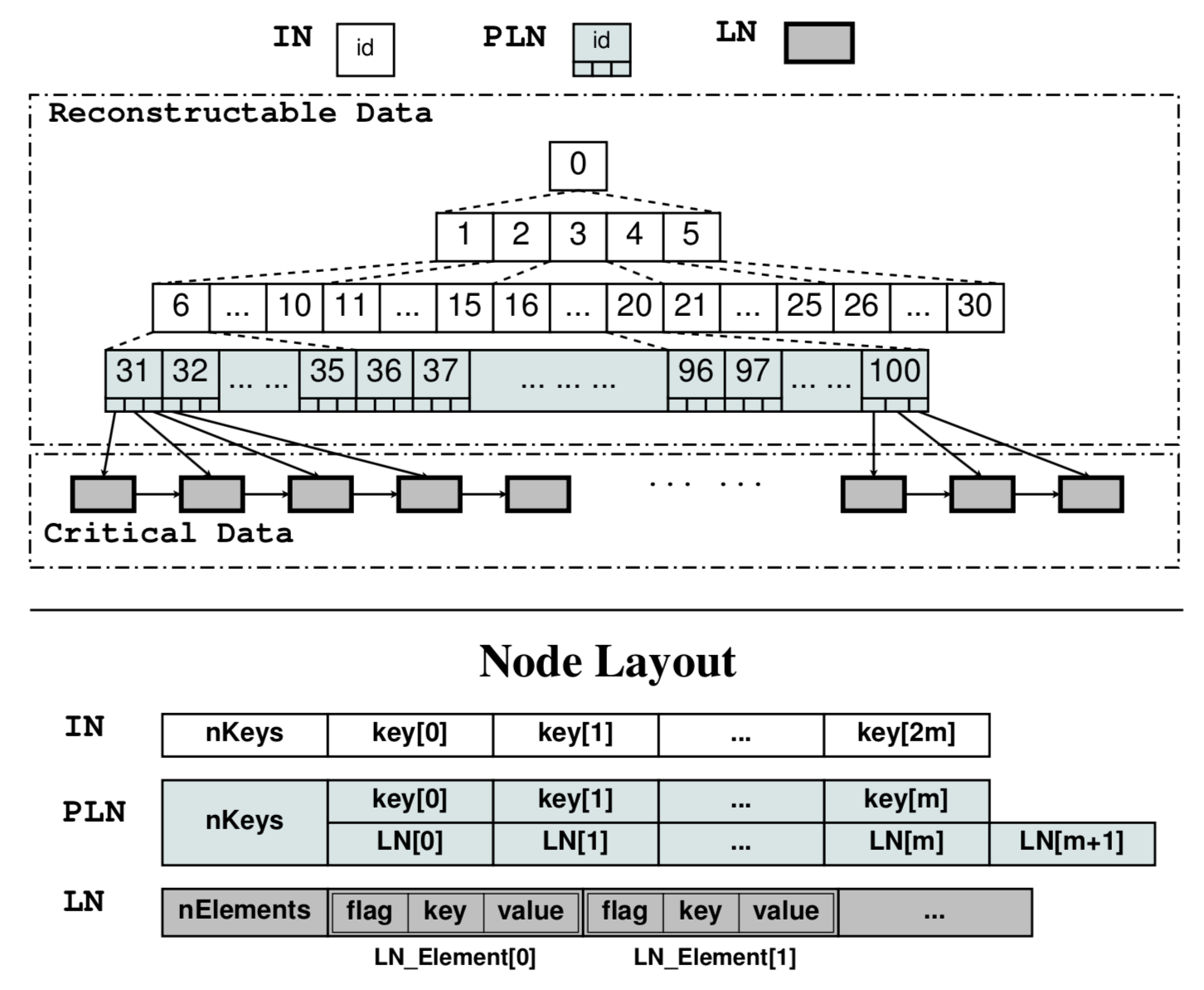
如上图所示,所有的叶子节点通过右指针衔接成一个链表,每个叶节点可以通过最后一层内部节点(parent of leaf node,PLN)的指针进行访问。所有的内部节点都存储在预分配的连续内存空间,所有内部节点的偏移位置都是固定可计算的,从而消除了指针的空间开销和可能导致的缓存缺失操作。

因为NV-Tree只将叶节点放在非易失内存上,下面笔者简单介绍NV-Tree叶节点的树操作。如上图所示,叶节点的更新操作不需要日志或者版本号开销,不论是删除/更新/插入操作,所有的新数据都以append-only方式插入到新节点中,这与传统的redo log原理十分相似。以图(a)为例,向一个节点插入7包含两个步骤:1. 将数据写入树节点,+表示这个数据是插入操作,-表示这个数据是删除操作;2. 用8字节原子操作修改树节点的记录项计数器,只有这个计数器修改成功,插入操作才算完成。如果系统在step1和step2之间发生了崩溃,因为计数器没有改变,所以step1不会影响叶节点的一致性。删除操作与插入操作相似,而更新操作可以分解为删除+插入操作,留给读者自己分析。
当NV-Tree发生了叶节点的分裂或者合并操作时,它使用clflush指令控制了持久化操作的顺序,同样确保操作所产生的修改只有在最后一次原子性操作后才可见。如下图所示,以分裂操作为例,它包含三个步骤:1. 拷贝合法记录到新的叶节点;2. 更新PLN节点,插入新的叶节点。这时候没有产生任何修改原叶节点链表的操作,不影响叶节点的一致性;3. 原子性更新分裂叶节点的前节点,指向新的叶节点。

值得注意的是,当PLN节点空间满的时候,NV-Tree会执行一个重建过程,扩大内部节点数组的大小。这个重建过程可能会对系统带来一定的性能抖动。详细的过程,用户可以阅读原论文。
采用间接排序数组的wB+Tree
针对CDDS B-Tree中排序操作带来的持久化开销,中国科学院的研究人员在VLDB'15上也发表了一种新的内存B+Tree - wB+Tree。针对CDDS B-Tree的缺点,wB+Tree提出了两点优化方向:1. 最小化记录的移位操作。在一个有序的树节点中,任何一个记录的插入和删除操作会引起平均一半记录项的移位操作。这么多的移位操作无法通过8字节原子操作保证崩溃一致性,因此需要依赖日志或者版本号机制,引入大量的持久化开销。2. 良好的搜索性能。虽然NV-Tree通过无序叶节点减少移位操作,但会带来一定程度的搜索延迟。

如上图所示,wB+Tree的树节点采用了一个小型的slot数组和一个小型的bitmap数组。对于基于磁盘的B+树,它的树节点大小往往位于4KB~256KB的范围内(例如MySQL中的16KB),而基于内存的B+树节点往往只有2-8个处理器缓存行大小,每个树节点往往只能存放数个或者数十个记录。以每个树节点存放64个记录为例,slot数组中slot-0记录合法记录的数目,其它项slot-i记录对应顺序的键值对在树节点Index-entries中的位置,从而wB+Tree通过slot数组就记录了所有键值对的顺序,可以完成二分查找过程。因为每个键值对的排序范围只会处于0-63这个区间,所以每个slot项只需要6个比特位(为了性能考虑,往往采用一个字节)。以上图(a)为例,这个slot数组表示有5个记录,后面slot-1到slot-5记录第1-5个记录在树节点中的位置。
上图(b)显示了一个配置bitmap数组的树节点,bitmap数组中每个比特位标bitmap-i记着对应slot-i是否是一个合法的记录。任何一个插入操作将记录写入数组后,只有将bitmap数组中对应的比特位设置为1才算插入成功。任何一个删除操作,只需要将bitmap数组中对应的比特位设置为0就可以结束。以每个树节点存放64个记录为例,一个bitmap数组只需要8个字节,所以可以用8字节的原子操作保证一致性。
上图(e)显示了一个配置slot+bitmap数组的树节点。以插入操作为例,它先将数据写入无序树节点,然后修改slot数组存储它的顺序,最后通过bitmap数组的原子操作完成这次操作。如果在修改bitmap之前发生了系统崩溃,系统可以通过bitmap数组+无序树节点,恢复出slot数组。综上所述,wB+Tree通过slot+bitmap数组,在支持二分查找和崩溃一致性的前提下,避免插入/删除操作带来的排序/移位操作。虽然绝大部分操作都可以通过原子操作来保证一致性,但是wB+Tree依然依赖redo日志保证树节点的分裂/合并操作的一致性。
基于指纹技术和硬件事务内存的FPTree
在SIGMOD’16上发表的FPTree,不仅减少了wB+Tree中slot数组的写开销,而且提高了索引的多线程扩展性,它主要包括三项优化:

- 指纹技术。如上图所示,每个叶节点头部存储着一个指纹数组,每个指纹项fingerprint-i记录的是对应记录K-i的哈希值,每个指纹项仅有1个字节。每个查找操作首先将值与指纹数组进行对比,只有哈希值相同才会对比具体的记录信息。因为指纹数组仅为一个缓存行大小,不需要从内存中访问多个缓存行数据,所以比较操作很快就可以完成。
- FPTree采用和NV-Tree类似的混合内存技术,只将叶节点存储在非易失内存上,而将内部节点存在传统内存中,从而消除内部节点的一致性开销。
- FPTree针对易失性内部节点和非易失性叶节点采用不同的并发机制。对于易失性内部节点,它采用硬件事务内存技术提高并发处理能力。因为硬件事务内存会被clflush操作影响,所以它采用细粒度的锁技术提供叶节点的并发控制。由于硬件事务内存是一项比较新的技术,笔者会在下一篇文章中详细分析。
可容忍临时不一致性的FAST+FAIR算法
虽然NV-Tree/FPTree采用混合内存技术降低了一致性开销,但是当系统崩溃时,它需要比较长的时间恢复内部节点,无法达到瞬间恢复的速度。另外,wB+Tree依赖redo日志保证分裂/合并操作的一致性,这会带来较高的持久化开销。针对这些问题,UNIST的研究人员在FAST18上提出了FAST+FAIR算法。它利用8字节的原子操作,即使在修改过程中B+Tree出现了不一致性,读操作也可以识别出不一致的数据,因此这种临时性的不一致状态是可容忍和可恢复的。
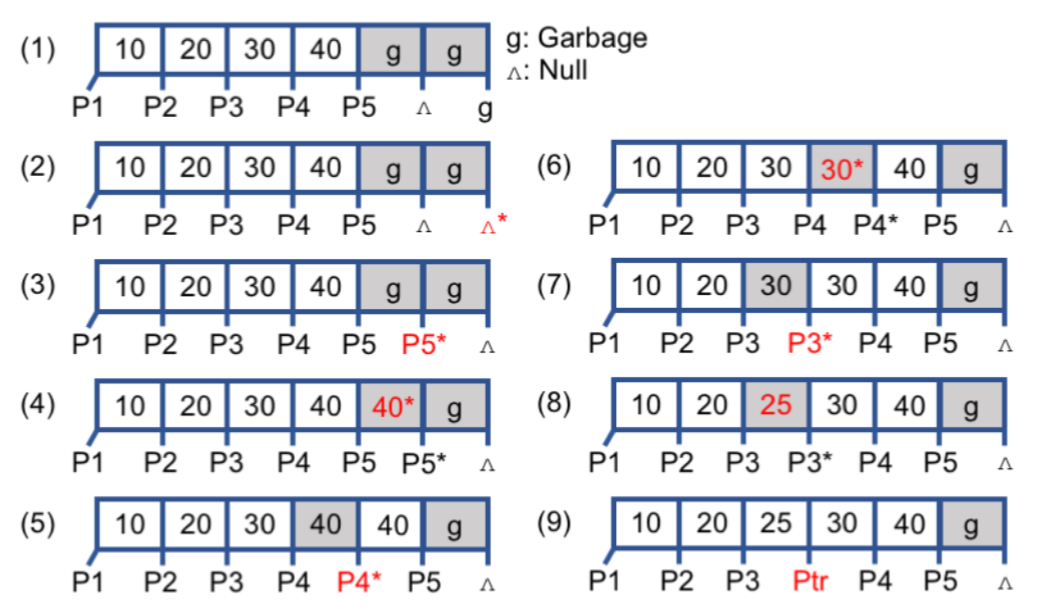
针对排序操作带来过高的持久化开销,研究人员提出了FAST(Failure-Atomic ShifT)算法。排序操作包括一个load/store操作序列,它们相互之间具有依赖性,通过级联的方式触发。如下图所示,以插入25为例。它从右向左找到插入位置(step 1),然后将后面那些记录右移一个位置,从而可以插入25。因为一个树节点可能包含多个缓存行大小的数据,所以它通过clflush指令保证缓存行的持久化顺序。在FAST算法中,每当一个缓存行的数据移动完时,它就会调用clflush,确保这个移位操作的持久性。移位操作无法保证原子性,所以系统崩溃时会导致数节点出现下图中(2) - (9)中的任何一种状态 (移位操作涉及一个缓存行的数据,无法保证原子性,红色的数据可能是未完成的)。FAST巧妙地解决了这个问题:因为B+树不会存在相同的指针,并且8字节的指针不会出现中间状态,所以当读操作找到目标记录时,它会比较左右儿子指针是否是重复值,从而识别出那些临时性的非一致数据,避免读取。此外,对于ARM处理器那种彻底打乱读写顺序的平台,FAST算法也有相应的处理机制,感兴趣的读者可以阅读原文。
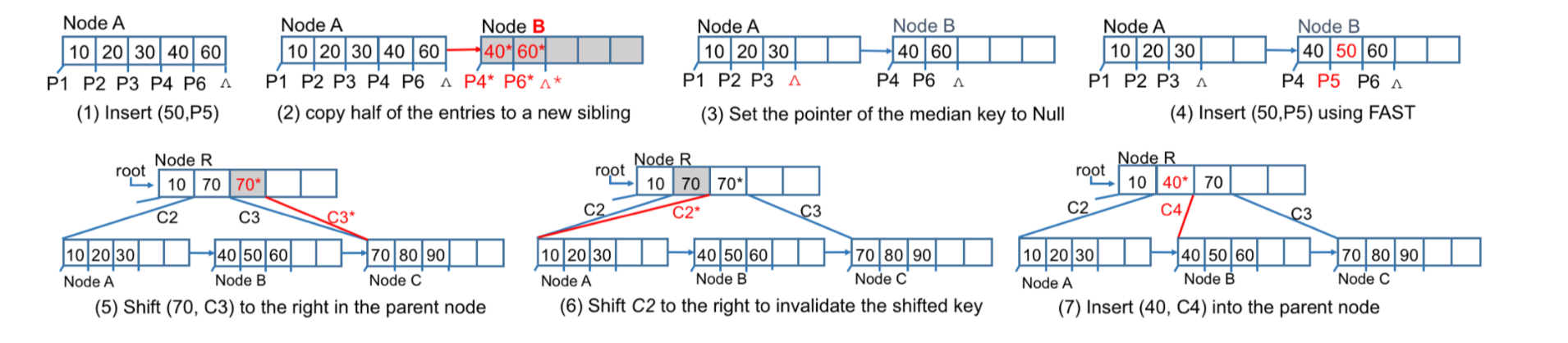
针对树平衡操作带来的持久化开销,研究人员提出了FAIR(Failure- Atomic In-place Rebalance)算法,与NV-Tree比较类似。FAIR算法采用了B-link tree[14]的结构,所有层次的树节点都有兄弟指针相连。如下图所示,以树节点分裂为例(将50插入一个满的树节点),它以下步骤:1. 创建一个空节点,这不会破坏B+树的旧数据;2. 拷贝一半的数据到新节点,并通过clflush指令持久化新节点,这也不会破坏旧数据;3. 将节点A指向节点B并持久化,通过8字节原子性操作保证一致性;4. 删除节点A中那些被移动的记录;5. 通过和FAST类似的方式将新节点插入到父节点。
总结
随着硬件技术的快速发展,软件系统的设计往往也需要作出相应的改变,才能充分榨干硬件红利。本文以多核处理器+非易失内存为背景,分析了多种新型B+树的原理/应用/优势劣势,希望大家看完后有一定的收获。目前在学术界,还有针对非易失内存设计的其它数据结构,笔者在后续的文章中也会进行分析。索引结构作为影响数据库系统性能的关键模块,对数据库系统在高并发场景下的性能表现具有重大影响。如何充分发挥出新型硬件的性能,为用户提供爆炸性的性能提升,POLARDB作为新一代云原生数据库,一直在努力!请持续关注POLARDB!
引用
- [1] Venkataraman S , Tolia N , Ranganathan P , et al. Consistent and Durable Data Structures for Non-Volatile Byte-Addressable Memory[C]// Usenix Conference on File & Stroage Technologies. USENIX Association, 2010.
- [2] Yang J , Wei Q , Chen C , et al. NV-Tree: reducing consistency cost for NVM-based single level systems[C]// Usenix Conference on File & Storage Technologies. 2015.
- [3] Chen S , Jin Q . Persistent B + -trees in non-volatile main memory[M]. VLDB Endowment, 2015.
- [4] Oukid I , Lasperas J , Nica A , et al. FPTree: A Hybrid SCM-DRAM Persistent and Concurrent B-Tree for Storage Class Memory[C]// the 2016 International Conference. ACM, 2016.
- [5] Hwang D, Kim W H, Won Y, et al. Endurable transient inconsistency in byte-addressable persistent B+-tree[C]//16th USENIX Conference on File and Storage Technologies. 2018: 187.
- [6] Arulraj J, Levandoski J, Minhas U F, et al. Bztree: A high-performance latch-free range index for non-volatile memory[J]. Proceedings of the VLDB Endowment, 2018, 11(5): 553-565.
- [7] Lu Y , Shu J , Sun L . Blurred persistence in transactional persistent memory[J]. Industrial Electronics IEEE Transactions on, 2015, 61(1):1-13.
- [8] Lee B C, Ipek E, Mutlu O, et al. Architecting phase change memory as a scalable dram alternative[J]. Acm Sigarch Computer Architecture News, 2009, 37(3):2-13.
- [9] Qureshi M K, Srinivasan V, Rivers J A. Scalable high performance main memory system using phase-change memory technology[J]. Acm Sigarch Computer Architecture News, 2009, 37(3):24-33.
- [10] Ping Z, Bo Z, Yang J, et al. A durable and energy efficient main memory using phase change memory technology[J]. Acm Sigarch Computer Architecture News, 2009, 37(3):14-23.
- [11] Kolli A , Pelley S , Saidi A , et al. High-Performance Transactions for Persistent Memories[J]. Acm Sigops Operating Systems Review, 2016, 51(4):399-411.
- [12] Zhao J , Li S , Yoon D H , et al. Kiln: Closing the performance gap between systems with and without persistence support[C]// Proceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture. ACM, 2013.
- [13] Pelley S, Chen P M, Wenisch T F. Memory persistency[C]// Proceeding of the International Symposium on Computer Architecuture. 2014.
- [14] Lehman P L, Yao S B. Efficient locking for concurrent operations on B-trees[J]. Acm Transactions on Database Systems, 1981, 6(4):650-670.